* [de] BITTE BEACHTEN SIE:
Sie verwenden einen veralteten Browser. Es ist unsicher und nicht mehr für moderne Webstandards geeignet.
Bitte aktualisieren (oder ändern) Sie Ihren Browser, um unsere Website so anzuzeigen, wie sie angezeigt werden soll.
Wir empfehlen die Browser 'Safari', 'Firefox' oder 'Brave'.
DANKE
—Klicken Sie, um diese Nachricht zu schließen—
* [pl] UWAGA:
Używasz przestarzałej przeglądarki. Nie jest ona bezpieczna i nie odpowiada nowoczesnym standardom internetowym.
Zaktualizuj (lub zmień) swoją przeglądarkę, aby wyświetlać naszą stronę w sposób, w jaki powinna być widoczna.
Polecamy przeglądarki „Safari”, „Firefox” lub „Brave”.
DZIĘKUJEMY
—Kliknij, aby zamknąć tę wiadomość—
* [en] PLEASE NOTE:
You are using an outdated browser. It is unsafe and no longer suitable for modern web standards.
Please, update (or change) your browser to view our site as it is intended to be seen.
We recommend 'Safari', 'Firefox' or 'Brave' browsers.
THANK YOU
—Click to dismiss this message—



Security News
Security News
Security News
Security News
On this page
you get important news and warnings about security and privacy on internet!
(Be patient – loading of this page takes few seconds.)
On this page, I give you the latest news, warnings and advice on the subject of security and privacy on the internet. You alone can take care of your own security and privacy and this requires some knowledge, strategy and constant vigilance.
(On the PRIVACY POLICY page, you will find my recommendations for a broad strategy to protect your computer from hackers.)
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
1. 1 PASSWORD Manager Appby Agilebits SoftwareA range of topics on security, focused on password management.
2026-06-02, 00:00

Zero-Shot Learning is a podcast about how AI gets built, secured, and deployed. Hosted by Nancy Wang, 1Password CTO, and Dev Tagare, Senior Director of Engineering at Google, it's a builder's view of the architecture and the complex choices it takes to ship with AI.
As Chief Product Officer at Vercel, Tom Occhino joined Zero-Shot Learning to discuss how AI is reshaping the developer workflow, from frontend architecture to v0, Vercel's production-ready AI coding assistant. What started as a conversation about AI-assisted development became a case for access control as a design decision, not a security afterthought.
How AI changes the developer security model
As part of the team that built and shipped React at Facebook, Tom helped replace MVC patterns with a component-based model that changed how an entire generation of engineers reasoned about interfaces. He calls what's happening now with AI-assisted development "a fundamentally different approach to software."
Where the earlier shift changed how developers organized their thinking, this one changes who or what creates and operates software. In the past, a developer working on component architecture brought years of professional judgment to those decisions. Today, a non-technical worker using an agent in that same workflow does not, and when that agent can call tools, the gap can't be covered by training. Authorization has to be built into the architecture.
Vercel's AI SDK makes it easier for agents to call tools, which adds to its appeal, but also means it requires stronger safeguards. "Putting on my security hat," Nancy said, "how do you make sure that these agents don't get exploited?"
"Under no circumstances are we encouraging code execution on the client," Tom replied.
Vercel builtSandbox because agent-driven development requires an environment without access to production secrets, environment variables, or configuration, so untrusted code doesn’t touch production by default. Sandbox limits what an agent can read or modify locally.
Outbound access needs authZ policy too. "There are outgoing requests that come from that sandbox," Tom said. "Who are they allowed to talk to, and in what capacity?"
Tom drew each boundary deliberately, inbound and outbound, before anything shipped. An agent that can't read your production secrets can still make outbound calls to wherever it chooses. One boundary without the other still leaves the agent free to act where it shouldn't.
When everyone builds, access must be secure by default
To secure the new group of people who can build with AI, products must be secure by default.
Especially as you open access to these tools to many more people who lack the security fundamentals from the first 15 or 20 years of their career," Tom said, "we need to be creating systems that are secure by default and safe by default."
Imagine that a product manager wants to track customer health without waiting on the analytics team and builds a dashboard overnight using an AI-assisted coding platform. The AI pulls account data from Salesforce, usage metrics from Mixpanel, and support ticket volume from Zendesk. To make it work quickly, the PM pastes API keys and account tokens directly into the app. Those credentials carry the PM's full permissions across all three platforms, including access to customer records the dashboard will never need. They share the link with their team, and suddenly several people are querying live customer data through an app nobody in security knows exists, usingcredentials that won't expire, with an agent that can't be attributed to individual users, and that has no revocation path if the PM leaves the company.
"We need that untrusted code execution environment that does not have access to production secrets," Tom said. In our example, the PM's dashboard is what it looks like when permissions are inherited by default.
It's an open area of research, Tom acknowledged, and one 1Password is already working through.
How 1Password makes the secure path the easy path
"You've got to make the paved path the easy path, because if security gets hard, it risks becoming an afterthought,” Nancy said.
“Make the secure way the easy way” is the design logic Tom applied to Vercel Sandbox, understanding that if the secure option requires extra steps, most developers won't take them.
The insecure way is already documented in many codebases. An SSH key is a plain-text file on a developer terminal. API tokens are hardcoded into scripts. Environment variables are inherited by anything running in that environment with no encryption, access controls, or audit trail. Just a file.
1Password Unified Access serves as the authorization layer between the agent and the systems it connects to. Credentials move from vault to runtime without passing through a file, a config, or a clipboard, and are evaluated in context when access is requested, not carried over from setup. The shift from always-on access that developers must manually provision to just-in-time authorization is where the agent gets only what it needs for the task at hand and nothing more. There are no keys to rotate, no authorization to revoke, and nothing to explain to a security team after the fact. It’s a change that fundamentally reduces risk and manual effort from developer workflows.
Vercel's integration with 1Password brings agentic access control directly into the cloud sandbox environment that Tom described. An agent calling tools through Vercel's AI SDK needs credentials to do useful work. Those credentials don't have to be long-lived or broadly scoped. They don't have to live in the agent's context at all.
Tom calls Vercel's platform strategy "the operating system of agents." The authorization decisions made at the design stage become the authorization model that everyone using the product inherits.
Designing access control for agents and AI-assistants
In "We solved the blank canvas problem," Tom joined Zero-Shot Learning to talk about generating ideas faster with AI, and the conversation arrived at why that requires designing authorization from the start. Access control has always been a requirement; what's changing is when in the process it gets built.
Watch the full episode with Vercel’s Tom Occhino
Tom Occhino joined Nancy Wang and Dev Tagare on Zero-Shot Learning, 1Password's podcast on agentic AI and the people building it.
Watch now2026-05-29, 00:00

May was A&PI Heritage Month, and at 1Password, we're proud to shine a light on the people who bring these perspectives to life in our work and help shape our culture every day.
This year, we decided to spotlight Stephanie Cheng, Senior Customer Trainer and a leader within our A&PI Employee Resource Group. With over five years at 1Password, Stephanie has built her career around helping people feel capable, confident, and supported, whether she's onboarding a new customer or creating space for her colleagues to connect and belong. We sat down with her to learn more about her approach to customer education, the community she helps lead, and what A&PI Heritage Month means to her.
You’ve spent five and a half years training thousands of customers on something they rely on every day to stay secure. What has that experience taught you about people, about learning, and about what it really takes for something to click?
One thing this experience has taught me is that learning really happens when people feel comfortable enough to ask questions and admit what they don’t know. Especially in security, people can feel intimidated or worried about “doing it wrong,” so a big part of my role became creating an environment where people felt supported rather than overwhelmed. It’s taught me that what makes something “click” usually isn’t just the technical explanation; it’s helping people understand why it matters in the context of their own work and daily habits. The most effective training moments happen when customers can connect the product back to something tangible in their world. Over time, I’ve also learned that good training is less about presenting information and more about listening. Every customer approaches technology differently, and being able to adapt to different learning styles, technical comfort levels, and goals has been one of the most rewarding parts of the job.
Is there a customer interaction or training moment that has stuck with you? Something that surprised you or shifted how you approach your work?
One interaction that has always stayed with me happened during my first year on the team.
After one of my training sessions, a customer actually reached out to their Account Executive to ask for my manager’s email so they could share positive feedback directly with her and senior leadership, including our CRO. I was pleasantly surprised at the time because I was still relatively new in my role, and I hadn’t realized how much of an impact those sessions could have on someone’s experience.
As we later introduced surveys and more formal feedback channels, I continued to receive positive comments from customers mentioning me by name. What stood out most wasn’t just the feedback itself, but realizing that customers remembered how the training made them feel. They felt more confident, supported, and comfortable using something that was important to their day-to-day work and security.
That experience really shaped how I approach customer education. It taught me that effective training isn’t just about transferring knowledge; it’s about building trust, creating a supportive environment, and helping people feel empowered rather than intimidated. That mindset has stayed with me since.
As part of the A&PI leadership team, how has the experience stretched you? What’s a skill or perspective you’ve developed that you wouldn’t have otherwise?
Being part of the A&PI leadership team has stretched me in ways that are very different from my day-to-day role. It gave me the opportunity to think more intentionally about community-building, engagement, and creating experiences that bring people together in meaningful ways.
One thing I’ve developed is a stronger understanding of how much thought and coordination go into building inclusive spaces. Whether it’s organizing events, coordinating speakers, or creating opportunities for people to connect socially, I’ve learned how important it is to create experiences that feel approachable and welcoming for a wide range of people.
It’s also helped me grow my leadership skills outside of formal authority. A lot of ERG work happens through collaboration, initiative, and shared ownership, and I’ve learned how impactful thoughtful planning and consistency can be in building trust and engagement over time.
You’ve played a big role in bringing the A&PI community to life – from Lunar New Year ramp cards to monthly socials. What has building that community meant to you personally? And what have you seen it make possible for others?
Building the A&PI community has been incredibly meaningful because it created opportunities for people to feel seen, connected, and celebrated in ways that go beyond day-to-day work.
One thing I’ve loved most is seeing how different types of events create different entry points for connection. Some people joined our monthly socials where we’d talk through relatable topics or do creative activities like building seasonal mood boards together for Thanksgiving or Spring. Others signed up for CliftonStrength assessments, watercolour classes, or purchased A&PI-authored books that they later shared back with the group. I also really valued being able to support Asian-owned local businesses through some of our initiatives. It made the celebrations feel more connected to the broader community outside of work as well.
Those moments helped create opportunities for people to connect in ways that felt authentic to them, whether that was through conversation, creativity, learning, or cultural celebrations. It reminded me that community isn’t built through one big event – it’s built through consistent, thoughtful experiences that make people feel welcomed and included over time. It is so exciting to have returning members join monthly socials, and to see new faces show up and continue to stay engaged. Even though we are all working virtually, the sense of community really brings everyone closer together!
What does it mean to you to be celebrating A&PI Heritage Month at work, specifically? Why does it matter that this happens inside a company and not just outside of it?
Celebrating A&PI Heritage Month within a company matters because it creates intentional space for people to share culture, stories, and experiences that may not otherwise surface in day-to-day work conversations. It also gives others an opportunity to learn, engage, and build connections across different backgrounds in a meaningful way.
Outside of work, I volunteer with Asian Roots Collective, a community that creates spaces centred around familiarity, belonging, and celebrating Asian excellence across sports, arts, food, entertainment and beyond. One of the things I’ve always appreciated most about that experience is seeing how powerful it can be when people feel represented, understood and connected to a community that reflects part of their identity and experiences.
That perspective has shaped how I think about community-building at work as well. We spend such a significant part of our lives in the workplace, so feeling seen and included there has a real impact on belonging and how comfortable people feel showing up as themselves.
Through the A&PI ERG, I want to help create some of that same sense of connection and community that I’ve experienced outside of work - whether that’s through cultural celebrations, creative events, or simply giving people opportunities to gather and feel part of something together. To me, that’s what makes these spaces so meaningful: they help people feel represented, welcomed, and connected beyond just their role or title.
Stephanie's story is a reminder that the most meaningful work, whether it's guiding a customer through a new product or helping a colleague feel seen and celebrated, comes down to the same thing: creating environments where people feel safe, supported, and empowered to show up fully. As we close out our celebration of A&PI Heritage Month, we're grateful for the community Stephanie helps build and for the care she brings to every interaction, on and off the screen.
If you’re curious about building a career at 1Password, we invite you to explore our open roles and learn more about how you can be part of our growing team. https://1password.com/careers
2026-05-29, 00:00

In the constantly evolving world of enterprise tech, there’s one thing that IT and security teams have always been able to count on: users won’t follow policy if they think it’s standing in the way of their productivity.
Case in point: 1Password’s most recent annual report found that 52% of employees have downloaded apps without IT approval. These shadow IT apps typically sit outside a company’s SSO provider, and introduce both unmanaged risk and cost.
That governance gap has become more pressing with the growing adoption of AI tools and agents, which introduce new and worsening threats. This issue was the focus of 1Password’s recent webinar, “The unmanaged stack: Governing SaaS apps and AI tools outside SSO.”
What is the unmanaged stack? It refers to all of the SaaS apps and AI-based tools that can’t be managed by traditional IAM tools, whether that’s due to software constraints or the infamous “SSO tax.”
During the webinar, Evan Sandhu, 1Password Product Marketing Specialist, and Ethan Stoler, Senior Demo Engineer, explored how 1Password’s solutions can help IT and security teams secure and govern these unapproved or unmanaged access points.
Read on for an in-depth recap of the webinar’s key themes.
New integration features to manage high-risk SaaS and AI
IT and security teams need solutions to manage those apps that fall outside the purview of SSO. Thankfully, new integrations between 1Password Enterprise Password Manager (EPM) and 1Password SaaS Manager are able to do just that.
“With SaaS Manager integrating with EPM, you can now discover sensitive and shared accounts stored in EPM vaults, surface them for review, and let IT take ownership of them, moving them from end-user management to IT management.”
– Evan Sandhu, The unmanaged stack: Governing SaaS apps and AI tools outside SSO
During the webinar, Evan Sandhu explored how these integration features work across three different categories:
Discover: With Vault Insights, teams can discover sensitive or shared logins across an organization’s EPM vaults. And with Browser Insights (beta) teams can surface login activity from the 1Password browser extension to reveal unapproved app usage.
Review: With an Account Risk Report, teams can review the surfaced accounts and credentials according to their risk level, enabling admins to prioritize remediation.
Govern: With Account Governance, IT and security teams can take over management of any of the discovered high-risk logins for sensitive or shared accounts.
In a live demo of these features, Ethan Stoler showed in real time how quickly this integration can surface various credential risks for critical applications like GitHub, and how simple it is for admins to govern those risks.
How 1Password SaaS Manager helps prevent OAuth supply chain attacks
OAuth-based supply chain attacks are a growing concern for today’s companies. These attacks tend to play out like so:
An employee connects a third-party tool using “sign in with Google” or “sign in with Microsoft.”
Permissions are granted, then forgotten.
That third-party tool gets compromised.
The attacker walks into your systems with a valid key.
In this scenario, the attacker is making authenticated requests within the approved permission scopes; there are no failed logins, anomalies, or privilege escalation attempts that can be detected by a team’s SIEM provider, CASB, or anomaly detection tools.
The key to managing this risk doesn’t lie in preventing every OAuth connection or blocking every third-party tool. Rather, as Sandhu put it during the webinar, “Prevention requires knowing which connections exist right now at this moment, and ensuring access is granted only when needed. This is exactly what 1Password SaaS Manager does.”
1Password SaaS Manager can help companies:
Discover risky OAuth connections: Teams can continuously surface Oauth connections and flag connections with elevated permission scopes.
Secure Access: Admins can revoke access with a single action, set policies to restrict OAuth, and reduce standing privilege exposure.
Audit Actions: Every access change is automatically logged, providing teams with defensible audit records for compliance standards like SOC 2, ISO 27001, and HIPAA.
These abilities mean that 1Password SaaS Manager is uniquely able to help teams manage risks related to OAuth supply chain attacks – and the other risks associated with a company’s unmanaged stack of shadow IT and AI.
New AI integrations to help you govern ChatGPT, Claude, Gemini, and Cursor
Unfortunately, even company-approved AI tools often can’t integrate cleanly or affordably with SSO.
As Sandhu stated, “Let’s say someone needs access to an AI platform. You create accounts for them, and it’s done one by one for every tool. You as an IT admin are constantly context switching between every different admin console to check who’s using what, how many tokens they’re spending, and how much usage they’re getting.”
This is why the webinar also highlighted five new AI integrations within 1Password SaaS Manager, including:
ChatGPT and openAI
Claude
Cursor
Google Gemini
These integrations are built with full lifecycle governance, including onboarding and offboarding workflows, in mind. As Sandhu put it, “You can assign roles, whether to individuals or groups. You can log specific metrics like usage and token spend. And you have full deprovisioning and provisioning capabilities as well. All of this is done in 1Password SaaS Manager.”
Ethan Stoler’s demo showed how simple it is to discover and manage these unapproved AI tools, including setting up workflows that let teams automate and customize their management processes.
What should teams do next?
To summarize the main points of the webinar:
1Password EPM and 1Password SaaS Manager have new integration capabilities that enable them to discover and govern high-risk logins.
1Password SaaS Manager is able to help companies surface, secure, and audit the unsanctioned AI tools and agents that can put companies at risk.
1Password SaaS Manager has new integrations with major AI companies that provide admins with a central tool for full lifecycle governance over their AI applications.
These integrations and capabilities are already available for teams that currently use 1Password EPM and 1Password SaaS Manager. To learn more and to see the demos in action, watch the complete webinar recording.
Want to get started with 1Password SaaS Manager? Reach out to our team.
2026-05-28, 00:00

At 1Password, our Jewish 'Bits Employee Community Group exists to create space for Jewish employees and curious allies alike to connect, learn, and show up authentically. For Jewish Heritage Month this May, we wanted to spotlight Nicole Smith, Staff Project Manager and lead of our Jewish 'Bits ECG.
In her four years at 1Password, Nicole has been someone people turn to when the work gets complicated, because she builds trust that makes honest conversations possible. That same instinct to lead with curiosity and create space for real connection shows up across everything she does, from leading complex, cross-functional work to fostering community that enriches how we all experience 1Password together.
We sat down with Nicole to talk about what drives her, the projects she's most proud of, and what she hopes her colleagues take a moment to appreciate in honor of Jewish Heritage Month this year.
As a Staff Project Manager for our CX organization, you're known for bringing clarity to complex, cross-functional work - helping teams stay aligned and move effectively so they can show up for customers. What is it about that kind of work that energizes you?
The people I get to work with every single day are what energize me! Cross-functional work involves navigating a lot of competing priorities and moving pieces, and that complexity can create a lot of noise. My job is to cut through it, not by having all the answers, but by building enough trust with the people around me that we can be honest about what's working and what isn't.
When people trust you, they tell you the truth, and when you have the truth, you can actually move forward together. When a working group aligns and shifts into driving forward together with purpose, it's powerful. When my colleagues feel supported in the work we’re doing, we show up better for each other, and that ultimately creates the best experience possible for our customers.
What's a moment or project at 1Password that you're especially proud of - something where you could really see the difference your work made for the team
Our migration from our previous Customer Relationship Management software to implementing a new tool for everyone at 1Password is a project I'm especially proud of. It involved over ten months of deeply cross-functional, complex work, and we went live in March 2026.
The thing I'm most proud of isn't the go-live itself, but how the team showed up together to get there. There were moments where things could have gone sideways, and what propelled us to the finish line together was trust. Our team was honest about known risks, they flagged problems early, they backed each other up, and that's what winning together looks like when the stakes are high. I know the work we did as a team made a difference for not only our Customer Experience folks, but the customers we interact with on a daily basis.
You also serve as a mentor in our CX mentorship program. What inspires you to invest in others' growth, and what do you hope the people you mentor feel when they're in your corner?
I've been extremely fortunate to have some incredible managers, mentors, and colleagues in my corner who saw something in me before I saw it in myself. Once you've been on the receiving end of that kind of investment, you feel empowered to pay it forward. When I'm mentoring, I try to be a good listener first, while also being honest. As a mentor, I'm going to tell you what I actually think and ask my mentee the hard questions. I’m going to show up for the moments that don't feel great or might feel like a challenge, because that makes the accomplishments and wins even better to celebrate. I want the people I mentor to leave our conversations trusting and feeling more confident in themselves because they know they have someone who is there to support them.
In addition to your work in CX, you lead our Jewish ‘Bits Employee Community Group. What does that leadership role involve, and how do you approach building a space that feels welcoming both to Jewish employees and to allies who want to learn?
At its core, our Jewish 'Bits Community Group is about connection. We create space for Jewish employees to share culture, identity, and history with one another. That sometimes looks like hosting an educational panel and conversation, a holiday gathering, or starting a Slack thread where someone shares something personal and meaningful.
We're equally committed to being a space where allies and curious colleagues feel genuinely welcome. Building that kind of trust where people can come with questions and without fear of getting it wrong is something I take seriously. Jewish identity is layered and rich and sometimes complicated, and my approach is to lead with honesty, make room for real conversations, and make it clear that everyone's curiosity is welcome here.
As a leader for the ECG, you've been involved in many meaningful moments - including the opportunity to moderate a conversation with Holocaust survivor Mariette Doduck. How has leading within this community deepened your connection to your Jewish heritage and identity?
In 2025, I moderated a conversation with Mariette Doduck, a Holocaust survivor who has spent decades sharing her testimony, and it was one of the most profound experiences of my professional life. Hearing her story and sitting in that very real, challenging conversation gave me a deep appreciation for the Jewish people who have come before me, and that stays with me. Leading Jewish 'Bits has made me more intentional about what I carry forward as a Jewish person, and about what it means to hold space for others to do the same. My connection to my heritage has deepened in ways I didn't expect, and there's something about being responsible for that space that shifts how you carry your own identity. Jewish Heritage Month honors history, culture, and the richness of Jewish identity. What does this month mean to you personally, and what would you want your colleagues at 1Password to take a moment to appreciate or learn about?
Jewish Heritage Month is a dedicated time to celebrate history, culture, and the richness of Jewish identity. Jewish heritage is at times complex and deeply personal to those who carry it, and this month is a reminder to appreciate the depth of what it holds.
My invitation to colleagues is to get curious, to ask a question, start a conversation, and lean into what they don't yet know. Jewish identity is not a monolith, it's a tapestry of cultures, histories, languages, and lived experiences, and there is so much to discover. Engage with the community and conversations that Jewish 'Bits created this month, and in the conversations they'll create throughout the rest of the year, and you might be surprised by what resonates, and by what you didn't already know.
– Through her leadership, Nicole demonstrates that fostering genuine trust and leading with honesty are the keys to accomplishing impactful work - from aligning complex working groups and empowering mentees, to cultivating a truly authentic community space.
As we celebrate Jewish Heritage Month, we encourage you to embrace Nicole’s call to action: lead with curiosity, ask questions, and lean into the unfamiliar. Jewish heritage remains a rich collection of diverse cultures and shared histories, and there is no better moment than now to explore it.
Want to learn more about life at 1Password and our people and culture? Explore our careers page. https://1password.com/careers
2026-05-20, 00:00

There’s a question we get asked constantly, and it’s the right one to ask: “Can 1Password see the contents of my vault?”
The answer is no, and it’s because of how we built the product, not just a promise we’re making. That’s an important distinction, because “we promise” has never been an acceptable answer in this industry. After all, promises get broken, and companies get compromised, acquired, and are under constant attack from threat actors.
1Password’s commitment to our security principles is genuine, but what matters more is how we’ve built that commitment into our product and architecture, and the transparency we back it up with with our security white paper.
So here’s the precise answer: The way 1Password is built means that we are incapable, on a technical level, of decrypting and reading your vault contents. We're not policy-prevented or contractually restricted; we are technically incapable. This post explains what that means, why we built it this way, and what the real tradeoffs are.
Your data is encrypted before it ever leaves your device
When you save a password, a credit card number, or a note in 1Password, the first thing that happens is encryption, and it happens on your device, before any data moves anywhere.
Encryption here doesn’t mean we “hide” or “scramble” your data and promise not to look. It means your plaintext vault item is transformed into ciphertext using cryptographic keys that are only available on your devices. Without these keys, 1Password is unable to decrypt and read your data.
The two keys in question are your 128 bit Secret Key (a 34-character value separated by dashes) and your account password. Together, these produce the cryptographic key that locks and unlocks your vault.
Here’s the critical part: neither your Secret Key nor your account password is ever transmitted to 1Password or stored on our servers. We never possess the keys needed to decrypt your vaults. When you set up your 1Password account on a new device, you’re not “downloading” your key from us, you’re entering it yourself (either manually or using a QR code), and your device uses it locally to decrypt the vault data it receives.
What we store on our servers is the encrypted version of your vault contents: ciphertext that is, for all practical purposes, indistinguishable from random data without the key to decrypt it. If our servers were compromised tomorrow and an attacker exfiltrated every byte of stored data, they’d only have encrypted blobs they cannot read.
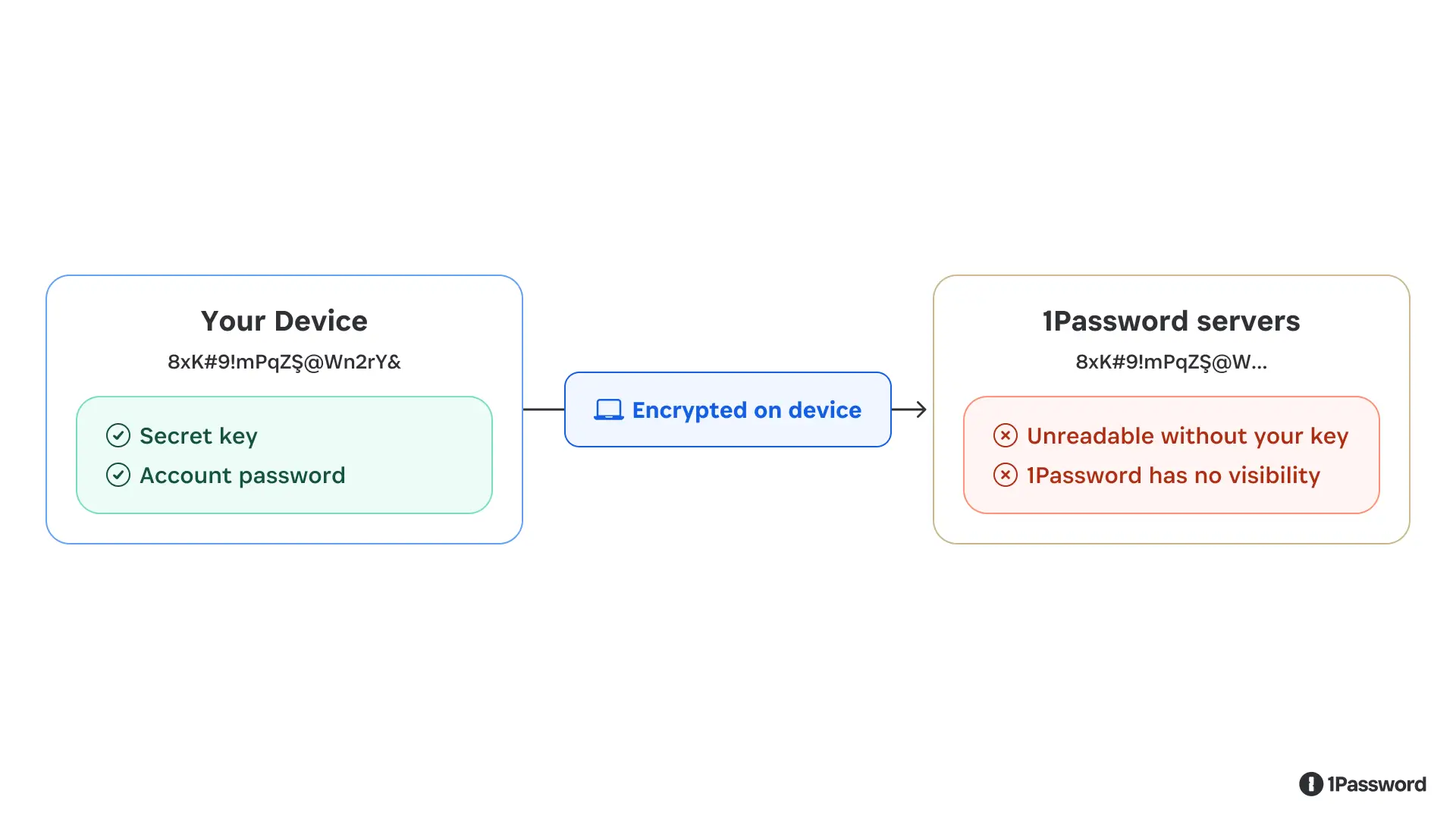
Your vault content are encrypted on your device. What reaches our servers is unreadable ciphertext.
Even the fastest supercomputer would take (literally) billions of billions of years to try and guess a 128-bit encryption key. That’s what we mean when we say 1Password’s security isn’t built on promises; it’s built on math.
What “zero-knowledge” actually means and what it costs
The design pattern described above is called zero-knowledge architecture. It means the service provider, in this case, 1Password, has zero knowledge of the plaintext contents of what it’s storing.
Zero-knowledge is a meaningful claim because it is an immutable fact of our architecture. But zero-knowledge is a security guarantee with real product implications and intentional constraints.
The most significant tradeoff is account recovery. If you forget your account password or lose your Secret Key, we cannot return them to you, because we don’t have them. (If you forget your password, you can regain access to your account by generating a recovery code, but this still requires you to have access to the email account you used to create the account.)
The same constraint shapes what features we can build. Any capability that would require 1Password to see your plaintext data is, by design, off the table. We can’t offer server-side search across your vault contents. When we scan your saved passwords and tell you which ones have appeared in a breach, we do that computation on your device and only a partial hash of your password is checked against breach databases, so we learn nothing about the actual credential. Some things that would be convenient to build are simply incompatible with the architecture, and we think that’s the correct tradeoff.
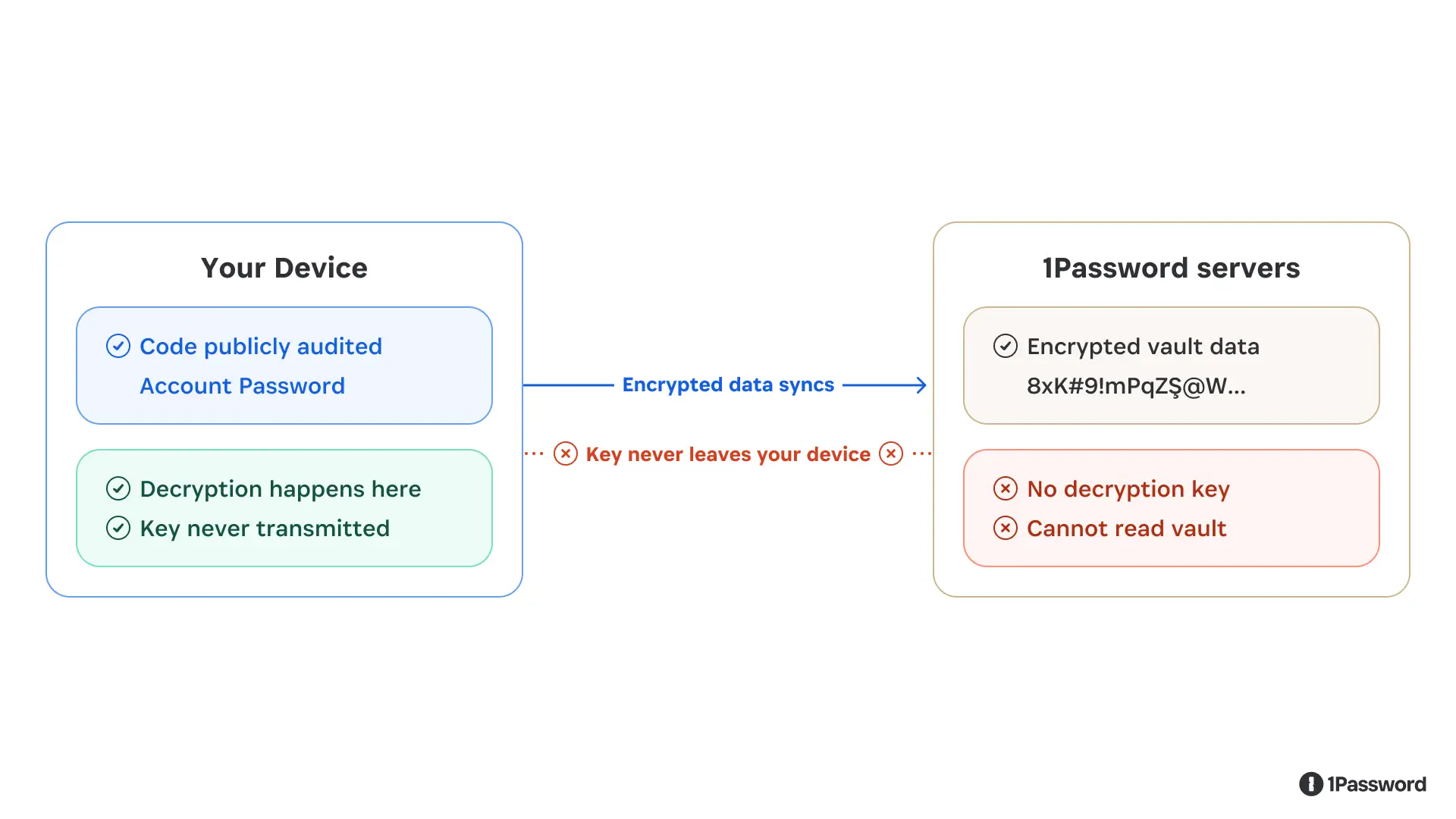
The decryption key lives on your device. Encrypted data syncs to our servers, but the key never does.
Zero-knowledge also means we can’t be compelled to hand over vault contents we don’t have. A court order can require us to produce data, but it can’t require us to produce a decryption key that doesn’t exist on our systems. (You can read our full policy on legal requests here.)
When computation has to happen in the cloud
The zero-knowledge constraint of only processing unencrypted data on a user's device works well for storing and syncing data. But some features, particularly enterprise capabilities like company-wide security reporting, require server-side computation. So our question in building those features has been: how can we do this without undermining our architecture and creating a new exposure point?
This creates a real problem. If you need to process data in the cloud, and that data needs to be in a usable form during processing, how do you prevent the cloud infrastructure from being a point of exposure? The standard answer in most other software is to trust the server, use access controls, audit the logs, and hope the infrastructure isn’t compromised.
We weren’t satisfied with that. So we built cloud processing on top of a technology called confidential computing.
The core idea: instead of processing data on a regular server, we run computation inside a hardware-enforced enclave. Think of it as a sealed processing room: data goes in, results come out, and the room is impenetrable at the hardware level.
The enclave combines hardware-backed isolation, verified code execution, and cryptographic attestation – protocols designed to minimize what services can learn. Not even the cloud provider running the hardware can observe what’s happening.
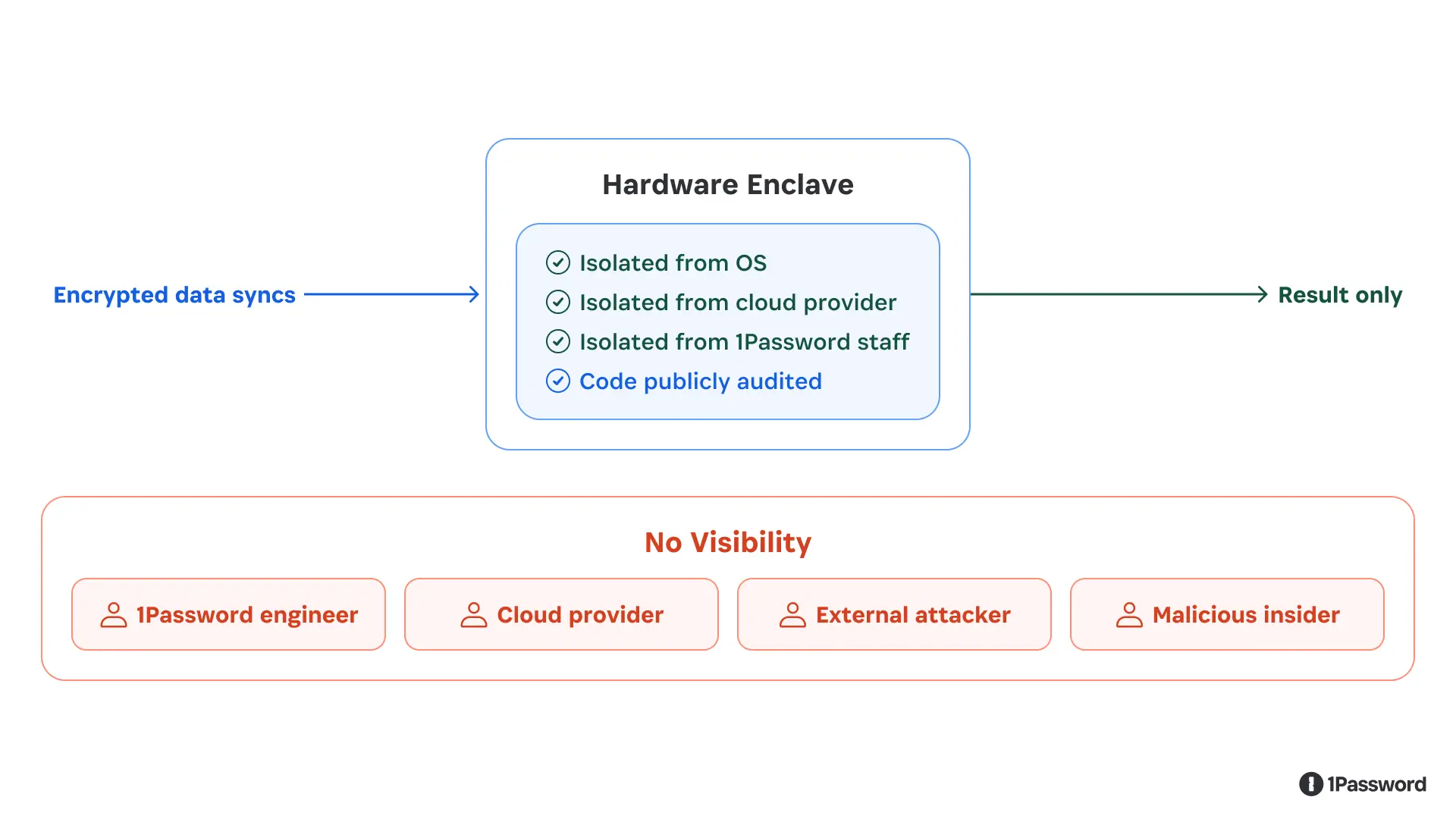
The enclave is a hardware-enforced sealed room. Data is processed inside; nobody — including 1Password — can reach in.
We also publish the code that runs inside these enclaves, and we use cryptographic attestation so that you can independently verify it’s running the code we published and not some modified version. An independent security firm audited the implementation and found no critical vulnerabilities. The full report is publicly available, the code is available, and the verification mechanism is built into the protocol.
Why this design matters more now
Password managers contain sensitive and valuable secrets for individuals, families, and companies alike, so they are often subjected to attacks by bad actors. That has been true for years, and it’s only becoming more true as technology evolves.
Password managers are increasingly the credential layer for a broader set of tools: browsers, developer environments, workplace automation, and now AI-powered agents that can take actions on your behalf. We’ve written about how we approach agent identity and the trust decisions that come with it. As those connections multiply, the question becomes: how do we allow the right tools to access the right data at the right time, without expanding trust more than necessary?
The right answer is to stick to proven security principles: zero trust, zero-knowledge, and cryptographic designs published and reviewed by our customers and the community.
Want to learn more?
If you’re a customer, this is how your data is protected. If you’re evaluating password managers, these are the questions worth asking: Where does encryption happen? Who holds the keys? What can the service provider see, and what can they be compelled to produce?
If you want to go deeper, our cryptography white paper walks through the technical implementation in full detail. Our confidential computing blog post covers the enclave architecture specifically.
Even as 1Password and the digital world evolve, we will continue to insist that security should be verifiable, not just claimed. Everything we build maintains that standard.
2026-05-20, 00:00
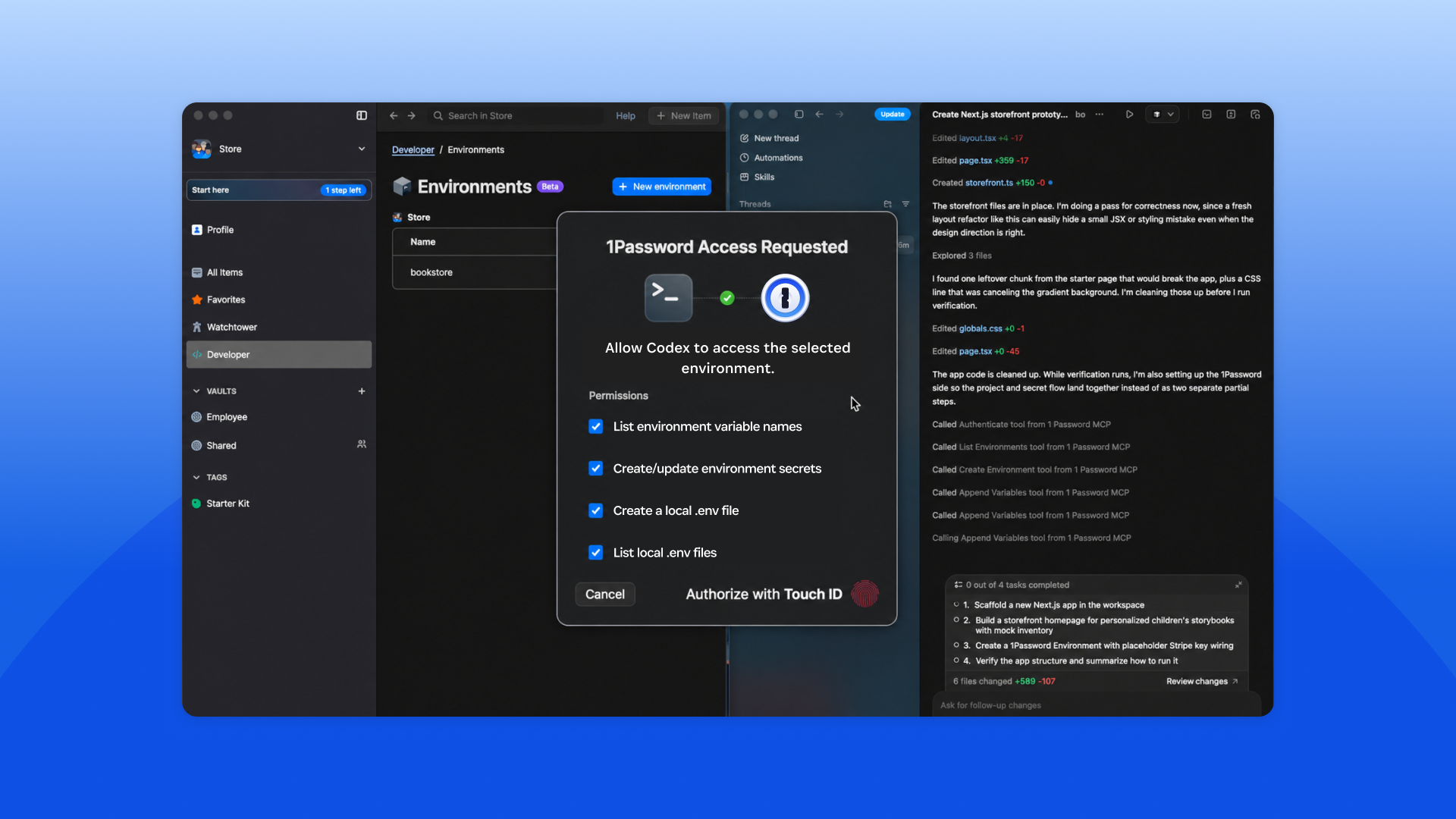
Coding agents like Codex are helping developers write, execute, and prepare code for production. Every action that AI coding agents take against a database, an API, or a deployment pipeline requires access to credentials. Today, these credentials typically live in .env files, scripts, or hardcoded in repositories, where they can be easily exfiltrated and are difficult to govern and audit. The shift from AI assistance to AI execution has outpaced how teams manage the secrets needed for execution.
1Password and OpenAI are working together to close this gap. The 1Password Environments MCP Server for Codex makes 1Password the trusted access layer for Codex: credentials are issued just-in-time and scoped to the task, while keeping them outside the model’s context window. Developers get the access they need to build and ship, while secrets stay where they belong. The same integration helps catch secrets at the source. Codex can be prompted to use 1Password and the 1Password MCP to store and use credentials that it needs.
Why secrets should stay out of prompts, code, and model context
Every credential placed inside an agent's context is a credential at risk of easily being exfiltrated. It can be logged, cached, reused across sessions, or surfaced in unexpected outputs. A secure architecture treats a coding agent as a tenant, not a vault: it gets secure access to do its job, but never custody of the secret itself. 1Password Environments is built on that principle. Instead of sharing .env files or hardcoding credential values, teams work from a shared environment where secrets are made available at runtime to the application, without the values ever appearing in code, terminals, or model context.
This secure access model is built on the same vault technology and security architecture used across 1Password. Secrets remain end-to-end encrypted and centrally managed, with access limited to authorized users and groups, and through custom permissions.
This architecture matters more as coding agents take on a bigger share of the development workflow. Any agent that executes code needs credentials, and any credential copied into local files or prompts, or hardcoded into repositories is a credential at risk. 1Password Environments gives teams a way to support these workflows without trading security for developer velocity.
Connecting 1Password Environments to Codex
The integration uses a local MCP server – packaged inside our Password Manager and developer tools – to connect Codex and 1Password Environments, and is available to both 1Password business and personal accounts. MCP connects models to tools and context, specifically with 1Password’s MCP Server for Codex, developers can grant Codex access to credentials directly inside their coding workflows while keeping secrets outside of code. That last part is key: the MCP server here is designed so that Codex can act on secrets without ever seeing them.
Here's what happens when a developer or builder asks Codex to configure an environment:
Start a task in Codex: For example, ask Codex to create an app and configure the environment it needs.
Codex connects to the 1Password MCP server: This happens over a local MCP server connection, where Codex can discover and invoke available actions from instructions the MCP is providing.
Requests are validated through 1Password: The MCP server communicates with the 1Password desktop app, which handles identity, authorization, and secure access.
A user always needs to approve access: Every interaction requires explicit 1Password user auth prompt approval before Codex can proceed.
Codex creates and manages an environment: It can create environments, list and manage variable names, and prepare configuration without accessing raw secrets.
Secrets are used at runtime: Applications run using secrets from 1Password, without copying credentials into prompts, local files, or repositories.
It’s important to note the architectural guarantee: secrets never leave 1Password and are always secure. The MCP server does not read or return secret values through the MCP channel, surface secrets in the model’s context window, or write them to disk. Codex can create environments, list variable names, and invoke applications that use those secrets, but the values themselves never leave 1Password.
Here’s what actually happens at runtime: 1Password injects the required variables directly into the application process when it runs. The values exist in memory only for the authorized process, and only for as long as the process needs them. Codex orchestrates, the application executes, and 1Password issues the credentials.
This integration reflects 1Password’s approach to MCP and agentic workflows. Secrets are securely injected at runtime for an authorized process and users must explicitly authorize access for the scoped task. MCP works best when access is scoped, user-approved, and keeps credentials out of the agent context.
What builders can do with Codex and 1Password Environments
If you’re a developer or builder, this integration is designed to fit into how you already work, while reducing the need to handle secrets directly or copy them into prompts, local files, or repositories. With this integration, developers can:
Bootstrap new projects with 1Password-managed environments so you don't have to create or share .env files.
Allow Codex to create and manage environments so your code runs with the right configuration, while underlying secrets stay in 1Password.
Stay in control of every access since each Codex interaction with 1Password requires explicit user approval.
Use Codex to scan repositories for secrets in plain text, then move these secrets into 1Password for secure storage, and replace them with references in code.
Use Codex to extend environments across stages. Use your local environment as a baseline to help bootstrap staging and production environments.
What this unlocks for engineering and security teams
This integration reduces the overhead of managing secrets in AI-driven workflows, while giving teams more control over how those workflows are adopted.
With this integration, teams can:
Eliminate manual secret cleanup and the context switching it requires.
Move existing secrets into secure storage as part of the normal coding workflow, not as a separate hygiene task.
Support Codex adoption while keeping credentials outside the model’s context window.
Give developers a fast path to AI-assisted workflows while security teams retain oversight of how secrets are accessed.
Centralize secrets in 1Password instead of letting them scatter across repositories, files, and local environments.
Get started with 1Password Environments and Codex
We're launching the 1Password Environments MCP Server with Codex as a proof point for a broader thesis about the future of agent access.
Coding agents are the leading edge of a larger shift: AI agents joining the workforce and needing real access to real systems. Every one of them will need credentials, but none of them should have custody of those credentials. 1Password is building the access architecture for a future where every agent: coding, operational, and customer-facing gets access through the same trusted layer. Codex is where that future starts.
How to turn it on
This new feature is available to all joint 1Password and OpenAI customers with access to our Password Managers and 1Password developer tools.
To get started, visit the 1Password Marketplace listing for step-by-step documentation on connecting Codex to 1Password using the local MCP server.
2026-05-19, 00:00

Design system work follows a well-defined loop: read the ticket, check the Figma spec, find the right component primitives, apply the right tokens, write the Storybook stories, run the tests, open the PR. The steps are consistent enough that when we looked at our design system backlog, we didn't just see a list of tasks; we saw a set of instructions waiting to be executed.
So we set an agent loose on the loop. At first, it was a semi-hot mess. But then we gave it the right context, and boom, it has completely changed how we improve our Design System.
Here’s our approach on what we did and what we learned.
Why we started with our design system
Every team considering agentic coding faces the same question of where to begin. The tempting answer is your largest codebase or your most complex feature. The right answer is wherever the work is most well-specified, and the feedback loop is fastest.
Our React component library, the web layer of our design system, happened to be both. Conventions are strict by design: that's the whole point of having a design system. The output shape is predictable and well-documented: a component, some design tokens, a story, and a test. The blast radius of any change is traceable. And if a token is wrong, the tests catch it automatically, without a human having to notice.
That combination of explicit conventions, predictable outputs, and automatic validation describes exactly the kind of bounded context where agents do well. When we looked at where to prove the pattern before adapting it to larger, messier codebases, the design system was an obvious answer.
What happened when we pointed a general-purpose agent at our design system
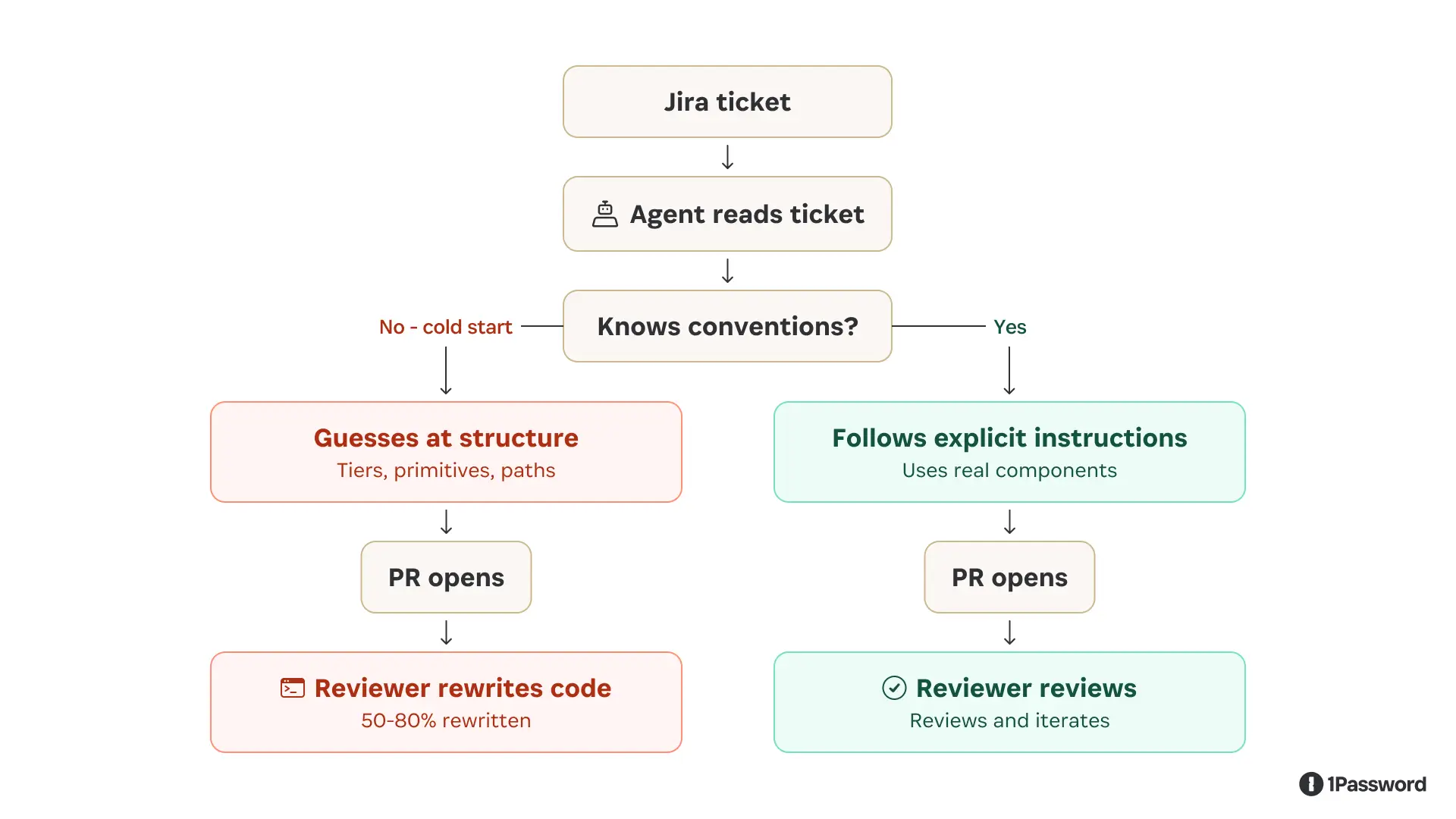
The first attempt was to take a well-scoped ticket, hand it to a capable coding agent, and see what comes out.
The results were instructive, and not in the way we hoped.
The agent could read the ticket and navigate the codebase. But without design system-specific context, it filled knowledge gaps with confident-sounding guesses.
It placed tokens at the wrong tier in the hierarchy. Reached for raw HTML elements instead of the correct component primitives. The agent often chose components that looked right in isolation but were semantically wrong for the system, the kind of inconsistency a developer would catch immediately because it breaks patterns that only make sense in the context of the product as a whole.
It opened PRs that didn't follow the team's merge template; the code was often compiled, and tests even passed, but the output wasn't idiomatic. It was close enough to look right yet different enough that a reviewer had to do substantial correction work before anything could merge.
We hadn't saved developer time by making it easier to open a PR; instead, we'd moved the work downstream.
Without institutional knowledge, the agent’s work was insufficient. It knew how to write React, but it didn't know how our design system writes React: the specific directory structure, the token tier model, the CI conventions, and the component primitives we use instead of raw elements. That knowledge lives in the heads of everyone who works on the system, not in any file the agent could easily read.
The fix: making tacit knowledge explicit with agent skills
The solution was to stop expecting the agent to infer what experienced contributors know implicitly and start encoding that knowledge as explicit, executable instructions.
We wrote a set of skills covering the core design system contributor workflows that included
Scaffolding a new component
Defining tokens
Writing Storybook stories
Adding icons across platforms
Opening a merge request
Debugging a CI failure
Tracing cross-platform impact from a token change
Each skill provides the agent with exact file paths, naming conventions, import patterns, and build commands to make them executable by our agent.
We also exposed Knox through MCP for consumer-facing workflows where agents don’t necessarily have the Knox repo available but still need authoritative guidance on components, design tokens, and interaction patterns. This gave agents a way to ask the design system what exists, how to use it, and which patterns are appropriate without relying on guesswork or outdated copied context.
We folded in our existing builder-facing documentation, including real examples from the product, so the agent could anchor its decisions in consistency. Instead of the agent inferring what's in the system by reading source files, it can ask our design system directly. Our MCP server also added documentation on the user’s intent and the problem a specific component would solve. It enabled the agent to not only make it visually correct but also function as the user would expect in the product UI.
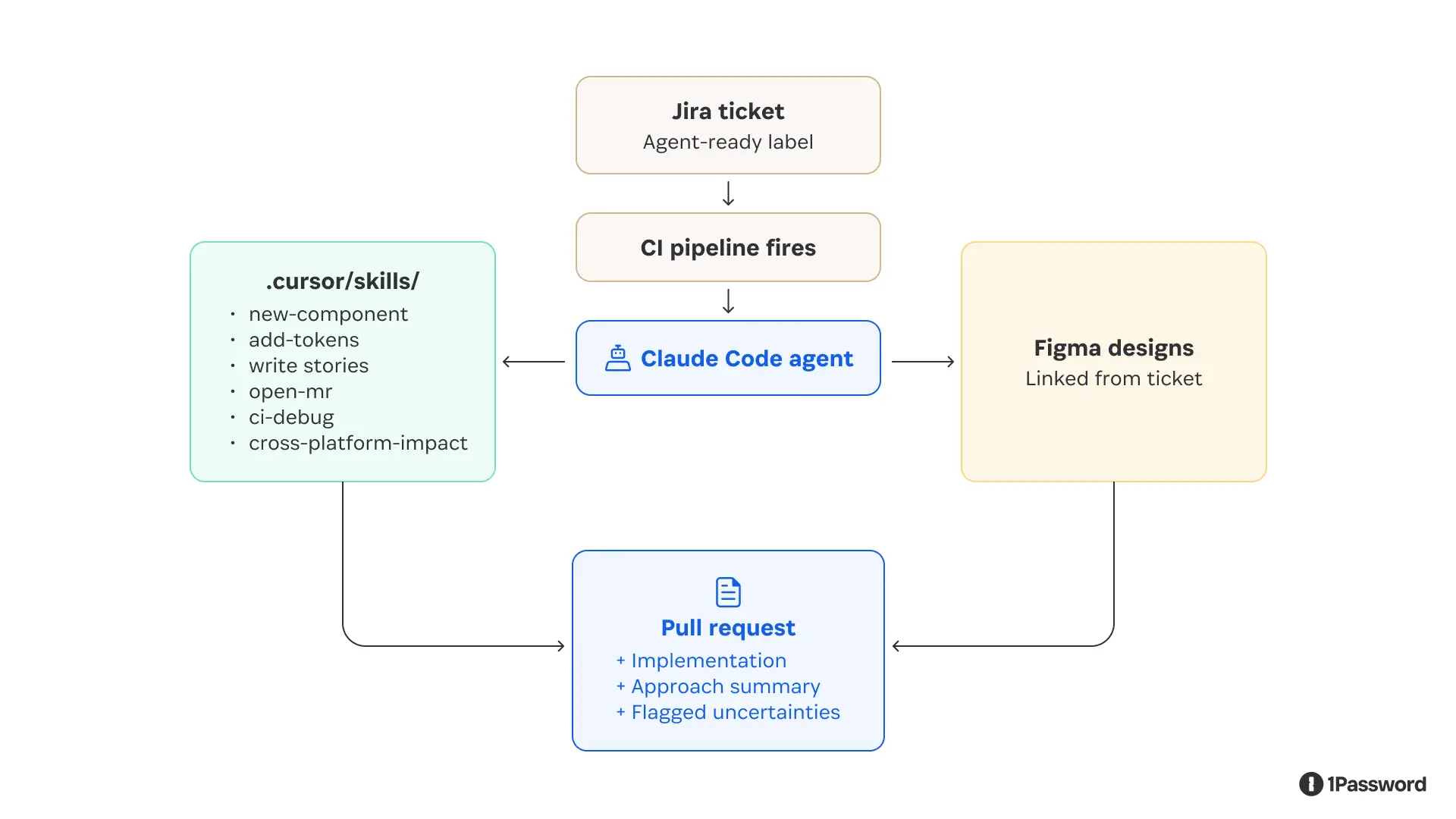
Right away, the agent’s output improved. It stopped guessing conventions because the repeated contributor workflows were now explicit. It had focused skills, clear commands, and a human-qualified ticket to work from.
How to do this for your own design system
This approach generalizes the specific tooling we used, a custom MCP server, CI-triggered runs, and skills committed to the repo can be adapted to any design system with enough test coverage and explicit conventions.
1. Pick the right starting scope
Don't start with your most common ticket type; start with the one you specify most often.
Good candidates:
Adding a component variant
Defining a new token tier
Updating an icon pipeline
Poor candidates:
Broad refactors
Anything that touches cross-team contracts
Work that requires design judgment
Tickets that the system doesn’t capture
A safe guide is that if a new contributor couldn't implement the ticket from the description alone, the agent can't either. The agent's output ceiling is the quality of its input.
2. Write skills, not documentation
Most design systems have documentation that defines what things are, but few have executable instructions written as skills, which tell an agent what to do, in what order, with exact commands.
Write a skill for each atomic workflow your contributors repeat. Keep them narrow; a skill that does one thing well is easier to maintain and easier for the agent to execute correctly than one that covers every case. Commit them to the repo alongside the code they describe, and when a convention changes, update the skill.
3. Match the context layer to the workflow
Agents working inside a well-structured repo can often read source files effectively when they have narrow skills that tell them where to look, what conventions to follow, and which commands to run. For the Jira-to-PR pipeline, the foundation was repo access, explicit skills, and CI review.
Not every agent workflow starts with a full design system repo available. Consumer-facing agents, prototyping tools, and downstream product workflows may still need authoritative guidance.
If your tooling supports MCP, a lightweight MCP server wrapping your component API, token registry, or Figma library data is the right answer. The agent queries it at runtime instead of guessing.
If a full MCP server is out of scope, a well-maintained DESIGN_SYSTEM.md context file that the agent loads at session start accomplishes most of the same goal at lower fidelity and is still significantly better than nothing.
4. Wire the trigger to a human qualification step
The best trigger we found was a ticket label.
A developer reviews the ticket, decides it's well-scoped, applies a label, and the pipeline fires. This keeps a human in the qualification loop while automating everything downstream.
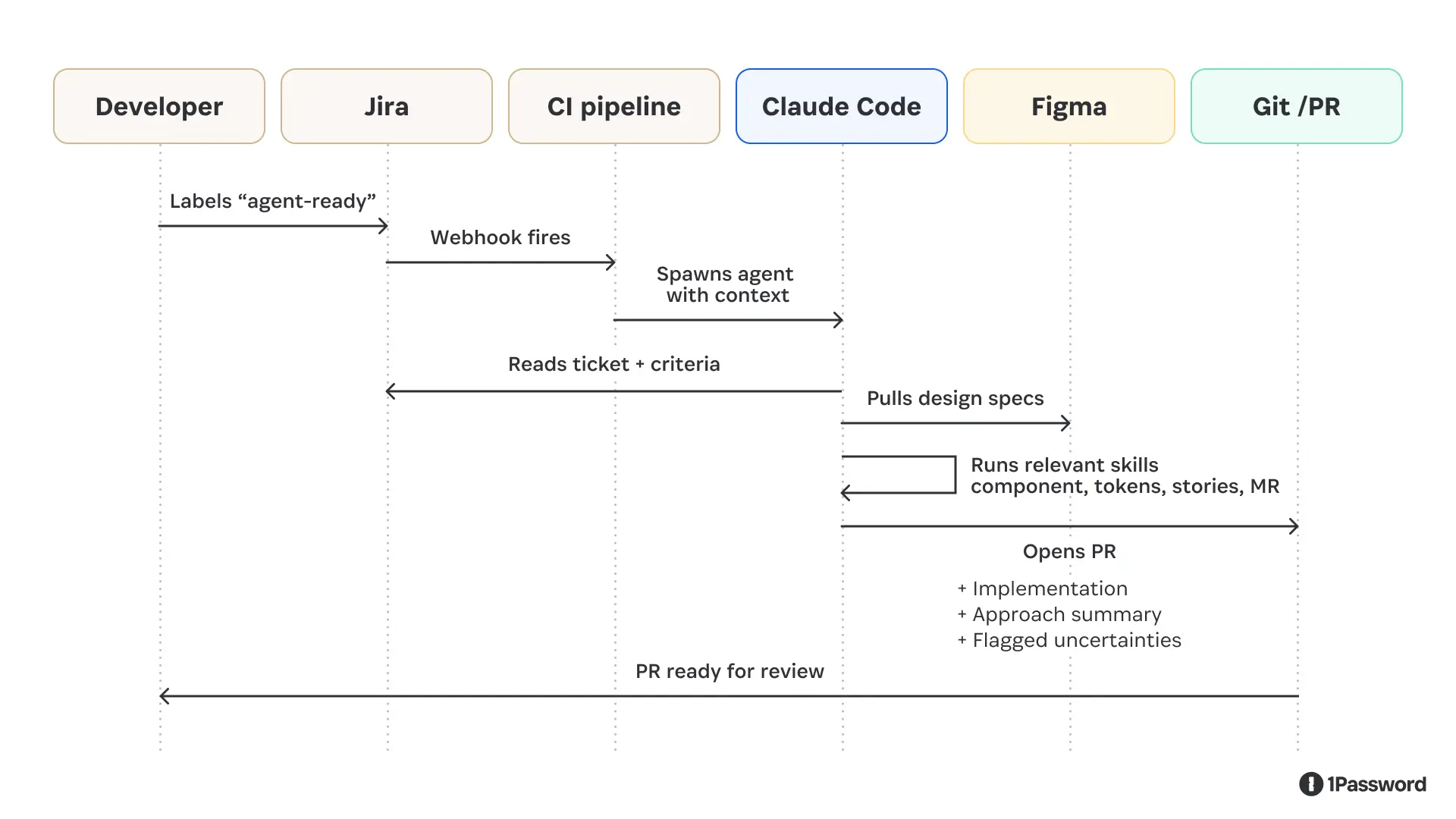
5. Make the agent surface uncertainty
The PR description should explicitly name the decisions the agent wasn't confident about. A reviewer who knows exactly where to look can validate a draft in minutes, but a reviewer hunting for hidden assumptions will spend hours.
We asked the agent to flag uncertainties. For example, a PR that says "I wasn't sure whether this token belongs at the alias or component tier; I chose alias, but please verify" is far more useful than one that looks confident and buries the guess.
6. Measure PR quality before speed
Resist the temptation to lead with velocity metrics. The number that tells you whether the system is actually working is pull request quality.
Start with what percentage of agent PRs need only review and minor tweaks versus a substantial rewrite. A high rewrite rate means you've shifted work downstream, not eliminated it.
Component accuracy is a useful proxy. Does the agent reach for your actual design system primitives, or does it fall back to raw elements when it doesn't know what to use? If it's reaching for raw elements, your MCP context layer isn't working.
What the ticket-to-PR pipeline produces
In our workflow, a developer labels a ticket as ready. Then a few minutes later, a PR opens with idiomatic code, an approach summary, and explicit notes on where the agent was uncertain.
With this context, the reviewer's job becomes iteration, not inception. They're looking at a working draft with known uncertainties called out up front, not a blank editor.
The quality gap between "agent with skills and real design system context" versus "agent reading files cold" is large enough that it felt more like crossing a threshold than an incremental improvement.
Below the threshold, agents generate code that appears plausible but requires significant correction. Above it, they generate drafts that a reviewer can actually build on.
An unexpected outcome: design-led prototyping
While building the ticket-to-PR pipeline, another question came up: could we give designers the same setup our engineers use for rapid prototyping?
Using the MCP-backed Knox context, we built a prototype playground with prebuilt product templates, an agent to query components, and a simple slash command to scaffold a new prototype from scratch, integrating guidance directly into the user workflow.
A designer describes what they want to build or links to a Figma frame, and the agent generates a working interactive prototype using real design system components ready for iteration and feedback. They share it with a deploy link.
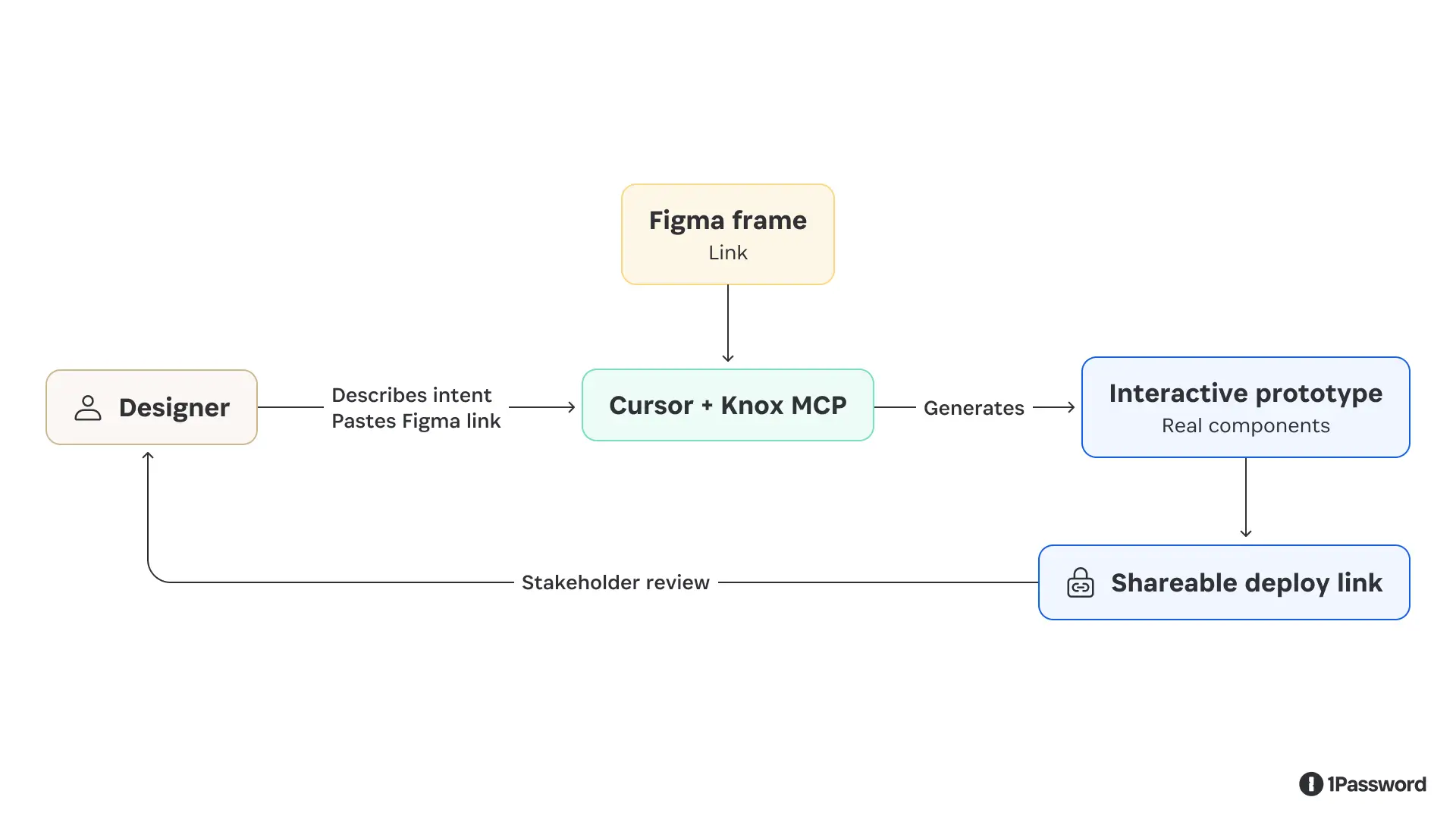
This changed a workflow that previously required developer time into something a designer could run on their own.
A stakeholder review that used to mean a static mockup or a time-consuming Figma clickthrough could now be a clickable prototype built with the actual component library, matching the product's fidelity and interactions.
A few things we learned here that we didn't expect:
Smaller tasks produce better results than large ones ("build the sidebar" before "build the entire dashboard")
Naming components specifically ("use the secondary neutral button") beats describing the desired appearance
Detailed Figma component annotations (size, padding, intended behavior, and states) translate directly into better agent output, because the agent reads that documentation the same way a developer would
What we'd do differently
Ticket quality is not automatable. The agent is a strong implementer of well-specified work and a poor interpreter of ambiguous requirements. The qualification step (a human deciding whether a ticket is genuinely ready) is the most important step in the pipeline, and it can't be delegated to the agent.
Start with the narrowest possible scope. Our early instinct was to write a single "implement a design system ticket" skill. What actually worked was breaking it into eight focused skills that the agent could compose as needed. Narrow skills are easier to maintain, easier to debug when something goes wrong, and easier for the agent to execute correctly.
Treat agent credentials the way you'd treat any machine credential. The design system MCP disconnects after a fixed window, making an agent credential that persists indefinitely a liability. Issuing short-lived, scoped access for agent workflows isn't a UX inconvenience. It's baseline security practice, and it's consistent with how you'd handle any other automated system that has access to your codebase.
Vercel’s design system tooling powers some of the most widely used component libraries in production. Andrew Qu has been tracking how teams are starting to embed agents directly into that layer:
"The gap between design and production has always lived in the component library, where intent either survives or gets lost in translation. With Generative UI, the component library stops being the end of the handoff and starts being the substrate the model renders from. When the model is grounded in what your components are and how they behave, it stops generating one-off UI and starts generating things that belong in your product.”
–Andrew Qu, Chief of Software, Vercel
Design system work will always require human judgment on the questions that influence your product. What's changed is the ratio of that judgment work to the implementation work that follows it.
Agents are increasingly handling the latter. The point is to free the people who understand the system to focus on the work that actually requires human judgment.
Subscribe to the 1Password Developer newsletter
Stay up to date with the latest 1Password Developer product news, industry insights, and community contributions. Plus, learn best practices for becoming a better, more secure developer – both at work and at home.
Subscribe2026-05-19, 00:00

Authentication is built on the assumption that identity can be verified once and trusted for a specified period. Over time, the security industry has gotten very good at validating that trust through a chain of identity providers, certificates, and infrastructure that confirm that a user is who it claims to be at login. Authentication assumes that identity and intent will stay relatively stable and predictable because it was designed for people whose behavior is largely stable and predictable.
Agents break that assumption entirely. They act non-deterministically, starting with one task and expanding their scope as they work, accessing new files and APIs, making their identities difficult to track. When an agent acts autonomously on a person's behalf, the question is no longer whether it can log in; it's how it uses access after it does.
To establish a control plane for agents, Nancy asks, “If you’re a CTO and you’ve been told to deploy internal agents into production, what are the no-excuses minimum controls for identity, authorization, secrets handling, and audit?
Fotis Chantzis, Agent Security Lead at OpenAI, joined Zero-Shot Learning, 1Password’s AI builder podcast, to talk through why the protocols built for human identity don’t hold up under those conditions, and what teams can do to secure agents in production.
Static authorization fails when agents get new ideas
Continuous authorization is the practice of evaluating and enforcing access permissions at each step of an agent's workflow, rather than granting access once at the start of a session.
OAuth and OIDC assume relatively stable scopes and front-loaded authorization decisions. A user signs in, approves access once, and the system moves forward with that grant.
But agents make decisions and take actions beyond the original intent of the person who authorized them.
As Fotis says, "There is no concept of continuous authorization that agents require because an agent starts with one task and then decides that it needs to do something else."
For example, a coding agent might start by accessing local files, then decide mid-task that it needs to browse the web for API documentation. At that point, it writes a new task and downloads the documentation file. Nothing was re-evaluated to determine whether that change should be allowed. An agent can take dozens of these actions in seconds, adding new tools and risk with each move.
A functional identity model for agents must continuously evaluate access as the workflow evolves. Otherwise, teams face the familiar tradeoff of blocking too much and slowing work, or approving too much and holding their breath.
At 1Password, we see the value in continuous, workflow-aware authorization, where access is brokered at runtime, scoped to each action, and enforced at each step through a control layer that mediates how credentials are used.
Nancy framed this as a question of how authority moves between users, agents, and tools: “This brings us to the concept of delegation chains and how we should think about them, scope, duration, thresholds, and the systems those agents are allowed to access.”
Attribution has to survive across tools, runtimes, and sessions
Attribution is the ability to trace every action an agent takes back to the human who initiated it and the authority under which it ran, across every system the agent touches.
Nancy framed the operational challenge directly asking, when an enterprise needs to investigate an incident or audit access, how does it determine which agent actually accessed a system or dataset, and under whose authority?
For agents, attribution breaks as work moves between systems because each step is recorded separately, severing the connection to the original user or task.
Without attribution, we lose governance.”
–Fotis Chantzis, Agent Security Lead, OpenAI
In an incident response scenario, teams work backward from logs to reconstruct what happened. With agents, that quickly becomes difficult. The agent may start in one environment, then call multiple systems, each logging events separately and without shared context.
In one system, the action might appear under a user identity. In another, it shows up as a service account. In a third, it’s tied to an API token. Each step appears valid on its own, but the connection between them isn’t preserved.
Investigators can see the individual steps, but not the full chain of actions or who was responsible for them.
Nancy connected this to a growing need for execution traces that can compare an agent’s intended plan with what it actually did, step by step, across prompts, tool calls, and outputs. For auditing, this proves that the agent operated within the bounds of what it was supposed to do.
A stronger approach preserves attribution at each step, so every action can be traced back to its initiator and the authority under which it was performed.
That shift from reconstructing activity to proving it changes what’s possible in audit and in policy enforcement.
Authority has to be mediated
Mediated credential use means routing an agent's access through a controlled layer (a proxy, gateway, or injection layer) that binds credentials to specific destinations, rather than passing the underlying secret to the agent directly.
The most immediate risk from continuous agent action is how the systems handle credentials.
It's essentially game over if a credential ends up in the context window of the agent."
–Fotis Chantzis, Agent Security Lead, OpenAI
Once a secret is exposed to the model, it introduces the risk of credential exposure, whether through a prompt-injection attack or other, less malicious means. Handing an agent a credential isn't effective delegation.
The alternative is to mediate access rather than hand it over. Systems can route access through controlled infrastructure, such as proxies, gateways, or injection layers, that bind credentials to specific destinations and enforce their use. The agent can request access, but never holds the underlying secret. A compromised agent may still attempt unintended actions, but has far less freedom to abuse the authority granted to it.
The minimum control plane before deploying to production
In the episode, the hosts agreed that the control plane, the system that enforces how access is used across identities, tools, and actions, has to persist as agents act, across systems, over time, and through changing intent.
The baseline looks different from human access controls:
Credentials have to be short-lived and scoped to the task, not granted broadly and reused
Execution has to be constrained by the environment, not assumed to behave
Secrets can’t be exposed to the model; they have to be mediated at the point of use
Every action has to be attributable back to both the agent and the human who delegated it
Policy has to be enforced continuously, so intent drift is detected before it becomes an incident
Authentication still matters, but it can’t carry the full load. Identity tells you who delegates an agent; it doesn’t control what happens next.
Teams can't wait for standards to catch up
But IT teams don’t have the luxury of waiting. Agents are already operating in production.
Agentic security is still a moving target. To secure agents today, teams need continuous authorization, attribution, and mediated access. The standards agents will rely on around identity, delegation, and authorization are still evolving. Extensions to OIDC, verifiable credentials, and cross-provider delegation models are in development but not yet ready.
In the meantime, most teams aren’t waiting for a perfect model. They’re adapting existing controls, tightening credential lifetimes, introducing mediation layers, and treating agents as first-class machine identities with explicit boundaries.
Watch the full episode with OpenAI’s Fotis Chantzis
Fotis, Nancy Wang, and Jeff Malnick go deep on continuous authorization, attribution, and what it takes to secure agents in production on Zero-Shot Learning, 1Password's AI builder podcast.
Watch now2026-05-18, 00:00

AI coding tools have changed who builds software. The barrier to entry has dropped to the point where a designer, an analyst, or a first-time founder can turn an idea into a working app in an afternoon. That shift is real, and it's accelerating.
But every app needs to talk to something. Every API call, database connection, and automated workflow runs on secrets: API keys, tokens, SSH keys, service account credentials. And those secrets have to live somewhere.
For most people building with AI tools today, secrets end up in a .env file, a chat message, a script, or a note that will "definitely get cleaned up later." AI coding tools are good at helping you get something working fast, but they tend to suggest the fastest path to a functioning prototype, not the most secure one. The result is real credentials stored in plain text, scattered across machines and codebases, hard to track and easy for threat actors to find when a machine is compromised.
This is how credential sprawl starts. Not with a dramatic failure, but one unknowing shortcut at a time.
Developers rely on secrets management tools: Now AI builders need them too
Until recently, managing developer credentials was mostly a concern for engineering teams with the time and expertise to configure dedicated tooling. The people who generate secrets have historically been developers trained in secure coding.
Today, that's changed. Designers are prototyping internal dashboards. Operations teams are automating repetitive tasks. Data analysts are connecting pipelines to interactive graphics. Founders are shipping their first apps without engineering teams. None of them signed up to become cybersecurity experts, but they're now handling some of the most sensitive credentials and secrets in their organizations, often without a clear path to doing it safely.
The new wave of AI builders are frequently seeing directions from their vibe coding tool to either put plaintext credentials into a .env file on the computer desktop or store them in a secrets manager. The former is the most risky way to manage secrets, and the latter is the most secure. That is why every AI builder needs a secrets manager.
Secrets management tools are already in 1Password
1Password is where millions of people store their most sensitive information. What you may not know is that every 1Password subscription already includes a full set of developer security tools.
SSH Agent, the CLI, SDKs, environments, service accounts, and secret references are all part of 1Password. They let apps, scripts, and AI coding agents pull secrets from 1Password at runtime rather than hardcoding them into code or configuration files. Service accounts handle automation without requiring shared personal credentials. The CLI and SDKs mean good security can be part of the build process from the start, not something you retrofit when a prototype moves into production.
1Password's developer tools have been part of the product for years. But keeping secrets secure shouldn't require knowing which corner of the app to look in, whether you're a senior engineer, a data analyst, or someone who shipped their first app last month. Making these tools visible to everyone gives all builders the same starting point.
What's changing
Developer tools are now visible in the 1Password desktop app sidebar for all users, matching the experience already available in the browser extension.
We've also rebuilt our developer documentation. The new quick start guides are organized around what you're trying to do, not how the product is structured:
Developer quickstart: common setups, step by step
Admin quickstart: what's available and how to roll it out across your organization
Workflow guides for SSH and Git, developer secrets, deployments, AI access, and building integrations
Admins retain full control over how these features are used across their organization.
How you can use 1Password developer tools today
With 1Password developer tools, you can already:
Store and use SSH keys without keeping them on disk
Keep secrets out of code and .env files using 1Password environments and secret references
Use the CLI and SDKs to access credentials at runtime, including from AI-assisted build workflows
Create service accounts for automation instead of sharing personal credentials
Connect secrets into CI/CD pipelines without exposing them
These tools are included in your existing subscription. There's nothing additional to buy or deploy.
The secure path should be the obvious, easy path
AI tools have made building faster than it's ever been. The cost of that speed, if we're not intentional about it, is secrets scattered across machines, codebases, and chat logs that nobody is tracking, and credentials that remain valid long after a prototype becomes a production system.
1Password was built on the idea that security works best when it's the easy choice, not an extra effort on top of the work you're already doing. Making developer tools visible is a small change in the interface with a clear purpose: make the secure path the obvious one, so more builders will take it.
If you want to see how this fits into your team's development workflows, join us on June 10th for a live webinar on developer credential security. Or check out thequick start guides and see how it fits into what you're already building.
2026-05-14, 00:00
Today we're releasing the 1Password Device Trust MCP Server, an open-source server that connects your Device Trust data directly to the AI tools your team already uses, like Claude or ChatGPT. It's available now for all customers on Device Trust Connect.
As AI agents take on more of the work across your organization, IT and security teams need visibility and control that keeps pace. The Device Trust MCP Server is part of how 1Password is extending that control to the way security teams actually work today, inside AI tools, in plain language, with every action logged and auditable.
Once it's running, you can query your entire device fleet without leaving your AI client. Which devices have disk encryption off? Who owns the machines failing compliance checks? How long does it typically take to resolve a specific issue across the fleet? Instead of navigating dashboards or writing custom scripts, you just prompt.
What is MCP, and why does it matter?
If you use AI tools like Cursor or Claude, you may have already come across the Model Context Protocol (MCP). MCP has become the standard way to connect LLMs and AI agents to data sources and tools. It’s an open standard that lets AI tools connect to external data sources and take action on your behalf, with built-in controls over what those tools can access and do. It's supported by every major AI platform, and the ecosystem has grown from around 1,200 servers in early 2025 to over 6,400 today. IT and security practitioners are increasingly doing their work inside AI-powered tools, and MCP is what makes those tools useful for real administrative workflows.
The Device Trust MCP Server plugs your device security data into that ecosystem. Instead of switching between tools, admins can stay in their AI client of choice and get answers in seconds.
What you can do with the Device Trust MCP
Once connected, you can ask questions like:
"Which devices are currently failing checks?"
"Who owns the devices with disk encryption disabled?"
"Which of my devices are vulnerable to this CVE?"
"Which devices have the most Chrome extensions installed?"
"Show me all macOS devices running outdated versions of ChatGPT."
"What's the average time to resolve issues for this check?"
The server covers the full Device Trust API surface across 59 tools, including devices, people, issues, checks, audit logs, live queries, exemption requests, and reporting tables. Smart features like auto-pagination, field projection, and device-owner enrichment make it easy to pull complete, clean answers without extra steps. And because it's part of the broader MCP ecosystem, it compounds with your other AI integrations, combining device data with security intelligence, identity, or ITSM sources to answer questions no single tool could on its own.
How the Device Trust MCP server works
The MCP Server runs locally on your machine and binds to localhost by default, so your Device Trust data stays in your environment. Setup takes a few minutes and boils down to three steps:
Clone the open-source repo
Set your Kolide API key and MCP authentication (bearer) token as environment variables
Start the server and connect your AI tool (Claude, Cursor, or any MCP-compatible client)
From there, your AI tool handles translating natural language questions into the right API calls and returns clean, human-readable answers. Every invocation is logged for auditability, and all endpoints require bearer token authentication.
Full setup instructions are available in this support document.
Built for the way IT and security teams work with AI
1Password Device Trust already detects AI tools running on your endpoints. Now it gives security teams AI-native tooling to manage those endpoints too.
This server is a part of 1Password's broader investment in AI across our product suite. It joins the MCP Server for 1Password SaaS Manager, which provides SaaS visibility and governance data to AI agents. Together they reflect one of 1Password’s bedrock security principles: AI agents should work with your data in a way that's useful, auditable, and secure, without ever exposing credentials or sensitive secrets.
You can get started with 1Password Device Trust MCP Server here, or learn more about Device Trust on our product page.
2026-05-12, 00:00

1Password has never been more popular in the workplace. Okta’s 2026 “Businesses at Work” report reveals that, of the 8,000+ apps that Okta analyzed, “The security tool 1Password showed the highest industry-level growth, notching a 370% YoY increase in the technology sector.”
This statistic refers specifically to the number of individual 1Password users on the Okta platform, indicating a sharp increase in the rollout and adoption of 1Password across business users.
This growth is no coincidence. As 1Password becomes foundational to how employees build and operate AI-powered workflows, it is increasingly embedded in the critical path of the modern “AI builder.” The result is a surge in demand for secure access across tools, credentials, and agents, starting in the technology sector and expanding outward.
What drove 1Password’s growth on Okta's platform?
The stated purpose of Okta’s report is to: “...track how enterprise technology adoption continues to evolve, and… how identity strategies must evolve alongside it.”
1Password’s dramatic growth among Okta customers reflects our company’s evolution. Our innovations in AI and agentic security are resonating deeply with enterprise customers, many of whom are seeking to adapt their identity security strategies to securely enable AI across their workforces and technology stacks.
Okta’s report also reveals that agentic AI is an urgent need, since 91% of the organizations they surveyed are using AI agents. The majority of those orgs, however, are in early or limited stages of agent deployment. It’s not hard to understand why; the identity and access risks posed by AI can significantly hamper a company’s ability to fully integrate agents into their workflows.
Businesses have historically had limited ability to manage these risks or enforce company policies around AI use. 1Password’s 2025 Annual Report found that one in four employees has used AI applications that weren’t approved by their company, and over a third of employees admit to having knowingly disregarded their company’s AI policies. Employees regularly adopt shadow AI tools that can expose sensitive information in a variety of ways, and AI agents are an entirely new class of identities that present novel risks. As security analyst Francis Odum puts it, “Because existing access solutions were not designed for dynamic, probabilistic machine identities…This leads to over-privileged agents, limited auditability, and elevated data loss risk.”
1Password has been making significant moves to enable businesses to embrace AI without sacrificing security. In the past year, this has included launching partnerships with AI leaders like Cursor, developing an AI Agent Security Benchmark to help businesses understand and manage the risks of different AI models, and deepening integrations between 1Password Enterprise Password Manager (EPM) and 1Password SaaS Manager to help teams manage shadow IT and AI.
Most significantly, we recently launched 1Password® Unified Access, which lets teams discover, secure, and audit access across humans, agents, and machine identities, enabling organizations to adopt AI confidently and securely.
1Password’s growth in the past year has been driven by our proven dedication to building the next layer of AI security, and that growth trajectory is only being accelerated through new and upcoming tools like just-in-time credential access for agents, secrets management for AI builders, and more.
Strong security foundation accelerates growth
1Password’s rapid growth was reflected at other points within Okta’s report; we are the fastest growing app in Canada, and ranked 13th on the list of “most popular apps” within the startup category. As Okta puts it, “If the fastest growing apps represent new momentum, the most popular apps are the familiar platforms companies rely on, year after year.”
In short, what this report indicates is that 1Password’s growth is being driven not only by our recent innovations, but by our strong foundation and reputation for security. Our rapidly growing number of users on the Okta platform is a testament to how deeply our offerings and principles have resonated with the modern enterprise.
This is only the beginning. 1Password’s commitment to serving the ever-evolving needs of our customers will continue to drive our innovation and growth in the years to come.
Want to see our innovations in action? Explore 1Password Unified Access.
2026-05-12, 00:00

This blog has been adapted from an excerpted section of 1Password’s ebook, Credential sprawl: How AI increases the risks. To read the complete ebook and learn more about how AI is accelerating credential sprawl, click here.
In Ancient Rome, the military had a daily “watchword” that soldiers used to enter the camp. An official would inscribe the watchword on clay tablets, which were distributed throughout the various military units. If a tablet wasn’t returned, they swiftly tracked it down and punished the soldier who had failed to return it.
Clearly, one thing has been true from Ancient Roman times until now: if you want to stay secure, you need to know where your passwords are.
Unfortunately, keeping track of credentials is more difficult for a modern organization. Today’s companies have to manage an ever-growing number of credentials that go well beyond traditional passwords, such as developer secrets, passkeys, shared logins, API keys, SSH keys, service accounts, and SSO access tokens.
This problem is especially urgent due to the rise of AI-based tools and agents, which have not only increased the scale and scope of unmanaged credentials, but also present access and identity management challenges that tools like SSO and PAM aren’t equipped to handle.
Credential sprawl tends to quietly accumulate across systems, often going unaddressed until a breach exposes the vast web of risky, unmanaged access. In this blog, we’ll make a case for addressing this issue proactively, by examining all the ways it extracts a cost from companies.
What are the risks and costs of credential sprawl?
When credential sprawl runs rampant through a company, the costs manifest in a variety of ways, from an increased blast radius in the event of a breach, to time-consuming manual processes to manage security posture, compliance, and incident response.
Compliance failures
IT and security teams are consistently faced with the difficult task of achieving and proving compliance with regulatory standards like SOC 2, PCI DSS, ISO 27001:2022, and HIPAA.
Each of these standards has requirements related to the secure use and storage of credentials. For instance, PCI DSS requires that, “Audit logs capture all changes to identification and authentication credentials…”
SOC 2 similarly has various requirements related to how companies provision access to credentials, including requirements dictating that “Your organisation should implement processes to remove credential access when an individual no longer requires such access.”
With the increasing need to manage how AI and agentic AI access and store credentials, it’s worth noting that SOC 2 extends their requirements not only to user credential access, but to how “internal and external infrastructure and software” access credentials.
Regulatory bodies, on the whole, expect companies to prove that they’ve done their due diligence to protect sensitive information. “Due diligence,” in the case of managing credentials, means implementing essential tools to give admins oversight over where and how credentials are being used. Credential sprawl fundamentally undermines a company’s ability to do so.
Furthermore, regulatory bodies aren’t likely to cut companies any slack. If anything, they’re increasing their scrutiny. As Itamar Apelblat pointed out in an article for BleepingComputer, “In each of these frameworks, the organization is accountable for what happens to regulated data and regulated workflows. When AI agents are the ones acting inside those systems, accountability doesn’t disappear.”
Risk exposure
Compliance standards place so much emphasis on credential and access management because credential sprawl greatly increases an organization’s risk of cyber attack, and attackers are eager to take advantage of it.
Compromised credentials are the single most common entry point for attackers, and have been for some time; 50% of CISOs who’ve experienced a material breach in the last three years identified compromised credentials as a root cause.
Credential sprawl significantly increases a company’s attack surface. Each credential that’s stored without security and IT oversight presents an opportunity for bad actors to breach systems, particularly backend credentials like OAuth tokens and API keys, which often have broad permissions, and which are now being used by AI agents. And with automation and AI adoption spreading so rapidly, companies are facing more risk than ever.
In 2025, IBM reported that shadow AI accounted for 20% of breaches, and 97% of AI-related security breaches involved AI that didn’t have proper access controls. IBM also points out, “...that data was most often stored across multiple environments, revealing just one unmonitored AI system can lead to widespread exposure.”
Incident Response
Breach remediation and incident response are already costly and time-consuming processes. Credential sprawl is only worsening these issues, as breaches involving data stored across multiple environments take the longest to resolve.
As TechTarget reported, NHIs and agentic AI complicate this issue further: “Since many organizations use NHIs to link cloud environments… secrets are often duplicated or reused across multiple systems, making remediation and rotation difficult if a single identity is compromised.” Shadow AI, for instance, adds more complexity and cost to breach response; a breach involving shadow AI can cost up to $670k more than a comparable breach that didn’t involve it.
According to GitGuardian, 70% of secrets that were leaked in 2022 were still valid in 2025. That’s a deeply worrying figure, indicating that compromised credentials aren’t being remediated by any standard business process; they’re not expiring automatically or being rotated by teams.
How can organizations manage credential sprawl?
Managing credential sprawl requires a multi-pronged effort that addresses the myriad types of credentials and places they can live.
Secrets management for AI and business-led IT
Broadly speaking, credential sprawl often comes down to the push and pull between security and productivity. The rise of AI has placed this conflict in stark relief: employees, and developers in particular, adopt AI to improve productivity. They often see security tools as intrusive blockers to their improved workflows.
1Password doesn’t just improve secrets management for developers; it removes friction. 1Password’s developer tools let teams securely vault secrets and make them available at runtime as developers code, so that they can work securely without interrupting workflows.
When it comes to agentic AI use, 1Password has also taken steps to let teams take advantage of the benefits of AI-assisted coding without ignoring the risks. Our Cursor integration “... gives developers a secure, just-in-time way to ensure required secrets are made available to Cursor’s AI agents via 1Password Environments. The result is an AI-native development workflow where… secure access becomes a natural part of writing and running code.”
1Password® Unified Access also includes shadow AI discovery, enabling IT and security teams to discover and manage the use of unapproved AI apps or local agents across their ecosystem. This is just the beginning, as 1Password is building a new foundation for runtime access governance for AI agents and machine workloads.
This is the next frontier of credential management: governing not just who logs in, but how software identities authenticate, operate, and persist across environments.
Credential management
As the analyst and researcher Francis Odum reported, “1Password’s architectural anchor is its Enterprise Password Management (EPM) core. This zero-knowledge vault serves as the singular ‘system of record for all workforce credentials,’ spanning both human users and non-human identities (NHI)...”
Modern credential management platforms, such as 1Password, secure more than passwords, and are a mission-critical tool for companies to rein in credential sprawl and manage agentic AI use. 1Password’s EPM centralizes visibility into how credentials are used, allowing admins to enforce principles of least privilege through role-based vault access. Structured onboarding and offboarding workflows mean that users are only given access to the credentials, passkeys, and secrets that they need to do their jobs. And critically, EPM extends protection into developer workflows and AI-powered automation without introducing friction.
Since credentials are encrypted, teams can ensure that they can’t be accessed by infostealers and other targeted attacks. 1Password's breach monitoring also informs users and admins as soon as possible if a managed credential has been compromised.
It’s worth noting an essential element of EPM’s efficacy: credential governance must be deployed wall-to-wall. Businesses have to enforce credential management for every person, agent, secret, and workflow. Companies cannot stay secure by only protecting part of the identity surface.
How to manage credential sprawl and its costs
Credential risks are hardly a new issue. However, in recent years, managing where and how credentials are used has evolved from a Herculean task to a Sisyphean one. That is to say: it was never easy, but at some point it became close to impossible. Teams are faced with an ever-growing number of credentials across an ever-growing number of endpoints and apps. Credentials are hidden in codebases, Slack messages, AI chatbots, spreadsheets – and they probably still find a home on a sticky note or two.
Credential management has never been more difficult, but it’s also never been more crucial. In blunt terms: every unmanaged credential puts your ecosystem at risk. If credentials aren’t being secured wall-to-wall, then your business can have untold numbers of unsecured access points.
Credential management has been an essential (though often neglected) part of security for years, and it has only become more pressing with the rapid rise of AI. 1Password is the critical solution for companies to control how credentials are used across their ecosystems. By building on the strong security of our password manager, we’re creating systems that will let teams manage credentials wherever they may be, from the spreadsheet to the AI agent.
There’s never been a better time to start managing credential sprawl. Reach out for a demo.
2026-05-07, 00:00

Introducing new features in 1Password Enterprise Password Manager – MSP Edition to reduce client onboarding effort and give MSPs greater control over policies, access, and usage.
Setting up and managing client environments often involves repetitive, manual work. Each new managed company requires policy setup, access configuration, and ongoing oversight. Repeating this across environments slows onboarding, introduces inconsistencies, and makes it harder to maintain control.
To address this, 1Password is introducing Policy Templates, Seat Limits, and Granular Vault Permissions in 1Password Enterprise Password Manager – MSP Edition to reduce repetitive setup, enforce consistent access controls, and give MSPs greater control over client license usage.
Apply consistent policies from the start
Setting up policies for each client’s environment individually is time-consuming and increases the risk of inconsistencies. Policy Templates for MSPs allows owners, administrators, and MSP administrators to define and enforce policies once, then apply these policies across all or selected managed companies. With Policy Templates, teams can:
Create reusable policy configurations for multiple clients
Enforce consistent baseline security and access policies
Centrally update templates and apply changes across environments
Control which policies clients can or cannot override
These templates reduce manual setup during client onboarding and ensure each managed company environment starts from a consistent security baseline while still allowing flexibility where needed.
Keep client usage predictable and aligned with contracts
As clients grow, usage can quickly exceed initial expectations or contracted limits. Without clear controls, MSPs may only discover overages after costs have already increased. Seat Limits for managed companies allow MSPs to set and enforce a maximum number of users or guests that can be given licenses. With Seat Limits, MSP teams can:
Align client usage with contracted agreements
Prevent unplanned overages
Maintain predictable margin and cost structures
Proactively plan for growth discussions as client usage increases
Control access without slowing down support
Supporting clients requires access to their environments, but that access shouldn’t be broadly granted. Granular Vault Permissions within managed companies give MSPs and their clients precise control over who can access shared vaults. Managed companies can choose to give MSP technicians no default access and only assign access to specific vaults or assign access by role to support least-privilege access.
With granular, role-based vault permissions, MSPs can work with their managed companies to:
Limit shared vault access to only the technicians who need it
Assign access based on roles or specific users
Maintain least-privilege access across client environments
This ensures technicians only access what’s needed to support clients while reducing unnecessary exposure. It also helps MSPs and their clients maintain stronger control over sensitive data sharing.
Built for how MSPs manage client environments
These capabilities are built for how MSPs manage client environments, from onboarding new clients to enforcing policies, managing user growth, and controlling access to client data. By reducing repetitive work and improving control, MSPs can onboard clients more efficiently and maintain consistency across every client environment.
These features are now available in 1Password Enterprise Password Manager – MSP Edition. Existing customers can start using these new capabilities through the MSP console. New MSPs can start a free 14-day trial to explore these capabilities in 1Password today.
2026-05-07, 00:00

The proliferation of credentials outside centralized visibility and control is known as “credential sprawl,” and attackers are eager to take advantage of it.
Unfortunately, credential management is a broad problem that only grows in complexity as organizations add new tools, employees, and partners. Today’s companies have to manage an ever-growing number of credentials that go well beyond traditional passwords, such as developer secrets, passkeys, shared logins, API keys, SSH keys, service accounts, and SSO access tokens. Each of these, if exposed in an attack or breach, can have severe consequences, and developer secrets pose particular, systemic risk.
Addressing credential sprawl has become especially urgent due to the rise of AI-based tools and agents. AI agents are a primary driver of credential sprawl because they create, use, and replicate credentials at machine scale. They have unique access needs and can behave both autonomously and unpredictably. Companies that want to integrate AI-based tools must carefully consider how to mitigate these risks to avoid an exponential rise in unmanaged and vulnerable credentials.
How do AI agents increase credential risk?
AI agents increase credential security risks through their reliance on non-human identities like API keys and service accounts, which are frequently overprivileged, long-lived, and poorly audited. Agents create and use these credentials at machine scale, beyond centralized oversight, leading to rapidly expanding credential sprawl with limited oversight for security teams. And while AI tools and agents pose new and distinct risks, they’re also expanding on credential problems that have existed for years, stemming from SaaS sprawl, shadow IT, and unsafe developer practices.
Traditional security tools are falling behind
As security analyst Francis Odum shared in his enterprise identity security report, “As organizations increasingly adopted SaaS applications, the need for enterprise-grade password management became more pronounced. Employees frequently relied on personal credentials for work accounts, increasing the risk of credential reuse and security incidents. While Single Sign-On (SSO) and Multi-Factor Authentication (MFA) became standard controls, they often failed to cover the full range of enterprise applications, leaving visibility gaps…”
In its research report, 1Password found that the average company has a third of its apps outside SSO’s protection. Our report also noted that, “One major indicator of how SSO is falling short is the amount of access that comes from employees whom IT believed to have been successfully offboarded. Over one-third (38%) of employees have successfully accessed a prior employer’s account, data, or applications after leaving the company.”
Now, AI is accelerating SaaS sprawl even further beyond what SSO was built for. 1Password’s research also found that 1 in 4 employees has used AI applications that weren’t approved by their company, and over a third of employees admit to having knowingly disregarded their company’s AI policies.
Employees are experimenting with AI coding tools, browser extensions, writing assistants, data analysis tools, and agent platforms, often before IT has evaluated or approved them. Many of these tools don’t integrate cleanly with enterprise SSO, and even when they do, adoption frequently begins outside official onboarding processes. Shadow AI poses serious risks, as even innocuous apps can contain security flaws that expose company data and credentials.
Each unmanaged app and AI tool represents at least one unmanaged credential that an organization can’t secure. And as the number of unmanaged credentials grows, so does the likelihood that one is exposed, overprivileged, forgotten, or used to create a direct path to unauthorized access. The result is an ever-expanding layer of applications and credentials that exist outside centralized governance.
Unmanaged AI agent access
AI agents represent an entirely new class of identities; they require varying levels of access, and they operate in ways that are frequently invisible to security tools.
As The Hacker News put it, “AI agents don't operate in isolation. To function, they need access to data, systems, and resources. This highly privileged, often overlooked access happens through non-human identities: API keys, service accounts, OAuth tokens, and other machine credentials.”
All NHIs pose credential risk – over-privileged service accounts, for example, have been putting CI/CD pipelines at risk for years – but the way that AI agents use them has increased their sprawl drastically. Figures vary, but in 2025, there were somewhere between 82 – but potentially up to 144 – non-human identities (NHIs) for every 1 human identity in the average enterprise environment. Regardless, that number is growing fast.
More concerning is the fact that many of these machine identities have highly privileged levels of access, often without the level of scrutiny that would typically be applied to highly privileged users. In fact, a recent study found that 1 in 20 NHIs carries full-admin privileges even though only 38% of total NHIs had been active within the last 9 months.
What this means is:
AI agents are being given access to these highly-privileged NHIs.
That access is often going unmanaged by security teams, who may not be able to differentiate it from normal activity.
Agents can retain this access after it is needed, use it in ways that are harmful, or expose it via prompt injection or other forms of compromise.
Together, these behaviors create a rapidly expanding layer of credentials that exist outside centralized identity systems.
Agentic applications and capabilities are evolving at unprecedented speed, and new tools are often being adopted before their risks are understood. Jason Meller, VP and Security Strategist at 1Password, wrote two blog posts on how powerful – and frightening – these tools can be.
“The short version: agent gateways that act like OpenClaw are powerful because they have real access to your files, your tools, your browser, your terminals, and often a long-term ‘memory’ file that captures how you think and what you’re building. That combination is exactly what modern infostealers are designed to exploit.”
–Jason Meller, Vice President and Security Strategist, 1Password
While OpenClaw certainly garnered some attention, its issues aren’t isolated to one tool alone. In MIT’s “AI Agent Index,” researchers found that the majority of agent developers share little about their tool’s security. “25/30 agents disclose no internal safety results, and 23/30 agents have no third-party testing information.” OpenClaw is an indicator of how severe the security risks can be when AI agents are given unmanaged levels of access; its popularity, and its security risks, have quickly forced security teams to reckon with the fact that the standard enterprise perimeter is not equipped to handle the issues of agentic AI.
AI worsens credential security practices
AI-based tools are also exacerbating credential sprawl by replicating poor credential security practices.
Vibe coding (using generative AI to write code) tends to reproduce poor security habits. For example, one largely vibe coded platform, Moltbook, was quickly found to have a misconfigured database within it that exposed over a million API authentication tokens, along with email addresses and private messages.
Again, this isn’t exclusive to a single platform. GitGuardian analyzed the use of Copilot – Microsoft’s AI assistant (used for vibe coding, among other things) – and they found that repositories with Copilot active are 40% more likely to have at least one leaked secret.
Vibe coding can also enable employees with less coding experience, and therefore less coding security training, to push through code that hasn’t received the standard checks and scrutiny.
Developer secrets, meanwhile, pose their own security challenges. Secrets sprawl is a particularly dangerous subset of credential sprawl; developer credentials tend to live outside of traditional identity security systems, and developers often hardcode secrets into code for simplified access during their workflows. If these hardcoded secrets aren’t discovered during security or access reviews, they pose serious threats to company security, as seen in a recent Uber breach, which began when the hacker “...located a PowerShell script with hard-coded privileged credentials for Uber’s Privileged Access Management (PAM) solution…”
Unfortunately, hardcoded secrets are only growing as a problem. GitGuardian’s 2025 report, The State of Secrets Sprawl, shows how rapidly this problem is accelerating. “In 2024, we found 23,770,171 new hardcoded secrets added to public GitHub repositories. This figure represents a 25% surge in the total number of secrets from the previous year.” As they put it, “secrets sprawl is steadily worsening over time.”
Secrets sprawl can spread in a number of ways, including when developers accidentally expose secrets in public-facing code. However, GitGuardian’s report highlights a more basic concern: “[while] source code management tools have been the primary focus of secrets detection… secrets appear wherever teams collaborate, often in collaboration and project management tools like Slack, Jira, or Confluence.”
Plaintext secrets being sent through apps like Slack represents a dangerously lax approach to secrets hygiene. Unfortunately, cybercriminals are aware of this trend. Dark Readingreports that“...cybercriminals and nation-state actors alike are following a proven playbook and capitalizing on ‘bad secret hygiene’ to further their campaigns.”
AI is now accelerating this dynamic. As developers use AI copilots to generate code, spin up infrastructure, or automate workflows, machine credentials are created and reused at greater speed. All of this is expanding the identity surface far beyond what traditional identity and access management (IAM) and privileged access management (PAM) systems were designed to govern.
Traditional identity security is falling behind
Monitoring how employees use and store credentials has always been challenging. But AI fundamentally changes the identity security model.
AI tools and agents don’t authenticate, store, or use credentials the way humans do. They rely on embedded tokens, API keys, service accounts, and programmatic access patterns. They operate continuously, duplicate easily, and often persist long after their original purpose has ended.
Traditional identity security tools were designed for human behavior, with interactive logins, session-based authentication, and clearly defined privilege tiers. They were not designed to govern autonomous software identities that scale and authenticate programmatically without supervision.
In a way, this is almost by design. As Saumitra Das put it in an article for Corporate Compliance Insights, “By nature, autonomous agents are trained to find the easiest and most efficient way to complete the assigned job. This means that they can often identify ways around guardrails…”
Traditional access control methods are quickly proving to be inadequate, as AI and event-driven automation create NHIs at a scale we haven’t seen before. As TechTarget reported, “Most legacy IAM and privileged access management (PAM) tools were never designed to handle that level of volume and churn.”
The article goes on to point out some of the issues related to how NHIs use credentials, including:
NHIs use a broad array of authentication methods, like JSON tokens, cloud IAM roles, OAuth2 secrets, and API keys. Each of these has its own unique security needs.
NHIs are often given outsized access and long-lived credentials so that teams can ensure the tool will have the access needed to automate various business processes.
Anomaly detection can’t always notice when something has gone wrong with an AI agent, since they don’t really have “normal” behavioral patterns to deviate from.
Each of these factors can seriously damage the efficacy of a company’s security stack.
How can teams manage credential sprawl for agents?
Traditional IAM tools and strategies cannot manage the (sprawling) issues of credential sprawl, especially in a world where so much access isn’t coming from people at all. Rather, teams will require a multi-pronged effort that approaches the problem from multiple angles.
Unified access management for AI Agents and humans
AI-related credential sprawl reflects a fundamental change in how authority is delegated inside the enterprise. AI systems are no longer tools that assist humans; agents increasingly act with independent access to applications, data, and workflows. Yet most access controls still assume a human at the keyboard.
Employees, and developers in particular, are encouraged to adopt AI to improve productivity, but without purpose-built tools to safely delegate access to agent and machine identities, workers resort to unsafe workarounds outside the reach of traditional security tools. Addressing AI-related credential sprawl requires tools that govern non-human access without slowing down workflows.
1Password® Unified Access helps teams create a framework to:
Discover risk: Identify unmanaged AI tools and agents running on developer and end-user devices, and detect credentials and secrets stored in local files and developer environments.
Secure credentials: Vault exposed credentials and remove access for risky AI tools and agents. Deliver credentials to agents, automation, and CI/CD at runtime to reduce long-lived secrets and ensure they’re used only when needed.
Audit agent actions: Gain clear attribution for every action, showing when and how credentials are being used and who’s using them across humans, agents, and machines.
SaaS management
Credential sprawl and SaaS sprawl are irrevocably intertwined. For IT and security teams to effectively determine where and how credentials are being stored, they need to know what applications their employees are using.
The unfortunate nature of SaaS sprawl, though, is that it’s next to impossible for teams to find the time or resources to take control of it manually.
1Password SaaS Manager solves this problem through automation. With over 40,000 app integrations, it lets teams build and maintain a complete inventory of the apps their employees use – including the apps that can’t be secured behind SSO. That includes capabilities for continuous app discovery to illuminate the use of shadow IT – and shadow AI apps – across an organization.
With automated onboarding and offboarding workflows, teams can also ensure that employee access to apps is provided only when needed, without running the risk of unapproved access from improperly offboarded employees.
Identifying which applications are in use, whether they’re company approved or not, is a critical step to making sure that every credential is being used and stored securely. A team cannot achieve wall-to-wall credential security if any part of their application surface is going unmanaged.
AI is here: do you know where your credentials are?
Credential sprawl is far from a new problem. But rather than improving, it only seems to be getting worse, as teams are faced with an ever-growing number of credentials across an ever-growing number of endpoints and apps. Credentials are hidden in codebases, Slack messages, AI chatbots, spreadsheets – and they probably still find a home on a sticky note or two.
An updated and enforceable credential management strategy has never been more crucial. In blunt terms: every unmanaged credential puts your ecosystem at risk.1Password is the critical solution for companies to reign in and control how credentials are used across their ecosystems. By building on the strong security of our password manager, we’re building systems that will let teams manage credentials wherever they may be, from the spreadsheet to the AI agent.
Want to learn more? Read the full ebook on AI credential risk management. Ready to start managing credential sprawl? Reach out for a demo.
2026-05-06, 00:00

Security is tied to business operations in many (often unappreciated) ways, but the connection is rarely more visible or consequential than during an acquisition or partnership. In those deals, a company stakes its reputation and finances on another company, and a lapse in security can throw the whole thing into chaos.
That’s the subject of this episode of Chasing Entropy, in which Dave Lewis talks with Matt O'Leary, 1Password’s Vice President of Corporate Development and Strategic Partnerships. They discuss what changes about M&As and partnerships when security is tied directly to the product, the brand, and the deal itself.
Caveat emptor in M&As
O’Leary’s core idea is simple: when a company makes an acquisition, it inherits the whole business, not just the part that looked attractive in the pitch. That includes the technology, the team, the process gaps, the legal exposure, and any security weaknesses that were not obvious at first glance. O'Leary makes the case that strong dealmaking starts with risk discipline, because a transaction only creates value if the company can integrate what it buys without importing problems that slow everything down.
He also explains that good corporate development starts with the roadmap, not the deal. An acquisition makes sense when it helps the company move faster than building on its own. That is why corp dev has to stay tightly aligned with product, engineering, and security leadership. In a cybersecurity company, technical diligence carries extra weight. If a target has a serious security or technology issue, that is not a detail to clean up later. It is a reason to walk away.
Go as deep as you possibly can, before you cut the proverbial check…If there is any major issue with the technology, if there is any significant exposure to cybersecurity risks in a company we are targeting, those are deal killers.” - Matt O'Leary
The risks and rewards of partnerships
The conversation also sharpens the distinction between partnerships and acquisitions. O'Leary argues that deep partnerships can create major leverage because they expand reach, increase product value, and connect a platform to the tools customers already use. But they also transfer risk. If two companies are tightly integrated, trust becomes shared. A failure on one side can damage both. In that sense, partnerships may be lighter than acquisitions, but they still demand the same seriousness around diligence, reputation, and customer impact.
When you’re doing an integration partnership, you’re tying your brand, and the trust that you stand for with another company’s. So you really need to be thoughtful about how you go about that.” - Matt O'Leary
After the deal: integration and communication
One of the strongest parts of the episode is the discussion about integration. O'Leary is clear that post-close integration is the hardest part of M&A. Retaining key people, understanding founder motivation, aligning technical architecture, and planning how products and teams will come together all matter before the announcement, not after. Dave Lewis brings home this lesson by sharing a story of a botched M&A, where the acquiring company failed to lock in the engineering staff. “We had the big celebration party and none of the engineering team were there, and we were like, ‘What’s going on?’”
He also emphasizes the importance of customer communication, since M&As can raise questions and trigger concerns. “You want to communicate to customers that the standards that we apply to ourselves – that are the reason they bought our product – are the same standards that we will apply to the new product and service that we have acquired.”
For anyone interested in corporate development, O'Leary’s advice is direct. Curiosity matters more than a fixed career path. The best operators learn across functions, ask better questions, and build enough context to understand how product, security, legal, and finance decisions connect. For founders, his advice is just as clear. Build relationships with corp dev teams before you want an outcome. Trust and credibility take time, and good deals depend on both.
Subscribe to Chasing Entropy
Subscribe to Chasing Entropy for honest, expert-led conversations on agentic AI, security, shadow IT, and extended access control from industry leaders.
Subscribe now2026-05-05, 00:00
A password manager should make everyday tasks feel simple.
Whether that's:
Saving a new password
Signing in on your phone
Finding the right item
Moving your data from another password manager
We’ve made a set of updates across 1Password in our latest release to improve exactly these moments. Let's get into it!
A direct way to move your credentials into 1Password
Switching password managers hasn’t always felt straightforward. Exporting sensitive data into files, moving them yourself, and importing them again adds friction and risk.
We’re improving that with a direct credential transfer.
This work is part of the Credential Exchange Protocol (CXP), an industry effort to make credential migration more secure and interoperable. We helped author the FIDO Alliance’s Credential Exchange Format (CXF), a proposed standard that defines how credentials like passwords, passkeys, and other sensitive data can be structured and transferred safely between providers.
For you, this means a simpler experience on both iOS and Android, letting you move your credentials into 1Password without relying on manual export and import, and eliminating the need to handle sensitive files yourself.
Get your Autofill setup working smoothly on Android
Currently, Autofill on Android depends on several system settings, and when something isn’t configured correctly, it’s not always clear what the problem is or how to fix it.
So we’ve made this easier. 1Password now brings those settings into one place and checks them for you. You can see at a glance if something isn’t set up correctly, like Autofill not being enabled, the wrong service selected, or a required permission turned off. For each issue, 1Password explains what’s wrong and takes you directly to the right Android setting so you can fix it. You can also see a simple summary of your setup, so you know whether everything is working as expected or if something needs attention.
All of this can be found on the home screen of 1Password by navigating to Help > Autofill health check.
Instead of digging through menus or guessing what’s broken, you get clear, step-by-step guidance to get Autofill working again.
Smarter login item creation from the start
We’ve improved how new login items are created in 1Password. When you add a login, you can now search for the service you’re saving and 1Password will automatically fill in key details like the correct name, website, and icon.
For example, instead of saving a login as “login” or a long URL, it can be saved as “Instagram,” with the right website and icon already in place. You can still edit anything before saving. But now it takes less work to create a clean, complete item from the start.
That means your vault is easier to scan, easier to search, and easier to use over time.
Updates built with usability at the core
At 1Password, we spend a lot of time thinking about how it feels to use our products, from the big features to the small moments.
When our users tell us that we’re a reliable and easy part of their lives, that’s a huge win for us.
So let us know what you think about these updates on X, Instagram, and Reddit, and stay tuned for our next set of updates in the next one.
2026-05-04, 00:00

The latest National Institute of Standards and Technology (NIST) draft guidance on mobile driver’s licenses (mDLs) is about more than one use case or credential type. While the draft primarily focuses on the financial sector due to its high-assurance requirements, the bigger takeaway is that government-issued identity can be cryptographically verified and shared more selectively. This provides strong, cryptographically verifiable evidence of identity and shows what a more interoperable digital identity ecosystem could look like
1Password has contributed to the work behind this draft. We believe that identity systems need to be developed through global standards and collaboration across multiple verticals. Open ecosystems scale; closed ones often fail.
mDLs replace document uploads with cryptographic verification
An mDL is a government-issued verifiable digital credential. It serves as the digital version of your physical driver’s license, defined as a highly specified mobile document (mDoc) under international standards.
To identify a person with cryptographic trust, the ecosystem relies on three parties:
An issuer that signs the credential
A wallet that securely stores and presents it
A verifier that checks its authenticity
A simple real-world example is airport security, where the DMV is the issuer, your Apple Wallet is the wallet, and the TSA is the verifier when you present your mDL.
While this might sound more complex than simply flashing a physical ID, the experience can be seamless when implemented well. Historically, users had to upload an image of their driver’s license, which exposed their sex, address, weight, and other unnecessary personal data. With an mDL, you securely transmit only the attributes needed for that interaction.
For example, you would only expose the state you live in to qualify for services, nothing else in a well defined flow. mDLs turn automated online verification from an image processing problem into a cryptographic verification problem.
How an mDL standardizes high-assurance identity needs
At a high level, the mDL flow operates in a few simple steps:
A state issuer, like the DMV, verifies your identity and issues a digitally signed credential to your wallet.
Later, a verifier, like a bank, asks for specific identity attributes.
You authenticate locally on your device (e.g., using Face ID or a fingerprint) and consent to share the data.
The relying party receives a cryptographically verified result, rather than a raw image upload.
While the NIST architecture is focused on high-risk transactions in banking, account application and digital enrollment, this pattern can be applied to many other business verticals.
One area of the draft we focused heavily on was NIST’s decision to prioritize the W3C Digital Credentials API and avoid custom URI-based wallet invocation. This approach ensures that users clearly see which site is making the request and what attributes are requested, while also enabling CTAP-based proximity protections for cross-device flows. From our perspective, the ecosystem should converge on interoperable standards rather than ad hoc wallet-invocation workflows or the creation of proprietary protocols. Fragmented standards lead to more complicated implementations and a poorer user experience.
Our view is that this architecture works best when mDLs are used at key trust moments, such as identity proofing and high-risk transactions. Once that trust is established, the user can provision a purpose-built authentication method, such as a passkey, for everyday access
Standards make trust functional
We align with the NIST draft's goal: the industry must converge on interoperable standards, not custom integrations or fragmented protocols.
The digital identity ecosystem is a mix of published standards and still-evolving specifications like ISO 18013-5/7, W3C Verifiable Credentials, the Digital Credentials API, OpenID for Verifiable Presentations, and OpenID for Verifiable Credential Issuance. This work spans multiple standards bodies and communities, and 1Password has been contributing heavily to the organizations driving these protocols, including FIDO, W3C, and OIDF.
Because we build both consumer and enterprise security products, we are in a unique position to complete the feedback loop between standards formulation and actual product development. For this ecosystem to succeed, the rough edges for users, browsers, and wallets need to be worked through in the standards process in real time.
This work also requires alignment across different global jurisdictions. We are keeping an eye on the EU Digital Identify (EUDI) wallet work and other related regulatory work to inform future product decisions.
What mDLs suggest for the future of digital wallets
Over time, we expect the line between a traditional "password manager" and a digital "wallet" to keep getting thinner.
A modern wallet should do more than store passwords, credentials, or personal information. It should be able to protect a broader set of high-value credentials in a way that is secure, privacy-preserving, and easy to use across all your devices. That includes the kinds of government-issued credentials emerging in the mDL ecosystem.
This is one reason this space is so interesting to us. The long-term opportunity is far bigger than one single credential type or one specific industry. It’s about helping people seamlessly prove the right thing, to the right party, at the right time, without oversharing or adding unnecessary friction.
Putting identity in the driver’s seat
NIST started with the financial sector because it is a high-assurance environment facing fraud pressure and strict compliance requirements like the identity-proofing components of Know Your Customer (KYC). Finance is just a starting point. We highly recommend reading the draft and applying these learnings to your own industry's problem space.
mDLs are not a silver bullet, but they are a meaningful shift in how digital identity can work online. Cryptographically signed credentials are much harder to fake than document images, and standards-based workflows improve both usability and security.
That’s why 1Password is participating in this work. We believe in global standards. We believe digital identity should be controlled by the individual. And we believe the best systems will be those that give people greater control over their data while improving security and privacy.
Move from identity verification to everyday authentication
Curious what this looks like in everyday authentication? Passkeys make sign-in easier for users and stronger against phishing, without adding extra friction.
Explore passwordless2026-05-01, 00:00

Whether you’re juggling travel bookings with friends or packing the kids’ suitcases, planning a summer vacation can be far from relaxing. And once you get to your destination, the confirmation codes and passport numbers are always buried in the group chat when you need them most. But when you have all your travel essentials saved securely in one place, you can skip the scramble and put safe travels on autopilot.
Before you take off this summer, check these tips to keep your information safe and your trip on track.
Before you leave
Set up strong account passwords. Your personal information lives in a host of accounts, from airlines to hotels to car rentals. Make sure all of that stays secure by using 1Password to generate and save unique passwords for every account.
Securely store travel details. Shared travel information, like passport numbers and Airbnb codes, shouldn’t get lost in a group text. Store them in a shared vault in 1Password so everyone can access them safely and seamlessly.
Back up data for easy access from anywhere. If your phone gets lost or damaged during your travels, you’ll need an alternate way of accessing your critical data. Keep copies of sensitive documents and your digital wallet in 1Password so you can access that information from any device with your recovery code.
Organize vaults for Travel Mode. When in use, 1Password’s Travel Mode lets you remove selected vaults from your device. If you have any sensitive information unrelated to your trip, you can move it to a designated vault to keep it private while you’re in transit.
Turn on two-factor authentication (2FA). It’s always a good idea to have an extra layer of protection on your accounts, but especially so when you’re traveling. 1Password identifies accounts that don’t yet have 2FA and also functions as an authentication app for one-time passcodes, so you can easily add that second layer of security.
During your trip
Use Nearby Items for seamless check-ins. We all know the pain of standing outside a vacation rental frantically searching for the entry code. Add locations to saved items in 1Password and they will automatically appear at the top of your app when you get close.
Turn on Travel Mode. If you organized your vaults in 1Password before leaving, turn Travel Mode on once you’ve left home. Only the vaults you marked safe for travel will be visible, so you can protect your privacy on the road and in the air.
Turn off Face ID. Removing biometrics like Face ID adds another layer of security while you’re traveling. Make sure to set up a strong password or passcode for your phone instead.
Set shorter auto-lock windows. Minimize how long your phone and apps like 1Password remain unlocked. If you get separated from your phone during your travels, these settings can prevent others from gaining access to your accounts.
After you return
Delete unnecessary apps and accounts. If you downloaded any apps or added any accounts for your trip that you don’t need at home, delete or close your accounts before deleting the apps. A breach of a dormant account can take longer to notice and address.
Review statements for unknown charges. While you’ll have charges from new merchants and potentially in new currencies, it’s best to check accounts even after you’re home for any unexpected charges. The earlier you report a suspicious transaction, the better.
Check your password health. Double check that all of your accounts are protected with strong passwords. 1Password’s Watchtower automatically monitors accounts for compromised passwords and sends alerts when they need your attention.
Your vacation will end, but the habits you build for safe, smooth travels don't have to. Passwords for family streaming services can live in shared vaults. Credit cards and your home address can be safely stored for faster autofill when you’re online shopping. With the right tools to keep your accounts organized and secure, you can put your digital life on autopilot, too.
2026-04-30, 00:00

If cybersecurity teams were rock bands, offensive security professionals would be the cool drummers; they don’t just have a fun job, they help show the rest of the team where to go.
In this episode of TheChasing Entropy Podcast by 1Password, Dave Lewis speaks with a legend of offensive security, Dustin Heywood, known to many as EvilMog. Heywood is an executive managing hacker and senior technical staff member at IBM, and the conversation runs the gamut from password cracking and Active Directory abuse to AI privilege creep and quantum planning. The through line is simple: most security failures start with access, trust, and bad assumptions about how systems behave under pressure.
Heywood’s background explains why he sees the problem this way. He came up through network engineering, military communications, enterprise infrastructure, and offensive security. That path matters because his view of security is operational, not theoretical. As he continually reiterates, businesses are not trying to be secure for the sake of security. They are trying to keep operating, and security has to support that goal or it gets bypassed.
Rethinking access for the agentic world
A big part of the episode focuses on the risks of agentic AI, although Heywood argues that AI is exposing access problems that were already there. He runs through some of the weaknesses he encounters in his day-to-day job that AI agents are set to exploit, like overpermissioned service accounts and broad integrations.
Heywood’s main concern, and where he sees the biggest opportunity to make a difference, is the gap between identity and intent. He gives the example of a person using an agent to buy concert tickets at a specific time and with a specific budget, but
A user might want an agent to buy concert tickets under a clear budget and time window, but today’s systems rarely encode that level of permission. In practice, the agent often gets broad backend access and can do far more than the task requires, to the detriment of both the human user and the ticket company.
I think we need to overhaul identity management as a whole [to adapt to agentic AI]…We don’t have an intent-based authorization process right now, and that's where we need to go.” - Dustin Heywood
That leads to the episode’s strongest point about machine identity. Most organizations still think about access in terms of human users. That model does not hold up when a company has thousands of employees and tens of thousands of machine identities tied to services, devices, integrations, and automation. If those identities are overprivileged, an AI layer on top of them becomes a force multiplier for existing risk.
Quantum mania?
The discussion then shifts to quantum threats, and Heywood takes the issue from abstract future risks to concrete concerns. He is less focused on dramatic “decrypt everything later” scenarios and more focused on the systems around the data. If quantum-capable attacks weaken the trust layers behind OpenID Connect, SAML, certificate authorities, VPN certificates, and federation systems, attackers do not need to break every encrypted file directly. They can go after the identity and key infrastructure that grants access. That is the planning problem security leaders need to understand now.
His advice on crypto agility to prepare for quantum computing is practical. Start with inventory, know where cryptography lives in your environment, how certificates are issued and renewed, and what would have to change if a major algorithm or trust model becomes unusable. He also points out that many companies still struggle with certificate management at a basic level. If certificate rotation is manual, the organization is already behind. Automation is not optional here.
Stronger credentials shouldn’t mean added friction
On credentials, Heywood takes a hard line that is worth adopting: assume every password entered into a remote system will eventually leak. That changes the goal from “password theater” to unique credentials, automated rotation where possible, stronger storage, and lower user friction. If security makes daily work harder, people will work around it. His advice for security leaders is to strengthen weak and legacy encryption, start being more aggressive about clamping down on overpermissioned admins, and simplifying security wherever possible.
Talk to your employees about friction in your environment. Eliminate friction spots in security and focus on how you can be a business enabler.” - Dustin Heywood
Security leaders who are dealing with AI adoption, identity sprawl, legacy authentication, or PKI debt should definitely listen to the episode. Heywood is refreshing because he treats security as a systems problem tied directly to business operations and user behavior.
Subscribe to Chasing Entropy
Subscribe to Chasing Entropy for honest, expert-led conversations on agentic AI, security, shadow IT, and extended access control from industry leaders.
Subscribe now2026-04-30, 00:00

AI has gotten very good at generating answers. The bigger opportunity now is helping people take action.
That shift is already underway, and AI is moving from chat into real workflows: researching, navigating applications, and completing multi-step processes across systems. But the moment AI moves from answering questions to getting things done, one problem becomes impossible to ignore: secure access.
Secure access, in this context, means ensuring the right human or AI agent can reach the right application or credential at the exact moment an action is taken without exposing sensitive data or stopping the workflow to ask someone to log in manually. Every meaningful agentic workflow depends on this, but most existing access protocols weren't designed for it.
That's why we're expanding our partnership with Perplexity, by making 1Password’s secure access capabilities seamlessly integrate with Perplexity Computer.
AI agents are a new kind of actor in enterprise systems
Perplexity is building an orchestration platform that coordinates models, tools, and connectors to automate complex work. As Perplexity Computer operates across enterprise environments, access stops being a convenience question and becomes a trust question.
Consider what this looks like in practice: It's mid-March at a twelve-person CPA firm, and twenty new clients have dropped off boxes of files. In past years, the junior staff would spend ten days logging into Chase, Fidelity, Coinbase, and a dozen other portals one client at a time. This year, the senior CPA hands the intake list to Perplexity Computer. The agent asks 1Password for each credential, pulls the 1099s, logs into the IRS practitioner portal, files the extensions, and drops everything into UltraTax. The credentials never touch the model; the CPA spends her fourteen hours reviewing returns instead of typing them, and the firm takes on six more clients than last year because the bottleneck moved.
That's what Perplexity Computer does. And 1Password helps execute these workflows quickly and securely.
"We're focused on expanding what AI can do on a user's behalf," said Dmitry Shevelenko, Perplexity's CBO. "To do that effectively in the enterprise, secure and seamless access has to be built into the experience from the start."
AI agents don't behave like humans. They operate probabilistically, persist across workflows, and act at machine speed. A single workflow might touch a browser session, a system login, a token, and a service credential all in sequence, with all requiring different permissions. Without a secure way to provide agents access, you're either slowing the workflow down with manual authentication or accepting credential sprawl as the cost of moving fast. Neither works at scale.
What 1Password and Perplexity are building together
In the next phase of this partnership, we're working toward a model where access is provisioned dynamically as part of the workflow itself. A human stays in control by defining what should happen and what's allowed by the agent executing the work, but every action remains authorized, governed, and auditable. Crucially, credentials are never exposed to models or prompts.
This builds directly on 1Password® Unified Access, our recently released platform for discovering, securing, and auditing access across human, machine, and AI agent identities. Expanding the Perplexity partnership is a direct demonstration of how Unified Access works in practice. "Our partnership with 1Password helps ensure that as we expand what AI can do, we're doing it in a way organizations can trust," Shevelenko added.
The diagram below illustrates how 1Password Unified Access grants secure access to Perplexity's agent, without directly exposing credentials to it.
Security and productivity have long been framed as a tradeoff, but they don't have to be. If AI is going to deliver real value in the enterprise, the secure path has to be the easy path. That is what we're building together with Perplexity.
2026-04-23, 00:00

For security teams, credential sprawl is like dust; you don't notice it until it has accumulated.
Over time, access spreads across SaaS apps, developer tools, automation workflows, and now AI agents. People sign up for tools to get work done and connect accounts using OAuth because it is fast and familiar. Credentials get reused across scripts, stored in environment variables, or passed between systems that were never meant to share a common control layer.
The problem only becomes visible when you zoom out and realize that all these individual decisions have created a network of external dependencies that now sit on top of your internal access model.
That is where credential sprawl turns into a supply chain risk. Add enough overpermissioned OAuth connections and suddenly, access to your internal systems is at the mercy of the security posture of every third-party service that has been granted access along the way.
What is the attack chain for an OAuth-based supply chain brief?
Recent incidents have shown how this access pattern can turn into a breach.
Here’s how it has played out:
An employee connects a third-party tool using Google Workspace OAuth.
The permissions are granted through a standard consent flow.
At some point later, that third-party service is compromised.
The attacker obtains the token and uses it to access internal systems.
There is no need for the attacker to bypass authentication, because the token is valid. There is also no need to escalate privileges, because the permissions are already in place.
What makes this type of attack so insidious is that, from the perspective of most security systems, the hacker’s activity does not appear anomalous. The requests are authenticated, the client is recognized, and there are no failed login attempts or obvious indicators of abuse. The attacker is operating within the boundaries that have already been approved.
The issue here is that trusted access has been extended into an environment that sits outside of direct control.
Preventing it requires knowing which connections exist, ensuring access is granted only at the moment it is needed, and maintaining a clear record of who or what used it and when.
Managing the risk of overpermissioned tools in Google Workspace
Every time someone clicks “Sign in with Google” or “Sign in with Microsoft” on a new app, they are creating a new trust relationship between their company and a third-party service. In many cases, that happens without any formal review from security or IT. The scopes granted during that flow are often broader than people realize, and once the token exists, it tends to persist quietly in the background.
Over time, these connections add up. Some are actively used, others are forgotten, and very few are tracked continuously.
The pace of shadow IT adoption has only increased with AI tools, where the fastest path to value usually involves connecting directly to existing accounts. 1Password's research found that more than half of employees download apps without IT approval. OAuth makes that easier than ever: connecting a new tool takes one click and leaves no footprint in your identity provider's app catalog. And when it comes to third-party AI integrations, access can rapidly go from "benign" to "breached".
How to check your exposure to OAuth-based supply chain attacks
Before getting into architecture or long-term fixes, let’s go over some advice you can use right now.
If you are using Google Workspace, you can see which third-party apps currently have OAuth access:
Go to Security → API controls → App access control
Review the list of connected applications
Look for apps with broad scopes or unclear purpose
It's a quick check, but it answers an important question: what has access right now.
While you are there, it is also worth tightening the default posture. Limiting unconfigured apps to basic profile information reduces the impact of new connections that happen without review.
Replacing point-in-time checks with automated OAuth discovery and secrets rotation
The kind of review we shared above is useful, but it does not solve the underlying issue, because the set of connected apps is constantly changing. New tools get added, old ones linger, and the same pattern repeats with different services over time. Looking at a single snapshot only tells you what exists at that moment.
But you can change that with a few shifts that bring visibility and control closer to where access already happens.
First, treat discovery as an ongoing process rather than a periodic audit. The inventory of connected applications changes every time an employee signs up for a new tool, grants additional permissions, or stops using something without revoking it. A review you ran last quarter does not tell you what connected yesterday. The goal is a continuous view, so that risk prioritization is based on what exists now, not what existed the last time someone looked.
Second, look at how long credentials live. Many tokens remain valid far longer than the task that required them. Shortening that window changes the economics of an attack. A token that expires quickly is far less useful if it is exposed. For OAuth connections specifically, Google Workspace admins can set token expiry policies directly in the Admin console. For agent and automation credentials, the answer is issuing them at the moment of use through a credential broker rather than distributing long-lived secrets in advance.
Third, keep environments separate. Credentials used in development workflows should not carry over into production systems. Even basic separation limits how far access can travel if something goes wrong.
Fourth, reduce how often credentials end up in uncontrolled places. In practice, they show up in scripts, environment variables, and application contexts more often than teams expect. Moving toward centralized storage and issuing access at the moment it is needed helps contain that spread.
Finally, pay attention to how access is used after it is granted. Most detection systems are designed to catch failed attempts or obvious anomalies. They are less effective when valid credentials are used in ways that do not match normal behavior. Building a baseline of expected activity for machine identities makes those deviations easier to spot.
How 1Password helps prevent supply chain attacks
1Password is designed to make your access surface visible and manageable.
1Password SaaS Manager provides a continuous view of the applications connected to your environment, including those added through OAuth. When an employee connects a new tool using "Sign in with Google," SaaS Manager surfaces that connection automatically: the app name, the user who authorized it, the permission scopes granted, and a risk rating based on how broad those scopes are.
Security teams can review connections directly in the dashboard, revoke access with a single action, and set policies that restrict new connections to basic profile scopes by default. The inventory updates continuously, so the view reflects what exists now, not what was audited last quarter.
With 1Password Unified Access, credentials and secrets will be discovered and stored in a centralized system rather than spread across scripts and local environments. As credential brokering capabilities come to the platform, access will be issued at the moment it is needed, which reduces how much standing privilege exists at any given time. Every action tied to a credential can be traced back to who or what used it.
Going forward, teams will continue adopting new tools and OAuth will remain the default way to connect them. Credentials will continue to move across systems unless something is done to contain and govern that flow.
The work is not in preventing every connection or third-party tool, but understanding where those connections exist, how much access they carry, and how that access is being used over time.
FAQ: Protecting Your Supply Chain from Credential Sprawl
Q: What should I do if a third-party AI tool I use is compromised? A: Revoke the OAuth token in your Identity Provider (Google/Microsoft) immediately, rotate any credentials the tool had access to, and audit your internal logs for unauthorized requests using that tool’s Client ID.
Q: Why are environment variables a supply chain risk? A: Many platforms don't encrypt "standard" environment variables at rest. If an attacker hijacks a trusted integration's token, they can read these secrets in plain text, leading to a cascade of further breaches
Q: How do I find out which third-party apps have OAuth access to my Google Workspace?: Open your Google Admin console and go to Security → API controls → App access control → Manage Third-Party App Access. This lists every application that has been granted OAuth access by users in your organization, along with the permission scopes each app holds. Look specifically for apps with access to Gmail, Drive, or calendar data that were never formally reviewed by IT. You can revoke individual app access directly from this view. For ongoing monitoring rather than a one-time check, SaaS Manager automates this inventory continuously and flags connections with elevated or risky scope grants.

2026-04-22, 00:00

Cyber conflict is easiest to misread when we treat it as an isolated technical event. In this episode of Chasing Entropy, Dave Lewis speaks with analyst and author Allie Mellen about her book Code War and why the cyber strategies of the United States, China, and Russia make more sense when viewed through the lens of history, doctrine, and political intent.
From the Gulf War to Russia’s war in Ukraine, cyberattacks are most effective when they reinforce defined objectives within a larger campaign and help a state apply pressure, gather intelligence, or shape the environment around a conflict.
History shapes cyber strategy
A nation’s cyber strategy is rooted in its political history and military doctrine.
Mellen traces the US approach to a culture of experimentation and technical tinkering. China’s cyber ecosystem emerged from hacktivism and state-linked talent pipelines. Russia’s path was shaped by the post-Soviet collapse, when cybercrime became tied to survival and later overlapped with state interests.
Those origins still influence how each country organizes teams, chooses targets, and pursues advantage. Countries do not enter cyberspace as blank slates. They bring older power habits with them, and those habits continue to shape how cyber campaigns are built and used.
That is the first step to decode cyber conflict. The tools may be technical, but the logic behind them is familiar. States still pursue leverage. They still coordinate across different forms of power. They still use whatever tools best support their goals.
Mellen also pushes back on the way cyber conflict is portrayed in pop culture, often appearing as code on screens and elite operators in high-tech rooms. That framing misses the larger story. One of the more memorable examples in the episode is her discussion of how WarGames helped push US policymakers to take computer security more seriously in the 1980s. Public narratives matter, even when they get parts of the story wrong.
Attribution defines intent
This is where the conversation becomes especially useful for security teams.
Mellen argues that defenders need to understand who is behind an operation, not just what malware was used. Attribution helps explain motive, likely targets, and what may come next. It helps distinguish between disruption, intelligence gathering, and influence activity, which changes how defenders prioritize response and what they watch for next.
That matters for governments, but it matters for enterprises too. Security teams build better threat models when they understand how a group typically operates and what it wants. Technical indicators still matter, but they are more useful when paired with context about intent.
This is also where the episode connects to a broader shift in the security landscape. As more activity is delegated to automation and AI systems, defenders need better ways to understand who acted, under whose authority, and toward what goal. The attribution problem is becoming more central.
AI makes deception cheaper and attribution harder
The episode closes on AI with a sober tone. Mellen sees real value in automation, especially when it speeds up workflows and reduces manual effort. She also points to a growing challenge: AI lowers the cost of deception, makes false flag activity easier, and adds friction to attribution.
That raises the stakes for defenders. In a more fragmented internet and a less stable geopolitical environment, it becomes harder to tell what an operation is meant to do, who benefits from it, and how confidently you can respond. The problem is no longer just technical detection; it’s an interpretation.
That is what makes Mellen’s argument so useful. The mistake is a misunderstanding of the role cyber plays inside broader campaigns of pressure, intelligence, and influence. When defenders treat cyber incidents as isolated technical events, they miss the larger strategic context.
Listen to the full conversation with Allie Mellen on Chasing Entropy, then take another look at whether your threat model reflects how cyber conflict actually works.
Get Allie Mellen’s book, Code War
Code War: How Nations Hack, Spy, and Shape The Digital Battlefield is a smart next read for anyone who wants more context on the history, strategy, and real-world stakes behind the themes explored here.
Get the bookSubscribe to Chasing Entropy
Subscribe to Chasing Entropy for honest, expert-led conversations on agentic AI, security, shadow IT, and extended access control from industry leaders.
Subscribe now2026-04-20, 00:00

AI agents are increasingly used to refactor large codebases, but many teams lack a clear understanding of where they succeed and where they fail. At 1Password, we applied agentic tooling to a multi-million-line Go monolith, and in this blog we'll share what worked, what broke, and what it means for teams adopting AI in production systems.
Here’s the situation: 1Password runs a large Go monolith called B5. It has been the foundation of our product for years and continues to perform well in production, both in terms of reliability and scale.
Now, Unified Access is designed to support both human and agent-driven workflows at high request rates and low latency. As we continue adding and enhancing its capabilities, we need clearer service boundaries and more independent scaling characteristics. Over time, that means evolving parts of the system in a way that preserves the privacy, performance, reliability, and security properties we have already established.
Coming up with an actionable plan for tackling this problem sounded like a good job for agents.
In our case, this meant applying agentic refactoring: using AI agents to analyze, plan, and execute changes across a codebase, from dependency mapping to system decomposition.
There’s a version of this story where agentic tooling analyzes a large codebase, produces a clean extraction plan, and service decomposition follows a predictable path from there.
Parts of that story did play out as expected. We built an agentic toolchain that analyzed millions of lines of code and gave us a clear, defensible extraction order, and that work has meaningfully improved how we think about decomposing the system.
What ended up being more valuable, though, was what we learned once we applied those tools to real changes in a live production environment. That is the part that tends to get glossed over, and it is the part that actually determines whether this approach works.
Building the analysis layer
The first question we had to answer was sequencing. In a system that handles sensitive data at scale, extraction order is a correctness constraint. If you get the sequence wrong, you can introduce subtle failures that are difficult to detect and even harder to unwind later.
To make that problem tractable, we built an agentic toolchain that combined a few different sources of truth.
We used Go SSA analysis to understand code structure, SQL parsing to identify data dependencies, and a DataDog MCP integration to bring in runtime coupling data. Together, these gave us a domain ownership map, a coupling graph, and a prioritized extraction order.
The output largely matched what you would expect from experienced engineers looking at the system. It suggested starting with Vault, which has its own API, dataset, and security boundary, followed by Billing, then AuthN and AuthZ, with Identity remaining as the core.
One pattern that worked especially well was using agents to build deterministic tooling rather than relying on them for ongoing interpretation. In this case, agents helped write parts of the SSA analyzer, and the analyzer then produced a reproducible domain map. That distinction matters because once the tool exists, you are reasoning over a stable artifact rather than debating what the model believes the system looks like.
An unexpected benefit of this work was that the instrumentation we added to support the analysis also improved our end to end transaction visibility in DataDog, which has been useful beyond this project.
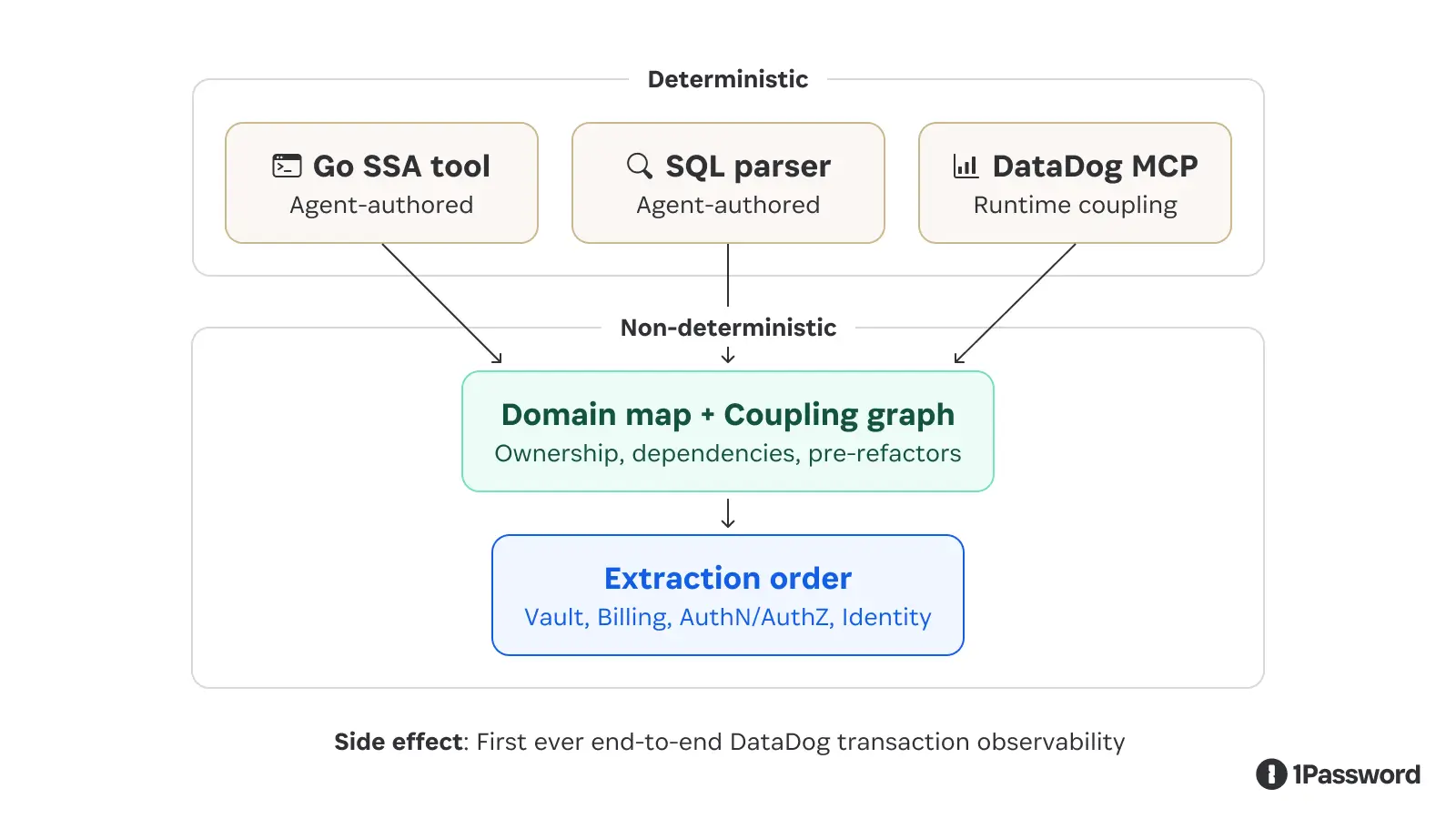
Finding the human to agent ratio
In parallel with the extraction analysis, we applied the same approach to a long-standing cleanup task in the codebase.
Our Go server used MustBegin to start database transactions, which panics on failure. That behavior made sense early on because it surfaced database issues quickly during development, but at production scale it is not the behavior you want when connections time out or request contexts are cancelled. In those cases, returning a clean error is the correct outcome.
The migration required updating more than 3,000 call sites across production and test code, which is why it had been sitting in the backlog.
The approach we took was highly structured. We generated a deterministic manifest of every call site using SSA, classified those sites into a small number of patterns, and defined explicit templates for each one. From there, we wrote a detailed playbook that described exactly how agents should execute the migration, including a list of common failure modes and clear instructions on when to stop and escalate instead of guessing. To scale execution, we ran multiple agents in parallel using git worktrees so that changes remained isolated.
Execution itself took a matter of hours. The majority of the time was spent building the tooling and writing the specification.
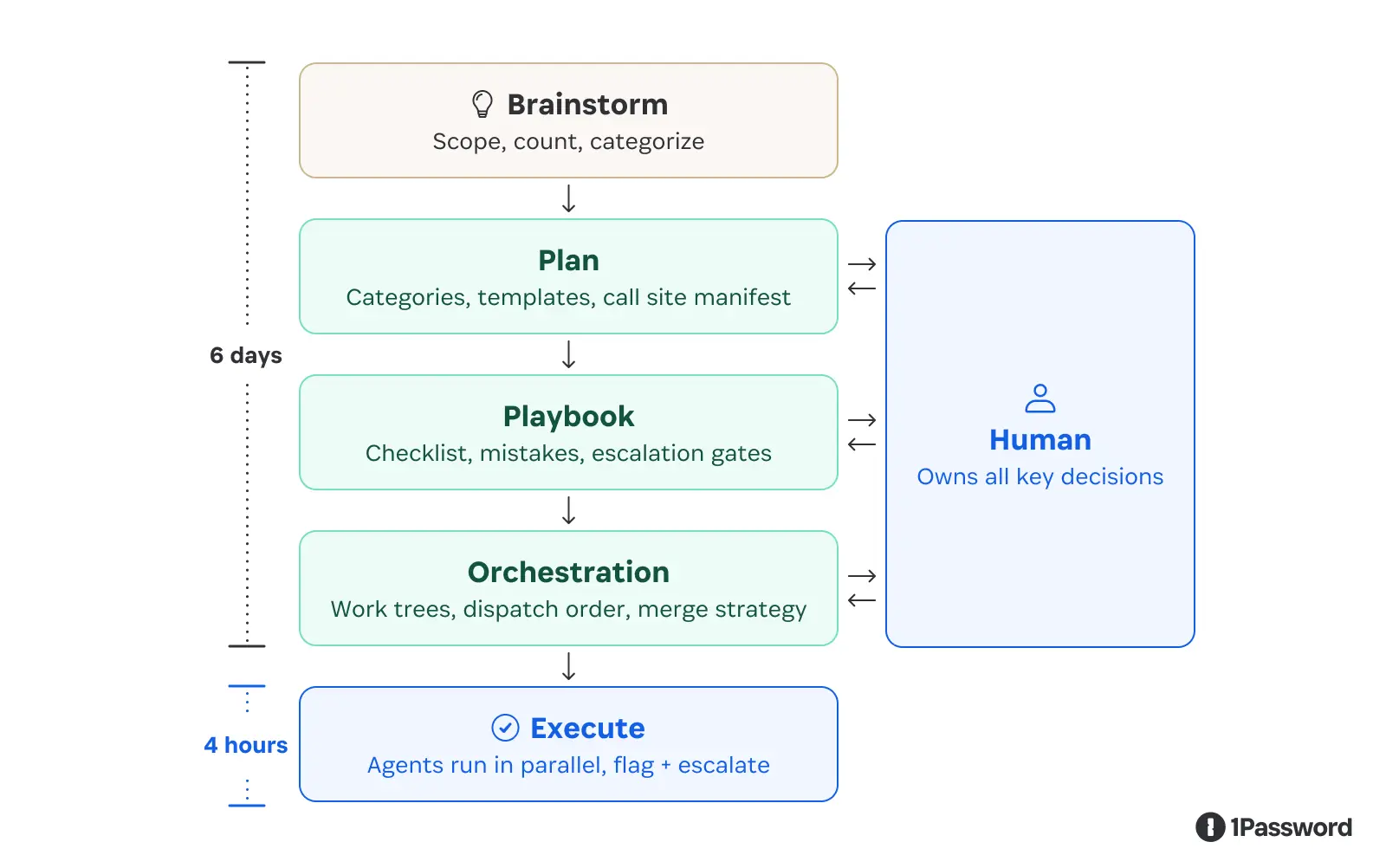
That ratio is the important part. When the work is fully specified and bounded, agents are both fast and accurate. When they encounter something outside the specification, the system is designed to surface that rather than attempting to resolve it implicitly.
Where agents need stronger constraints
We then moved on to a more complex task, which was extracting a service from the monolith.
Even for a relatively small service, this kind of work requires coordinated changes across schema evolution, read and write paths, deployment sequencing, and shared data contracts. These are interdependent decisions that need to happen in the right order. The primary issue we saw with this task was related to sequencing and invariants.
For example, the agent would attempt to backfill UUID columns before updating the code responsible for inserting new rows. That sequence introduces silent data loss, even if the underlying system is otherwise well designed. In other cases, it treated shared tables as if they were independently owned by the new service, which would have created conflicts at deployment time. These patterns persisted even when we provided explicit instructions about ordering and constraints.
We also saw a recurring behavior that we described internally as “speculation.” When the agent lacked sufficient context, it filled in the gaps with assumptions that appeared reasonable but were not verified. In one case, it inferred that a particular identifier format was a ULID and propagated that assumption through a series of changes, which ultimately required rolling back the entire session.
The pattern that works is using agents to produce deterministic artifacts, then forcing execution through those constraints. For instance, in Cursor, we see lots of customers use Plan Mode with a bigger, slower model (like GPT5.4 or Opus) to produce a concrete plan.md file, edit the file as needed, and then actually build with a smaller, faster model that is excellent at coding (like Composer)." - Tido Carriero, VP of Engineering, Cursor
For this class of work, the productivity gains were real but more modest. In practice, we saw something close to a 20-30% improvement. The agents were helpful, but they did not replace the need for careful coordination and review.
This points to a broader shift we’re seeing at 1Password. AI agents are becoming a new class of actor in systems, one that introduces non-determinism, persistence, and scale that traditional models were not designed to handle. That has implications not just for engineering workflows, but for how access and trust are managed across systems.
Lessons for teams using AI agents in code
There are a number of lessons other teams can take away from 1Password’s experience, and their applications extend beyond this single use case.
Lesson 1: The bottleneck for agentic refactoring is not code generation
Agents are very effective at reading code, analyzing structure, and drafting changes. Where things become difficult is in managing sequences of decisions that have ordering constraints or are difficult to reverse. This includes schema changes, deployment sequencing, and shared state boundaries. If those are not handled correctly, the system will fail regardless of how clean the generated code is.
Lesson 2: Non-determinism needs to be carefully contained
Language models are non-deterministic, which is part of what makes them useful. In the context of production migrations, however, that variability becomes a source of risk. The pattern that has worked well for us is to use agents to build deterministic tools, such as analyzers and manifests, and then constrain subsequent work to those outputs. This creates a stable foundation even when the agents themselves are not fully predictable.
Lesson 3: Incomplete specifications lead to implicit ones
When an agent does not have enough context, it will fill in the gaps, often in ways that are locally reasonable but globally incorrect. The only reliable way to address this is to make the specification explicit, including invariants, ordering constraints, and clear escalation paths for anything that falls outside the defined patterns.
Another important shift is around how to think about coverage. The goal is not to have the agent handle every possible case. The goal is to have it execute confidently on well-understood patterns and escalate quickly when it encounters ambiguity. This requires being intentional about where automation stops and human judgment takes over.
Lesson 4: Parallelism only works when isolation has already been solved
Running multiple agents at once can be very effective, but only when changes are independent and conflicts are structurally eliminated. Otherwise, you end up increasing the surface area for inconsistency rather than reducing execution time.
How this impacts 1Password’s agentic approach
We are rolling out agentic tooling across the engineering organization with a clear understanding of where it provides leverage.
We know that agents are most effective when the problem is well specified and that deterministic tooling provides the constraints that make that possible. Engineers remain responsible for defining system boundaries, modeling dependencies, and ensuring that sequencing is correct.
These insights will help us shift the nature of the work we allocate to engineers, understanding that the highest leverage activities are not writing code or prompting models, but defining systems in a way that can be executed safely and predictably.
The problems we are working on, including decomposing a production system under live traffic and structuring multi-agent execution, do not yet have well-established playbooks. We are building those in real time, and that is where most of the interesting engineering work is happening.
If that is the kind of problem you enjoy working on, we are hiring.
2026-04-17, 00:00

April marks Southwest Asia and North Africa (SWANA) Heritage Month, a time to recognize and celebrate the rich cultures, histories, and contributions of SWANA communities. At 1Password, we’re proud to highlight the people who bring these perspectives to life in our work and shape our culture every day.
This month, we’re spotlighting Kaynat Chowdhury, Customer Success Manager and Communications Lead for our SWANA Employee Community Group. We sat down with Kaynat to learn more about her career journey, her impact in Customer Success, and how community and belonging have shaped her experience at 1Password.
Meet Kaynat
Can you share a bit about your career journey and what led you to Customer Success? Was this a path you always saw for yourself?
When I was in school in Bangladesh, I studied Science and then Commerce, then I came to Canada to get a Bachelor’s Degree in Sociology. All the while, I had no idea I was going to be in tech and in Customer Success. However, it really was the best decision and I feel that Customer Success found me more than I found it, and once I was in it, I realized it was a perfect fit. It combines everything I enjoy: building relationships, problem-solving, and making a real difference for the people I work with. Was this the path I always saw? To be honest, no! It’s quite hard to be an immigrant in a new country (I have been here more than a decade now) and truly know what path will be possible. You're just doing your best with what's in front of you. But I am so glad I stayed open, because Customer Success turned out to be everything I didn't know I was looking for.
As a Customer Success Manager, you work closely with organizations to help them get the most value from 1Password. How has that work evolved as we’ve expanded into areas like Unified Access, SaaS Manager, and EPM?
It has been incredible to see the reception our clients have with our product expansion from EPM into Unified Access and SaaS Manager. I have had the privilege of interacting across thousands of clients over the years and people really love our product and are curious about what we are building. This evolution is also allowing me to have much more strategic discussions with IT leaders and security teams about how 1Password fits into their broader security posture.
You’ve been at 1Password for four years and have seen the company evolve quite a bit. What’s felt most meaningful to you as that growth has taken shape, and what are you most looking forward to next?
Four years! I cannot believe it. When I think back to where I started versus where I am now, the growth has been remarkable – and not just for the company, but personally for me too. I went from Customer Success Representative, to Customer Success Manager, and now Customer Success Manager, Level 2. Watching 1Password evolve from a well-loved password manager into a comprehensive security platform has been genuinely exciting to be part of. The most meaningful moments have always been the human ones, though; the customers who tell you that your work made a real difference (which in my role, I get to hear a lot of) and the colleagues who show up for you every single day. Being part of a team like that is something I don't take for granted, and I want to continue contributing to that culture as we grow.
During your time here, we’ve also seen our inclusion efforts grow, including the launch of Employee Community Groups like SWANA. As Communications Lead for SWANA, what does your role involve, and how do you approach building connection and visibility for the community? 1Password's inclusion efforts have been wonderful to see and to be a part of. The love for my SWANA community and the amazing leads I share space with is truly unmatched. As Communications Lead, my role is really about making sure our community feels seen, heard, and celebrated, both within SWANA and across the broader 1Password organization. That means everything from crafting our messaging, to helping plan events and amplifying the stories of our community in ways that feel authentic and meaningful. What I love most about this role is that connection is at the heart of everything. The SWANA region is incredibly diverse, spanning so many cultures, languages, and experiences, and I think that richness is exactly what makes our community so special.
How has being part of the SWANA community shaped your experience at 1Password? Honestly, it has made me feel more at home. I already loved working at 1Password, but SWANA added a layer of belonging that is hard to describe. As someone who immigrated from Bangladesh, there is something really meaningful about having a space where your culture and your background are not just acknowledged but celebrated. It has connected me to colleagues I might never have crossed paths with otherwise, and some of those connections have become some of my most valued relationships here.
What would you say to someone from a background represented within the SWANA community who is considering a path in tech or cybersecurity today?
I would say: do not let the unfamiliarity of the industry intimidate you. When I was studying Sociology in Canada, I never imagined I would end up in tech. But here I am, and I genuinely love what I do. The skills you bring from your background, your ability to navigate different cultures, to communicate across differences, and to be resilient in unfamiliar spaces, are not weaknesses. They are strengths that this industry needs. Tech and cybersecurity need more diverse voices, more perspectives, more people who understand the world in different ways. The path may not always be clear, but the community around you will support you. Lean on it.
Happy SWANA Heritage Month
Kaynat’s story is a reminder that there’s no single path into tech – and that the perspectives we bring with us are often what make the biggest impact. Whether she’s building trusted partnerships with customers or fostering connection and visibility within the SWANA community, her work reflects the kind of care, curiosity, and leadership that drive both our business and our culture forward. As we celebrate SWANA Heritage Month, we’re grateful for the community Kaynat helps build and for the impact she makes every day in shaping 1Password as a place where people feel a true sense of belonging.
If you’re interested in joining us, explore open roles at 1Password.
ALL RSS FEEDS
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
2. PROTON BLOGby ProtonMailSwiss-knife comprehensive solution for privacy and security in email and on the web.
2026-06-03, 20:10
From Google Chrome to Google Workspace, Google has been aggressively integrating AI into its apps and platforms — and Google Search is no exception. As long as you’ve looked anything up on Google since 2024, you’re already familiar with AI Overviews: the AI-generated summary that appears at the top of your results before any actual links.

The idea is to help you get answers more efficiently. But in practice, AI Overviews have been criticized for being inaccurate or confusing, for pushing real results further down the page, and for taking away traffic from the original sources.
What’s more, if you’re signed into a Google account — which most people are — your searches and browsing activity, along with associated data like your location and device details, are tracked by default. That means this so-called convenience also comes at a cost to your privacy.
There isn’t a simple built-in off switch to disable AI Overviews on Google. But the good news is that there are a few effective workarounds with no external plugins or complicated setups required.
Use the Web filter
This is the quickest way to strip AI Overview from your results without changing any settings, though you’ll have to perform the same steps below for every new search.
1. Run a Google Search as usual.
2. Underneath the search bar, look for the tabs: All, Products, Images, News, Videos, etc. Select Web.

If you don’t see it among the tabs, select More → Web.
Your results will reload without AI Overview.
Add -AI to your search
This method relies on Google’s minus (NOT) operator to exclude a certain term from the results. Simply add -ai to the end of your query, like price of eggs -ai. Your search results should appear without AI Overviews, but this isn’t always guaranteed.

Append &udm=14 to URLs
Adding this parameter forces Google to automatically show web-only results. There are two ways to implement this:
Manually (one-off)
Search something on Google, and on the result page, add &udm=14 to the end of the URL in your browser’s address bar and hit Enter.

The new page will load without AI Overview, and you can bookmark this modified URL for future searches.
Save as a custom search engine on Chrome
This enables you to permanently add the &udm=14 parameter to every search on the Google Chrome browser, effectively bypassing AI Overview each time without having to do so manually. Note that this only applies to desktop devices.
1. On Google Chrome, click the vertical ellipsis ⋮ on the top-right and open Settings.

2. Go to Search engine and click Manage search engines and site search.

3. Under Site search, click Add.

4. Fill in the following details:
Name: Google Web
Shortcut: @web
URL with %s in place of query: https://www.google.com/search?q=%s&udm=14
5. Click Add.

6. Click the vertical ellipsis ⋮ next to Google Web and select Make default.

Every default search you run from Chrome’s address bar now bypasses AI Overview and returns clean web results.
Your privacy deserves more than a workaround
Gemini, Google’s own AI, is deeply embedded in the Google ecosystem, including Gmail, Android, Google Docs, and Google Drive. This gives the company broad access to your data and raises suspicions about how that data can be used to fuel Google’s business model, including for targeted ads and AI training. For many, the lack of clear transparency and meaningful consent makes this integration feels more like surveillance.
AI Overviews are just another way for Google to push AI into your life by changing the default search experience itself. Not everyone is on board with this AI takeover, especially when it is built into services people use every day. If you agree, turning off AI Overviews is a start.
But if you’re serious about keeping your data out of Google’s AI systems, the most effective step is to reduce how much you rely on Google in the first place.
Next, you can switch to an encrypted ecosystem that believes privacy should be the default on the internet, not something you have to fight for. AI can be useful, but it should be optional, transparent, and built around consent. Our own AI assistant never logs or trains on your data. When it comes to search, you can choose a European search engine with opt-in AI features, or no AI at all.
Google is not the only company whose AI tools have implications for your privacy. Whether you’re using AI for work or in your daily life, it’s worth understanding exactly how your data is being handled — because the defaults of Big Tech rarely have your best interests in mind.
2026-06-02, 18:30
ChatGPT is one of the most popular AI assistants, but growing concerns about AI privacy, data security, and OpenAI as a company have spurred people to look up how to delete ChatGPT.
If you’ve decided it’s time to move on from ChatGPT — whether for privacy or moral reasons, to reduce your digital footprint, or simply because you’ve found a better ChatGPT alternative — this guide will walk you through exactly how to delete your ChatGPT account, cancel your subscription, and export your data before you go.
- How to delete your ChatGPT account
- What to do before deleting your ChatGPT account
- What happens after your ChatGPT account is deleted?
- Why delete your ChatGPT account?
- Choose an AI that respects your privacy
How to delete your ChatGPT account
Deleting your ChatGPT account is permanent and cannot be undone. Before you proceed, ensure that you’re ready to delete your ChatGPT account.
ChatGPT offers several methods for account deletion:
Delete your account directly in ChatGPT on web
- Go to chatgpt.com and log in.
- Click on your profile icon in the bottom-left corner.
- Select Settings → Account → Delete account → Delete. If you haven’t logged in within the last ten minutes, you’ll be prompted to log in again.
- In the confirmation screen, type your account email address and the word DELETE into the input fields.

- Click Permanently delete my account to complete the deletion.
Delete your account through OpenAI’s Privacy Portal
- Go to privacy.openai.com.
- Click Make a Privacy Request in the top-right corner.

- Select I have a consumer ChatGPT account.

- Click Delete my ChatGPT account and follow the prompts to request your account deletion.

Delete your account on iOS
- Open the ChatGPT app on your iOS device.
- Tap the two horizontal lines in the top-left corner to open the menu.

- Tap your user icon in the top-right corner.

- Scroll down and select Data controls.
- Select Delete account.
- In the confirmation modal that appears, tap Delete account.

Delete your account on Android
- Open the ChatGPT app on your Android device.
- Tap the two horizontal lines in the top-left corner to open the menu.

- Tap your user icon in the top-right corner.

- Scroll down and select Data controls.

- Select Delete OpenAI account.

- In the confirmation modal that appears, tap Delete OpenAI account.
OpenAI will delete your data within 30 days, with certain exceptions. According to OpenAI’s privacy policy, even if your account is deleted, they may retain certain information for legal compliance, fraud prevention, or safety purposes. The exact retention period and what data is kept isn’t always immediately obvious, which is one reason many privacy-conscious users are switching to alternatives.
What to do before deleting your ChatGPT account
Before deleting your account, you should first export any conversations or information you’d like to keep. If you have a paid ChatGPT subscription, it’s best to cancel it before deleting your account to prevent future charges.
Export your ChatGPT data
You can export your ChatGPT data through a web browser. This applies even for the ChatGPT app on iOS and Android, which redirects you to export your data through web. Here’s how:
- Go to chatgpt.com and log in.
- Click your profile icon in the bottom-left corner.
- Select Settings → Data controls.
- Look for the Export data section, then click Export.
- Click Confirm export in the pop-up window.

You’ll receive an email notifying you when your export is complete and ready to download. This process can take a few hours to several days, depending on how much data you have.
Note: Your data will be exported as a ZIP file containing JSON files and an HTML file with your conversations, account information, uploaded or created images, and other data associated with your account. The download link in this email will expire after 24 hours, after which you’ll have to repeat the process if you don’t export by then.
Cancel your ChatGPT subscription
If you have a ChatGPT subscription, you should cancel it before deleting your account. Otherwise, you may continue to be charged even after your account is deleted.
If you subscribed through the ChatGPT website:
- Go to chatgpt.com and log in.
- Click your profile icon in the bottom-left corner.
- Select Settings → Billing → Cancel subscription.
- Click Cancel subscription in the popup.

You’ll receive an email confirmation of your cancellation. Your subscription will remain active until the end of your current billing period, but you won’t be charged again.
If you subscribed through the iOS App Store:
- Open the Settings app on your iOS device (not the ChatGPT app).
- Tap your name at the top of the screen.
- Select Subscriptions, then find and tap ChatGPT in your list of active subscriptions.
- Tap Cancel subscription and follow the prompts to confirm your cancellation.
If you subscribed through Google Play Store:
- Open the Google Play Store app.
- Tap your profile icon in the top-right corner.
- Select Payments & subscriptions → Subscriptions, then find and tap ChatGPT in your subscription list.
- Tap Cancel Subscription and follow the prompts to confirm your cancellation.
Once you’ve canceled your subscription, you can safely move on to deleting your ChatGPT account.
What happens after your ChatGPT account is deleted?
Once you delete your account:
- You’ll lose access to all conversation history, unless it’s already exported.
- Your ChatGPT subscription will be canceled (if you haven’t already done so through the website).
- You won’t be able to log in or use ChatGPT with that email address for 30 days.
- Any API keys associated with your account will be deactivated.
- Custom instructions and preferences will be permanently deleted.
- Your data will be deleted within 30 days, unless OpenAI chooses to retain information for legal, fraud prevention, or safety reasons.
Why delete your ChatGPT account?
There are several reasons to stop using ChatGPT, including its implications for personal privacy and OpenAI’s controversial track record.
Privacy concerns and data collection
OpenAI collects your conversations, account information, and usage patterns every time you interact with their platforms. And because ChatGPT doesn’t offer zero-access encryption, your personal data may be exposed in data breaches. This has already happened: In 2023, a ChatGPT bug briefly allowed some users to see titles from other people’s chat histories, and in 2025, attackers breached an OpenAI vendor and gained access to sensitive information of ChatGPT business users.
AI model training
By default, your conversations are used to train and improve OpenAI’s models. Even if you opt out of having your data used for training or use ChatGPT in Temporary Mode, your conversations are still stored on OpenAI’s servers — at least temporarily. This creates a permanent record of potentially sensitive information, from confidential work discussions to personal questions, that can be at risk of being leaked.
Third-party access and legal compliance
As a US-based company, OpenAI is subject to government data requests and surveillance laws that may conflict with international privacy standards. Your ChatGPT conversations can be accessed by US authorities without your knowledge, regardless of where you live. OpenAI also shares data with third-party service providers for business operations. For people in privacy-conscious regions like the EU, this creates jurisdiction concerns, as your data crosses borders into legal frameworks that may offer less protection than your home country.
OpenAI controversies
OpenAI has faced mounting backlash that extend beyond technical privacy issues. The company’s partnership with the Pentagon in using AI for military applications, including autonomous warfare systems, has raised serious ethical concerns and directly contradicts its stated mission of ensuring AI benefits all of humanity. OpenAI has also been criticized for messy internal governance, conflicts between its stated nonprofit mission and for-profit practices, lack of transparency around safety protocols, and enabling the creation of misleading content.
Choose an AI that doesn’t compromise on privacy and values
If privacy and ethical concerns are driving your departure from ChatGPT, you don’t need to give up AI assistance entirely. There are alternatives built around your rights, not corporate profit or surveillance.
Proton’s Lumo is built with the same privacy principles as the rest of the Proton ecosystem. Your conversations are encrypted, your data is never stored or used for training, and you maintain full control. Built and hosted in Europe, away from US jurisdiction and under some of the world’s strictest privacy laws, your private data stays in the safest possible hands: yours.
Ready to explore AI that respects your privacy? Try Lumo, Proton’s AI assistant, for free today.
2026-06-01, 11:55
If you’re trying to avoid Google in an effort to protect your privacy, you may well have considered using DuckDuckGo instead. It’s one of the better-known private search engines, but is it really private, and is DuckDuckGo safe to use? We look at how it works, what its data practices are, and how it stacks up against Google and other private search engines.
- Who owns DuckDuckGo? Understanding the business model
- How DuckDuckGo functions: The mechanics of private search
- What data does DuckDuckGo collect?
- DuckDuckGo vs. Google
- DuckDuckGo vs. other private search engines
- Is DuckDuckGo right for you?
- Frequently asked questions
Who owns DuckDuckGo? Understanding the business model
DuckDuckGo is majority-owned by its founder, Gabriel Weinberg, and other DDG team members, and has remained an independent company since its founding in 2008. Although it’s a for-profit company, DuckDuckGo does not make its money by selling personal information or tracking users.
How does DuckDuckGo make money without tracking you?
DuckDuckGo has two income streams: advertising and subscriptions.
Advertising
The majority of DuckDuckGo’s income comes from private ads on the search engine. Google also shows ads in search results; however, these ads are based on user profiles that come from tracking your search, browsing, and purchase history. Because DuckDuckGo doesn’t collect information on its users, the ads you see are based on the search term you enter.
Subscriptions
Users can pay to access a DuckDuckGo subscription service, which bundles privacy-related tools for a monthly or annual fee.
2022 tracking revelations
In May 2022, a security researcher discovered that DuckDuckGo browsers allowed Microsoft trackers on third-party sites, despite claiming to block all third-party trackers. In response, Weinberg explained that this exemption was due to a search agreement with Microsoft, and that plans were underway to “do more”.
In August 2022 DuckDuckGo began blocking most Microsoft trackers in the same way it already blocked Google and Meta, with the exception of advertising clicks. Because DuckDuckGo uses Microsoft Advertising, they allow tracking scripts from the the bat.bing.com domain, in order for advertisers to track conversions from their ads. However, it’s possible to disable ads in the search settings.
How DuckDuckGo functions: The mechanics of private search
DuckDuckGo isn’t a secret search engine in the sense that it has its own unique index. Rather, it’s a privacy layer that sits on top of existing search data from established sources like Bing, Yahoo, and its own smaller crawler, DuckDuckBot.
Instead of building a massive proprietary database like Google, DuckDuckGo aggregates results from these public sources while stripping away the tracking, profiling, and personalization that typically accompany searches on Google, Bing, and Yahoo. This system means that every user sees the same results for the same query, regardless of their location, search history, or browsing habits.
What data does DuckDuckGo collect?
DuckDuckGo collects only what’s technically necessary for functionality and security. Your device sends basic information such as browser type, operating system, and language; DuckDuckGo uses this information temporarily to deliver content and verify that you’re not a malicious bot.
Cookies and IP address logging
DuckDuckGo doesn’t save your IP address or any unique identifiers alongside your searches. Neither does it track you through cookies or any other storage methods — it uses anonymous cookies for search settings and local storage for anonymous display settings only.
Search analytics
For search analytics, DuckDuckGo may save anonymous queries, completely disconnected from unique identifiers, to analyze search trends and improve its indexes. For local search results, it sends a random location near your actual position, which is never logged to disk. As a result, when you use their services, they have no way to create a history of your search queries or the sites you browse, so viewing search results on DuckDuckGo is anonymous.
Third-party sharing
DuckDuckGo shares some information with hosting and content providers, but with strict anonymity safeguards. It calls for content (such as images) from DuckDuckGo servers on your behalf and securely delivers content over an end-to-end encrypted connection. DuckDuckGo shares anonymous information, such as browser and device types, with these providers, but never shares any information that could personally identify your searches or website visits.
DuckDuckGo uses Microsoft’s ad network to manage ad clicks, and according to their privacy policy, Microsoft has committed not to associate your ad-click behavior with a user profile. Note that your ISP can still see your IP address, but the encrypted HTTPS connection prevents them from seeing your search queries. To hide your browsing behavior completely from your ISP, use a VPN.
Of course, when you visit other websites by clicking external links or using bang shortcuts, the privacy policies of those other websites apply. For example, if you browse Facebook, Facebook will know what you do on its site.
Data sovereignty
DuckDuckGo is a US company, so despite its privacy-focused positioning, it remains subject to US jurisdiction. This creates a vulnerability to legal mechanisms like National Security Letters (NSLs) from the FBI, or under foreign intelligence laws such as FISA’s Section 702.
While Section 702 is legally intended for collecting foreign intelligence, its implementation allows for the “incidental collection” of communications involving Americans. Because DuckDuckGo is a US entity, search queries and metadata passing through its servers or U.S. internet infrastructure can be swept up by upstream collection, regardless of the company’s internal no-log policies. Similarly, while NSLs are typically targeted rather than bulk, they can compel a company to hand over any data it does possess (such as security logs or error reports) without a traditional warrant.
DuckDuckGo’s privacy practices reduce the amount of stored data available for disclosure, but the company’s US incorporation is a factor worth considering. For most users concerned primarily with commercial tracking, this is a secondary concern. For users who are actively trying to avoid US government surveillance, a private search engine in a jurisdiction with stronger privacy laws, such as the EU, might be a better option.
DuckDuckGo vs. Google
Google and DuckDuckGo represent two fundamentally different approaches to search. Google monetizes its search results by tracking and profiling you, and markets this privacy violation back to you as personalization and ecosystem integration. DuckDuckGo emphasizes privacy and neutrality. Here’s how they stack up:
Data collection and tracking
Google builds a detailed profile of each user by collecting location, search history, device type, and browsing preferences. It monetizes user information in two major ways: targeted advertising and real-time bidding (RTB). Both involve sharing your data with advertisers. However, RTB is the more egregious privacy violation. This data also feeds into their ranking algorithms to deliver highly personalized results tailored to individual users.
DuckDuckGo deliberately avoids collecting any personal data. Every user receives the same search results for a given query, regardless of their location, past searches, or browsing habits.
Search quality and personalization
Google’s personalization creates what’s known as the “filter bubble” effect, where Google tailors results to keep you engaged and reinforce your existing beliefs and preferences based on your profile.
DuckDuckGo delivers neutral results that remain consistent across all users. So, no personalization, but no tracking either.
Google’s approach can increase relevance for known preferences, while DuckDuckGo’s neutrality protects privacy but may sacrifice some contextual precision.
Ecosystem integration
Google benefits from a deeply integrated ecosystem, including Maps, Gmail, and Android, which provides additional data points for refining search results.
DuckDuckGo takes a standalone approach.
The seamlessness of the Google ecosystem helps explain why some stick with Google despite privacy concerns. Its convenience and comprehensiveness can outweigh privacy considerations for many people.
How these differences affect you
Google typically delivers more comprehensive, contextually relevant results due to its personalization and larger index, but at the cost of privacy. DuckDuckGo provides consistent, privacy-protected results that can be surprisingly comparable across many queries, though they may lack the precision that comes from knowing the user’s context.
However, according to PCMag’s comparison testing, Google didn’t show a significant advantage over DuckDuckGo in the quality of raw search results.
DuckDuckGo vs. other private search engines
While DuckDuckGo is one of the most recognizable privacy-focused search engines, several others compete in this space, each with distinct approaches to balancing privacy, result quality, and usability.
DuckDuckGo vs. Startpage
Both DuckDuckGo and Startpage prioritize user privacy, but they do so in different ways. Startpage sources its results directly from Google, giving users access to Google’s comprehensive index, but without Google’s tracking.
DuckDuckGo, by contrast, aggregates results primarily from Bing and Yahoo, supplemented by its own crawler. Startpage users may find more familiar, Google-style results, while DuckDuckGo users get a different result set that avoids Google’s ecosystem entirely.
DuckDuckGo vs. Brave Search
Brave Search uses an independent search index built by its own web crawler, rather than relying on third-party providers like DuckDuckGo. As a result, Brave has more control over ranking and potentially more unique results.
However, their index is smaller than Google’s, so Brave Search gives you the option to let your browser anonymously check Google when their own index lacks coverage. Brave claims that these results are mixed client-side in your browser, and this has no impact on your privacy. It should be noted, though, that this claim has not been independently audited in way Proton VPN’s no logs claims are.
Brave and DuckDuckGo both offer integrated search experiences, but Brave’s tight integration with the Brave browser provides a more seamless experience for users already in that ecosystem.
DuckDuckGo maintains broader platform availability with dedicated apps and extensions across all major browsers, making it more accessible to users who aren’t committed to a single browser.
DuckDuckGo vs. Searx/MetaGer
Searx and MetaGer represent the open-source approach to private search, allowing users to self-host instances or choose from community-run servers. This approach offers maximum transparency and control but requires more technical knowledge to set up and maintain.
DuckDuckGo, as a proprietary service, prioritizes ease of use with a polished interface and reliable uptime that appeals to average users. While Searx and MetaGer can aggregate results from multiple engines simultaneously, DuckDuckGo’s curated approach ensures consistent performance without requiring users to configure their own result sources.
For most users seeking privacy without technical overhead, DuckDuckGo offers a more straightforward experience, while Searx and MetaGer appeal to those who value open-source principles and self-hosting capabilities.
| Feature | DuckDuckGo | Startpage | Brave Search | MetaGer | |
| Data collection | Extensive | Minimal | Minimal | Minimal | None |
| Result sources | Own proprietary index | Over 400 sources and their own crawler | Google (via proxy) | Independent crawler + other sources | Multiple engines aggregated |
| Personalization | High | Minimal | Minimal | Moderate | Minimal |
| Privacy philosophy | Ad-driven business model | Privacy-first, no tracking | “Google without tracking” | Privacy-focused browser ecosystem | Open-source, community-driven |
| Ecosystem integration | Extensive (Maps, Gmail, etc.) | Standalone | Standalone | Limited (Brave browser integration) | Standalone |
| Ease of use | Very high | High | High | High | Medium |
| Open source | No | Some products | Some products | Some products | Yes |
| Best For | Users who value ease-of-use and aren’t concerned about privacy | Privacy-conscious general users | Users wanting Google results privately | Brave browser users | Tech-savvy privacy advocates |
Is DuckDuckGo right for you?
If you’re committed to shoring up your digital privacy, using DuckDuckGo is a good choice for privacy-focused users. While no tool is perfect, DuckDuckGo offers a robust, transparent alternative to traditional search engines. It works best as part of a broader privacy strategy; combining DuckDuckGo or another private search engine with a private browser, a VPN, and a password manager is an effective way to improve your privacy while online.
Frequently asked questions
If it’s free, what’s the catch?
Unlike traditional engines that build detailed user profiles to target ads, DuckDuckGo displays ads based solely on the search terms you type at that moment, in what’s known as contextual advertising. This revenue stream allows the company to remain independent and privacy-focused without needing to harvest or sell personal data. You may see fewer relevant ads than in a personalized feed, but your privacy remains intact.
Do you still need Google?
No, there’s nothing that makes it essential, but despite its privacy disadvantages, there are scenarios where Google remains the more practical choice. If you’re deeply integrated into the Google ecosystem (relying on Google Workspace, Android-specific features, or Google Maps’ granular local data), you may find the transition difficult.
Additionally, for highly specialized queries where personalization significantly improves results, Google’s data advantage can be useful. You gain convenience and contextual precision with Google. Still, you pay for it with your personal data and the potential for a “filter bubble” that limits your exposure to diverse viewpoints.
2026-05-29, 16:48
One-time passcodes (OTPs) are a core part of traditional two-factor authentication (2FA) and multi-factor authentication (MFA).
If you log in to an account or verify a transaction, you’ll receive them by email, SMS, or authenticator apps to confirm your identity.
Now, cybercriminals have found a way to bypass these protections using OTP bots.
What is an OTP bot?
An OTP bot is an automated software program that intercepts or steals one-time passcodes used to verify your identity. The goal is to gain control of your account in what’s known as an account takeover attack (or ATO).
Cybercriminals can buy OTP bot attacks on underground marketplaces, often via Telegram, for as little as $10 per attack. This low-cost, scalable approach lets attackers target many people at once with minimal effort.
How OTP bots work
OTP bots are designed to exploit the time between when you receive a one-time password and when you enter it into the app or website. This window is often less than a minute.
Cybercriminals typically intercept the code in three ways:
OTP bot account takeover via social engineering
The attacker uses stolen or leaked credentials to trigger the OTP step on a legitimate site. A bot then contacts you by SMS or phone call, using a script designed to create urgency — for example, by impersonating a bank’s fraud team. If you share the OTP, the bot passes it to the attacker in real time, giving them access to your account. The attacker can then change the login credentials and lock you out.
OTP bot account takeover via interception
Using stolen credentials to trigger the OTP, the bot attempts to intercept the code before it reaches you. Common methods include:
- SIM swap attack: The attacker convinces a mobile carrier to transfer your phone number to a SIM card they control, so SMS codes are delivered directly to them.
- API exploitation: The bot targets poorly secured authentication APIs to capture OTPs as they’re generated.
- Brute force: The attacker tries all possible combinations of short numeric OTPs, which is possible when the website or app you’re using has not set a limit for repeated requests.
OTP bot account takeover via relay attack
This variation does not rely on stolen credentials. Instead, it tricks you into giving an attacker both your login details and your OTP. You land on a fake website that looks like the real one and enter your credentials. The bot immediately uses those credentials to log in to the real website, which triggers an OTP sent to your phone. The fake website then asks you to enter the code, which the bot relays to the real website in real time. This lets the attacker complete the login before the code expires.
As with the other variations, the attacker can then change the credentials and lock you out of your account.
How an OTP bot can affect your business
The ease of obtaining OTP bot services is likely to increase attacks on businesses. While banking and ecommerce are common targets, any industry can be affected. Small and medium-sized businesses (SMBs) are often targeted more frequently.
Financial losses can be significant, but they are not the only risk you should consider.
As damaging as financial losses can be to an organization, that’s not the only loss that should concern business owners.
Loss of customer trust
Customer trust often drops after a data breach. A 2024 study by Vercara found that 58% of consumers consider affected brands untrustworthy, and 70% would stop shopping with a brand after a security incident.
Regulatory compliance risks
Even if no funds are stolen, your business may face fines for failing to meet data protection requirements. For example, the General Data Protection Regulation (GDPR) applies to any organization that processes the personal data of EU residents, regardless of location or company size. Penalties for non-compliance can be substantial.
How to protect your business from OTP bots
Given that human error is the hardest thing to protect against, businesses should implement as many technical safeguards as possible. These might include:
Rate limiting and throttling
Limit how many one-time passcode (OTP) requests can be made from a single IP address, phone number, or account within a set timeframe. This prevents attackers from flooding your systems with automated requests.
CAPTCHA and behavioral analysis
Use CAPTCHA challenges when suspicious activity appears, and apply behavioral analysis to detect non-human patterns such as rapid form submissions or unrealistic mouse movements.
Device fingerprinting
Track device characteristics to identify repeat offenders and flag devices making multiple OTP requests across different accounts.
Multi-factor authentication beyond OTP
Add stronger authentication methods, such as hardware security keys, biometric verification, or push notifications, to reduce reliance on OTP alone.
API security hardening
Protect your OTP APIs by requiring authentication, signing requests, validating inputs, and using secure communication channels to prevent interception or manipulation.
Monitoring and detection
Monitor usage patterns to identify unusual behavior that may indicate bot activity. Use real-time alerts to catch spikes in OTP requests or unexpected geographic access. Review logs regularly to detect threats early.
How to protect yourself from OTP bots
OTP bots can be dangerous, but you can take simple steps to protect your accounts.
Use strong, unique passwords or passkeys
Use a business password manager to generate and store unique credentials for each account. If possible, use passkeys, which remove the need for one-time passwords (OTPs).
Use a hardware security key
Physical security keys, such as YubiKey, provide strong protection against automated attacks because they require physical access to your device.
Watch for phishing attempts
Be cautious of unsolicited messages that ask for verification codes. An OTP is meant to be entered into a website or app, not shared with anyone.
Monitor your account activity
Check login history and account settings regularly for unusual activity.
Use an authenticator app instead of SMS
Time-based one-time passwords (TOTP) — codes generated by an authenticator app — are more secure than SMS-based OTPs, which can be intercepted through SIM-swapping attacks.
Good password hygiene is your first line of defense
Combining strong technical safeguards with good credential hygiene goes a long way toward keeping attackers out.
A business password manager is one of the simplest and most effective tools you can use — it ensures employees aren’t reusing weak passwords across accounts, which is exactly the kind of vulnerability OTP bots are designed to exploit.
Pair it with phishing-resistant authentication methods and a culture of security awareness, and you make your business a much harder target.
2026-05-29, 16:09
Video conferencing is used by 58% of companies as part of their regular operations. It has allowed businesses to cut travel costs, hire talent from anywhere in the world, and keep teams connected even when they are miles apart.
But every new tool comes with a trade-off. When you move sensitive conversations — like contract negotiations, financial planning, or client strategy — onto the internet, you are also opening a door for potential risks.
Let’s look at how businesses actually use this technology, the hidden risks you need to watch for, and how to choose a tool that protects your reputation.
What is video conferencing?
You’ve likely heard the term “video conferencing” everywhere lately. If you’re a business owner who has traditionally relied on phone calls or in-person meetings, you might be wondering: “Do I really need this?” or “How do I do it without exposing my business to risk?”.
Video conferencing is a real-time technology to host meetings via live video and audio over the internet. Instead of driving across town or booking a flight, you use a computer or smartphone to see and hear your colleagues or clients in real-time.
How do businesses use video conferencing in their daily operations?
Video calls have replaced many traditional in-person interactions. Here is how they help your business run smoother:
Keeping teams aligned
Whether your team is in the next office or on the other side of the globe, video calls prevent the “out of sight, out of mind” problem. Seeing faces helps catch misunderstandings early — something that often gets lost in long email chains. This keeps projects on track and prevents costly rework.
Building trust with clients
Waiting weeks to schedule an in-person meeting can kill momentum. Video conferencing lets you connect with a client immediately. You can read their body language, share your screen to walk them through a proposal, and build the personal rapport that closes deals. It feels professional and personal, without the travel expense.
Hiring the best talent, faster
You don’t have to limit your hiring to people who live within commuting distance. Video interviews let you conduct thorough, face-to-face assessments with candidates anywhere in the world. This speeds up your hiring process, ensuring you don’t lose top talent to competitors who move faster.
Making decisions when it matters
When a crisis hits or a market opportunity opens up, you can’t wait for your leadership team to gather in a boardroom. Video calls allow you to bring key decision-makers together instantly, so you can act decisively and protect your business interests.
The hidden security risks of video conferencing services
While video conferencing offers huge benefits, it introduces new challenges that many business owners overlook.
Because these conversations travel across the internet, they can be intercepted if not properly secured.
The “open door” problem
Most mainstream video platforms encrypt your call while it travels, but they decrypt it on their servers. This means the company hosting the call — and anyone who hacks their server — could technically access your conversation. If you work with confidential client data or proprietary strategies, this is a significant risk.
Data collection and privacy
Some free or ad-supported platforms collect data from your calls to train their AI or serve you targeted ads. This means your sensitive business discussions could be stored, analyzed, or shared without your explicit knowledge.
Compliance and legal risks
If you operate in a regulated industry (like finance, healthcare, or law), using an insecure platform can lead to serious trouble. Violating data protection laws like GDPR or HIPAA can result in heavy fines, legal liability, and damage to your professional reputation.
The “third-party” trap
Many tools integrate with other apps (like calendars or project management software). While convenient, these third-party connections often operate under their own privacy policies, creating blind spots where your data could be exposed.
How to choose the right video conferencing tool for your business
You don’t need to be a tech expert to make a smart choice. When evaluating video conferencing tools, answer these six questions:
- Does it meet your basic needs?
Strike the right balance between overpaying for features you won’t use and settling for a tool that crashes during a client pitch.
- Is it easy to use?
If your team can join a call in seconds, and where your clients can join without needing to download complex software or create an account, it will become their go-to way to communicate.
- How are your calls secured?
Calls that are end-to-end encrypted means no one in the middle — not even the provider — can see or hear it.
- Where is your data stored?
Data laws vary by country. Providers based in countries with strong privacy laws (like Switzerland) offer better legal protection against government overreach and weak data regulations.
- Is the provider trustworthy?
If a service is free, you might be the product. Check the provider’s reputation. Do they have a history of prioritizing privacy? Are their security claims independently audited?
- Does it integrate safely?
If you need integrations, ensure they don’t create unnecessary security gaps. Sometimes, a standalone secure tool is safer than a “suite” that shares data across many apps.
Protect your business with secure video conferencing software
The “easy” solution is to grab the most popular free tool. But the path of least resistance can come with hidden costs to your security and reputation.
If you treat your client data and business conversations with the same care you treat your physical office, you need a tool built for that level of trust.
Proton Meet was built by the team behind Proton Mail with this exact philosophy. It is designed for businesses that cannot afford to compromise on privacy.
- Encryption by default: Every call is protected with end-to-end encryption. No one — not even Proton — can access your conversations.
- Zero data collection: Your calls are not used to train AI or serve ads.
- Swiss privacy laws: Hosted in Switzerland, your data enjoys some of the strongest legal protections in the world.
- Open source: Our code is open-source for independent experts to audit, proving our security claims.
You can host sensitive business discussions, onboard new hires, or close deals with clients knowing that your conversations remain strictly between you and them.
Frequently asked questions
- What is the difference between video conferencing and video calling?
People often use the terms interchangeably. Generally, “video calling” refers to a one-on-one chat, while “video conferencing” implies a group meeting with features like screen sharing and participant controls. However, most modern tools handle both seamlessly.
- Is video conferencing secure?
It depends entirely on the tool you choose. Many popular platforms are not secure for sensitive business data. Tools like Proton Meet use end-to-end encryption to ensure that only you and your participants can access the call, making it a secure choice for business.
- Which platform is best for video conferencing?
For businesses that prioritize security and privacy, Proton Meet is the top choice. It offers the familiar features you expect — screen sharing, high-quality video, and ease of use — but with a privacy-first design that ensures your data is never sold, shared, or accessed by third parties.
2026-05-29, 15:26
AI compliance is still emerging as a topic, but regulations like the EU AI Act make compliance compulsory.
However, many AI tools weren’t built to be compliance-ready. They log conversations, use your data for training, and provide little transparency about where your data ends up. That creates significant compliance risks for businesses adopting new AI technologies.
This guide explains what AI compliance is, how to choose the right tools, and how to stay compliant over time.
What is AI compliance?
AI compliance means using business AI assistants and other tools responsibly while meeting legal and ethical requirements. It differs from traditional data security compliance.
AI systems don’t just store your data; they also process it and learn from it, which creates new risks for businesses. Your business data could be used to train models, shape their outputs, or even appear in responses for other users.
According to McKinsey’s 2026 AI Trust Maturity Survey, awareness is outpacing action. Across every risk category, mitigation lags behind awareness. For example, 54% of respondents identify personal privacy as a relevant AI security risk, but only 44% are actively working to mitigate it.
AI compliance addresses these risks by focusing on:
- Protecting personal data and privacy
- Securing data against unauthorized access
- Ensuring transparency in AI decision-making
- Preventing discrimination and bias
Why AI compliance matters
The regulatory landscape for AI is evolving quickly, alongside the technology itself. In 2024, the EU AI Act came into effect as the first comprehensive AI regulatory framework.
It bans certain uses of AI and places strict requirements on others. For example, some systems must clearly disclose that people are interacting with AI.
While most countries do not yet have comprehensive AI laws, existing regulations may still apply at national or regional levels. Frameworks like GDPR and HIPAA already restrict how you can use personal data, including in AI systems.
AI compliance is not just about avoiding fines. It also helps you maintain trust and reduce legal risk. If AI systems produce biased or incorrect outcomes, you risk losing customer trust, facing regulatory scrutiny, or opening yourself up to legal action.
How to choose the right AI tools for small businesses
Choosing compliant AI tools isn’t fundamentally different from choosing a tool that handles sensitive data. As we covered earlier, AI systems don’t just store data; they learn from it and can expose it in unexpected ways.
Here’s what to focus on:
Data protection and privacy
Choose tools that encrypt your data and comply with regulations such as GDPR. Vendors should be transparent about where your data is stored, who can access it, and whether it is used to train AI models. Make sure you can delete your data when needed.
Transparency and control
Choose tools that explain how decisions are made and allow for human oversight. This helps you justify outcomes to customers or regulators and ensures you retain control when needed.
Fairness and ethical use
Choose tools that include safeguards to reduce bias and discrimination, especially for sensitive use cases like hiring or customer support. Vendors should also be able to explain how they test for fairness and address issues when they arise.
Compliance support
Choose tools that align with your industry regulatory requirements and provide documentation for audits. This makes it easier to demonstrate compliance, especially in regulated sectors like healthcare.
Best practices for maintaining AI compliance
Choosing the right tools is just one part of the equation. The other half is staying compliant, which requires ongoing effort.
Establish AI guidelines
The infamous 2023 Samsung-ChatGPT leak occurred when employees accidentally shared confidential trade secrets by pasting them into ChatGPT. It’s an incident that could have been prevented with established AI guidelines.
AI guidelines let your team know what’s acceptable and what isn’t when it comes to AI use. Your AI policy should cover which tools are approved, what they can be used for, and what data can and cannot be shared with them. Also, assign someone to maintain and update these guidelines as regulations and technology evolve.
Keep records of AI usage
If you can’t show how AI is being used in your business, you’ll struggle to respond when regulators or auditors ask questions. Track which tools are in use, what decisions they’re influencing, and any significant outputs. Where possible, ask vendors for usage logs and model update reports to simplify documentation.
Minimize and anonymize data
The less personal data you feed into AI systems, the lower your risk. Only share what’s necessary for the task, and strip out identifying details like names and addresses where possible. And make sure you have explicit permission before using customer or employee data with AI tools — don’t assume consent.
Monitor for unfair treatment
AI systems can develop biases from historical data, even when those biases are unintended. You should regularly review output for discriminatory patterns that disadvantage people by age, gender, race, sexuality, or other characteristics.
Amazon scrapped an AI recruiting tool in 2018 after discovering it downgraded resumes from women. The system had been trained on a decade of historical resumes — most from men — and learned to treat male candidates as the standard for success, penalizing resumes that deviated from that pattern.
How Proton helps businesses achieve strong AI compliance
AI may be a new frontier, but the fundamentals of compliance remain the same — strong data management, clear access control, and visibility over how your information is used.
Proton for Business is a suite of team collaboration tools built on these principles and extends them to AI with Lumo, our privacy-first AI assistant.
Keep full control of your data with Lumo
Need to summarize a confidential contract, brainstorm a sensitive business strategy, or analyze financial documents? With most AI tools, that’s risky — your inputs could be logged, used for training, or accessed by third parties.
Lumo is a business AI assistant that lets you work with sensitive information freely. No logs, no training on your data, and everything encrypted so only you can read it.
Manage credentials with Proton Pass
When employees share passwords over email or keep them in spreadsheets, you lose visibility over who has access to what — and that’s a compliance liability.
Our business password manager, Proton Pass, gives you a secure way to manage and share credentials, with clear oversight over access. When someone leaves, revoking their access only takes seconds.
Keep your files private with Proton Drive
Enjoy the productivity benefits of AI without the compliance challenges.
Proton Drive is a business cloud storage solution that integrates directly with Lumo, so your files stay within an end-to-end encrypted environment, allowing you to use AI with client documents or financial records without exposing them to third parties.
Protect your network with Proton VPN
When your team accesses AI tools or business systems from outside the office, unsecured networks create gaps in your data protection.
A business VPN encrypts their connections, keeping sensitive information protected in transit. And with a strict no-logs policy, there’s no record of your team’s activity that could be exposed or subpoenaed.
Backed by Swiss privacy laws
As a Swiss company, Proton operates under strong privacy protections. This limits external access to your data and helps safeguard your business.
Protect your business and ensure AI compliance with a secure business suite
With Proton Workspace, your business gets access to secure email, cloud storage, a password manager, VPN protection, and a private AI assistant. Proton’s entire ecosystem works together to keep your business private and compliant.
2026-05-28, 11:44
The case for leaving Gmail is well-established. Google scans all your Gmail activity to build advertising profiles that follow you across the internet and tie all of your activity to you.
Breaking up with Gmail overnight and making the transition to a privacy-first email provider, however, might not seem so easy, because it means informing all of your contacts and updating your email across possibly dozens of other services. To make switching from Gmail easier, you can now send emails from your Gmail address directly inside Proton Mail.
When you activate this feature, your latest Gmail messages will be imported into Proton Mail, so you have your recent conversations and updates right there with you. New emails received in your Gmail will then continue to appear in your Proton Mail inbox automatically.
Unlike Gmail, Proton doesn’t scan your emails, serve you ads, use your data for AI training, or build profiles on your correspondence. Your inbox is yours, not a data source. And the more you shift to your Proton address, such as services like Netflix and Amazon, the less Google has on you.
A more private way to use Gmail
This new feature allows you to check your Gmail inbox directly from Proton Mail, meaning you don’t need to go back to the Gmail app, which brings about several privacy benefits.
Proton strips trackers, ads and spam from your emails, giving you greater privacy compared to Gmail, which is basically adware. The Gmail app gathers an immense amount of data about you, and by Google’s own admission, uses your approximate location to show you more relevant ads, all of which is prevented by switching to the Proton Mail app.
Google will no longer be able to use your email activity, such as which emails you read and engage with, to build a profile about you. When your friends and family use Proton Mail too, messages exchanged between Gmail addresses connected to Proton become end-to-end encrypted, so Google will not be able to read your data anymore. That’s why it’s worth inviting the people you email most to join Proton and connect their Gmail accounts.
Not on Proton Mail yet? Create a free account.
This feature is rolling out gradually. If you don’t see it in your Proton Mail settings yet, it’s on its way.
Set it up easily
- Open Import via Easy Switch in your Proton Mail settings.
- Connect your Gmail account.
Find out how to move from Gmail to Proton Mail.

Connecting your Gmail does not give Google access to your Proton Mail inbox, so your privacy remains fully intact and protected.
An easier transition towards ditching Big Tech
For privacy and ethical reasons, it is better to ditch Big Tech entirely. Using Gmail from within Proton Mail does not solve some of the longstanding privacy issues with Gmail. Google is still reading every email received by your Gmail account, including any sensitive personal communications you might receive there.
Once your important accounts are updated and Gmail is only getting your spam, you can disconnect Gmail from Proton Mail entirely for a cleaner inbox experience and delete your Google account.
Not on Proton Mail yet? Create a free account.
In addition to Gmail, you can import your emails from Outlook, Yahoo and Apple Mail, using Easy Switch or our import tool, making it easier to consolidate your digital life in one place.
By using Gmail from within Proton Mail, you can gradually transition away. Every account you update to use your Proton Mail address instead of Gmail is one less source of data for Google’s gigantic data harvesting machine.
2026-05-27, 16:00
It’s only getting harder to manage screen time for kids — whether it’s setting up time limits, or making sure they don’t access inappropriate content. Sometimes you’ll think you’ve covered your bases by blocking access to an app (like YouTube or game apps like Roblox), but it turns out they’ve found a workaround by accessing the same content through their browser.
If you need to block a website on your Chrome browser, it’s important to note that Chrome doesn’t have a built-in way to do this, so we’ll share a few different approaches for both desktop and mobile.
Why would I need to block a website on Chrome?
There are any number of reasons why you might want to block websites on Chrome. These might include:
- To block inappropriate content
- To limit screen time
- To prevent access to social media
- To block access to certain games
Blocking access to specific websites can be an important part of your approach to limiting screen time and protecting your child’s mental health.
Options for blocking websites on Chrome
Here’s a quick overview of your options before we go into detail for each one.
| Option | Ease of use | Devices impacted |
| Family Link | Simple | Mobile and desktop |
| Chrome extensions | Simple | Desktop |
| Device-level settings | Simple | Mobile |
| Router-level blocking | Difficult | All devices |
How to block websites on Chrome with Google Family Link
Family Link is the most robust free option for parents, and it’s pretty simple to set up. You can use the Family Link categories to block sites, or add individual websites.
- Create a Gmail account for your child using Family Link
- Open Family Link and select your child’s profile
- Tap Controls > Google Chrome and Web
- Choose one of the existing settings (Allow all sites, Try to block explicit sites, or Only allow approved sites)
- Select Approved sites and Blocked sites under “Manage sites” to add approved and or blocked websites
This option works across desktop and mobile, provided your child is signed into their Google account. If you have an older device, however, you should check to confirm it’s compatible.
Google’s SafeSearch is another feature that helps you manage explicit content in your child’s search results. If your child is logged in to their Google account with their correct age (and is under 18), this feature will already be toggled on to the Filter setting, which blocks any explicit content that’s been detected.

Parent tip: Once your child turns 13 they can opt for an unsupervised Gmail account, meaning you can no longer manage their account. They can then visit the previously blocked websites, and adjust the SafeSearch settings.
How to use Chrome extensions to block websites
Installing a Chrome extension is the most popular method if you only need to worry about desktop solutions. These extensions generally allow you to be more granular about permissions, so you can block websites at certain times (for example overnight, or during homework times) and allow them at others.
- Choose an extension and install it
- Add the URLs for the websites you’d like to block
- Set a password so that your kids can’t disable the extension
- Optional: Set time usage limits for sites, set blocking schedules, or block by category
Some commonly recommended extensions include BlockSite and Stay Focusd, however, you should do your due diligence and make sure the extension you choose meets your needs and gets a good rating in the Google Play or App Store. Note that while many of them are technically free, you’ll probably need to pay in order to block more than one or two sites.

Parent tip: Chrome extensions won’t work if your child switches to another browser.
How to block websites on Chrome Mobile
If you only need to block websites on mobile devices, or want to supplement your Chrome extension solution, here’s how you can go about blocking sites on your child’s mobile device:
Android devices
The Digital Wellbeing and parental controls settings on Android allow you to adjust how long they can spend on each site, but if you’re looking for more targeted control, you’ll need to download Google’s Family Link app, which integrates with Android’s Digital Wellbeing.

Parent tip: Digital Wellbeing’s website filtering applies to the Chrome browser. If your child decides to use a different browser, you may need to block those browser apps entirely through Family Link’s app controls.
iPhone/iPad
The Screen Time settings offer a lot of control over what your kids can see on their devices, including the ability to block websites.
- Navigate to Screen Time, scroll down to Family and select your child’s name
- Scroll down and select Content & Privacy Restrictions
- Ensure this option is toggled on and tap App Store, Media, Web & Games
- Select Web Content and choose your preferred settings
Parent tip: These settings apply to everything on the iPhone or iPad, not just websites accessed using Google Chrome.
How to block websites on Chrome using your router
For parents who want to block sites across every device in the house, including gaming consoles, smart TVs, and more, you may be able to do this by updating your router settings. This is a more advanced option, but most routers have an app you can download, which makes the process slightly easier.
These are the steps for the ASUS router, which allows you to block categories, such as pornography and gambling, rather than specific pages.
- Tap on the Family tab
- Add a profile using the + on the top right of the screen
- Choose the age range that’s appropriate
- Add all the devices that you want grouped under that profile
- Select the time scheduling mode
- Go into the new profile and select Content Block
- Block all relevant categories
We recommend looking up the specific steps for your home router as the level of customization varies across devices and models.
Parent tip: Kids can circumvent router blocks by using mobile data.
What you can’t block (and what to do instead)
Kids are digital natives, and they’re shockingly good at finding workarounds when it comes to technical blockers; lock down Chrome and they may download another browser or use a friend’s device. Parental controls are important, including for social media, but they work best alongside open conversations about internet safety and digital literacy.
If you’re using multiple services to manage your child’s online activity, you may find it useful to use a secure password manager to keep all your logins in one place. Proton Pass also offers a dedicated family password manager that can help you share and manage family logins.
Parent tip: While these are all good options for preventing your child from seeing inappropriate content on Google Chrome, using Google products leaves your child vulnerable to Google’s data collection, tracking, and profiling. You may want to consider looking into a privacy-focused browser..
FAQ: Blocking websites on Chrome
Can I block websites on Chrome without an extension?
Yes, the best way to block websites on Chrome without an extension is to use the Family Link app.
How do I block websites on Chrome on my child’s phone?
To block websites on your child’s phone, you can use the Family Link app on Android or iOS, or update the Screen Time settings on iOS devices.
How do I stop my child from unblocking websites?
The Family Link restrictions are tied to your Google account, so your child can’t change Chrome’s filter settings without parental approval. However, this doesn’t mean they won’t attempt to access websites on a browser other than Chrome, or on a device that isn’t covered by parental controls. It’s best to pair technical solutions with conversations around what’s appropriate and why.
Does blocking work in incognito mode?
If your child is signed in to Chrome with an account managed by Family Link, then incognito mode is not available to them.
Is there a free way to block websites on Chrome?
Yes, Family Link is free, and there are some Chrome extensions that offer basic site blocking at no cost, although you’ll have to pay to get the really useful features.
2026-05-27, 15:18
Who doesn’t love snagging a bargain online? It’s easy on the wallet, kinder to the planet, and you often uncover unique pieces. But buying from strangers on the internet carries risks that you rarely encounter in brick‑and‑mortar stores or with established brands.
To help you shop safely, we’ll share the most common fraud tactics you’ll find on Facebook Marketplace, how to report sellers, and some clear, actionable steps to stay safe while shopping on the platform.
What is Facebook Marketplace?
Facebook Marketplace is the social network’s built-in classifieds hub, allowing anyone to list or browse items within their Facebook account. Because listings are linked to a real Facebook profile, you can see the seller’s name, profile picture, and any mutual friends.
This information can lend a sense of legitimacy, but can also be fabricated by scammers who exploit the platform’s openness. Fake messages and fake ads on Facebook and sister company Instagram have proliferated in recent years. In 2025, reporting from Reuters proved that scam ads actually account for 10% of Meta’s income.
Common Facebook Marketplace scams and how to avoid them
There are endless ways scammers can try to defraud genuine buyers and sellers on Facebook Marketplace, but these are some of the more common scams to watch out for.
Gift card payment scams
Target: Buyers and sellers
There are a few variations on this scam:
- After agreeing to purchase an item, the bogus buyer claims to have “accidentally” sent too much money. They ask for a refund of the excess amount, often via a gift card code, but after the seller provides the refund, the original payment is reported as fraud and reversed.
- The bogus seller requests payment via a gift card instead of a payment platform that offers buyer protection. The scammer immediately uses the gift card, doesn’t send the item, and the buyer has no recourse to recover the money.
- The bogus seller is offering a gift card below cost, for example, a $100 App Store gift card for $80. After the buyer purchases it, they discover the gift card is fake or already used.
Too-good‑to‑be‑true pricing
Target: Buyers
You come across a listing for something where the price is far below market value. After you pay, the seller disappears, or the item delivered is counterfeit or of poor quality.
Deposit scams
Target: Buyers
Often combined with the pricing scam, a seller will list an item at an incredibly low price. They then claim they’ve had a lot of interest in the item and will require you to pay a deposit to hold it, or miss out. Once the buyer pays the deposit, the listing and the seller will disappear.
Phishing scams
Target: Buyers and sellers
Scammers masquerade as buyers or sellers to send convincing “secure checkout” links to make or request payment. Because the interaction happens through Messenger, it’s easy for the target to assume a malicious link is valid. If you manually enter your details into the bogus link (rather than using a password manager), you may unwittingly share your private credentials with the scammer.
Facebook Marketplace scam red flags
These signs aren’t definitive confirmation of a scam, but rather a sign to proceed with caution.
Payment requests with no buyer protection
Payment methods that don’t offer buyer protection include PayPal Family and Friends, wire transfers, gift cards, and cash.
Stock photos of items in listings
You can ask the seller to take some new photos of the item, and if you’re suspicious, ask them to include a piece of paper with the date and their name written on it in the photo.
Urgent language
Anything that requires you to act fast and bypass your better judgment or normal processes should be a red flag.
Newly created Facebook accounts
Scammers often have to create new accounts after being reported. A newly created profile, with very few friends or followers and no other listings, is a definite red flag.
Your password manager doesn’t autofill your credentials
If you have a PayPal account but your password manager doesn’t fill in your details when you use the PayPal link the seller shares, the link may be a phishing or spoofed site. When a password manager refuses to autofill, it means the URL you’re looking at doesn’t match the legitimate PayPal domain (paypal.com vs. paypa1.com).
Which payment method should you use on Facebook Marketplace?
Choosing the right way to send and receive money is the biggest factor in staying safe on Facebook Marketplace. We’ve outlined the most common options, the protection each offers, and the red flags to watch for.
| Payment option | How it works on Marketplace | Buyer‑protection level | When to use | Red flags |
| Meta Pay (formerly Facebook Pay) | Built into the Messenger checkout flow, you link a credit/debit card or bank account once and then pay with a single tap. | Full protection; Meta handles disputes, and you can request a refund if the item isn’t delivered or is not as described. | Ideal for most transactions, provided both parties have access to it. | Be sure the payment screen shows the official Meta Pay branding and correct URL. |
| PayPal – Goods & Services | Select the “Pay for goods/services” option to ensure the payment goes through PayPal’s protected channel. | Full protection; you can open a dispute within 180 days, and PayPal may reimburse you if the seller fails to deliver. | Good for higher‑value items or when parties don’t have access to Meta Pay. | Scammers often request to use the Friends & Family option, as it doesn’t offer buyer protection. |
| Credit or debit card | Enter card details on the Meta Pay checkout or a seller‑provided secure payment page. | Card‑issuer chargeback rights; most banks allow you to dispute unauthorized payments or undelivered goods. | Useful when the seller insists on a custom checkout page that you recognize as legitimate (for example, a verified Stripe link). | Beware of unfamiliar URLs that mimic PayPal or Stripe; a password manager will refuse to autofill on mismatched domains. |
| Apple Pay / Google Pay | Mobile wallets that tokenize your card details; supported where the seller uses Meta Pay or a compatible checkout. | Same protection as the underlying card, plus tokenization reduces exposure of your raw card number. | Convenient for mobile‑first shoppers who already have these wallets set up. | Only use when the checkout clearly indicates Apple Pay or Google Pay; never click a link that redirects to a plain‑HTML “payment” page. |
| Cash | Hand the money to the seller when you meet at a public location. | No digital protection – you rely entirely on the physical exchange. | Acceptable for large items where postage isn’t an option. | Avoid meeting in secluded places, and take someone with you if possible. |
How does a password manager help protect against Facebook Marketplace phishing scams?
By pairing a protected payment method with a robust password manager like Proton pass, you dramatically reduce the attack surface that scammers rely on.
Domain‑locked autofill: Your credentials are injected only on the exact URL you saved. If a scammer sends a fake PayPal link, the manager won’t fill in your password, alerting you to the mismatch.
Secure vault for payment details: Store credit card numbers, billing addresses, and even one‑time virtual cards in an encrypted vault. You can copy‑paste the data into a verified checkout without ever typing it on a malicious page.
Unique passwords per service: If a phishing site somehow captures a password, the breach won’t affect your other accounts because each service uses a distinct login.
How to report a Facebook Marketplace seller or listing
Reporting a listing on the Facebook app
- Select the Marketplace icon
- Open the listing you want to report
- Tap the three dots on the top right corner
- Select Report listing

Reporting a seller on the Facebook app
- Select the Marketplace icon
- Open a listing from the seller you want to report
- Scroll down to the seller details and tap on the seller name
- Tap the three dots next to View profile
Select Report.

Reporting a seller or listing on the Facebook website
- Open Marketplace
- Open the listing you want to report
- Tap the three dots on the top right corner
- Select Report listing or Report seller
Alternatively you can report from within your Facebook Messenger chat window, by tapping the three dots, and selecting Report.

Best practices for staying safe on Facebook Marketplace
So, is Facebook Marketplace safe? With the right precautions, the answer is a qualified yes.
Here are some easy ways to make your shopping experience safer:
- Always use a payment gateway with buyer and seller protection and verify any payment links shared by sellers.
- Do your due diligence — check the Facebook profile of the person you’re dealing with to see if it’s newly created, has any reviews, and whether any other items have been listed, bought, or sold.
- Don’t give out bank details, phone numbers, or other personal information, and use a password manager to keep your private information secure.
- If you’re meeting in person, choose a public, well‑lit spot like a coffee shop (if possible), bring a friend, and inspect the item properly before paying.
2026-05-27, 14:37
Changing your WiFi password every 3-6 months is considered best practice, but many of us are guilty of setting and forgetting. It’s not hard to update, though, and can protect you from security headaches ranging from bandwidth theft to device exploitation.
We’ll cover which scenarios prompt a WiFi password reset and how to reset your password on your router and update it across your devices.
When it’s a good idea to change your WiFi password
Changing the WiFi password on popular home routers
Changing WiFi password on Windows 10/11
Changing WiFi password on macOS
Changing WiFi password on Android
Should I change my WiFi network name (SSID)?
When it’s a good idea to change your WiFi password
Aside from updating your WiFi password every 3-6 months, some specific events should trigger a password reset.
After a guest leaves
If you share your WiFi password with anyone who’s not a member of your household, you’ll want to change it after they leave. At the same time, you could set up a guest account for future guests.
If you suspect a device is compromised
A compromised device can capture your WiFi password, sniff traffic, or act as a bridge for attackers to reach other devices on the same network.
When you receive a firmware update that resets settings
It might be tempting to ignore updates, but router manufacturers regularly issue firmware updates to patch security vulnerabilities, improve stability, or add new features.
If you notice unknown devices on your network
It’s a good idea to check your network devices periodically. Seeing unfamiliar MAC addresses or device names in your router’s connected‑device list is an indication that someone may have joined your WiFi without permission.
Changing the WiFi password on popular home routers
Many routers have a dedicated app for managing them. Using the app is generally recommended over the website, and makes it fairly straightforward to see devices and traffic on your network, as well as to change your password and network name.
ASUS routers
ASUS has one app that works across all ASUS routers, available for download from their website, the App Store, or Google Play.
- Open the app and select Settings
- Select WiFi > Wireless Settings > Network Settings
- Add your new password in the Network Key field
- Tap Apply
(Steps may vary slightly depending on your firmware.)
What if I can’t use the app?
- Connect your computer to your router
- Open a browser and go to http://www.asusrouter.com or type your router’s IP address directly
- Log in using your router username and password
- Navigate to:
For firmware (>3.0.0.6.102_35404): Network > Main network profile
For firmware (<3.0.0.6.102_35404): Wireless > General
- Select WPA Pre-Shared Key (Password) and enter your new password
- Click Apply
NETGEAR routers
NETGEAR has separate apps for Nighthawk and Orbi Mesh routers. Select your NETGEAR router type and download the app from their website, the App Store, or Google Play. Although the apps are different, the steps are the same.
- Open the app and select WiFi Settings
- Select the WiFi network you want to update
- Enter your new password
- Tap Save
What if I can’t use the app?
- Connect your computer to your router
- Open a browser and go to the appropriate URL or type your router’s IP in directly
Nighthawk: www.routerlogin.net or www.routerlogin.com
Orbi: www.orbilogin.com
- Log in using your router username and password
- Nighthawk: Select Wireless
- Omni: Select Basic > Wireless
- Enter your new password in the Password (Network Key) field
- Click Apply
Verizon routers
Download the Verizon Home app – available in the Apple App Store and Google Play.
- Launch the app and log in with your My Verizon credentials
- In Connections, tap Network
- Select Primary tab > Edit Wi-Fi
- Enter your new password in the Wi-Fi password field
- Tap Save changes
What if I can’t use the app?
As long as you don’t have a Fios Quantum Gateway or a Verizon Fios Advanced router, you should be able to change the WiFi password manually.
- Open a browser and enter 192.168.1.1
- Log in using your router username and password
- Follow the onscreen directions (or refer to your router user guide)
TP-Link routers
You can download TP-Link’s Tether app from their website, the App Store, or Google Play.
- Launch the app and log in with your TP-Link credentials
- Tap Tools > Wireless
- Enter a new password in the Password field
- Tap Save
What if I can’t use the app?
- Connect your computer to your router
- Open a browser and go to http://tplinkwifi.net or type your router’s IP address directly
- Log in with your router username and password
- In the left‑hand menu, select Wireless > Wireless Settings
- Enter your new password in the Password / Pre‑Shared Key field
- Click Save
If your router isn’t included here, you should be able to find the instructions by searching “[router name] change WiFi password” or similar.
And of course, once you’ve changed your WiFi password on your router, you’ll need to update the password in your password manager and across your devices.
Changing WiFi password on Windows 10/11
- Click the WiFi icon in the taskbar and select Network & Internet settings
- Choose Wi‑Fi > Manage known networks
- Find your network and click the three‑dot menu > Forget
- Return to the WiFi icon, click your network name, and enter the new password
- Select Connect automatically if you want to auto-join in the future
Changing WiFi password on macOS
- Open System Settings > Wi-Fi
- Next to your network name, select Details…
- Scroll to the bottom and select Forget This Network… > Remove
- Reselect your network and enter your new password
- Select Remember this network to auto-join in the future
Changing WiFi password on Android
- Open Settings > Network & internet > WiFi
- Tap the gear icon next to your network > Forget
- Select the network name and enter your new password
Changing WiFi password on iOS
- Open Settings > Wi‑Fi
- Tap the information button next to your network and choose Forget This Network > Delete > OK
- Return to the Wi-Fi screen, tap your network name, and type the new password
- Select Auto‑Join if you want your device to reconnect automatically
We’ve also written a guide about how to share your WiFi password.
Should I change my WiFi network name (SSID)?
Your WiFi network name, officially known as the service set identifier (SSID), doesn’t need to be changed regularly, but you should change your SSID from the default setting.
SSID best practices
- Skip the generic router labels. Names like “NETGEAR_47” or “Linksys123” hand over clues to anyone scanning for networks. Pick a unique, non‑descriptive SSID that doesn’t give attackers a head start.
- Give your network a distinct identity. Changing the default SSID thwarts “Evil Twin” attacks, where malicious actors clone popular router names to lure unsuspecting users onto a rogue hotspot.
- Don’t rely on hiding alone. Disabling SSID broadcast adds a layer of obscurity, but it isn’t a real security barrier. Skilled adversaries can still discover hidden networks with the right tools.
- Keep personal details out of the mix. Avoid using your name, street address, birthdate, or any other identifying information in the SSID. A clean, anonymous network name protects your privacy and reduces the risk of targeted attacks.
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
3. SPREAD PRIVACYby DuckDuckGoWide range of security and privacy topics.
2026-03-18, 13:29
- The DuckDuckGo subscription includes our VPN, access to more advanced private AI when you want it, Personal Information Removal, and Identity Theft Restoration. It now comes in two plans: Plus, which includes all four protections, and Pro, which unlocks even more powerful AI functionality.
- The new Pro plan is for people who use AI for demanding tasks. On top of the VPN and other protections, it includes three Duck.ai upgrades: 2x higher usage limits than Plus, exclusive access to Claude Opus 4.6, and the highest reasoning available on Duck.ai. (Extended reasoning capabilities available on GPT-5.2 and Claude Opus 4.6.)
- Whether or not you’re a paid subscriber, everyone gets the same industry-leading privacy protections when you search and browse with DuckDuckGo, or chat privately with ChatGPT, Claude, and other popular AIs on Duck.ai.
What is the DuckDuckGo subscription?

The DuckDuckGo subscription is a four-in-one privacy service that gives you extra protection beyond what's available for free in our web browser, search engine, and private AI chat, Duck.ai. It includes our VPN to encrypt your Internet connection, access to more advanced private AI when you want it, Personal Information Removal to help combat identity theft and spam, and Identity Theft Restoration.
The original DuckDuckGo subscription is now called Plus. (If you’re a current subscriber, this is what you have!) It includes all four protections and costs $9.99 USD/month or $99.99 USD/year. Enhanced with more powerful AI tools, the new Pro plan is $19.99 USD/month or $199.99 USD/year. Subscriptions are available in the U.S., Canada, the E.U., and the U.K. See this help page for international pricing and feature availability.
What are the benefits of the Pro plan?
On Duck.ai, anyone can chat privately with ChatGPT, Claude, and other popular AIs, whether you have a subscription or not. Text chat, voice chat, and image generation are free to use within daily limits. DuckDuckGo subscribers on the Plus plan can do more, with higher usage limits and access to smarter AI models with extended reasoning. But the Pro plan is even more powerful.
We designed Pro for people who use AI frequently throughout the day, or for more demanding tasks that require multi-step reasoning…or both! Subscribers to the Pro plan get three additional Duck.ai upgrades:
- 2x higher usage limits, compared to Plus. This includes text chat, voice chat, and image generation limits across all the AIs available.
- One Pro-exclusive model, currently the newly launched Claude Opus 4.6.
- Access to the highest reasoning available in Duck.ai. Extended reasoning capabilities on GPT-5.2 and Claude Opus 4.6 let the AI spend more time thinking through complex, multi-step problems before responding.
This new Pro plan gives you the freedom to dive deep and iterate back and forth for complicated tasks, whether you’re fine-tuning images, analyzing data, writing long-form content, or making an in-depth plan. Higher limits also mean you don’t have to pick and choose as much; you can use AI for a broad range of day-to-day tasks.
When you take advantage of the extended reasoning on GPT-5.2 or Claude Opus 4.6, you’re more likely to get considered, relevant, and well-structured answers to even very complex prompts. And thanks to the Pro plan’s higher usage limits, you’re less likely to be disrupted in the middle of a complicated job.
Which plan is right for me?
If you primarily use DuckDuckGo to search and browse, and you’re not interested in advanced AI chat or added protections…our free offerings may meet all your needs. If you want to expand your privacy protection with our VPN, or you’re getting more into AI productivity tools, consider Plus! Pro is most suited if you use AI for tasks that require deeper context and multi-step reasoning.
The specific AI models included in each plan are upgraded regularly; at the time of publication, the lineup is as follows:
- Free on Duck.ai: GPT-4o mini, GPT-5 mini, GPT-OSS 120B, Llama 4 Scout, Claude Haiku 4.5, Mistral Small 3.
- Plus: GPT-4o, GPT-5.2 (reasoning), Claude Sonnet 4.5, Llama 4 Maverick, free models.
- Pro: GPT-5.2 (extended reasoning), Claude Opus 4.6 (extended reasoning), Plus and free models.
Can I upgrade an existing subscription?
Yes! As a subscriber, you can switch between the Plus and Pro plan at any time. In the DuckDuckGo browser, go to Settings > DuckDuckGo Subscription. Select View All Plans, pick the plan you'd like to switch to, and proceed to payment or confirm. In third-party browsers, start by navigating to Duck.ai. Just go to Settings & More > Manage Subscription and follow the same steps above.
Ready to give it a try? Head to duckduckgo.com/subscribe to see if the Plus or Pro subscription is right for you!
2025-09-30, 13:00

2025 marks DuckDuckGo's 15th year of donations—our annual program to support organizations that share our vision of raising the standard of trust online. We are proud to donate to a diverse group of organizations around the world that promote privacy and security, digital competition, and a healthier online ecosystem.
This year, we’re donating $1,100,000, bringing DuckDuckGo's total donations since 2011 to $8,050,000. Everyone using the Internet deserves simple and accessible online protection; these organizations are all pushing to make that a reality. We encourage you to check out their valuable work below.
$100,000 to Public Knowledge

Public Knowledge promotes freedom of expression, an open internet, and access to affordable communications tools and creative works. We work to shape policy on behalf of the public interest.
$75,000 to ARTICLE 19
ARTICLE 19 is an international think-do organisation, that takes its name from the Universal Declaration of Human Rights, and works to propel the freedom of expression movement, fighting censorship, defending dissenting voices and advocating against laws and practices that silence.
$75,000 to the Digital Progress Institute
The Digital Progress Institute seeks to bridge the tech-telecom policy divide through incremental, bipartisan measures in line with its principles of bringing about ubiquitous broadband, 5G and beyond, privacy for every American, real competition in digital markets, and a full-stack framework for Internet policy issues.
$50,000 to the Electronic Frontier Foundation (EFF)
EFF's mission is to ensure that technology supports freedom, justice, and innovation for all people of the world.
$50,000 to European Digital Rights (EDRi)
With more than two decades of advocacy experience, European Digital Rights (EDRi) is the go-to, nongovernmental network working on EU and national laws and policies on privacy, freedom of expression, participation online, data protection and technology policy. EDRi unites over 50 organisations from across Europe (and beyond).
$50,000 to the Foundation for American Innovation

The Foundation for American Innovation, a think-and-do tank based in Washington, D.C. and San Francisco, CA, advances technology, talent, and ideas that support a better, freer, and more abundant future.
$50,000 to the Open Home Foundation

The Open Home Foundation fights for the fundamental principles of privacy, choice, and sustainability for smart homes - and for every person who lives in one. It is best known as the organization that owns and governs Home Assistant, among many other projects crucial to the open home.
$50,000 to Signal
Signal Technology Foundation protects free expression and enables secure global communication through open source privacy technology.
$50,000 to the Surveillance Technology Oversight Project (S.T.O.P.)
The Surveillance Technology Oversight Project (S.T.O.P.) advocates and litigates for privacy, working to abolish local governments’ systems of discriminatory mass surveillance that disproportionately impact vulnerable communities.
$50,000 to Tech Policy Press
Tech Policy Press publishes reporting, analysis, and perspective on events, issues, and ideas at the intersection of technology and democracy.
$50,000 to the Tech Oversight Project

Through engaging with lawmakers, exposing false narratives and bad actors, and pushing for landmark legislation, the Tech Oversight Project seeks to hold tech giants accountable for their anti-competitive, corrupting, and corrosive influence on our society and the levers of power.
$30,000 to the Internet Security Research Group
Our mission at ISRG is to reduce financial, technological, and educational barriers to secure communication over the Internet. We operate three projects (Let’s Encrypt, Prossimo, and Divvi Up) that improve the security and privacy of billions of people using the Internet.
$25,000 to Algorithmic Justice League (AJL)

The Algorithmic Justice League is on a global mission to prevent AI harm using research, advocacy, and art.
$25,000 to the British Institute of International and Comparative Law (BIICL)
The British Institute of International and Comparative Law (BIICL) hosts the Competition Law Forum, a centre of excellence for European competition and antitrust policy and law.
$25,000 to Bull Moose Project

The Bull Moose Project Foundation develops and promotes policies that promote fair markets, support American innovation, and hold Big Tech accountable for anti-competitive and anti-consumer conduct.
$25,000 to Canadian Anti-Monopoly Project

The Canadian Anti-Monopoly Project (CAMP) is a think tank dedicated to addressing the issue of monopoly power in Canada and around the world. CAMP produces research, commentary, and policy to make our economies more fair, free, and democratic.
$25,000 to Consumers International
Consumers International is the global membership organisation for consumer rights groups. Founded in 1960, we bring together over 200 member organisations in more than 100 countries, with a mission to empower and champion the rights of consumers everywhere and to build a fair, safe and sustainable marketplace.
$25,000 to Demand Progress

DPEF empowers people to understand how our communications and governance systems should serve democracy — and how corporate power threatens our economy and our democratic future.
$25,000 to Digital Rights Watch

Digital Rights Watch is Australia's leading digital rights organisation. They defend and promote privacy, democracy, fairness and fundamental rights in the digital age.
$25,000 to Gesellschaft für Freiheitsrechte (GFF)
The Society for Civil Rights e.V. (Gesellschaft für Freiheitsrechte e.V. or "GFF") is a donor-funded organization from Germany that defends fundamental and human rights by legal means. The organization promotes democracy and civil society, protects against disproportionate surveillance and advocates for equal rights and social participation for everyone.
$25,000 to noyb
noyb is committed to the legal enforcement of European data protection laws and has filed more than 850 cases against numerous intentional infringements by Big Tech companies - to make online privacy a reality for everyone.
$25,000 to the Internet Archive
The Internet Archive's mission is to provide “Universal Access yo All Knowledge” by preserving and providing free access to digital materials and cultural heritage serving as a digital library for researchers, historians, scholars, and the public to read, learn, and explore for free.
$25,000 to the Open Rights Group (ORG)

Open Rights Group is the UK’s largest grassroots digital rights campaigning organisation, working to protect everyone’s rights to privacy and free speech online.
$25,000 to the Open Source Technology Improvement Fund (OSTIF)
In the past year, OSTIF collaborations led to the fixing of over 130 findings with security impact. Our security uplifts to open source projects wouldn't be possible without the continued support from DuckDuckGo. We are honored to be part of this program and contribute to a more secure Internet ecosystem.
$25,000 to Perl and Raku Foundation
The Perl and Raku Foundation is dedicated to the advancement of the Perl and Raku programming languages, through open discussion, collaboration, design, and code.
$25,000 to Privacy Rights Clearinghouse
Privacy Rights Clearinghouse focuses on increasing access to information, policy discussions, and meaningful rights so that data privacy can be a reality for everyone.
$25,000 to Restore the Fourth

Restore the Fourth advocates with federal, state and local elected officials, to defend privacy and freedom from unreasonable government surveillance.
$25,000 to the Tor Project
At the Tor Project, we believe everyone should be able to explore the internet with privacy. We advance human rights and defend your privacy online through free, open source software and the decentralized Tor network.
$20,000 to The Markup
The Markup challenges technology to serve the public good by producing investigative journalism, unique tools, and accessible resources to inspire action and agency.
2025-09-04, 11:05
- More advanced AI models from OpenAI, Anthropic, and other providers are now available in Duck.ai as part of the DuckDuckGo subscription, formerly known as Privacy Pro.
- Subscribers can now access OpenAI’s GPT-4o and GPT-5, Anthropic’s Claude Sonnet 4, and Meta’s Llama Maverick – and supercharge productivity at work, school, or home.
- The DuckDuckGo subscription is still the same price: $9.99 USD a month or $99 USD a year. On top of access to premium AI models on Duck.ai, it still includes our VPN, Personal Information Removal, and Identity Theft Restoration*. Sign up at duckduckgo.com/subscribe for a seven-day free trial.
- Keep an eye out for higher DuckDuckGo subscription tiers in the future with access to even more advanced AI models.
A layer of protection for everything you do online – including AI
We believe the best way to protect your personal information from hackers, scammers, and privacy-invasive companies is to stop it from being collected at all. To make that happen, we offer a layer of protection for everything you do online. Our browser, for example, is packed with a suite of built-in privacy protections, including our search engine that never tracks you. Our growing suite of private, useful, and optional AI tools is the next evolution.
AI tools have quickly become a significant part of people's online experience, but there’s a gap between how often we use AI, and how safe and in control we feel about it. According to recent Pew research, 27% of US adults use AI tools every day, but 59% feel no control over how AI shows up in their lives. That's why we created Duck.ai, which gives you access to popular AI models from OpenAI, Anthropic, Meta, and Mistral, with the following added protections built by us:
- Anonymized chats. We call model providers on your behalf, so personal information like your IP address is not exposed to them.
- No AI training. Your data is never used to train the AI models.
- Local chat storage. Chats and settings stay on your device to protect your privacy.
- Instant deletion. Erase your chat history in a flash with our Fire Button.
Today, we're expanding Duck.ai by giving DuckDuckGo subscribers access to more advanced AI models, covered by the same strong protections. The base version of Duck.ai is not changing; it’s still free to use, with no account necessary. We’re just adding more models for subscribers. You can see which models are available with and without a subscription here.
Please note that Duck.ai is always optional, whether you’re a subscriber to DuckDuckGo or not. If AI is not for you, you can hide the AI buttons and features from your search settings and your desktop and mobile browser settings. If you use the VPN, for example, but you’re not interested in anonymized AI chat, that’s no problem. Just head to your browser’s Settings menu to turn off the AI features and continue using your VPN normally.
What does the DuckDuckGo subscription include?
Formerly known as Privacy Pro, the DuckDuckGo subscription expands the great protection you get from DuckDuckGo’s free offerings, covering even more of what you do online:
- DuckDuckGo VPN. Built for speed and simplicity, the DuckDuckGo VPN secures your WiFi connection on your entire device, hiding your location and IP address from the sites you visit. Includes full-device coverage on up to five devices at once. Learn more.
- Personal Information Removal. Helps remove personal information like your name, address, and family connections from people search sites that store and sell it, helping to combat identity theft and spam. Available for Mac and Windows.* Learn more.
- Identity Theft Restoration. If your identity is stolen, get expert guidance as you get back on track. Brought to you by Iris (Iris Powered by Generali) — a world leader in identity theft restoration.* Learn more.
- NEW: More Advanced AI models. Subscribers can now access OpenAI’s GPT-4o and GPT-5, Anthropic’s Claude 4 Sonnet, and Meta’s Llama Maverick, in addition to all the free-tier chat models. Models are updated regularly. See the full list here.
The price is staying the same in all regions: $9.99 USD/month or $99 USD/year, with international pricing information available on this help page.
Achieve more with advanced models
More advanced AI models like OpenAI’s GPT-4o are built to handle more complicated tasks than their smaller counterparts like GPT-4o mini. These bigger models are better at following detailed instructions, maintaining context through extended chats, and delivering deeper, more nuanced responses. The DuckDuckGo subscription offers a way to use some of these models, but with more privacy. Even larger and more highly advanced models will be made available through higher subscription tiers in the future.
If you’re a frequent user of different advanced chatbots, the DuckDuckGo subscription is an easy one-stop solution. It lets you access multiple premium models in one place, rather than juggling multiple subscriptions and apps. Your subscription lets you visit Duck.ai and use those premium models in any browser you like. But it's especially convenient within the DuckDuckGo browser, where Duck.ai is seamlessly integrated on both desktop and mobile. Using the DuckDuckGo browser, you can access AI chat when and where you need it, getting support for specific tasks without switching platforms. And as always, it’s completely optional – you can adjust or turn off Duck.ai’s integrations from your browser’s settings menu.
Whether you subscribe for premium models or stick with the free tier, you get the same strong privacy protections.
Is the DuckDuckGo subscription worth it?
When you get a DuckDuckGo subscription, you get instant, full access to any or all the features you want, without complex add-ons – at a price competitive with any of the individual features on their own. The $9.99 USD monthly price tag is more cost effective than maintaining multiple separate AI subscriptions – many of which are in the $20/month range. (See this help page for more international pricing information.)
Additional features like the DuckDuckGo VPN and Personal Information Removal service add value and convenience – and everything is available in one place, your DuckDuckGo browser.
Want to give it a try for free? You can get a 7-day trial of the subscription in the DuckDuckGo Browser's settings. In the US, you can also access the 7-day trial at DuckDuckGo.com/subscribe.
How to access Duck.ai and activate your subscription
Duck.ai can be accessed from any browser. Just visit duck.ai or hit the Duck.ai button on any search engine results page on duckduckgo.com. From there, paid subscribers can head to Duck.ai Settings, click “I Have A Subscription”, and follow the prompts to access the premium models.
If you are using the DuckDuckGo browser, you can use more subscription features, like the VPN and Personal Information Removal*. You also have even more ways to get to Duck.ai! You can click the optional Duck.ai buttons in our desktop and mobile browsers, use one of our iOS widgets, or press and hold the DuckDuckGo icon on iOS or Android. However you get there, the process for activating your subscription is the same.
Learn more about the DuckDuckGo subscription and sign up at duckduckgo.com/subscribe
*The DuckDuckGo subscription is available in the U.S., Canada, the E.U. and the U.K. All subscribers can use the VPN and access the same premium AI models, regardless of region. Personal Information Removal is available to U.S.-based subscribers. Identity Theft Restoration coverage varies by region. Learn more here.
2025-08-05, 20:09

Privacy Pro is our privacy-protecting subscription service that includes the DuckDuckGo VPN, Personal Information Removal to protect yourself from data brokers, and Identity Theft Restoration, which you can call if your identity is ever stolen.
In the year since we launched Privacy Pro, we’ve been working hard behind the scenes to make it more comprehensive, more powerful, and easier to use. Have you been waiting for the perfect moment to sign up? Good news: you can now try Privacy Pro free for 7 days. The free trial is available on all platforms – sign up here to redeem the offer. After your free trial, you can continue at $9.99 USD/month or $99.99 USD/year. (International pricing information here.)
Here’s a look at the major improvements we’ve made in the past year! To learn even more about Privacy Pro, you can visit our blog and Help Pages.
Overall Improvements
International Availability
Privacy Pro subscriptions are now available in the U.S., E.U., Canada, and the U.K. Features and coverage vary by region, but the DuckDuckGo VPN works the same in all regions. You can now use Privacy Pro in more languages including Dutch, French, German, Italian, Polish, Portuguese, Russian, and Spanish. Learn more about using Privacy Pro outside the U.S. here.
DuckDuckGo VPN Improvements
More Server Locations
DuckDuckGo VPN users can now choose from more than 40 locations in 30+ countries. Check out the full list here.
Independent Security Audit
We partnered with Securitum to conduct a comprehensive security audit of the DuckDuckGo VPN and supporting infrastructure. We're pleased to report that it found no critical vulnerabilities, underscoring the strong security measures we have in place for our VPN! Visit this help page for a summary of the key findings, remediations, and accepted risks, plus a link to the full report.
Block Risky Domains Automatically
The DuckDuckGo VPN now automatically blocks known phishing, malware, and scam sites – no matter what browser you're using. This new setting is on by default on all platforms.
Now On All Platforms: VPN Notifications
All users can now get notifications that display VPN status at a glance. These notifications are on by default but can be disabled in your VPN Settings.
Desktop: Automatic VPN Connection
All desktop users now have a setting that lets the VPN connect automatically when you log in to your computer.
Desktop: Introduced App and Website Exclusions
Because some apps and websites aren’t compatible with VPNs, we made sure you can exclude them from our VPN. This lets you use those incompatible apps and websites on desktop without disconnecting from the VPN. (App exclusions are also available on Android. Not compatible with iOS.) Manage website and app exclusions in your VPN settings; you can also manage website exclusions by clicking on the VPN icon in the toolbar.
IOS: VPN Widgets and Siri Shortcuts
We created VPN widgets for the iOS home screen and Control Center, so you can quickly connect or disconnect from the VPN and see your VPN connection status at a glance. We also added a Siri Shortcut.
Mobile: VPN Snooze
Both iOS and Android users can now “snooze” the VPN for easier access to sites and apps incompatible with VPNs.
Android: Automatically Pause VPN During Wi-Fi Calls
To help avoid dropped calls on Android, we introduced a setting that temporarily snoozes the DuckDuckGo VPN during Wi-Fi calls. The best part? We automatically restore your VPN connection when you end your call.
Android: Implemented Auto-Excluded Apps
Our new auto-exclude feature on Android automatically detects apps that aren’t compatible with VPNs and bypasses them, so you won’t need to manually adjust settings. (If you would like to adjust this feature, you can! Just go to Settings > VPN > Manage Apps.)
Custom DNS for Windows, iOS, Mac, and Android
You can now switch between the default DuckDuckGo DNS resolvers and a custom DNS resolver of your choosing in VPN Settings > Advanced Settings.
Personal Information Removal Improvements
New Personal Information Removal Dashboard
We completely redesigned the Personal Information Removal dashboard to give Privacy Pro subscribers more insight into the data removal process. You can more easily see when a site was last scanned, how many records have been removed, which sites are clear of your personal information, and more.
Personal Information Removal Request Timeline
Monitor your data broker removal requests with our new Removal Request timeline. You can track the progress of each request, see when your data has been removed, and get help with next steps if any removals take longer than expected.
More Data Brokers Covered
Privacy Pro now covers over 80 data broker sites and counting, including FastPeopleSearch, MyLife, and OfficialUSA.com. Check out the full list here. Some competitors only re-scan data broker sites on a monthly or quarterly basis…or not at all! But we re-scan the sites every 10 days, submitting new removal requests if your data has reappeared.
Improved Scan Performance
Personal Information Removal now more reliably detects when your information has been removed from the data broker sites. Your first scan after signing up or updating your profile now happens 10x faster than before.
What’s Next for Privacy Pro?
Even more improvements are coming soon. We’re working on adding an upgraded AI chat experience to your subscription, with anonymized access to more advanced chat models than the free version on Duck.ai. We’re adding more data brokers to Personal Information Removal all the time, and we’re working on bringing the feature to mobile. Your feedback helps us catch and address bugs, too – so keep it coming!
Go here to redeem your free trial today. Follow us on social [Reddit/X/Facebook/Linkedin] for updates about all things DuckDuckGo, including more Privacy Pro improvements.
2025-07-22, 19:24
Have you been using the DuckDuckGo browser for a while? If so, you may have noticed a few changes around here! As you navigate through the browser, you’ll notice redesigned icons, a softer, rounder interface, and a fresh color palette. Moving between desktop and mobile is more seamless than ever. And new interactive elements show you exactly how DuckDuckGo is protecting you.
Fresh Visuals, Seamless Protection
We’ve updated our browser’s visual design with a new color palette and softer, rounder shapes, including new icons that we designed in-house. This new look reflects what we believe the internet should feel like with real privacy protection: calm instead of chaotic, streamlined instead of cluttered, secure instead of surveilled.

Hit the green duck-foot shield in the redesigned address bar for real-time information about our tracking protections. Use the redesigned Fire Button to delete your browsing data with one click. Other changes you’ll notice include smoother, softer tab lines and a roomier address bar.

Private, Useful, and Optional AI
We’ve also made it easier than ever to access our private, useful, and optional AI features. Add a Duck.ai button to your URL bar for quick access to free, anonymized AI chats – available on both desktop and mobile.
These new buttons join several other convenient access points. On iOS, get to Duck.ai via Siri shortcut or widgets for your Lock Screen and Control Center. On Android, you find a shortcut by pressing and holding the DuckDuckGo app icon. (There’s also a Duck.ai button on our search results page when you visit duckduckgo.com, which can be toggled on and off here.)
Don’t use Duck.ai? You can disable the feature and hide the buttons in your browser’s Settings menu.

Tell Us What You Think
We love our browser’s new look – and we hope you do, too. If you have comments or questions, you can join our active community on Reddit or reach out on social media (Facebook | Linkedin | X).

2025-06-19, 11:41
- The DuckDuckGo browser’s built-in Scam Blocker guards against phishing sites, malware, and other common online scams. It’s on by default, so you’re protected as soon as you open the browser.
- NEW: Scam Blocker now also covers sham e-commerce sites, fake cryptocurrency exchanges, “scareware” that falsely claims your device has a virus, and other sites known to advertise fake products or services.
- Most browsers use Google tools for their phishing and malware protections, sending browsing data to Google in real time. We don’t. We designed Scam Blocker ourselves, with data from Netcraft, an independent cybersecurity company. Our scam protections don’t require an account, and we don’t share your browsing data with third parties.
- Scam Blocker is available for free within the DuckDuckGo browser on desktop and mobile. DuckDuckGo subscribers get full-device coverage when logged into the DuckDuckGo VPN – even when using other browsers.
Scam Blocker: Multiple protections for multiple threats

It’s not your imagination – online scams are getting more sophisticated. According to new reporting from the United States’ Federal Trade Commission, consumers lost $12.5 billion to fraud in 2024 alone. Scams related to investments, online shopping, and internet services were among the worst offenders.
Around here, we believe the best way to protect your personal information from hackers, scammers, and privacy-invasive companies is to stop it from being collected at all. Our browser and built-in search engine never track your searches, and our browsing protections help stop other companies from collecting your data, too. One of those protections is our Scam Blocker, designed and built by us for your security and your privacy. Scam Blocker guards against phishing sites, malware, and other common online scams without tracking your browsing data or sharing it with any third parties. It’s built into the DuckDuckGo browser and free to use, with no signup required.
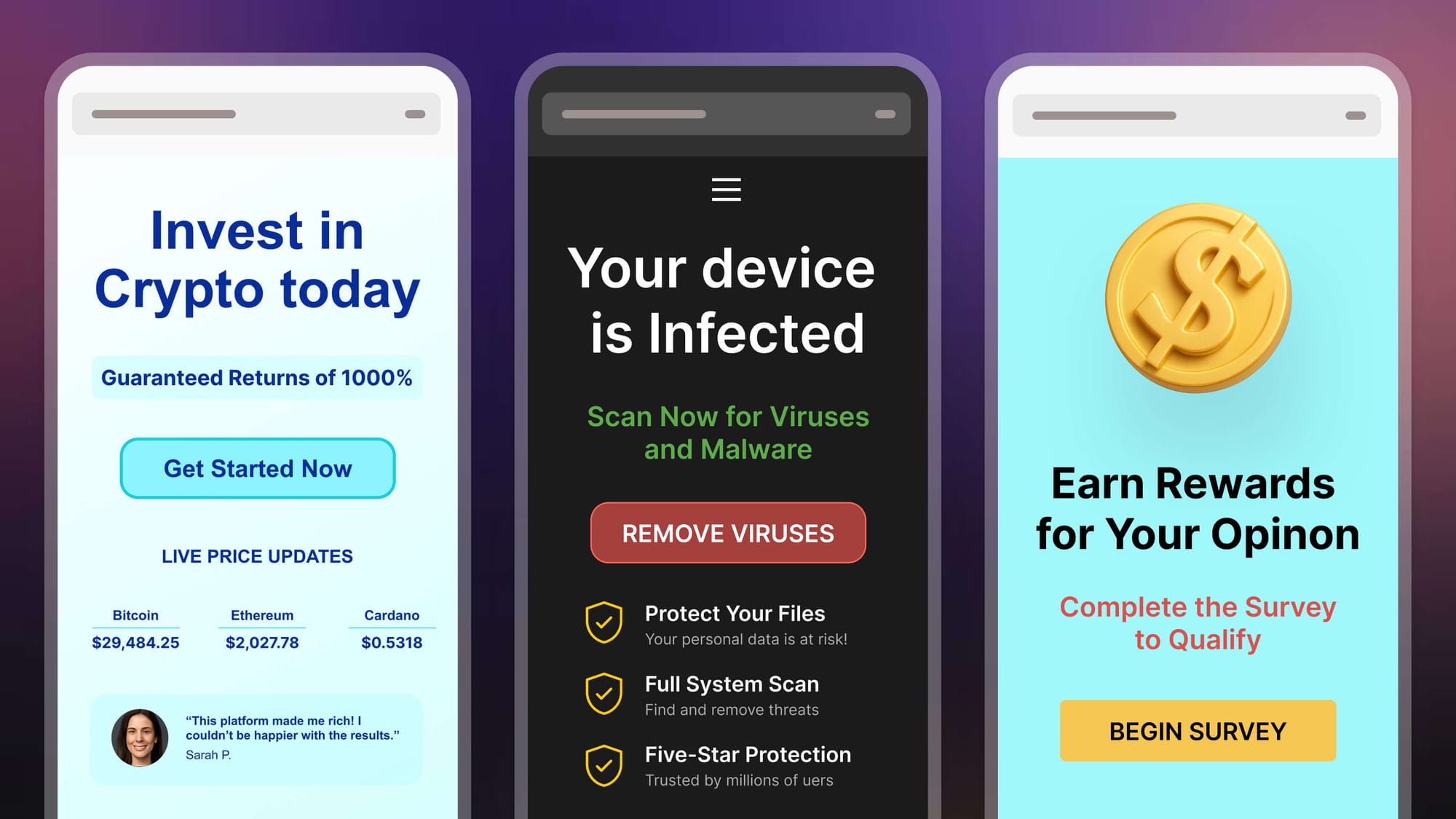
Fake cryptocurrency offers, urgent messages about "viruses," and high-paying surveys – like the hypothetical examples above – are some of the common scam sites covered by DuckDuckGo’s Scam Blocker.
Scammers and cybercriminals have constantly evolving tactics, so it’s important to stay protected on multiple fronts. Thanks to Scam Blocker, the DuckDuckGo browser can help you spot and avoid some of the most common types:
- NEW PROTECTION: Scam investment sites, storefronts, surveys and more. Designed to trick you into giving away personal information or making bad financial transactions under false pretenses. These scam sites can include investment offers, cryptocurrency trading schemes, discounted pharmaceutical products, affiliate surveys with cash rewards, and more; the sites can look legitimate, but the offers are often “too good to be true.”
- NEW PROTECTION: Scareware. These alarming sites claim that your computer or phone is infected with spyware or viruses. Scareware creates a false sense of urgency to trick people into engaging with fake “tech support” and buying unwanted – or completely fake – antivirus software.
- Phishing sites. Phishing generally uses impersonation to get your login credentials or sensitive personal information. Cybercriminals’ phishing techniques include creating sham websites that look like a familiar legitimate business and using link redirects to get unsuspecting users there.
- Malware sites. If you download a harmless-looking file from one of these sites, malware can infect your phone or computer, causing damage or extracting personal information for later use. Some malware sites start an automatic download before you even click or enter anything.
- Tracker-powered malicious ads. “Malvertising” typically involves injecting malware-laden advertisements into legitimate websites and online ad networks. Some malicious ads can compromise your system even if you don’t click on them.
The scam tactics vary, but the end goals are usually the same: to commit financial fraud using your personal information or to trick you into paying for products or services that don’t exist. If you accidentally click a link that would take you to one of these scammy sites, DuckDuckGo’s built-in Scam Blocker will stop the page from loading and show you a warning message that allows you to navigate safely away. The DuckDuckGo browser also reduces your malicious ad risk while you browse, blocking tracker-powered ads while before they load.
Other browsers like Chrome, Firefox, and Safari rely on Google’s Safe Browsing Service to provide warnings about phishing sites, which involves sending information to Google. We don’t. We built our own anonymous solution that doesn’t send data to any third parties. No sign in, no tracking, and it’s on by default, so you're protected from the moment you open the browser. DuckDuckGo subscribers can connect to the DuckDuckGo VPN to get these protections for your whole device – including in other browsers!
How Scam Blocker works
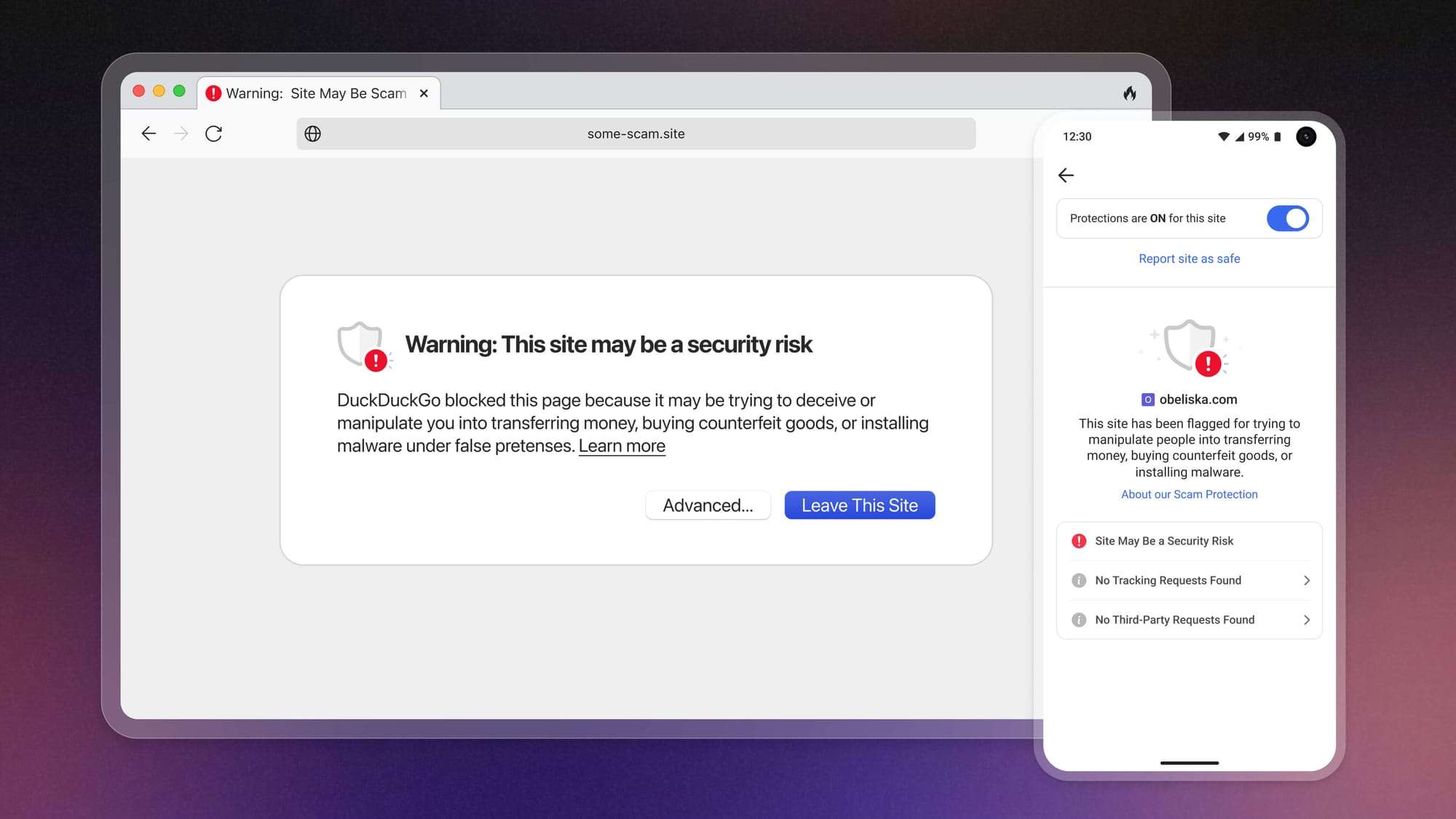
When you land on a potentially dangerous website, Scam Blocker will display a warning message before loading the site.
New scam sites pop up all the time, but the DuckDuckGo browser stays on top of it. We get a feed of malicious site URLs from Netcraft, an independent cybersecurity company that’s always scanning for new threats. We store that constantly refreshing list on our servers and pass any updates to your browser every 20 minutes.
The way Scam Blocker works is always anonymous. Once your browser downloads the latest dangerous site list from DuckDuckGo, it’s available locally on your device. When you navigate to a site, your browser first checks the site against the list stored on your device. If the site is on the list, your browser shows a warning message that gives you the option to navigate away safely or to continue to the site at your own risk.
Most of the potentially dangerous URLs flagged by Scam Blocker can be found on common sites like Google Drive or GitHub. Uncommon threats – which we encounter less than 0.1% of the time! – require an extra verification step that checks websites against a larger and more comprehensive database on DuckDuckGo servers. But this process is also anonymous; at no time during the threat verification process does your device communicate with any third parties. For a deeper dive on the cryptography we use to maintain anonymity when handling uncommon threats, visit this Help Page.
All this means that your searches and browsing history are still completely anonymous.
Note: This blog post has been edited since initial publication to stay up to date with our evolving product offerings.
2025-03-06, 12:41
- DuckDuckGo’s approach to AI is to provide private, useful, and optional AI features – including chat and search instant answers – to people who want the productivity benefits of AI without the privacy risks.
- Now out of beta: Get free, anonymized access to popular chatbots at Duck.ai. Easily move traditional search results – which now include more AI-assisted answers from web sources – to Duck.ai to continue your conversation.
- Both Duck.ai and AI-assisted answers are free to use, with no account required. We now serve millions of AI-assisted answers daily. If you opt to show them "often" in your settings, they should appear in our traditional search results over 20% of the time.
- Recent updates to AI-assisted answers include expanding sources across the web, beyond just Wikipedia; answering English-language queries outside the U.S.; and adding customization that lets you decide how often you want
answers to appear: often, sometimes (default), on-demand, or never. - Recent Duck.ai chat updates include upgraded models (GPT-4o mini and o3-mini from OpenAI, Meta Llama 3.3, Mistral Small 3, and Claude 3 Haiku from Anthropic) and a “Recent Chats” feature that stores conversations locally on your device – not on DuckDuckGo or other remote servers.
Our approach to AI: private, useful, and optional.
At DuckDuckGo, we believe the best way to protect your personal information from hackers, scammers, and privacy-invasive companies is to stop it from being collected at all. We started with a search engine that doesn’t collect your search history; our flagship experience is now a browser with a suite of built-in protections that includes our search engine, ad and cookie blocking, and many more protections.
Our approach to AI extends this strategy by integrating protected AI features that offer the productivity benefits of AI without privacy risks like tracking your prompts and training on your data.
We’re not making AI features just for the sake of making AI features. They have to be actually useful in everyday use, starting with helping people get faster, high-quality answers to their questions. However, we recognize not everyone wants AI in their lives right now, and that’s OK with us. That’s why all our AI features are optional and can be turned off or tuned down.
To chat or not to chat.
Head to Duck.ai for free, proxied access to popular chatbots from OpenAI, Anthropic, Meta, and Mistral.
A search engine’s core job is to get you the high-quality information you want fast. AI can help with that job, including a new mode of information-seeking through chat. We’re finding that some people prefer to start in chat mode and then jump into more traditional search results when needed, while others prefer the opposite. (Some questions just lend themselves more naturally to one mode or the other, too.) So, we thought the best thing to do was offer both. We made it easy to move between them, and we included an off switch for those who’d like to avoid AI altogether.
If you want to start with chat, try Duck.ai (previously called DuckDuckGo AI Chat), a free and account-less way to access popular AI chatbots, privately. Models are periodically updated and currently feature GPT-4o mini and o3-mini from OpenAI, open-source models Meta Llama 3.3 and Mistral Small 3, and Claude 3 Haiku from Anthropic. Chats are anonymized via proxying and never used for AI model training.
You can navigate directly to https://duck.ai/ or via the optional chat icons within our search engine or browsers. (There's also a widget - on iOS for now.) You can also use the !ai or !chat bang search commands from any browser where you have DuckDuckGo search set as the default search engine.
One way to access Duck.ai is via the Chat icons in our desktop and mobile browsers.
If you’d rather start with traditional search results, simply use DuckDuckGo search as usual. AI-assisted answers – previously called DuckAssist – will automatically appear on the search results page for relevant English language queries. You can also manually trigger an AI-assisted answer on demand by pressing the “Assist” button under the search box, which appears on most queries. The answers source information from across the web, and like Duck.ai, they are completely free and private, with no sign-up required.
The “Assist” button lets you generate AI-assisted answers on demand.
We’ve continuously heard from users that they want more quick, at-a-glance answers, for a broad range of topics. For years, we’ve been doing that by working on search modules to provide instant answers for things like sports scores, local business information, where to watch movies and TV shows, and much more. Now, we are finding that we can significantly expand the scale of high-quality instant answers we can show with AI as we’re now serving millions of AI-assisted answers daily. Since we’ve introduced AI-assisted answers on our search results, overall user satisfaction with our search results has improved.
If you were unsatisfied after trying DuckDuckGo search in the past, now is a great time to try us again. We’re always improving. If you do try us or try us again, please set DuckDuckGo search as your default search engine or download our browser and make it the device default. It can take a moment to get used to something different, and setting the default is the best way to get over that hump.
How can I customize my search experience?
Navigate to the AI Features section of your search settings. If you really like our AI-assisted answers, change Assist to Often, which will make them appear over 20% of time. On the other hand, if you never want to see any AI features, turn Chat to Off and Assist to Never.
On DuckDuckGo browsers, you can choose whether the chat icon appears on the toolbar from within the ‘Duck.ai’ section in your browser settings.

Control how often you see AI-assisted answers from your search settings.
In addition to respecting our users’ choices, we respect publishers’ wishes to opt out of AI-assisted answers on DuckDuckGo and don’t penalize publishers for that choice. Even if they opt out as a source for our AI-assisted answers, they can stay opted into our other search results.
How am I protected?
When we generate AI-assisted answers, we anonymously call the underlying AI models used to summarize web sources on your behalf, so your personal information is never exposed to third parties. This method is called proxying. Duck.ai chats work similarly. To accomplish this technically, we remove your IP address completely and use our own IP address instead. This way, the proxied requests are coming from us, not you. For more information, please see the DuckDuckGo General Privacy Policy.
Duck.ai's "Recent Chats" let you pick up where you left off. Chats are saved locally on your device – not on DuckDuckGo or any other outside servers.
Within Duck.ai, recent chats are only stored locally on your device, not on DuckDuckGo servers. Not interested in storing your chats? You can disable the option altogether, or use the Fire Button to clear all your recent chats at once. Duck.ai chats are not used for any AI training, either by us or the underlying model providers. To respond with answers and ensure all systems are working, these providers may store chats temporarily, but we remove all the metadata so there’s no way for them to tie chats back to you personally. On top of that, we have agreements in place with all providers to ensure that any saved chats are completely deleted within 30 days. For more information, please see the DuckDuckGo AI Chat Privacy Policy and Terms of Use.
Clear your recent Duck.ai chats with the click of a button.
Are AI-assisted answers reliable?
When you search on DuckDuckGo, our AI-assisted answers are based on real-time web crawling, so they’re as reliable as the sources from which they are drawn. But even the most reliable sources can have errors, and mistakes can occasionally happen in the summarization process, too. That’s why we prominently display our cited sources: you can easily check them out and use your own judgment to make the final call.
Want to know where your AI-assisted answer came from? Check the sources below the answer and click through for a deeper dive into complex topics.
We also have a number of precautions in place. Out of the countless websites we could draw from, we try to weed out ultra-low-quality sources like spammy content farms and invasive people search sites, and we try to avoid satirical sites and opinion pieces.
You are a critical part of the process as well. “Was this helpful? 👍 👎” is displayed next to every AI-assisted answer. So, if you see a bad answer – or a great answer! – please let us know. We review it all as part of our quality control process.
Is this really free?
Yes! AI-assisted answers are integrated into DuckDuckGo search, which is always free to use, with no log-in required. (We make money from private search ads.) Chatting on Duck.ai is also free within a daily limit, which we implement while maintaining strict user anonymity, just like we do for our search engine. We plan to keep the current level of access free; we’re exploring a paid plan for access to higher limits and more advanced (and costly) chat models.
What’s next?
We are largely driving our AI roadmap based on your feedback, so please keep it coming—we appreciate it. Within Duck.ai, this includes adding newer models, voice and image support, and granting models web access. For AI-assisted answers on our traditional search engine, we’re making them faster and more interactive, answering more queries, and improving when they appear automatically, including for less straightforward queries.
In the meantime, give Duck.ai a try and keep an eye out for AI-assisted in your traditional search results. Head to your search settings if you want to see them more or less often.
2024-12-03, 14:00

2024 marks DuckDuckGo's 14th year of donations—our annual program to support organizations that share our vision of raising the standard of trust online. We are proud to donate to diverse group of organizations around the world that promote privacy, digital rights, access to information online, and a healthier online ecosystem.
This year, we’re donating $1,100,000, bringing DuckDuckGo's total donations since 2011 to $6,950,000. Everyone using the Internet deserves simple and accessible online protection; these organizations are all pushing to make that a reality. We encourage you to check out their valuable work below, alongside details about how our funds were allocated this year.
$100,000 to the Electronic Frontier Foundation (EFF)
“EFF's mission is to ensure that technology supports freedom, justice, and innovation for all people of the world.”
$75,000 to Public Knowledge
"Public Knowledge promotes freedom of expression, an open internet, and access to affordable communications tools and creative works. We work to shape policy on behalf of the public interest."
$50,000 to ARTICLE 19
"Established in 1987, ARTICLE 19 is an international non-profit organization that defends freedom of expression, fights against censorship, protects dissenting voices, and advocates against laws and practices that silence individuals, both online and offline."

$50,000 to Demand Progress
"DPEF educates our members and the general public about matters pertaining to the democratic nature of our nation’s communications infrastructure and governance structures, and the impacts of corporate power over our economy and democracy."
$50,000 to European Digital Rights (EDRi)
"The EDRi network is a dynamic and resilient collective of 50+ NGOs, as well as experts, advocates and academics working to defend and advance digital rights across Europe and beyond. For over two decades, it has served as the backbone of the digital rights movement and has achieved landmark successes in digital rights in Europe."
$50,000 to Fight for the Future
"Known for organizing some of the largest and most effective online campaigns in history, Fight for the Future’s mission is to ensure a just Internet and technology that is a force for empowerment and liberation, free of surveillance, censorship, and abuse of personal data."
$50,000 to The Markup
"The Markup challenges technology to serve the public good by producing investigative journalism, unique tools, and accessible resources to inspire action and agency."
$50,000 to OpenMedia
"OpenMedia is a community-driven organization that works to keep the Internet open, affordable, and surveillance-free. We operate as a civic engagement platform to educate, engage, and empower Internet users to advance digital rights around the world."
$50,000 to Restore the Fourth
“Restore the Fourth opposes mass government surveillance, and organizes locally and nationally to defend privacy and the Fourth Amendment.”
$50,000 to Signal
“Signal Technology Foundation protects free expression and enables secure global communication through open source privacy technology.”
$50,000 to the Surveillance Technology Oversight Project (S.T.O.P.)
“The Surveillance Technology Oversight Project (S.T.O.P.) advocates and litigates for privacy, working to abolish local governments’ systems of discriminatory mass surveillance."
$50,000 to Tech Policy Press

“Tech Policy Press promotes discussion, debate, and analysis of issues and ideas at the critical intersection of technology and democracy.”
$50,000 to the Tech Oversight Project
"Through engaging with lawmakers, exposing false narratives and bad actors, and pushing for landmark legislation, the Tech Oversight Project seeks to hold tech giants accountable for their anti-competitive, corrupting, and corrosive influence on our society and the levers of power."
$25,000 to Algorithmic Justice League (AJL)
“AJL’s harms reporting platform aims to capture people's lived experiences with AI harms, connect them with resources, and identify areas where there are no or few resources.”
$25,000 to Bits of Freedom

“Bits of Freedom shapes tech policy in order to facilitate an open and just society, in which people can hold power accountable and effectively question the status quo.”
$25,000 to the British Institute of International and Comparative Law (BIICL)
"The Competition Law Forum is a centre of excellence for European competition and antitrust policy and law at the British Institute of International and Comparative Law (BIICL)."
$25,000 to the Center for Critical Internet Inquiry (C2i2)

“UCLA Center for Critical Internet Inquiry (C2i2), housed in the UCLA Division of Social Sciences, is a critical internet studies community committed to reimagining technology, championing social justice, and strengthening human rights through research, culture, and public policy.”
$25,000 to Creative Commons (CC)

“Creative Commons (CC) is an international nonprofit organization dedicated to building and sustaining a thriving commons of shared knowledge and culture that serves the public interest.”
$25,000 to Digital Rights Watch

"Digital Rights Watch is Australia's leading digital rights organisation. They defend and promote privacy, democracy, fairness and fundamental rights in the digital age."
$25,000 to Gesellschaft für Freiheitsrechte (GFF)
"The Society for Civil Rights e.V. (Gesellschaft für Freiheitsrechte e.V. or "GFF") is a donor-funded organization from Germany that defends fundamental and human rights by legal means. The organization promotes democracy and civil society, protects against disproportionate surveillance and advocates for equal rights and social participation for everyone."
$25,000 to noyb
"noyb is committed to the legal enforcement of European data protection laws and has filed more than 850 cases against numerous intentional infringements by Big Tech companies - to make online privacy a reality for everyone."
$25,000 to the Open Home Foundation
“The Open Home Foundation fights for the fundamental principles of privacy, choice, and sustainability for smart homes - and for every person who lives in one. It is best known as the organization that owns and governs Home Assistant, among many other projects crucial to the open home."
$25,000 to the Open Rights Group (ORG)

"Open Rights Group is the UK’s largest grassroots digital rights campaigning organisation, working to protect everyone’s rights to privacy and free speech online."
$25,000 to the Open Source Technology Improvement Fund (OSTIF)
"Open Source Technology Improvement Fund helps critical open source projects with their security needs and is grateful for the continued support from DuckDuckGo. This funding is pivotal to ongoing operations, as it is one of our only donation sources that is not tied to any deliverable or project. Over the past year, OSTIF has been able to sustainably help critical open source projects improve their security posture, and in the process have found and fixed over 150 bugs and vulnerabilities."
$25,000 to Perl and Raku Foundation
"The Perl and Raku Foundation is a non-profit, 501(c)(3) which fulfills a range of activities including the collection and distribution of development grants, sponsorship and organization of community-led local and international Perl conferences, and support for community resources and user groups."
$25,000 to Privacy Rights Clearinghouse
"Privacy Rights Clearinghouse focuses on increasing access to information, policy discussions, and meaningful rights so that data privacy can be a reality for everyone."
$25,000 to Proof

"Proof is a new nonprofit journalism studio that is working to redefine and reimagine trustworthiness in news and investigative reporting."
$25,000 to the Tor Project
"At the Tor Project, we believe everyone should be able to explore the internet with privacy. We advance human rights and defend your privacy online through free, open source software and the decentralized Tor network."
2024-11-20, 12:30

Today, we are calling on the European Commission to launch three non-compliance investigations around Google’s obligations under the EU’s Digital Markets Act (DMA):
- On Google’s non-compliance with Article 6(11), which requires Google to share anonymized click and query data.
- On Google’s non-compliance with Article 6(3), which requires Google to implement choice screens and enable end users to easily change default search settings.
- On Google’s non-compliance with Article 6(4), which requires any downloaded search or browser app to have the ability to prompt users to set search defaults easily.
The DMA created these obligations to address Google’s scale and distribution advantages, which the judge in the United States v. Google search case found to be illegal. The judge specifically highlighted that 70% of queries flow through search engine access points preloaded with Google, which creates a “perpetual scale and quality deficit” for rivals that locks in Google’s position.
Unfortunately, Google is using a malicious compliance playbook to undercut the DMA. Google has selectively adhered to certain obligations – often due to pressure from the Commission – while totally disregarding others or making farcical compliance proposals that could never have the desired impact. As a result, the DMA has yet to achieve its full potential, the search market in the EU has seen little movement, and we believe launching formal investigations is the only way to force Google into compliance. The Commission has already demonstrated its ability to use such investigations effectively under the DMA.
While Google’s bad faith approach is not surprising, it should not go unnoticed. Any regulator looking to create enduring competition in the search market should take note of the tactics Google is using to thwart and circumvent its legal obligations.
We project Google’s Click-and-Query data sharing proposal eliminates ~99% of search queries.
Google’s exclusive default distribution deals mean they see many times more search queries than any competitor can, which gives them what’s called a “scale advantage.” In Article 6(11), the DMA directly addresses this scale advantage by mandating Google share anonymized click, query, ranking, and view data. This data would help search engines improve results quality, especially for less frequent (so-called “long-tail”) queries.
Google’s Click-and-Query obligation under the DMA, Article 6(11), reads:
“The gatekeeper shall provide to any third-party undertaking providing online search engines, at its request, with access on fair, reasonable and non-discriminatory [FRAND] terms to ranking, query, click and view data in relation to free and paid search generated by end users on its online search engines. Any such query, click and view data that constitutes personal data shall be anonymised.”
To comply with this requirement, Google announced the “Google European Search Dataset Licensing Program.” However, this data set has little to no utility to competing search engines due, in large part, to Google’s proposed anonymization method, which only includes data from queries that have been searched more than 30 times in the last 13 months by 30 separate signed in users. This method is conveniently overbroad: we extrapolate that Google’s dataset would omit a staggering ~99% of search queries including “longtail” queries that are the most valuable to competitors. Google is trying to avoid its legal obligation in the name of privacy, which is ironic coming from the Internet’s biggest tracker.
Part of our goal at DuckDuckGo has always been to prove that tech can make great products without exploiting people’s data or using mass surveillance. Our Privacy Policy explains how we go about doing this, for example, “we have no way to create a history of your search queries.” We do this by stripping out any metadata that can tie searches together made by the same individual, so re-identification cannot happen like in the memorable AOL case. For example, we may know that we got a lot of searches for "cute cat pictures" today, but we don’t know - and have no way to figure out - who actually performed those searches.
The fact is that most "rare" queries are actually just common words put in an order that isn’t searched very often. These queries are not inherently problematic since they cannot be traced back to any individual. So, instead of attempting to filter all of these relatively unique queries, we should instead focus on removing the subset of those queries that contain personal identifiers, like addresses and phone numbers or accidental pastes like user ids and passwords. Fortunately, there are relatively straightforward approaches to remove these types of queries that will result in much of the long tail data remaining available to improve search results.
This isn’t even the only part of the proposal that severely hampers the usefulness of the data:
- The proposal averages ranking data, which eliminates critical nuances. It also doesn’t provide anonymous ranking signals like dwell time or bounce rate.
- The proposal shares at best three-month old data, meaning the data is already stale when received because many results would no longer reflect current search trends.
- The proposal contains hardly any information on search modules, such as knowledge panel content, meaning information on much of the content on the search result page is not being shared.
We recognize that fine-tuning the right approach requires further considerations and, most importantly, testing and good faith cooperation from Google. Faced with Google’s continued obstruction, we believe that opening an official investigation is the only way to arrive at a workable proposal. We would like to help in that effort and believe there are ways for Google to provide a data set that is both privacy respecting and useful to competitors.
Google has so far completely ignored “easy switching” requirements.
The DMA includes provisions designed to facilitate easy switching of search engines and browsers, targeting Google’s entrenched hold over search and browser access points. Google’s obligation under Article 6(3) of the DMA reads:
“The gatekeeper shall allow and technically enable end users to easily change default settings on the operating system, virtual assistant and web browser of the gatekeeper.”
Despite this obligation, switching search engines on Android devices (which make up more than 60% of the mobile market in the EU) is still not “easy.” Before the DMA came into effect, it took more than 15 steps to switch your default search engine on Android and today that is still the case.
Zero changes have been made. What should happen is that users should be able to change their default search engine across every search access point in one click, similar to how a choice screen works, but currently choice screens are only shown on device onboarding. Users should be able to get back to a similar screen via a top-level device setting for default search, which we should be also able to guide users to directly from our app.
Similarly on Chrome, switching the default search engine has not been made any easier either. For example, there’s still no way to guide a user directly to the default search engine setting from the DuckDuckGo search homepage. And Google’s persistent dark pattern for search extensions on Chrome remains.
Google has completely ignored its easy switching obligations under the DMA. As a result, we believe the Commission must launch a non-compliance investigation to get Google to fulfill its requirements under the law. “Easy switching” should mean competition is actually one click away.
Google still hasn’t rolled out its updated Android choice screens to 250+ million EU Android users.
Article 6(3) DMA requires Google to show choice screens to end users “at the moment of the end users’ first use of an online search engine or web browser.”
Google’s search engine DMA choice screen is explicitly different from the choice screen Google implemented following the Android case. Key improvements have been made to its design, such as automatically showing taglines. But Google has not rolled out this updated DMA choice screen to all Android users, in breach of Article 6(3). Apple, for example, rolled out its DMA browser choice screen to its entire EEA user base and is planning to do so again after an investigation from the Commission – this time to Safari default users only.
A non-compliance investigation must therefore be opened to ensure that Google will fulfill its obligation and roll out both the DMA search engine and browser choice screens to all Android devices at once like they did on Chrome for desktop and iOS. When those Chrome choice screens rolled out, the positive competitive impact was evident: DuckDuckGo search queries on Chrome have increased by around 75% across the EEA. This rapid and stable growth in query volume shows pent-up demand by Chrome users for privacy-respecting search alternatives.
What can regulators learn from this?
Regulators around the world should be looking at what’s happening with the DMA, learn from how Google has been able to exploit its loopholes and circumvent it, and then take steps to make sure Google cannot continue to put up roadblocks in the way of progress and fair competition.
In the EU, Google chose to roll out self-serving compliance proposals around these obligations without engaging in meaningful consultations, leading to significant delays in achieving contestability and fairness, the objectives of the DMA. Given the opportunity, it should not come as a surprise that Google is taking advantage.
Instead, regulators and market participants should be able to review, test, and validate remedies before they are implemented to ensure they actually accomplish their intended purpose, while maintaining the regulatory authority to launch investigations and make changes after implementation, if necessary. Regulators can set additional criteria to make sure these interventions have the desired impact. For example, dominant firms could be required to demonstrate that consumers understand how to switch and that switching to a competitor is equivalently easy to sticking with the services from the dominant firm.
In addition, we believe the DMA doesn’t properly address Google’s scale advantage. Sharing click-and-query data is a critical intervention to address Google’s scale advantage, but alone, it isn’t sufficient to create a competitive search engine. As we’ve previously written, we believe the best and fastest way to level the playing field on search quality is for Google to provide access to its search results via real-time APIs (Application Programming Interfaces), also on FRAND (Fair, Reasonable, and Non-Discriminatory) terms. That means for any query that could go in a search engine, a competitor would have access to the same search results.
If Google is required to license its search results in this manner, this would allow existing search engines and potential market entrants to build on top of Google’s various modules and indexes, and offer consumers more competitive and innovative alternatives. In addition, while choice screens are an excellent mechanism to provide consumers access to competitors, they need to be shown periodically, at least yearly, to give competing search engines a chance to build awareness over time. We are happy to work with regulators to craft remedies that will create enduring search competition.
2024-10-23, 11:50

At DuckDuckGo, we know what it's like to turn a vision into a successful company. Our founder and CEO, Gabriel Weinberg, began DuckDuckGo’s journey to “raise the standard of trust online” from his basement in Pennsylvania and turned it into a browser and search engine used by millions of people around the world.
Today, this vision still inspires us. Each year, we donate to non-profit organizations that align with this vision, and now we're investing in companies that align with it as well.
As more and more consumers seek privacy-conscious technologies, we want to partner with other like-minded entrepreneurs and help turn their visions into reality. With the core objective of supporting consumer privacy technologies, DuckDuckGo is actively investing in early-stage companies as well as pursuing acquisitions and partnerships. We've actually already been doing this quietly for the last couple years, and we’re energized to do more. So, we'd love to hear from you and find ways to work together.
We are focused primarily on three domains:
- Search and browse: It's the core of our product and where we continue to invest most heavily.
- Consumer privacy technologies: This spring, we launched Privacy Pro, a 3-in-1 subscription service with VPN, Personal Information Removal, and Identity Theft Restoration. Our acquisition of Removaly was key to accelerating the development of our Personal Information Removal solution. We continue to look for other complementary technologies that could extend our offerings.
- Emerging technologies: We recently announced DuckDuckGo AI Chat, which offers private access to popular AI chatbots. We’re committed to investing in this emerging technology space and others, but only in ways that are privacy-respecting.
For early-stage investments, we are flexible on deal structure, aim to move quickly and are happy to co-invest with other companies, funds, and individuals. For acquisitions, we are open to a range of companies that share a commitment to protecting user privacy.
You can reach Mike Marino, SVP of Finance and Diana Chiu, Director of Corporate & Business Development directly at investments@duckduckgo.com.
2024-09-12, 12:39

Since the ruling in the U.S. v. Google search case was announced, there has been discussion about how to remedy Google’s dominance. As a company that operates a search engine that directly competes with Google, we have several ideas about how to craft a set of legal and technical interventions that can, in combination, effectively curb the advantages Google has gained through illegal use of their search monopoly. DuckDuckGo believes it is possible to put remedies in place that will establish enduring search competition, encourage innovation and new market entrants, and result in significant market share among multiple competitors.
However, there is no silver bullet remedy that, alone, will adequately address both Google’s scale and distribution advantage as well as ensure that Google cannot circumvent its obligations. Instead, the “remedy” must be a package of remedies that work together to effectively counteract the unlawful competitive imbalance.
Counteracting Google’s Scale Advantage with Access to Search Results
Many ideas on the table aim to counteract Google’s distribution advantage, but we believe it’s equally important to address Google’s scale advantage. Google’s exclusive default distribution deals mean they see way more queries than everyone else, a.k.a. their scale advantage. The court’s opinion quantifies this disparity:
More users mean more advertisers, and more advertisers mean more revenues…. Google’s scale means that it not only sees more queries than its rivals, but also more unique queries, known as “long-tail queries.” To illustrate the point, Dr. Whinston analyzed 3.7 million unique query phrases on Google and Bing, showing that 93% of unique phrases were only seen by Google versus 4.8% seen only by Bing.
Google uses this stream of information to continuously improve their results by running large-scale experiments in ways that no rival can because we’re effectively blinded. Google infers the best results based on queries it has seen before. If a search engine sees fewer – or often zero – similar queries, these inferences are less effective.
As the court describes the situation, Google’s scale advantage fuels a powerful feedback loop of different network effects that ensure a “perpetual scale and quality deficit” for rivals that locks in Google’s advantage.
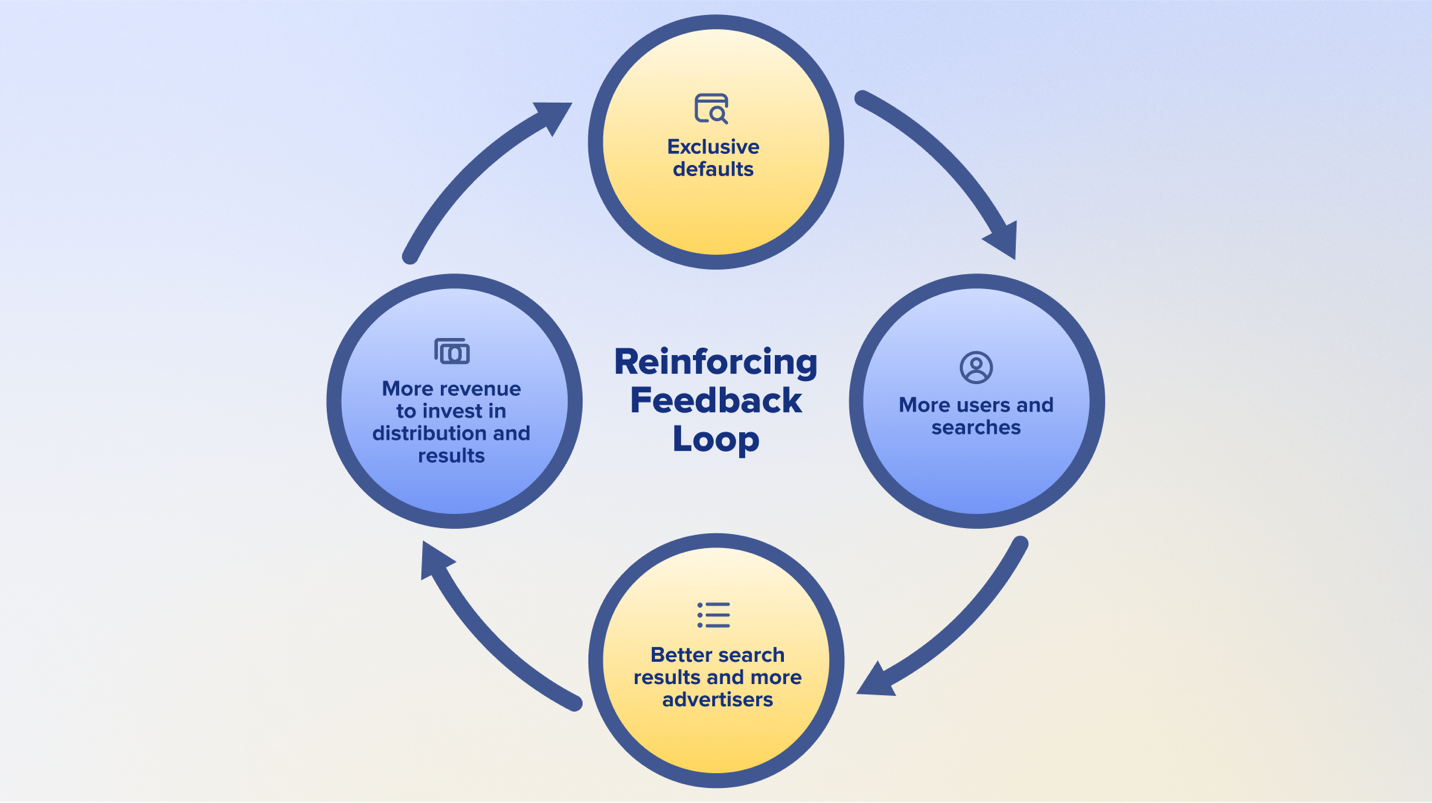
Google’s exclusive defaults are part of a reinforcing feedback loop that gives them an insurmountable scale advantage and makes it difficult for rivals to compete.
The best and fastest way to level this playing field is for Google to provide access to its search results via real-time APIs (Application Programming Interfaces) on fair, reasonable, and non-discriminatory (FRAND) terms. That means for any query that could go in a search engine, a competitor would have access to the same search results: everything that Google would serve on their own search results page in response to that query. If Google is forced to license its search results in this manner, this would allow existing search engines and potential market entrants to build on top of Google’s various modules and indexes and offer consumers more competitive and innovative alternatives.
Today, we believe that we already offer a compelling search alternative with more privacy and fewer ads, relative to Google. We’ve also been working for fifteen years to make our search results on par in terms of feature set and quality by combining our own search indexes with those of partners like Apple, Microsoft, TripAdvisor, Wikipedia, and Yelp. However, we know that many consumers still prefer Google’s results due to the benefits of scale discussed above, and this intervention would erase that advantage, instantly making us and others much more competitive.
We’ve already seen some concerns about this remedy direction that we’d like to quickly address. First, licensing Google’s search results does not involve accessing any user data. This remedy will not invade user’s privacy, which is aligned with our vision as a company. We know from experience that this remedy can be implemented anonymously, and we can advise on that implementation. We can open up Google without opening up user data.
A second potential concern is that long-tail results on leading search engines could be similar in some cases, but that’s a feature not a bug. Google’s scale advantage gives them insights into which obscure links should be ranked higher, and so we should expect that when smaller search engines incorporate this information that some results would become more similar. However, licensing on FRAND terms should also allow competitor search engines to re-rank and mix results with other content, which will enable competitor search engines to produce different ranking algorithms based on the same underlying high-quality search results.
Additionally, FRAND licensing will allow other search engines to more competitively differentiate on things like privacy, design, and customization of the user interface and results page, while still providing high-quality results. For example, we can envision a universe of differentiated and innovative experiences, such as features that allow users to tweak ranking algorithms, features that bring more transparency to ranking algorithms, and other AI capabilities, all leveraging Google’s search result APIs. Future-looking use cases like these must be kept in mind, and FRAND API access is what is needed to power these types of search innovations.
A third concern is that competitor indexes could become too reliant on Google; however, if all the results that come through the APIs can also be used as an input into building search indexes, this would ensure that there is also a path to long term viability and independence for competitors. We, for one, would go further down this path. This could be accelerated if the APIs also provide access to Google’s anonymous ranking signals (for example, how often and quickly people in aggregate click back after visiting a link), which will help tune competitor indexes even faster as well as improve real-time reranking algorithms. That said, we recognize that licensing Google’s search results needs to be a long-term intervention because their scale advantage will persist as long as Google has much more significant market share than competitors.
There are historical precedents for this type of remedy as well. AT&T’s 1956 antitrust agreement required the company to license its patents on FRAND terms, which allowed existing and new companies to build on top of AT&T’s innovations. Similarly, the Telecommunications Act of 1996 encouraged competition in communications markets by requiring large telecommunications providers to interconnect their networks with new competitors on FRAND terms.
This is not a new technical challenge for Google either: Google already licenses their search results, including their ads, via real-time APIs to some competitors. It’s also not novel in antitrust, as API access was at stake in Microsoft’s antitrust settlement two decades ago. An API-based remedy also means that startups could immediately enter the search market rather than be forced to invest tens or hundreds of millions of dollars upfront to get started by acquiring and consuming massive data sets. It also protects nascent competition in AI-driven search by allowing them to use the APIs to ground answers in real-time.
Finally, we should note that the EU’s Digital Markets Act attempts to solve Google’s scale advantage by requiring Google to provide FRAND access to its “click and query data.” To date, this has been ineffective because Google has undermined the requirement by limiting the data they share to the point of being useless. However, while we believe that click and query data is not a substitute for FRAND access to search result APIs, we also believe that if implemented correctly it can complement and further accelerate the path to competitor independence. That’s because API access will be limited to queries a competitor search engine actually sees, whereas click and query data can be much broader, covering almost all the queries Google sees. Therefore, access to this data in a privacy-protective manner should also be given on FRAND terms.
Counteracting Google’s Distribution Advantage with a Ban on Self-Preferencing in Chrome and Android
Google likes to claim everyone chooses Google, but most consumers don’t: they just go with the default. The court outlines how staggering this default advantage is:
50% of all queries in the United States are run through the default search access points covered by the challenged distribution agreements…. An additional 20% of all searches nationwide are derived from user-downloaded Chrome, a market reality that compounds the effect of the default search agreements. That means only 30% of all [general search engine] queries in the United States come through a search access point that is not preloaded with Google. Additionally, default placements drive significant traffic to Google. Over 65% of searches on all Apple devices go through the Safari default. On Android, 80% of all queries flow through a search access point that defaults to Google.
The court also consolidates evidence highlighting that large percentages of consumers don’t even realize they are using Google because of these defaults:
- An internal Google email in 2016 acknowledged that “users on Edge don’t even realize they aren’t using Google.”
- A 2018 Google study revealed there was “substantial user confusion regarding which browser and [general search engine] was in use.”
- A 2020 Google study found that over 50% of U.S. iPhone users were “unsure” what search engine powered Safari, concluding users are “often unaware they’re using Google.”
Users are confused and competition is crushed. As a result, Google shouldn’t be able to self-preference its search engine on Chrome and Android, which were developed to expand the reach of Google Search. Within these products, there should be no preset search default. Instead, these platforms need user-friendly settings based on sound principles that provide for:
- Regular access to well-designed choice screens that put users in charge of choosing their search engine default when setting up Android or Chrome, and periodically thereafter. Choice screens should set the search engine across all search access points on Android and Chrome.
- An easy way for users to navigate back to these settings.
- A one-click mechanism for any rival search engine to switch these settings and offer itself as a default search engine when users visit their website or app.
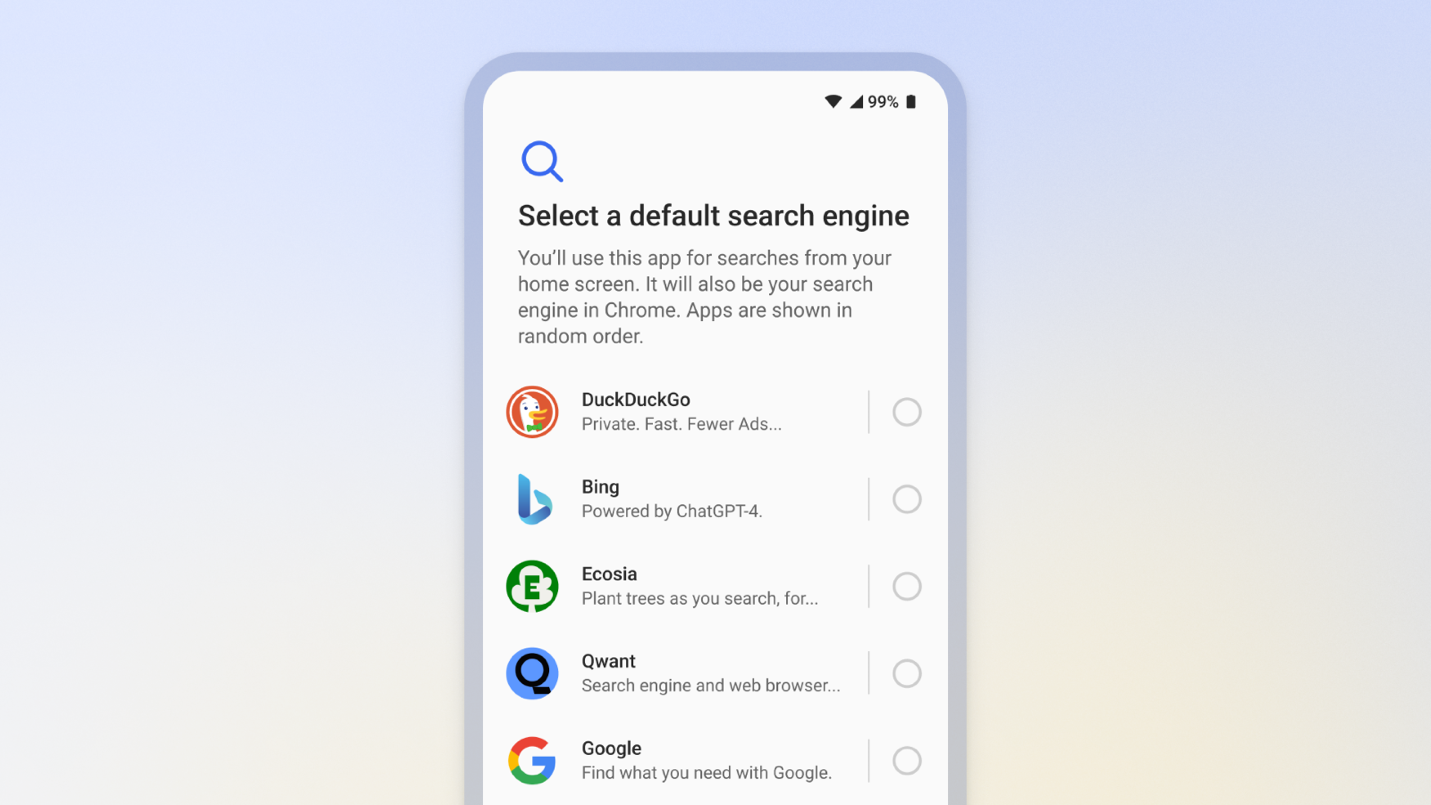
Image of the search engine choice screen on Android in the EU.
Banning self-preferencing must also include a prohibition on dark patterns, and all remedies must be subject to anti-circumvention provisions. For example, these restrictions should prohibit Google from discouraging users from installing rival apps or search extensions, or encouraging them to switch back to Google.
Unfortunately, a self-preferencing ban won’t create enduring competition by itself. However, as rivals can innovate on top of Google’s search results, and consumers become aware of rival brands and their increased quality, this increased access to consumers will accelerate competition in the search market.
Counteracting Google’s Distribution Advantage by Restricting Exclusionary Contracts
The court has already declared Google’s exclusionary contracts unlawful. While there are methods outside of these exclusive defaults to access search engines, the court recognizes that these “channels are far less effective at reaching users. That is due in part to users’ lack of awareness of these options and the ‘choice friction’ required to reach these alternatives.”
Restricting these exclusive agreements is therefore essential to help open up access to the search market. However, just restructuring these contracts by itself won’t do much because it won’t directly counteract Google’s entrenched advantage. For that, we need to look to the remedies discussed above.
On Accountability
Even the most well-crafted remedies will ultimately fail if Google is in charge of designing and implementing them, as has been the case in the EU. We’ve seen firsthand how Google has easily and repeatedly avoided complying with both the letter and the spirit of the law. Consequently, an independent monitoring body made up of technical experts and affected market participants must be fully empowered to keep Google honest. We should expect that this monitoring entity will need to be in place for as long as the remedies are in place. We cannot let the fox guard the henhouse.
On Structural Remedies
We are not opposed to structural remedies, but they would need to be paired with the additional interventions outlined in this post. In other words, structural changes to Google could theoretically be an accelerant in some circumstances, but regardless are not a replacement for FRAND access to search results and click and query data together with a ban on Google-self preferencing and a restriction on exclusive contracts. And we can envision some scenarios where a particular structural remedy could be more harmful to us than helpful.
A Long Road Ahead
Counteracting the entrenched competitive imbalance that Google’s default advantage has afforded them will not happen overnight. Realistically, it will take years for competition to take hold, and a fully-funded and motivated Department of Justice will need to be involved for the long haul. However, we are confident that a package of well-implemented and carefully monitored remedies, each designed to address a specific choke point, can work to create enduring competition in the search market.
2024-06-06, 11:36
DuckDuckGo AI Chat is an anonymous way to access popular AI chatbots – currently, Open AI's GPT 3.5 Turbo, Anthropic's Claude 3 Haiku, and two open-source models (Meta Llama 3 and Mistral's Mixtral 8x7B), with more to come. This optional feature is free to use within a daily limit, and can easily be switched off.
- Chats are private, anonymized by us, and not used for any AI model training.
- Find DuckDuckGo AI Chat at duck.ai, duckduckgo.com/chat, on your search results page under the Chat tab, or via the !ai and !chat bang shortcuts. They all take you to the same place.
- Improvements are already on the way. Our roadmap includes adding more chat models and browser entry points. We’re also exploring a paid plan for access to higher daily usage limits and more advanced models.
Why did you make AI Chat?
Find AI Chat on your search results page for easy switching between the two.
Our mission is to show the world that protecting your privacy online can be easy. We believe people should be able to use the Internet and other digital tools without feeling like they need to sacrifice their privacy in the process. So, we meet people where they are, developing products that add a layer of privacy to the everyday things they do online. That’s been our approach across the board – first with search, then browsing, email, and now with generative AI via AI Chat.
DuckDuckGo AI Chat is a free, anonymous way to access popular AI chatbots. According to recent Pew reporting, adults in the U.S. have a negative view of AI's impact on privacy, even as they're feeling more positive about AI's potential impact in other areas. "About eight-in-ten of those familiar with AI say its use by companies will lead to people’s personal information being used in ways they won’t be comfortable with (81%) or that weren’t originally intended (80%)." Even so, another recent report shows a steady uptick in the share of U.S. adults who are using chatbots for work, education, and entertainment. If you're interested in AI chatbots but share those privacy concerns, DuckDuckGo AI Chat is for you.
In the industry-wide race to integrate generative AI, there’s a lot of pressure to add AI features just for the sake of saying you have them. We’re taking a different approach. Before adding any AI-assisted features to our products – first DuckAssist, our AI-enhanced Instant Answer, and now AI Chat – we think carefully about how to make them additive to the search and browse experience, and we roll them out cautiously to ensure this is the case. We also recognize these features aren’t for everyone, so we’ve made our AI-assisted features totally optional; if you’re not interested, you can easily switch them all off.
We view AI Chat and search as two different but powerful tools to help you find what you’re looking for – especially when you’re exploring a new topic. You might be shopping or doing research for a project and are unsure how to get started. In situations like these, either AI Chat or Search could be good starting points. If you start by asking a few questions in AI Chat, the answers may inspire traditional searches to track down reviews, prices, or other primary sources. If you start with Search, you may want to switch to AI Chat for follow-up queries to help make sense of what you’ve read, or for quick, direct answers to new questions that weren’t covered in the web pages you saw. It’s all down to your personal preference. That’s on top of AI Chat’s unique generative capabilities, like drafting emails, writing code, creating travel itineraries, and much more.
Since it can be useful to switch back and forth, we’ve made AI Chat accessible through DuckDuckGo Private Search for quick access: after you make a search, just click on the Chat tab underneath the search bar to keep exploring the topic. You can also get to AI Chat directly by navigating to duck.ai or duckduckgo.com/chat; from there, it’s easy to jump back into traditional search using the top navigation.
How does it work … and how is it private?
AI Chat is always anonymous. Want to start over? Hit the Fire Button to delete your current conversation.
When you land on the AI Chat page, you can pick your chat model – currently, OpenAI’s GPT 3.5 Turbo, Anthropic’s latest generation Claude 3 Haiku, and open-source options Mixtral 8x7B and Meta Llama 3 – and start using it just like any other chat interface. Just like searches on DuckDuckGo, all chats are completely anonymous: they cannot be traced back to any one individual. To accomplish that technically, we call the underlying chat models on your behalf, removing your IP address completely and using our IP address instead. This way it looks like the requests are coming from us and not you. Within AI Chat, you can use the Fire Button to clear the chat and start over.
In addition, DuckDuckGo does not save or store any chats. To respond with answers and ensure all systems are working, the underlying model providers may store chats temporarily, but there’s no way for them to tie chats back to you, personally, since all metadata is removed. (Even if you enter your name or other personal information into the chat, the model providers have no way of knowing who typed it in – you, or someone else.) We have agreements in place with all model providers to ensure that any saved chats are completely deleted by the providers within 30 days, and that none of the chats made on our platform can be used to train or improve the models. For more information, please see the DuckDuckGo AI Chat Privacy Policy and Terms of Use.
Is it really free?
Yes! AI Chat is free to use, within a daily limit – which we implement while still maintaining strict user anonymity, just like we do for our search engine. We are planning to keep the current level of access free and exploring a paid plan for access to higher limits and more advanced (and costly) chat models.
What’s next?
We’re excited to spread the word about AI Chat, but there are already improvements on the way. Keep an eye out for new capabilities, like custom system prompts, and general improvements to the AI Chat user experience. We’re also planning to add more chat models – potentially including either DuckDuckGo- or user-hosted options. If you’re interested in seeing a particular chat model or feature added in the future, please let us know via the Share Feedback button in the AI Chat screen.
Ready to give it a spin? Head to duck.ai or duckduckgo.com/chat. You can also find it on your search results page – the Chat tab is just under the search box, on the right side, alongside Images and Videos on the left. If you’re a fan of our bangs, you can also initiate an AI chat by starting your search query with !ai or !chat. Not for you? Head to the Search settings menu to disable AI Chat, DuckAssist, or both.
Happy chatting!
2024-04-11, 11:46

Privacy Pro bundles three new protections from DuckDuckGo into one easy subscription. Subscribers get:
- An anonymous VPN built for speed, security, and simplicity. Secure your connection anytime, anywhere, on up to five devices simultaneously.
- Personal Information Removal, which finds and removes personal details – like your name and home address – from data broker sites that store and sell them, helping to combat identity theft and spam. (U.S. only.)
- Identity Theft Restoration. If your identity is stolen, a dedicated advisor will help restore stolen accounts, assist in recovering resulting financial losses, and help correct your credit report.
Getting these services separately from other companies could cost upwards of $30/month in the U.S.; our users can subscribe to Privacy Pro for $9.99/month or $99.99/year. Privacy Pro is currently available in the United States, Canada, the European Union, and United Kingdom; see this list for the latest availability. Sign up at duckduckgo.com/pro and make sure you're using the most up-to-date version of the DuckDuckGo browser on all your devices. Features and coverage vary by country.
What is Privacy Pro?
Every day, tens of millions of people rely on DuckDuckGo to add a layer of privacy to their online activities. The centerpiece of our product offering is now the DuckDuckGo browser, which offers the most comprehensive set of free privacy protections by default. (One immediate benefit? Fewer ads and popups than you’d see on other browsers.) Our browser bundles our private search engine, tracker blocking, Email Protection, and more than a dozen other free privacy features in one convenient package. However, there’s only so much protection we can provide for free. For example, some protections, like securing our users’ network connections with a VPN, require significantly more bandwidth and other resources.
Enter Privacy Pro: a three-in-one subscription service that offers even more seamless privacy protection. Privacy Pro subscribers get a fast, secure, and easy-to-use VPN that doesn’t log your activity; Personal Information Removal, which helps U.S.-based users remove your information from “people search” data broker sites that store and sell it; and Identity Theft Restoration, which helps to fix credit report mistakes and recover any resulting financial losses. (Please note: Setting up and managing Personal Information Removal requires a Mac or Windows computer.)
On its own, the DuckDuckGo browser lets you search and browse privately. By adding Privacy Pro, you can also limit data brokers’ access to your personal information and secure your Internet connection across your whole device, which hides your location and device IP address from sites you visit — all in one place.

Adding a Privacy Pro subscription makes the DuckDuckGo browser's best-in-class protections even stronger.
More protections, same privacy promise.
At DuckDuckGo, we don’t track you; that’s our privacy policy in a nutshell, and this new subscription service is no exception. Guided by the principle of data minimization, we designed Privacy Pro to maximize your privacy:
- We don’t keep logs of your VPN activity. This means we have no way to tie what you do while connected to the DuckDuckGo VPN to you as an individual — or to anything else you do on DuckDuckGo, like searching.
- Personal Information Removal is the first service of its kind that works directly from your device to keep your sensitive information safe. The details you provide during setup are stored on your device, not on remote servers, and removal requests are initiated directly from that device.
- Unlike other data removal services, which take a more scattershot approach, Personal Information Removal only starts opt-out processes with data brokers once we’ve confirmed that they have you in their databases.
- Unless you become a victim of identity theft and need help, you don’t need to provide any information for Identity Theft Restoration. It’s waiting for you when you need it.
- Payment information is securely handled by Stripe (U.S. only), Google Play, or the Apple App Store, depending on how you sign up. We do not hold or process any of your payment information ourselves.
- Instead of a traditional account, we assign you a random ID when you sign up for Privacy Pro. We have no way to connect this random ID back to your payment information.
We’re here to seamlessly protect your privacy — not compromise it.
Read the Privacy Policy and Terms of Service for Privacy Pro.
VPN
Our non-logging VPN secures your Internet connection on up to five devices at once.
Get an extra layer of online protection with the VPN made for speed, security, and simplicity — built and operated by DuckDuckGo, not an outside provider. Our VPN encrypts your Internet connection for all your browsers and apps across your entire device, hiding your location and IP address from the sites you visit. Because connections are encrypted, your Internet service provider (ISP) can’t see your online traffic either. And we have a strict no-logging policy; we don’t log or store data that can connect you to your online activity, or to any other DuckDuckGo services, such as search.
No need to install a separate VPN app. Once you sign up for Privacy Pro, you can install our VPN right in your DuckDuckGo browser. After that, you can secure your connection in just one click and check its status at a glance. It offers full-device coverage on up to five devices at once.
Our VPN is simple to use. If your VPN connection gets interrupted for any reason, it attempts to reconnect automatically and prevents data leaks until the reconnection is successful. And it works perfectly with DuckDuckGo’s other protections; if you’re an Android user, you should know our VPN is the only one compatible with App Tracking Protection.
We have VPN servers worldwide, and we’ll be adding more over time. To maximize speed and stability, you’ll connect to the closest available VPN server by default, but you can manually choose whichever location you prefer.
To encrypt your traffic and route it through a VPN server, we use the open-source WireGuard protocol, which is fast and secure. We also route your DNS queries automatically through the VPN connection to our own DNS resolvers, which further hides your browsing history from your ISP.
Learn more about the VPN on our Help Pages.
Personal Information Removal
Personal Information Removal helps get your name, address, and more off of people search sites.
Ever tried looking yourself up online? Where our other web tracking protections help defend against trackers that gather your personal information while you browse, Personal Information Removal goes one step further: It works to actually remove personal information, such as your name and home address, from people search sites that store and sell it, helping to combat identity theft and spam.
How does it work? People search sites, like Spokeo and Verecor, are a common type of data broker. They collect your personal information from local and federal records, public forums like social media, and even other data brokers, and make it available online. (If you’re in the U.S., where people search sites can operate freely, you’ve probably seen them in search results when you look up your name.) We scan dozens of these sites for your info and, if found, request its removal, even handling back-and-forth confirmation emails for you automatically behind the scenes. Unlike other similar services, we only contact the data brokers once we confirm that you’re in their databases, and the info you enter for scanning is stored on your device — not on remote servers.
To help us build Personal Information Removal from the ground up while maintaining our strict privacy standards, DuckDuckGo acquired data removal service Removaly in 2022. Removaly was a pioneer in the data removal space, developing a way to navigate data brokers’ confusing opt-out process automatically without compromising users’ privacy in the process.
Personal Information Removal re-scans sites regularly to minimize the risk of your info reappearing, using the data stored on your device. Your device also initiates any removal requests. You can keep tabs on the progress of ongoing removals — and see the personal information we’ve already removed! — on your personal dashboard within the DuckDuckGo browser. Once it’s set up, simply select Personal Information Removal from the browser’s three-dot menu in the upper right.
You'll need to set up Personal Information Removal on one primary Mac or Windows computer. Right now, the dashboard can only be accessed from that device, but we are planning to add the ability to view it from your other devices.
Learn more about Personal Information Removal on our Help Pages. This feature is only available to U.S. subscribers.
Identity Theft Restoration
Get some peace of mind: if your identity is ever compromised, Identity Theft Restoration is standing by to help.
With more than 1 million cases a year reported in the U.S., identity theft is more common than you might think. And Personal Information Removal helps reduce the chance of identity theft, but unfortunately, nothing can totally prevent it. So, let us give you some peace of mind: If your identity is stolen or compromised, Identity Theft Restoration will help you handle the stress and expense.
Identity Theft Restoration is brought to our users in partnership with Iris® Powered by Generali, one of the oldest firms specializing in identity theft in the U.S. Iris’s identity theft advisors are available 24/7, every day of the year, and answer calls within 11 seconds on average. This responsiveness has earned them 18 customer service awards over the last 10 years.
If your identity is stolen, Iris will collect some details about your situation in order to provide assistance; no personal information is shared between Iris and DuckDuckGo. Once a case is established, Iris has several ways to help get you back on track:
- Repairing your credit after fraudulent activity: Iris can help freeze your credit report until your identity is restored and help fix any errors that result from fraudulent activity. They’ll also work with you or your financial institutions to help reverse any fraudulent transactions.
- Document replacement: Iris can help you cancel and replace your driver’s license, bank cards, passport, and social security card. In the U.S., case managers can connect with financial institutions directly; elsewhere, they’ll offer guidance as you replace your documents.
- Travel assistance: In some cases, if you’re 100+ miles from home, Iris can provide a cash advance of up to $500 to assist U.S. subscribers with emergency travel. If you’re abroad when your identity is stolen, they can help you report fraudulent activity to police and legal authorities.
- Untangling fraudulent medical claims: Iris can help inform your healthcare and insurance providers of any fraudulent claims, as well as ensuring medical records are corrected — with help from their in-house medical staff if needed.
- Covering out-of-pocket costs: For U.S. subscribers, Iris reimburses certain out-of-pocket expenses associated with identity theft restoration in some cases The reimbursement benefit is underwritten by an authorized insurance company under insurance policies issued to Iris. Please review the Summary of Benefits to understand the full coverage terms, conditions, and exclusions.
Learn more about Identity Theft Restoration in our Help Pages. Features vary by region.
Getting started and managing your subscription.
Ready to give Privacy Pro a try? Make sure you’ve got the latest version of the DuckDuckGo browser (iOS / Android / macOS / Windows) and head to duckduckgo.com/pro.
Privacy Pro is available for $9.99 USD/month or $99.99 USD/year in the U.S., and can be purchased through the Apple App Store, Google Play Store, or on the web via Stripe. Subscribers in the U.K., E.U., and Canada can sign up via the Apple App Store and Google Play Store only; international pricing details here. Your subscription will auto-renew monthly or annually, depending on the payment terms selected, until canceled. If you subscribed via the Apple App Store or Google Play Store, you can manage your subscription and payment methods there. If you subscribed via our website, you’ll manage your account from the DuckDuckGo browser’s Settings instead.
Note: This blog post has been edited since initial publication to stay up to date with our evolving product offerings.
2024-02-14, 12:26
- Now live: Sync bookmarks, passwords, and Email Protection settings between DuckDuckGo browsers on phones, tablets, and computers, privately and securely.
- Our new Sync & Backup feature is designed with your privacy and security in mind. You don’t need to create an account or sign in to use it, and DuckDuckGo never sees your bookmarks or passwords.
- The DuckDuckGo browser is our privacy-respecting alternative to Chrome and other browsers – use it every day to visit websites and search the web. Get it here for Windows, Mac, iPhone, and Android devices.
Ditching Chrome for the DuckDuckGo browser is easier than ever.
Have you been waiting to try the DuckDuckGo browser? Maybe you’re using our browser on your phone but haven’t tried the Windows or Mac version? Now is the perfect time to make DuckDuckGo the default browser on all your devices, thanks to our latest improvement: Sync & Backup. You could already import bookmarks and passwords from other browsers into DuckDuckGo, but now you can privately sync those bookmarks and passwords between DuckDuckGo browsers on multiple devices.
Bring your passwords and bookmarks with you – without compromising your privacy.
When you use Chrome, there’s a good chance you’re signed in with your Google account – because they’re constantly pressuring you to do so! There is a convenience in that; all your bookmarks, passwords, and favorites follow you wherever you browse, whether you’re using your computer, phone, or tablet. But there’s a problem. This also gives Google implicit permission to collect even more data about your browsing activity than they would otherwise have and use it for targeted advertising that can follow you around.
At DuckDuckGo, we don’t track you; that’s our privacy policy in a nutshell. We’ve developed our privacy-respecting import and sync functions without requiring a DuckDuckGo account – and without compromising your personal data.
Our built-in password manager stores and encrypts your passwords locally on your device. Our private sync is end-to-end encrypted. (When you use private sync, your data stays securely encrypted throughout the syncing process, because the unique key needed to decrypt it is stored only on your devices.) Your passwords are completely inaccessible to anyone but you. That includes us: DuckDuckGo cannot access your data at any time.
What can Sync & Backup do?
- Privately sync and access the bookmarks and passwords saved in your DuckDuckGo browsers – including any you’ve imported from other browsers – across multiple devices.
- Back up passwords, bookmarks, and favorites in case your device is lost or damaged.
- Migrate your bookmarks and passwords to a new device.
- Sync your Email Protection account between devices.
Ready to give it a try? Here’s where to start…
The first step is to download our free browser on one or more devices. (The feature works across most Windows, Mac, Android, and iPhone devices – if you’ve got our browser, you can use Sync & Backup!) If you’re already using the browser, check that it’s up to date. Next, head to the browser’s Settings, choose Sync & Backup > Sync With Another Device and follow the instructions under Begin Syncing.
If you’re on a mobile phone or tablet, you can link devices with a QR code; on desktop computers, you’ll manually enter an alphanumeric code.
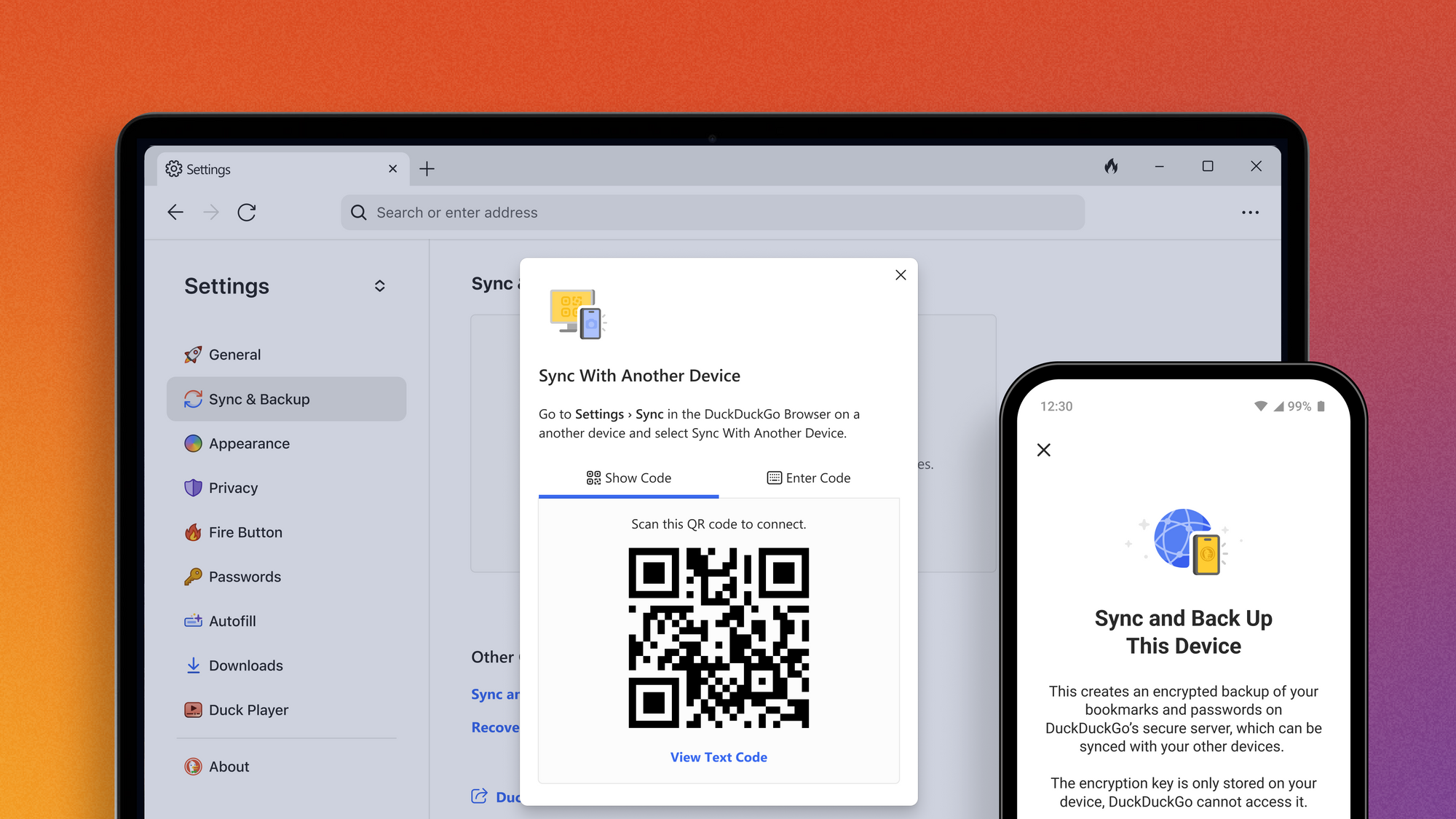
Sync passwords and bookmarks between devices by scanning a QR code or manually entering a unique alphanumeric code – no signing in necessary.
Only working with one device? Choose Sync and Back Up This Device from the “Single-Device Setup” section. Once your sync is complete, you can see a list of all your synced devices, edit device nicknames, and fine-tune your settings.
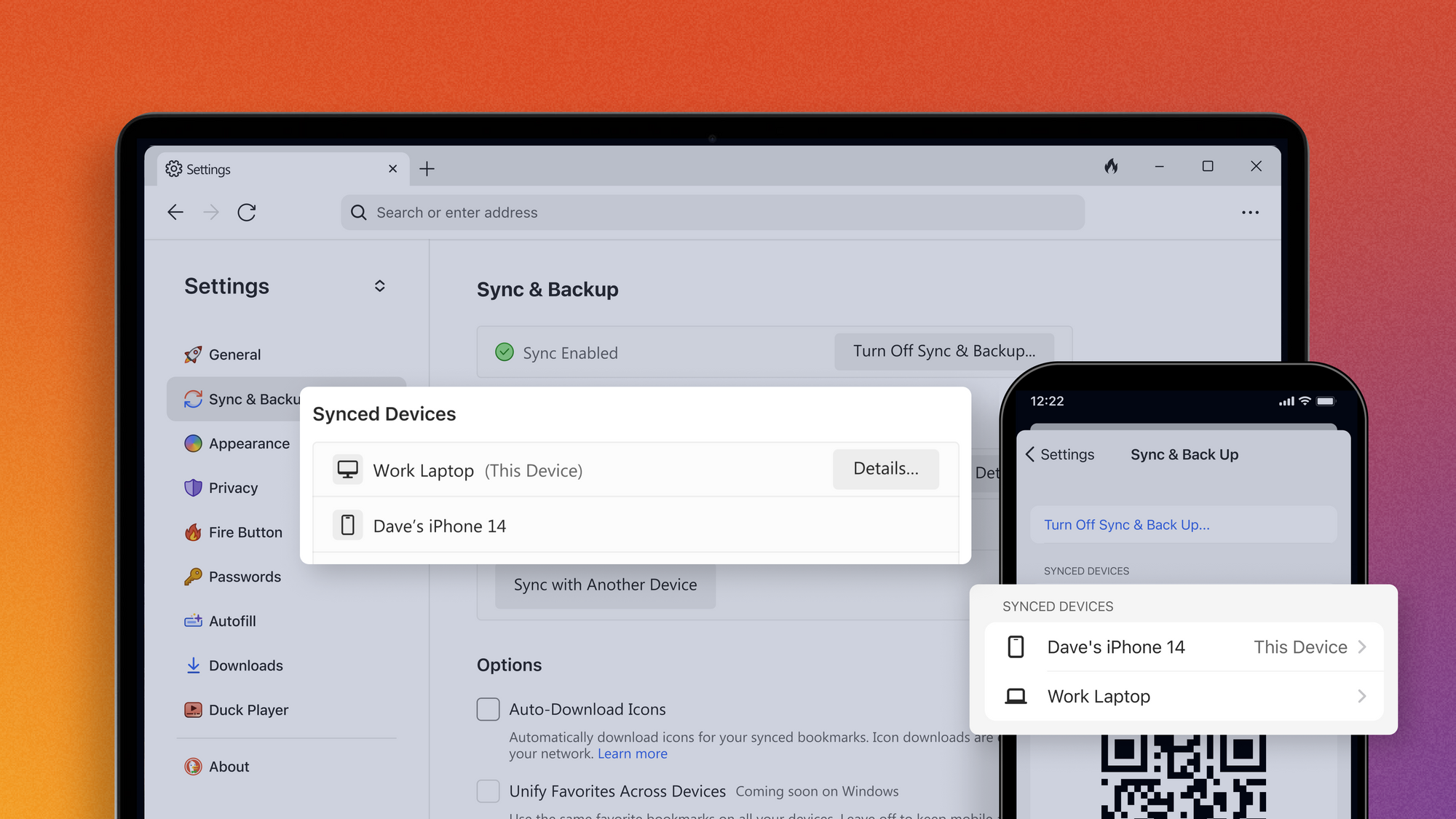
See a list of your synced devices – and add new ones! – under your browser’s Settings > Sync & Back Up.
Once you’re set up, you’ll want to save your Recovery PDF in a secure place. This document contains your Recovery Code, a unique code that will let you access your synced data if your devices are lost or damaged. This is especially important because of our secure end-to-end encryption; your Recovery Code contains the unique, locally generated encryption key that keeps your data private from everyone – including us! If you lose your devices, your Recovery Code is the only way to access your data from a new phone or computer.
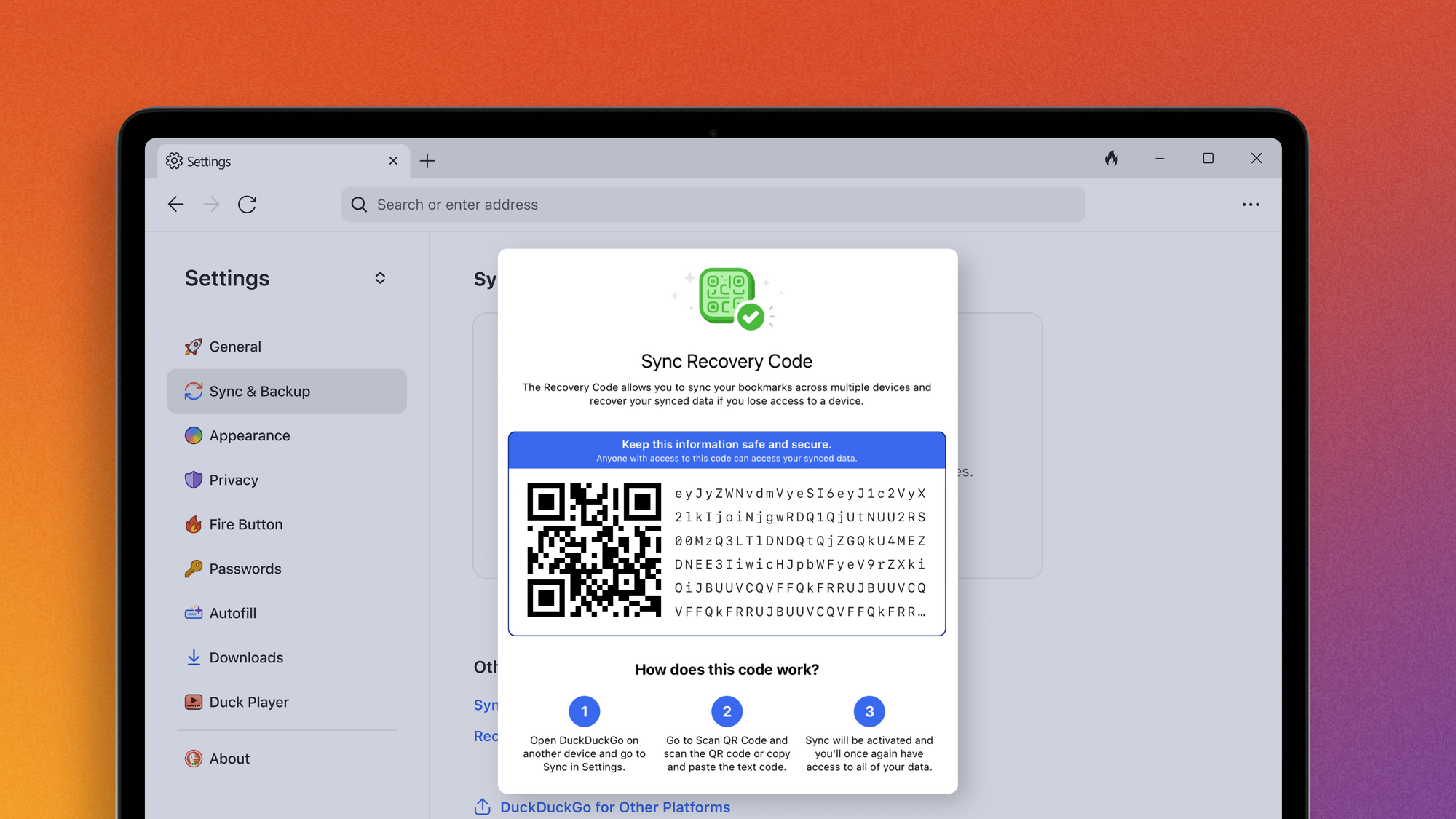
With your Recovery Code, you can restore bookmarks, favorites, and other DuckDuckGo settings on a replacement device if yours is lost or damaged.
What else can the DuckDuckGo browser do?
The DuckDuckGo browser comes with the features you expect from a go-to browser – it even banishes any ads we find that run on creepy trackers, without the need for an outside ad blocker. It also handles cookie pop-ups for you where we can. Plus, over a dozen powerful privacy protections not offered in most popular browsers by default. This uniquely comprehensive set of privacy protections helps protect your online activities, from searching to browsing, emailing, and more.
Our privacy protections work without you having to know anything about the technical details or deal with complicated settings. Just switch your browser to DuckDuckGo across all your devices, and you’ll get privacy by default.
For more detailed instructions on how to use the new sync function – or to peek under the hood of any of DuckDuckGo’s privacy protections! – you can find more information on our Help Pages.
2024-01-31, 12:00
- DuckDuckGo is now carbon negative dating back to our founding in 2008 through 2020, and is committed to being carbon negative in perpetuity.
- We've pioneered new estimation techniques, given our distributed team and non-physical product.
- We're accounting for our full-scope emissions, including upstream and downstream suppliers.
- We're donating the equivalent of 125% of our calculated net emissions to projects vetted by carbon-offset startup CNaught yearly, ranging from emissions reductions to conservation and long-lived removal.
- We're giving that same dollar amount yearly to advance carbon removal technology, currently via Carbonfuture.

At DuckDuckGo, our vision is to raise the standard of trust online. We also care about our impact offline, so we've stepped up to do our part in the climate crisis. We have already been doing what we can to minimize our carbon footprint, including using sustainable energy to power our servers and being a fully distributed company. We’re proud that, as of 2020, DuckDuckGo is carbon negative dating back to our founding in 2008.
When we set out to do this, we quickly realized there wasn’t much guidance for companies like ours that have 100% distributed teams and provide non-physical goods and services. We hope our experience figuring this out can be a reference guide for similar organizations. Here’s the summary:
- Redefining the Scope. We defined our carbon footprint in the broadest possible sense, including all of our suppliers, and vendors (In carbon language, that means Scopes 1, 2, and 3, as well as any other upstream/downstream activities we could pinpoint). We estimated the total impact of all search queries using our search engine, all our marketing activities (including the carbon used when viewing our online display ads), and – given we are a fully distributed company – the impact of all our local working environments.
- Estimating Emissions. During our initial estimate in 2020, we back-estimated to our founding in 2008.
- Net Zero Emissions. In 2020, we funded Gold Standard projects to achieve net zero emissions. Today, we work with CNaught, a carbon-offset firm that relies on leading science to build a rigorously vetted portfolio of projects from around the world, designed from the ground up to maximize climate impact.
- Going Carbon Negative. To go carbon negative in 2020, we first funded an additional 25% of reduction, for a total of 125% of our emissions. We then doubled this dollar amount and spent the second half on Stripe Climate to help build a much-needed market for carbon removal. We’re continuing this work with Carbonfuture, with a global portfolio of expertly vetted carbon removal projects backed by a cutting-edge, data-powered monitoring, reporting, and verification (MRV) solution that brings trust to every stage of the carbon removal process.
Redefining the Scope
We set out to calculate our carbon footprint using the commonly used Greenhouse Gas Protocol. The Protocol groups emissions into three “scopes” and additional activities:
- Scope 1: Direct emissions, e.g., emitted by factories or vehicles you own.
- Scope 2: Indirect emissions from purchasing energy, e.g., buying electricity for or heating and cooling your buildings.
- Scope 3: Other indirect emissions from making products and services, e.g., from purchased materials, business travel, etc.
- Full Upstream/Downstream Activities: Other emissions not covered so far in the full lifecycle of your products and services, e.g., distribution, storage, and disposal, sometimes covered in Scope 3 definitions and sometimes not.
Many companies who claim they are “carbon neutral” are often only looking at their Scope 1 or Scope 1 and 2 emissions, even though Scope 3 and Full Upstream/Downstream Activities are often where the vast majority of emissions take place—especially for organizations not producing or processing physical goods.
In addition, many organizations only look at activities where clear guidelines have been defined (e.g., air travel), but ignore areas where there are no guidelines (e.g., impact of marketing, home offices, etc.), even if much of the organization’s carbon emissions are the result of these activities.
At DuckDuckGo, we didn't think the standard went far enough, so we redefined our approach to make us responsible for all emissions we cause that are not already net zero, regardless of their categorization (or lack thereof).
Estimating Emissions
To estimate our emissions, we pulled together leading source material from environmental agencies around the world including the UK DEFRA / DEEC 2012 GHG Conversion Factors for Company Reporting, the EPA's 2018 Emission Factors for Greenhouse Gas Inventories Report, the BEIS' 2019 Government Greenhouse Gas Conversion Factors for Company Reporting Methodology Paper, and the Environmental Commission of Ontario's 2019 Climate Pollution Report. From here, we mapped out the carbon footprint of every single transaction on our books for the entire 2019 calendar year (since we started working on this in mid-2020) and used that to build a model to estimate category emissions per accounting transaction. That means every vendor bill and credit card purchase by a team member.
While some transactions fit into standard models developed by government agencies (e.g., air travel), it turned out that to our knowledge, no one in government had ever calculated the carbon emissions of an online display advertisement. So, in cases where there was no standard model—or where we felt a standard model clearly under-estimated the actual carbon footprint—we developed our own formulas.
We then surveyed our team to better understand their home-office/co-working situations, including the hardware and software they use, their work-related transit, and recorded all this usage as if it were regular direct Scope 1 emissions.
This led to us estimating some currently unorthodox emissions including:
- The hardware and software our staff use in their home offices.
- A proportional amount of heating/cooling used in each home office during the workday.
- The fuel used in the vehicles staff take to partner meetings.
- The emissions that stem from our marketing (both online and offline), such as showing a display ad on a user's computer.
- The amount of emissions generated from each DuckDuckGo Private Search query.
Lastly, we checked the sustainability programs of every single vendor we used in any capacity. Where one couldn't be identified, or where the program clearly failed to account for 100% of their carbon emissions, we recorded the full CO2e emissions from those transactions as our own.
In the end, our estimate for our 2019 emissions — including Scope 1, 2, 3, and Full Upstream/Downstream Activities — totaled 1,075T of CO2e. That works out to an average of 14.33T of CO2e/per year/per full-time team member. We used that figure to calculate a total of 5,875T of CO2e for the entire existence of DuckDuckGo, from our 2008 founding through 2020.
Net Zero Emissions
Once we felt our carbon emissions were properly estimated, we set out to understand how we could properly achieve net zero emissions in a way that would:
- Directly reduce carbon.
- Not come at other environmental costs.
- Respect and improve human life.
After an extensive review of our options, we first partnered with GoldStandard.org, an international non-profit foundation that is focused on reducing carbon emissions through sustainable investment in carbon reduction projects that also help improve the lives of those involved. Those projects included:
- Funding biomass generators in India, Malawi, Kenya, and biodigesters in Cambodia to bring safe, clean, self-reliant energy to small rural farming villages.
- Funding new wind farms in India and Indonesia, to provide clean energy to regions currently dependent on coal burning electricity.
- Providing solar cooking stoves in Chad, and improved clean efficiency stoves in Guinea and Rwanda, to end coal burning pollution and help protect families from inhaling toxic fumes when cooking in the home.
- Funding hydroelectric power in Honduras, and renewable energy in Brazil.
- Supporting biomass conservation and local biodiversity reforestation in Nicaragua and Ethiopia to help local farmers and conservationists rebuild soil that is suffering from desertification due to deforestation.
Current partner CNaught’s projects are similarly distributed across five categories ranging from emissions reductions to conservation and long-lived removal. You can learn more about each category, including example projects, on the CNaught website.
We're proud that DuckDuckGo is not only achieving net zero emissions, but doing so in a way that we hope will have a transformative and on-going impact around the world, creating jobs and improving the health and quality of life for many.
Going Carbon Negative
Addressing the climate crisis requires us to collectively get to net zero global emissions. We believe doing so will require the use of new technologies at scale, such as physically removing carbon from the atmosphere and sequestering it permanently. Unfortunately, this technology is too expensive right now to make an impact at scale.
In 2020, we were one of the first companies to join Stripe's Climate Program to bring down the cost of this technology by making commitments to fund this new type of carbon reduction. Unlike other carbon reduction methods, Stripe's program required that all carbon removal has a permanence of greater than a thousand years, is directly measured and verifiable, and has a net-negative lifecycle ratio of less than one.
Today, DuckDuckGo is pleased to contribute to carbon removal with Carbonfuture. We have committed that every year, whatever amount of money we spend on CNaught projects, we will make an equal dollar contribution to Carbonfuture to help directly remove carbon from the air – and more importantly, to help pull this technology forward. Visit Carbonfuture’s website to learn more about their rigorous, data-driven approach to carbon removal.
Sustainability at DuckDuckGo
We're committed to doing our part, both online and off. As a DuckDuckGo user, we hope you can rest assured that we are doing our part in the climate crisis. We're now achieving net zero emissions through rigorously measured programs that continue to have a positive environmental and societal impact year after year. We're going carbon negative by funding projects to account for 125% of our emissions, and then doubling that total amount to invest in physically removing carbon from the air to advance this important technology for our future.
Note: This blog post has been edited since initial publication with additional information about our sustainability commitments.
For more privacy advice follow us on Twitter, and stay protected and informed with our privacy newsletter.
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
4. NAKED SECURITYby Sophos NewsWide range of security and privacy topics.
2026-06-02, 00:00
AI accelerated tool development and testing, but humans drove the workflow
Categories: Threat Research
Tags: AI, EDR
2026-05-20, 00:00
<p>A malicious VS Code extension led to cloned private repositories, reportedly offered for sale on a criminal forum</p>
Categories: Threat Research
Tags: GitHub, Supply chain
2026-05-19, 00:00
Brute-force attempts against SMB services can be early signs of an attack
Categories: Threat Research
Tags: Ransomware, WantToCry, SMB
2026-05-14, 00:00
<p>Sophos X-Ops looks at the Atomic macOS Stealer and its capabilities</p>
Categories: Threat Research
Tags: MacOS, AMOS, infostealer
2026-05-13, 00:00
With advisories, this month’s count approaches 300 – though many are already in place
Categories: Threat Research, X-ops
Tags: Patch Tuesday, MICROSOFT PATCH TUESDAY
2026-05-12, 00:00
<p>Seven things security teams can start doing today to reduce risk</p>
Categories: Threat Research
Tags: AI, CISO, risk
2026-05-07, 00:00
<p>A malicious imitation of Anthropic’s Claude site leads to DLL sideloading – and a backdoor</p>
Categories: Threat Research
Tags: Claude, Beagle, Backdoor, malvertising, AI, DONUT, DLL sideloading, Sophos X-Ops
2026-05-01, 00:00
Categories: Threat Research
Tags: advisory, Linux, Copy Fail
2026-04-29, 00:00
Categories: Threat Research
Tags: advisory, NPM, SAP
2026-04-24, 00:00
<p>Two supply chain attacks, same day, same command-and-control domain</p>
Categories: Threat Research
Tags: Supply chain, Sophos X-Ops, pipeline, Bitwarden, Checkmarx
2026-04-17, 00:00
Following a long-established pattern, the fourth month of the year is one of the cruelest
Categories: X-ops, Threat Research
Tags: Patch Tuesday
2026-04-16, 00:00
The use of hidden virtual machines (VMs) enables long-term access, credential harvesting, data exfiltration, and PayoutsKing ransomware deployment
Categories: Threat Research
Tags: virtual machine, QEMU, PayoutsKing, GOLD ENCOUNTER, CitrixBleed2
2026-04-09, 00:00
Categories: Threat Research
Tags: advisory, vulnerability, Adobe Reader
2026-04-09, 00:00
<p>Following our article on the challenges posed by agentic AI, we gave OpenClaw access to one of our legacy networks</p>
Categories: Threat Research
Tags: OpenClaw, LLM, AI, penetration testing, Red Team, CISO, Sophos X-Ops
2026-03-31, 00:00
Categories: Threat Research
Tags: advisory, NPM, Axios
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
5. KREBS ON SECURITYby Brian KrebsAbout hackers, malware and scams on Internet.
2026-06-01, 17:32
The Instagram accounts for the Obama White House and the Chief Master Sergeant of the U.S. Space Force were briefly defaced with pro-Iranian images and messages over the weekend, after instructions began circulating on Telegram showing how to trick Meta’s “AI support assistant” bot into resetting account passwords.
A screenshot from a video released on Telegram claiming to show how Meta’s AI customer support bot could be tricked into resetting a target’s password.
On May 31, word began to spread on several Telegram instant message channels that Meta’s AI bot would happily add an email address to an existing account as part of the bot’s standard password reset flow.
A video released on Telegram by pro-Iran hackers claimed to document a remarkably simple exploit that appears to have involved using a VPN connection with an IP address that is in or near the target’s usual hometown, requesting a password reset for the account, and then choosing to chat with Meta’s AI support assistant. From there, the video shows the attacker told the bot to link the account in question to a new email address, after which the bot dutifully sent that address a one-time code that allowed a password reset.
The Telegram account that posted the video also linked to screenshots of pro-Iran images, videos and messages that defaced the hacked Instagram accounts, saying hackers had used the exploit to hijack a number of valuable (read: short) Instagram account names that allegedly have a resale value of more than a half million dollars.
Meta has not responded to requests for comment on the video’s claims, but Meta’s Andy Stone said on Twitter/X that the issue had been resolved and that they were securing impacted accounts. The security blog thecybersecguru.com reports that Meta pushed an emergency patch over the weekend, and clarified that no back end database was breached.
“Instagram has notoriously poor human support infrastructure,” Cybersecguru wrote. “Recovering a locked account – especially a high-value one can take weeks of back-and-forth with an automated ticketing system. Meta’s solution was to deploy a conversational AI layer to handle common recovery workflows: relinking a lost email address, triggering a password reset, verifying account ownership. The assistant, presumably, was supposed to reduce friction for legitimate users stuck in account-access hell.”
Ian Goldin, a threat researcher at Lumen’s Black Lotus Labs, said we’re entering unchartered security territory as more large online platforms start allowing AI chatbots to handle sensitive account recovery requests. Just like human customer support employees can be social engineered into providing unauthorized access to someone’s account, AI bots are equally eager to help and vulnerable to persuasion and trickery, he said.
“AI chatbots create interesting new attack surface, and we’re likely going to see a lot more of these kinds of attacks,” Goldin said.
Securing your various online accounts means taking full advantage of the most secure form of multi-factor authentication (MFA) offered (such as a passkey or security key). In this case, even using the least robust form of MFA that Instagram offers — a one-time code sent via SMS — likely would have blocked the exploit: The hackers who released the video on Telegram said their exploit failed to work against any accounts that had MFA enabled.
2026-05-25, 13:21
Authorities in the Netherlands have arrested the co-owners of two related Internet hosting companies for operating IT infrastructure used by Russia to carry out cyberattacks, influence operations and disinformation campaigns inside the European Union. The two men were the focus of a 2025 KrebsOnSecurity story about how their hosting companies had assumed control over the technical infrastructure of Stark Industries Solutions, an Internet service provider sanctioned last year by the EU as a frequent staging ground for cyber mischief from Russia’s intelligence agencies.

An investigator with the Tax Intelligence and Investigation Service (FIOD), the Dutch financial crimes agency, during the raid. Image: FIOD.
The Dutch daily news outlet de Volkskrant reports that the Dutch financial crime agency FIOD on May 18 arrested a 57-year-old from Amsterdam and a 39-year-old from The Hague, charging them with violating sanctions law by directly or indirectly making economic resources available to EU-sanctioned entities.
The Dutch investigation focuses on Stark Industries, a sprawling hosting provider that materialized just two weeks before Russia invaded Ukraine. As detailed in this May 2024 deep-dive, Stark quickly became the source of massive distributed denial-of-service (DDoS) attacks against European targets, and emerged as a top supplier of proxy and anonymity services that showed up time and again in cyberattacks linked to Russia-backed hacking groups.
That report identified two Moldovan brothers — Ivan and Yuri Neculiti and their company PQHosting — who were providing one of Stark’s two main conduits to the larger Internet. In May 2025, the EU sanctioned PQHosting and the Neculiti brothers for aiding Russia’s hybrid warfare efforts. But as KrebsOnSecurity observed in September 2025, those sanctions failed to target Stark’s remaining connection to the Internet — an Internet service provider based in the Netherlands called MIRhosting.
MIRhosting is operated by Andrey Nesterenko, a 39-year-old Russian native who runs the business out of the Netherlands. News that PQHosting and the Neculiti brothers were about to be sanctioned by the EU leaked in the media nearly two weeks before the sanctions were announced last year. During that time, the Stark network assets were transferred from PQHosting to a new entity called the[.]hosting, under the control of the Dutch entity WorkTitans BV.
And as our September 2025 report showed, WorkTitans was controlled by Nesterenko and a 57-year-old from Amsterdam named Youssef Zinad. On top of that, WorkTitans was getting connectivity to the larger Internet solely through MIRhosting, where Zinad had worked previously.
On May 18, Dutch financial crime investigators arrested Nesterenko and Zinad, and searched three businesses in Enschede and Almere and two data centers in Dronten and Schiphol-Rijk. A statement from the Dutch authorities said they also seized laptops, telephones and more than 800 servers.
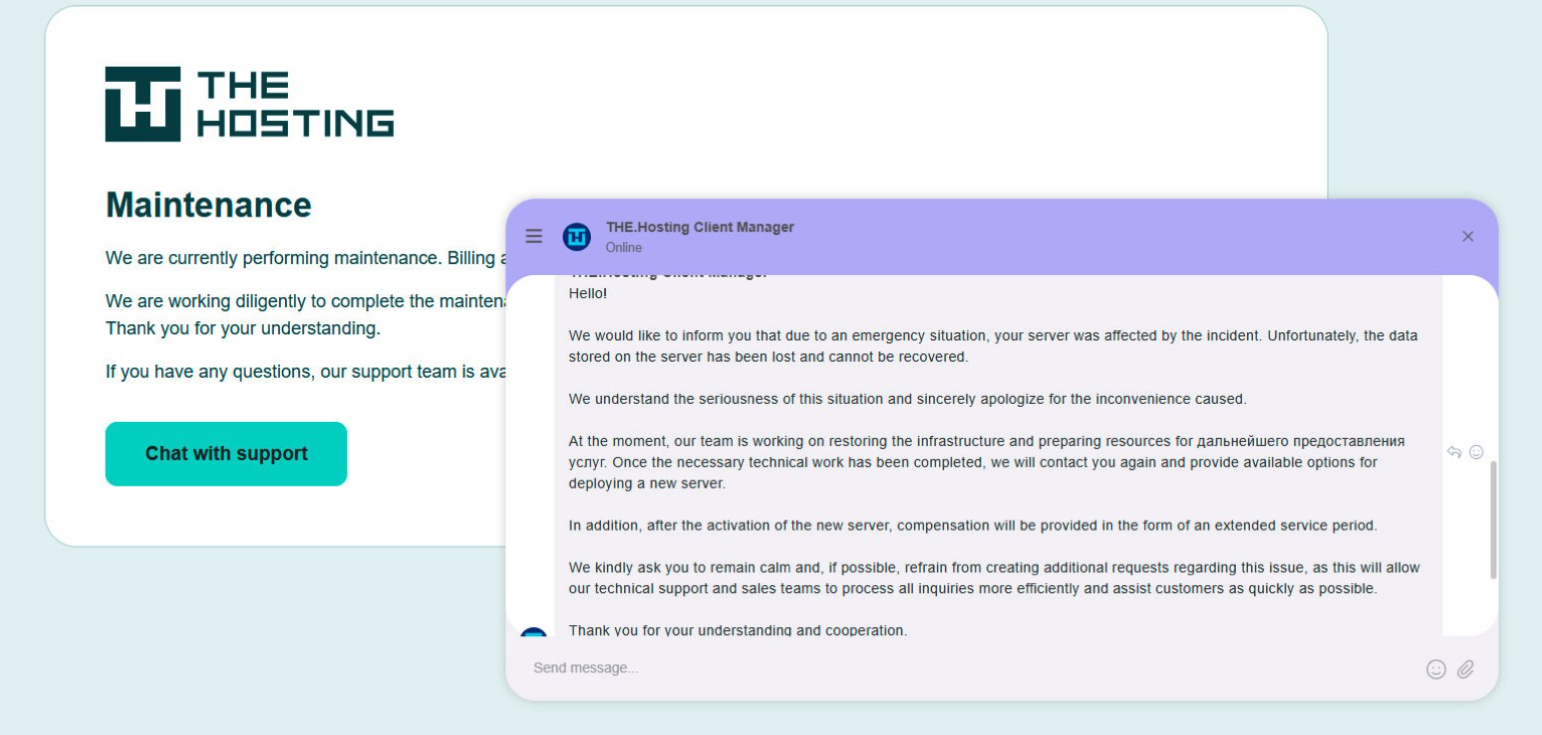
A message to the-hosting customers immediately after 800 of its servers were seized by Dutch authorities. The message says that unfortunately data stored on the server has been lost and cannot be recovered.
De Volkskrant said it reviewed data showing WorkTitans and MIRhosting were the most-used networks in pro-Russian attacks on Danish government bodies between November 13 and 19, 2025, the week of Denmark’s municipal elections.
The publication wrote that prior to Nesterenko’s arrest, the MIRhosting founder denied that he knew his servers had been misused by pro-Russian cybercriminals. “He said he had ended all services with the Neculiti brothers when the EU sanctions came into force in May 2025,” and the he “reserved all rights to take action against ‘harmful and incorrect publications,” de Volkskrant wrote.
MIRhosting released a statement saying it has initiated an internal investigation into the alleged facts concerning the elections in Denmark, and that it has temporarily paused services to WorkTitans as a precautionary measure while the matter is being reviewed further.
“Based on our preliminary findings, there are no indications that the services over which we exercise control were actually used to influence the Danish elections,” the statement reads. “No anomalies or spikes were observed in our network traffic during the period mentioned in the publication; had large-scale DDoS attacks occurred, such activity would have been evident. Furthermore, prior to the media publication, we had not received any complaints, abuse reports, or official requests regarding suspicious activities or misuse of our network. Meanwhile, our regular operational activities continue, and our service to our other clients remains fully intact.”
Born in Nizhny Novgorod, Russia, Mr. Nesterenko grew up as a piano prodigy who performed publicly at a young age. In 2004, Nesterenko founded MIRhosting’s parent Innovation IT Solutions Corp., which has the notable distinction of being the company responsible for hosting stopgeorgia[.]ru, a hacktivist website for organizing cyberattacks against Georgia that appeared at the same time Russian forces invaded the former Soviet nation in 2008. That conflict was thought to be the first war ever fought in which a notable cyberattack and an actual military engagement happened simultaneously.
Responding to questions shared via email, Nesterenko said MIRhosting does not support cybercrime, sanctions evasion, or illegal activity, and that the allegations and arrest by Dutch authorities have been extremely harmful to him and his company.
“The transition to the.hosting was not intended to evade sanctions,” Nesterenko wrote. “The hardware and customer portfolio had already been transferred to WorkTitans before the sanctions appeared. Closing or damaging a legitimate Dutch infrastructure company will not stop cybercrime, but it will harm many people who have done nothing wrong.”
Far less is public about the 57-year-old Zinad, who reportedly has been keeping a low profile since our story last year. De Volkskrant reported that Zinad blocked access to his LinkedIn account, had gone months without responding to emails, WhatsApp messages and phone calls, and told a colleague that illness was forcing him to lead a somewhat more reclusive life.
Mr. Zinad’s now-defunct LinkedIn profile. It was full of posts for MIRhosting’s services.
Mr. Nesterenko claims Zinad was never an employee of MIRhosting.
“He helped me and MIRhosting with certain business tasks under a normal business-to-business arrangement between companies,” Nesterenko explained.
However, in previous emails to KrebsOnSecurity, Nesterenko carbon copied Mr. Zinad (who had a @mirhosting.com email), explaining that he was part of the company’s legal team. Also, the Dutch website stagemarkt[.]nl lists Youssef Zinad as an official contact for MIRhosting’s offices in Almere.
Mr. Zinad has never responded to requests for comment. Nor did de Volkskrant have any luck tracking him down. The publication said it repeatedly asked Mr. Zinad (referred to here as simply “Z”), but he reportedly avoided every form of contact.
“‘I am unavailable but will respond to your message as soon as possible,’ reads an automated reply on WhatsApp on 2 October 2025,” de Volkskrant reported. “It is the only response de Volkskrant would receive in months. He did not pick up his phone and did not call back. When an acquaintance asked him via LinkedIn to contact the reporter, he blocked access to his LinkedIn page. At an address in Almere where Z.’s personal limited company is registered, no one was present in April. The corner house’s blinds were drawn, and a pile of rubbish bags lay outside next to a container, as if someone had recently left. A neighbour said he knew the man but did not know where he was staying. Z. was later arrested at a residence in Amsterdam.”
2026-05-22, 16:34
Lawmakers in both houses of Congress are demanding answers from the U.S. Cybersecurity & Infrastructure Security Agency (CISA) after KrebsOnSecurity reported this week that a CISA contractor intentionally published AWS GovCloud keys and a vast trove of other agency secrets on a public GitHub account. The inquiry comes as CISA is still struggling to contain the breach and invalidate the leaked credentials.
![]()
On May 18, KrebsOnSecurity reported that a CISA contractor with administrative access to the agency’s code development platform had created a public GitHub profile called “Private-CISA” that included plaintext credentials to dozens of internal CISA systems. Experts who reviewed the exposed secrets said the commit logs for the code repository showed the CISA contractor disabled GitHub’s built-in protection against publishing sensitive credentials in public repos.
CISA acknowledged the leak but has not responded to questions about the duration of the data exposure. However, experts who reviewed the now-defunct Private-CISA archive said it was originally created in November 2025, and that it exhibits a pattern consistent with an individual operator using the repository as a working scratchpad or synchronization mechanism rather than a curated project repository.
In a written statement, CISA said “there is no indication that any sensitive data was compromised as a result of the incident.” But in a May 19 a letter (PDF) to CISA’s Acting Director Nick Andersen, Sen. Maggie Hassan (D-NH) said the credential leak raises serious questions about how such a security lapse could occur at the very agency charged with helping to prevent cyber breaches.
“This reporting raises serious concerns regarding CISA’s internal policies and procedures at a time of significant cybersecurity threats against U.S. critical infrastructure,” Sen. Hassan wrote.

A May 19 letter from Sen. Margaret Hassan (D-NH) to the acting director of CISA demanded answers to a dozen questions about the breach.
Sen. Hassan noted that the incident occurred against the backdrop of major disruptions internally at CISA, which lost more than a third of it workforce and almost all of its senior leaders after the Trump administration forced a series of early retirements, buyouts, and resignations across the agency’s various divisions.
Rep. Bennie Thompson (D-MS), the ranking member on the House Homeland Security Committee, echoed the senator’s concerns.
“We are concerned that this incident reflects a diminished security culture and/or an inability for CISA to adequately manage its contract support,” Thompson wrote in a May 19 letter to the acting CISA chief that was co-signed by Rep. Delia Ramirez (D-Ill), the ranking member of the panel’s Subcommittee on Cybersecurity and Infrastructure Protection. “It’s no secret that our adversaries — like China, Russia, and Iran — seek to gain access to and persistence on federal networks. The files contained in the ‘Private-CISA’ repository provided the information, access, and roadmap to do just that.”
KrebsOnSecurity has learned that more a week after CISA was first notified of the data leak by the security firm GitGuardian, the agency is still working to invalidate and replace many of the exposed keys and secrets.
On May 20, KrebsOnSecurity heard from Dylan Ayrey, the creator of TruffleHog, an open-source tool for discovering private keys and other secrets buried in code hosted at GitHub and other public platforms. Ayrey said CISA still hadn’t invalidated an RSA private key exposed in the Private-CISA repo that granted access to a GitHub app which is owned by the CISA enterprise account and installed on the CISA-IT GitHub organization with full access to all code repositories.
“An attacker with this key can read source code from every repository in the CISA-IT organization, including private repos, register rogue self-hosted runners to hijack CI/CD pipelines and access repository secrets, and modify repository admin settings including branch protection rules, webhooks, and deploy keys,” Ayrey told KrebsOnSecurity. CI/CD stands for Continuous Integration and Continuous Delivery, and it refers to a set of practices used to automate the building, testing and deployment of software.
KrebsOnSecurity notified CISA about Ayrey’s findings on May 20. Ayrey said CISA appears to have invalidated the exposed RSA private key sometime after that notification. But he noted that CISA still hasn’t rotated leaked credentials tied to other critical security technologies that are deployed across the agency’s technology portfolio (KrebsOnSecurity is not naming those technologies publicly for the time being).
CISA responded with a brief written statement in response to questions about Ayrey’s findings, saying “CISA is actively responding and coordinating with the appropriate parties and vendors to ensure any identified leaked credentials are rotated and rendered invalid and will continue to take appropriate steps to protect the security of our systems.”
Ayrey said his company Truffle Security monitors GitHub and a number of other code platforms for exposed keys, and attempts to alert affected accounts to the sensitive data exposure(s). They can do this easily on GitHub because the platform publishes a live feed which includes a record of all commits and changes to public code repositories. But he said cybercriminal actors also monitor these public feeds, and are often quick to pounce on API or SSH keys that get inadvertently published in code commits.
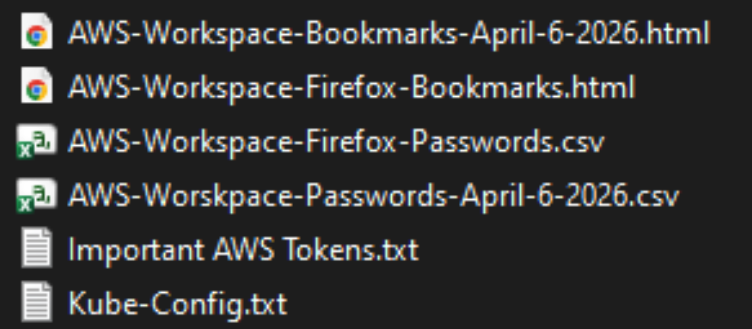
The Private-CISA GitHub repo exposed dozens of plaintext credentials to important CISA GovCloud resources.
In practical terms, it is likely that cybercrime groups or foreign adversaries also noticed the publication of these CISA secrets, the most egregious of which appears to have happened in late April 2026, Ayrey said.
“We monitor that firehose of data for keys, and we have tools to try to figure out whose they are,” he said. “We have evidence attackers monitor that firehose as well. Anyone monitoring GitHub events could be sitting on this information.”
James Wilson, the enterprise technology editor for the Risky Business security podcast, said organizations using GitHub to manage code projects can set top-down policies that prevent employees from disabling GitHub’s protections against publishing secret keys and credentials. But Wilson’s co-host Adam Boileau said it’s not clear that any technology could stop employees from opening their own personal GitHub account and using it to store sensitive and proprietary information.
“Ultimately, this is a thing you can’t solve with a technical control,” Boileau said on this week’s podcast. “This is a human problem where you’ve hired a contractor to do this work and they have decided of their own volition to use GitHub to synchronize content from a work machine to a home machine. I don’t know what technical controls you could put in place given that this is being done presumably outside of anything CISA managed or even had visibility on.”
Update, 3:05 p.m. ET: Added statement from CISA. Corrected a date in the story (Truffle Security said it found the repo gained some of its most sensitive secrets in late April 2026, not 2025).
2026-05-21, 21:50
Canadian authorities on Wednesday arrested a 23-year-old Ottawa man on suspicion of building and operating Kimwolf, a fast spreading Internet-of-Things botnet that enslaved millions of devices for use in a series of massive distributed denial-of-service (DDoS) attacks over the past six months. KrebsOnSecurity publicly named the suspect in February 2026 after the accused launched a volley of DDoS, doxing and swatting campaigns against this author and a security researcher. He now faces criminal hacking charges in both Canada and the United States.
A criminal complaint unsealed today in an Alaska district court charges Jacob Butler, a.k.a. “Dort,” of Ottawa, Canada with operating the Kimwolf DDoS botnet. A statement from the Department of Justice says the complaint against Butler was unsealed following the defendant’s arrest in Canada by the Ontario Provincial Police pursuant to a U.S. extradition warrant. Butler is currently in Canadian custody awaiting an initial court hearing scheduled for early next week.
The government said Kimwolf targeted infected devices which were traditionally “firewalled” from the rest of the internet, such as digital photo frames and web cameras. The infected systems were then rented to other cybercriminals, or forced to participate in record-smashing DDoS attacks, as well as assaults that affected Internet address ranges for the Department of Defense. Consequently, the DoD’s Defense Criminal Investigative Service is investigating the case, with assistance from the FBI field office in Anchorage.
“KimWolf was tied to DDoS attacks which were measured at nearly 30 Terabits per second, a record in recorded DDoS attack volume,” the Justice Department statement reads. “These attacks resulted in financial losses which, for some victims, exceeded one million dollars. The KimWolf botnet is alleged to have issued over 25,000 attack commands.”
On March 19, U.S. authorities joined international law enforcement partners in seizing the technical infrastructure for Kimwolf and three other large DDoS botnets — named Aisuru, JackSkid and Mossad — that were all competing for the same pool of vulnerable devices.
On February 28, KrebsOnSecurity identified Butler as the Kimwolf botmaster after digging through his various email addresses, registrations on the cybercrime forums, and posts to public Telegram and Discord servers. However, Dort continued to threaten and harass researchers who helped track down his real-life identity and dramatically slow the spread of his botnet.
Dort claimed responsibility for at least two swatting attacks targeting the founder of Synthient, a security startup that helped to secure a widespread critical security weakness that Kimwolf was using to spread faster and more effectively than any other IoT botnet out there. Synthient was among many technology companies thanked by the Justice Department today, and Synthient’s founder Ben Brundage told KrebsOnSecurity he’s relieved Butler is in custody.
“Hopefully this will end the harassment,” Brundage said.
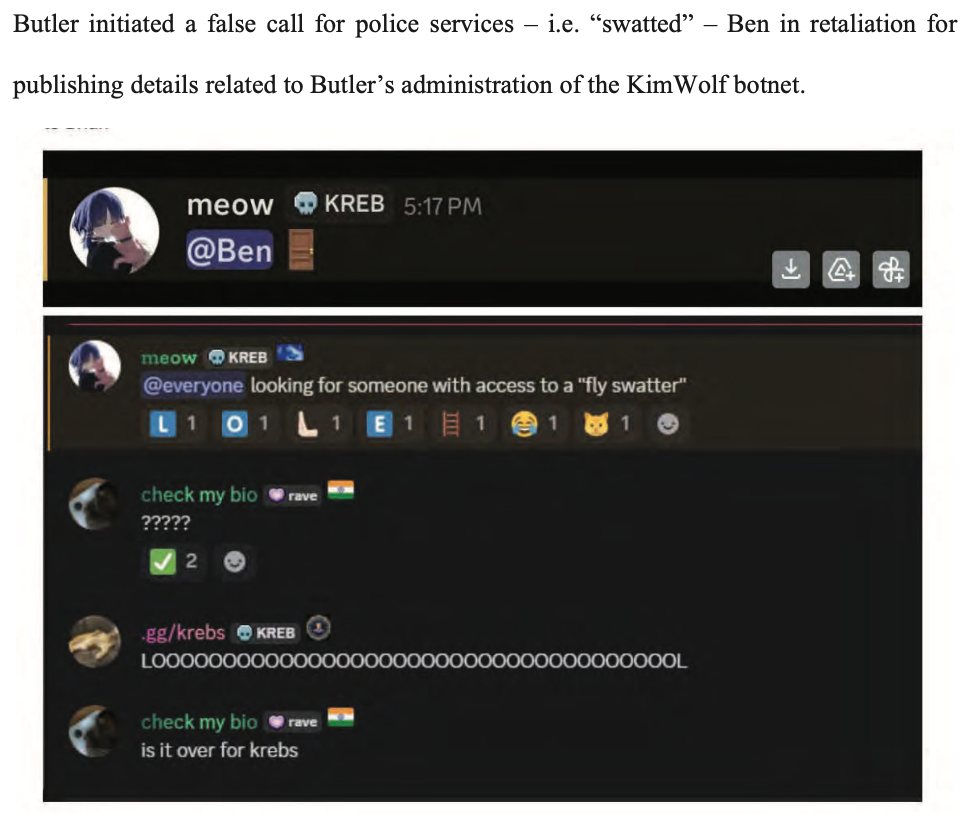
An excerpt from the criminal complaint against Butler, detailing how he ordered a swatting attack against Ben Brundage, the founder of the security firm Synthient.
The government says investigators connected Butler to the administration of the KimWolf botnet through IP address, online account information, transaction records, and online messaging application records obtained through the issuance of legal process. The criminal complaint against Butler (PDF) shows he did little to separate his real-life and cybercriminal identities (something we demonstrated in our February unmasking of Dort).
In April, the Justice Department joined authorities across Europe in seizing domain names tied to nearly four-dozen DDoS-for-hire services, although because of a bureaucratic mix-up the list of seized domains has remain sealed until today. The DOJ said at least one of those services collaborated with Butler’s Kimwolf botnet.
A statement from the Ontario Provincial Police said a search warrant was executed on March 19 at Butler’s address in Ottawa, where they seized multiple devices. As a result of that investigation, Butler was arrested and charged this week with unauthorized user of computer; possession of device to obtain unauthorized use of computer system or to commit mischief; and mischief in relation to computer data. He is scheduled to remain in custody until a hearing on May 26.
In the United States, Butler is facing one count of aiding and abetting computer intrusion. If extradited, tried and convicted in a U.S. court, Butler could face up to 10 years in prison, although that maximum sentence would likely be heavily tempered by considerations in the U.S. Sentencing Guidelines, which make allowances for mitigating factors such as youth, lack of criminal history and level of cooperation with investigators.
2026-05-18, 20:48
Until this past weekend, a contractor for the Cybersecurity & Infrastructure Security Agency (CISA) maintained a public GitHub repository that exposed credentials to several highly privileged AWS GovCloud accounts and a large number of internal CISA systems. Security experts said the public archive included files detailing how CISA builds, tests and deploys software internally, and that it represents one of the most egregious government data leaks in recent history.
On May 15, KrebsOnSecurity heard from Guillaume Valadon, a researcher with the security firm GitGuardian. Valadon’s company constantly scans public code repositories at GitHub and elsewhere for exposed secrets, automatically alerting the offending accounts of any apparent sensitive data exposures. Valadon said he reached out because the owner in this case wasn’t responding and the information exposed was highly sensitive.
A redacted screenshot of the now-defunct “Private CISA” repository maintained by a CISA contractor.
The GitHub repository that Valadon flagged was named “Private-CISA,” and it harbored a vast number of internal CISA/DHS credentials and files, including cloud keys, tokens, plaintext passwords, logs and other sensitive CISA assets.
Valadon said the exposed CISA credentials represent a textbook example of poor security hygiene, noting that the commit logs in the offending GitHub account show that the CISA administrator disabled the default setting in GitHub that blocks users from publishing SSH keys or other secrets in public code repositories.
“Passwords stored in plain text in a csv, backups in git, explicit commands to disable GitHub secrets detection feature,” Valadon wrote in an email. “I honestly believed that it was all fake before analyzing the content deeper. This is indeed the worst leak that I’ve witnessed in my career. It is obviously an individual’s mistake, but I believe that it might reveal internal practices.”
One of the exposed files, titled “importantAWStokens,” included the administrative credentials to three Amazon AWS GovCloud servers. Another file exposed in their public GitHub repository — “AWS-Workspace-Firefox-Passwords.csv” — listed plaintext usernames and passwords for dozens of internal CISA systems. According to Caturegli, those systems included one called “LZ-DSO,” which appears short for “Landing Zone DevSecOps,” the agency’s secure code development environment.
Philippe Caturegli, founder of the security consultancy Seralys, said he tested the AWS keys only to see whether they were still valid and to determine which internal systems the exposed accounts could access. Caturegli said the GitHub account that exposed the CISA secrets exhibits a pattern consistent with an individual operator using the repository as a working scratchpad or synchronization mechanism rather than a curated project repository.
“The use of both a CISA-associated email address and a personal email address suggests the repository may have been used across differently configured environments,” Caturegli observed. “The available Git metadata alone does not prove which endpoint or device was used.”
The Private CISA GitHub repo exposed dozens of plaintext credentials for important CISA GovCloud resources.
Caturegli said he validated that the exposed credentials could authenticate to three AWS GovCloud accounts at a high privilege level. He said the archive also includes plain text credentials to CISA’s internal “artifactory” — essentially a repository of all the code packages they are using to build software — and that this would represent a juicy target for malicious attackers looking for ways to maintain a persistent foothold in CISA systems.
“That would be a prime place to move laterally,” he said. “Backdoor in some software packages, and every time they build something new they deploy your backdoor left and right.”
In response to questions, a spokesperson for CISA said the agency is aware of the reported exposure and is continuing to investigate the situation.
“Currently, there is no indication that any sensitive data was compromised as a result of this incident,” the CISA spokesperson wrote. “While we hold our team members to the highest standards of integrity and operational awareness, we are working to ensure additional safeguards are implemented to prevent future occurrences.”
A review of the GitHub account and its exposed passwords show the “Private CISA” repository was maintained by an employee of Nightwing, a government contractor based in Dulles, Va. Nightwing declined to comment, directing inquiries to CISA.
CISA has not responded to questions about the potential duration of the data exposure, but Caturegli said the Private CISA repository was created on November 13, 2025. The contractor’s GitHub account was created back in September 2018.
The GitHub account that included the Private CISA repo was taken offline shortly after both KrebsOnSecurity and Seralys notified CISA about the exposure. But Caturegli said the exposed AWS keys inexplicably continued to remain valid for another 48 hours.
CISA is currently operating with only a fraction of its normal budget and staffing levels. The agency has lost nearly a third of its workforce since the beginning of the second Trump administration, which forced a series of early retirements, buyouts, and resignations across the agency’s various divisions.
The now-defunct Private CISA repo showed the contractor also used easily-guessed passwords for a number of internal resources; for example, many of the credentials used a password consisting of each platform’s name followed by the current year. Caturegli said such practices would constitute a serious security threat for any organization even if those credentials were never exposed externally, noting that threat actors often use key credentials exposed on the internal network to expand their reach after establishing initial access to a targeted system.
“What I suspect happened is [the CISA contractor] was using this GitHub to synchronize files between a work laptop and a home computer, because he has regularly committed to this repo since November 2025,” Caturegli said. “This would be an embarrassing leak for any company, but it’s even more so in this case because it’s CISA.”
2026-05-12, 21:46
Artificial intelligence platforms may be just as susceptible to social engineering as human beings, but they are proving remarkably good at finding security vulnerabilities in human-made computer code. That reality is on full display this month with some of the more widely-used software makers — including Apple, Google, Microsoft, Mozilla and Oracle — fixing near record volumes of security bugs, and/or quickening the tempo of their patch releases.
As it does on the second Tuesday of every month, Microsoft today released software updates to address at least 118 security vulnerabilities in its various Windows operating systems and other products. Remarkably, this is the first Patch Tuesday in nearly two years that Microsoft is not shipping any fixes to deal with emergency zero-day flaws that are already being exploited. Nor have any of the flaws fixed today been previously disclosed (potentially giving attackers a heads up in how to exploit the weakness).
Sixteen of the vulnerabilities earned Microsoft’s most-dire “critical” label, meaning malware or miscreants could abuse these bugs to seize remote control over a vulnerable Windows device with little or no help from the user. Rapid7 has done much of the heavy lifting in identifying some of the more concerning critical weaknesses this month, including:
- CVE-2026-41089: A critical stack-based buffer overflow in Windows Netlogon that offers an attacker SYSTEM privileges on the domain controller. No privileges or user interaction are required, and attack complexity is low. Patches are available for all versions of Windows Server from 2012 onwards.
- CVE-2026-41096: A critical RCE in the Windows DNS client implementation worthy of attention despite Microsoft assessing exploitation as less likely.
- CVE-2026-41103: A critical elevation of privilege vulnerability that allows an unauthorized attacker to impersonate an existing user by presenting forged credentials, thus bypassing Entra ID. Microsoft expects that exploitation is more likely.
May’s Patch Tuesday is a welcome respite from April, which saw Microsoft fix a near-record 167 security flaws. Microsoft was among a few dozen tech giants given access to a “Project Glasswing,” a much-hyped AI capability developed by Anthropic that appears quite effective at unearthing security vulnerabilities in code.
Apple, another early participant in Project Glasswing, typically fixes an average of 20 vulnerabilities each time it ships a security update for iOS devices, said Chris Goettl, vice president of product management at Ivanti. On May 11, Apple shipped updates to address at least 52 vulnerabilities and backported the changes all the way to iPhone 6s and iOS 15.
Last month, Mozilla released Firefox 150, which resolved a whopping 271 vulnerabilities that were reportedly discovered during the Glasswing evaluation.
“Since Firefox 150.0.0 released, they have been on a more aggressive weekly cadence for security updates including the release of Firefox 150.0.3 on May Patch Tuesday resolving between three to five CVEs in each release,” Goettl said.
The software giant Oracle likewise recently increased its patch pace in response to their work with Glasswing. In its most recent quarterly patch update, Oracle addressed at least 450 flaws, including more than 300 fixes for remotely exploitable, unauthenticated flaws. But at the end of April, Oracle announced it was switching to a monthly update cycle for critical security issues.
On May 8, Google started rolling out updates to its Chrome browser that fixed an astonishing 127 security flaws (up from just 30 the previous month). Chrome automagically downloads available security updates, but installing them requires fully restarting the browser.
If you encounter any weirdness applying the updates from Microsoft or any other vendor mentioned here, feel free to sound off in the comments below. Meantime, if you haven’t backed up your data and/or drive lately, doing that before updating is generally sound advice. For a more granular look at the Microsoft updates released today, checkout this inventory by the SANS Internet Storm Center.
2026-05-08, 02:58
An ongoing data extortion attack targeting the widely-used education technology platform Canvas disrupted classes and coursework at school districts and universities across the United States today, after a cybercrime group defaced the service’s login page with a ransom demand that threatened to leak data from 275 million students and faculty across nearly 9,000 educational institutions.
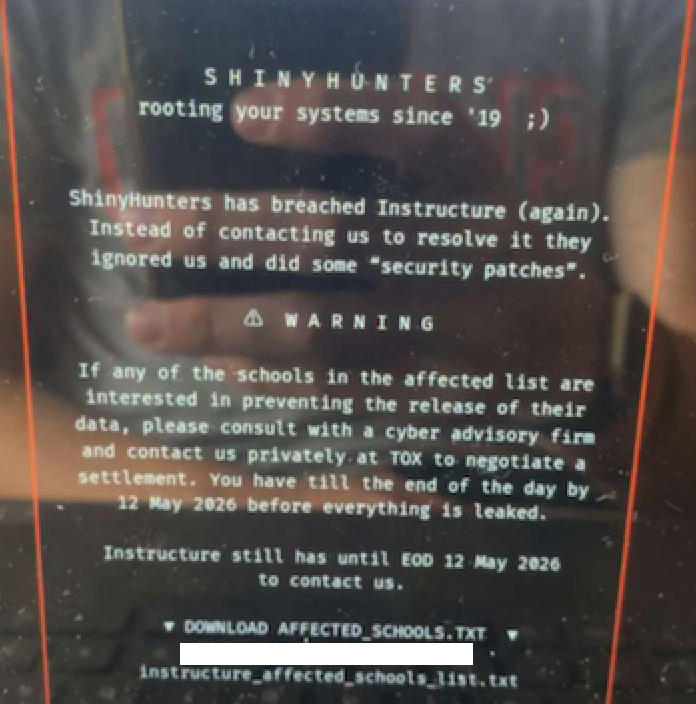
A screenshot shared by a reader showing the extortion message that was shown on the Canvas login page today.
Canvas parent firm Instructure responded to today’s defacement attacks by disabling the platform, which is used by thousands of schools, universities and businesses to manage coursework and assignments, and to communicate with students.
Instructure acknowledged a data breach earlier this week, after the cybercrime group ShinyHunters claimed responsibility and said they would leak data on tens of millions of students and faculty unless paid a ransom. The stated deadline for payment was initially set at May 6, but it was later pushed back to May 12.
In a statement on May 6, Instructure said the investigation so far shows the stolen information includes “certain identifying information of users at affected institutions, such as names, email addresses, and student ID numbers, as well as as messages among users.” The company said it found no evidence the breached data included more sensitive information, such as passwords, dates of birth, government identifiers or financial information.
The May 6 update stated that Canvas was fully operational, and that Instructure was not seeing any ongoing unauthorized activity on their platform. “At this stage, we believe the incident has been contained,” Instructure wrote.
However, by mid-day on Thursday, May 7, students and faculty at dozens of schools and universities were flooding social media sites with comments saying that a ransom demand from ShinyHunters had replaced the usual Canvas login page. Instructure responded by pulling Canvas offline and replacing the portal with the message, “Canvas is currently undergoing scheduled maintenance. Check back soon.”
“We anticipate being up soon, and will provide updates as soon as possible,” reads the current message on Instructure’s status page.
While the data stolen by ShinyHunters may or may not contain particularly sensitive information (ShinyHunters claims it includes several billion private messages among students and teachers, as well as names, phone numbers and email addresses), this attack could hardly have come at a worse time for Instructure: Many of the affected schools and universities are in the middle of final exams, and a prolonged outage could be highly damaging for the company.
The extortion message that greeted countless Canvas users today advised the affected schools to negotiate their own ransom payments to prevent the publication of their data — regardless of whether Instructure decides to pay.
“ShinyHunters has breached Instructure (again),” the extortion message read. “Instead of contacting us to resolve it they ignored us and did some ‘security patches.'”
A source close to the investigation who was not authorized to speak to the press told KrebsOnSecurity that a number of universities have already approached the cybercrime group about paying. The same source also pointed out that the ShinyHunters data leak blog no longer lists Instructure among its current extortion victims, and that the samples of data stolen from Canvas customers were removed as well. Data extortion groups like ShinyHunters will typically only remove victims from their leak sites after receiving an extortion payment or after a victim agrees to negotiate.
Dipan Mann, founder and CEO of the security firm Cloudskope, slammed Instructure for referring to today’s outage as a “scheduled maintenance” event on its status page. Mann said Shiny Hunters first demonstrated they’d breached Instructure on May 1, prompting Instructure’s Chief Information Security Officer Steve Proud to declare the following day that the incident had been contained. But Mann said today’s attack is at least the third time in the past eight months that Instructure has been breached by ShinyHunters.
In a blog post today, Mann noted that in September 2025, ShinyHunters released thousands of internal University of Pennsylvania files — donor records, internal memos, and other confidential materials — through what the Daily Pennsylvanian and other outlets later determined was, in part, a Canvas/Instructure-mediated access path.
“Penn was the named victim,” Mann wrote. “Instructure was the mechanism. The incident was treated as a Penn-specific story by most of the national press and quietly handled by Instructure as a customer-specific matter. That framing was wrong then. It is dramatically more wrong in light of the May 2026 events, which now look like the planned escalation of an attack pattern that ShinyHunters had been working against Instructure’s environment for at least eight months prior. The September 2025 Penn breach was the proof of concept. The May 1, 2026 incident was the production run. The May 7, 2026 recompromise was ShinyHunters demonstrating publicly that the May 2 ‘containment’ did not happen.”
In February, a ShinyHunters spokesperson told The Daily Pennsylvanian that Penn failed to pay a $1 million ransom demand. On March 5, ShinyHunters published 461 megabytes worth of data stolen from Penn, including thousands of files such as donor records and internal memos.
ShinyHunters is a prolific and fluid cybercriminal group that specializes in data theft and extortion. They typically gain access to companies through voice phishing and social engineering attacks that often involve impersonating IT personnel or other trusted members of a targeted organization.
Last month, ShinyHunters relieved the home security giant ADT of personal information on 5.5 million customers. The extortion group told BleepingComputer they breached the company by compromising an employee’s Okta single sign-on account in a voice phishing attack that enabled access to ADT’s Salesforce instance. BleepingComputer says ShinyHunters recently has taken credit for a number of extortion attacks against high-profile organizations, including Medtronic, Rockstar Games, McGraw Hill, 7-Eleven and the cruise line operator Carnival.
The attack on Canvas customers is just one of several major cybercrime campaigns being launched by ShinyHunters at the moment, said Charles Carmakal, chief technology officer at the Google-owned Mandiant Consulting. Carmakal declined to comment specifically on the Canvas breach, but said “there are multiple concurrent and discrete ShinyHunters intrusion and extortion campaigns happening right now.”
Cloudskope’s Mann said what happens next depends largely on whether Instructure’s customers — the universities, K-12 districts, and education ministries paying for Canvas — choose to apply pressure or absorb the breach quietly.
“The history of education-vendor incidents suggests the path of least resistance is the second one,” he concluded.
Update, May 8, 11:05 a.m. ET: Instructure has published an incident update page that includes more information about the breach. Instructure said its Canvas portal is functioning normally again, and that the hackers exploited an issue related to Free-for-Teacher accounts.
“This is the same issue that led to the unauthorized access the prior week,” Instructure wrote. “As a result, we have made the difficult decision to temporarily shut down Free-for-Teacher accounts. These accounts have been a core part of our platform, and we’re committed to resolving the issues with these accounts.”
Instructure said affected organizations were notified on May 6.
“If your organization is affected, Instructure will contact your organization’s primary contacts directly,” the update states. “Please don’t rely on third-party lists or social media posts naming potentially affected organizations as those lists aren’t verified. Instructure will confirm validated information through direct outreach to all affected organizations.”
Update, May 11, 10:16 p.m. ET: Instructure posted an update saying they paid their extortionists in exchange for a promise to destroy the stolen data. “The data was returned to us,” the update reads. “We received digital confirmation of data destruction (shred logs). We have been informed that no Instructure customers will be extorted as a result of this incident, publicly or otherwise.”
2026-04-30, 14:04
A Brazilian tech firm that specializes in protecting networks from distributed denial-of-service (DDoS) attacks has been enabling a botnet responsible for an extended campaign of massive DDoS attacks against other network operators in Brazil, KrebsOnSecurity has learned. The firm’s chief executive says the malicious activity resulted from a security breach and was likely the work of a competitor trying to tarnish his company’s public image.

An Archer AX21 router from TP-Link. Image: tp-link.com.
For the past several years, security experts have tracked a series of massive DDoS attacks originating from Brazil and solely targeting Brazilian ISPs. Until recently, it was less than clear who or what was behind these digital sieges. That changed earlier this month when a trusted source who asked to remain anonymous shared a curious file archive that was exposed in an open directory online.
The exposed archive contained several Portuguese-language malicious programs written in Python. It also included the private SSH authentication keys belonging to the CEO of Huge Networks, a Brazilian ISP that primarily offers DDoS protection to other Brazilian network operators.
Founded in Miami, Fla. in 2014, Huge Networks’s operations are centered in Brazil. The company originated from protecting game servers against DDoS attacks and evolved into an ISP-focused DDoS mitigation provider. It does not appear in any public abuse complaints and is not associated with any known DDoS-for-hire services.
Nevertheless, the exposed archive shows that a Brazil-based threat actor maintained root access to Huge Networks infrastructure and built a powerful DDoS botnet by routinely mass-scanning the Internet for insecure Internet routers and unmanaged domain name system (DNS) servers on the Web that could be enlisted in attacks.
DNS is what allows Internet users to reach websites by typing familiar domain names instead of the associated IP addresses. Ideally, DNS servers only provide answers to machines within a trusted domain. But so-called “DNS reflection” attacks rely on DNS servers that are (mis)configured to accept queries from anywhere on the Web. Attackers can send spoofed DNS queries to these servers so that the request appears to come from the target’s network. That way, when the DNS servers respond, they reply to the spoofed (targeted) address.
By taking advantage of an extension to the DNS protocol that enables large DNS messages, botmasters can dramatically boost the size and impact of a reflection attack — crafting DNS queries so that the responses are much bigger than the requests. For example, an attacker could compose a DNS request of less than 100 bytes, prompting a response that is 60-70 times as large. This amplification effect is especially pronounced when the perpetrators can query many DNS servers with these spoofed requests from tens of thousands of compromised devices simultaneously.
A DNS amplification and reflection attack, illustrated. Image: veracara.digicert.com.
The exposed file archive includes a command-line history showing exactly how this attacker built and maintained a powerful botnet by scouring the Internet for TP-Link Archer AX21 routers. Specifically, the botnet seeks out TP-Link devices that remain vulnerable to CVE-2023-1389, an unauthenticated command injection vulnerability that was patched back in April 2023.
Malicious domains in the exposed Python attack scripts included DNS lookups for hikylover[.]st, and c.loyaltyservices[.]lol, both domains that have been flagged in the past year as control servers for an Internet of Things (IoT) botnet powered by a Mirai malware variant.
The leaked archive shows the botmaster coordinated their scanning from a Digital Ocean server that has been flagged for abusive activity hundreds of times in the past year. The Python scripts invoke multiple Internet addresses assigned to Huge Networks that were used to identify targets and execute DDoS campaigns. The attacks were strictly limited to Brazilian IP address ranges, and the scripts show that each selected IP address prefix was attacked for 10-60 seconds with four parallel processes per host before the botnet moved on to the next target.
The archive also shows these malicious Python scripts relied on private SSH keys belonging to Huge Networks’s CEO, Erick Nascimento. Reached for comment about the files, Mr. Nascimento said he did not write the attack programs and that he didn’t realize the extent of the DDoS campaigns until contacted by KrebsOnSecurity.
“We received and notified many Tier 1 upstreams regarding very very large DDoS attacks against small ISPs,” Nascimento said. “We didn’t dig deep enough at the time, and what you sent makes that clear.”
Nascimento said the unauthorized activity is likely related to a digital intrusion first detected in January 2026 that compromised two of the company’s development servers, as well as his personal SSH keys. But he said there’s no evidence those keys were used after January.
“We notified the team in writing the same day, wiped the boxes, and rotated keys,” Nascimento said, sharing a screenshot of a January 11 notification from Digital Ocean. “All documented internally.”
Mr. Nascimento said Huge Networks has since engaged a third-party network forensics firm to investigate further.
“Our working assessment so far is that this all started with a single internal compromise — one pivot point that gave the attacker downstream access to some resources, including a legacy personal droplet of mine,” he wrote.
“The compromise happened through a bastion/jump server that several people had access to,” Nascimento continued. “Digital Ocean flagged the droplet on January 11 — compromised due to a leaked SSH key, in their wording — I was traveling at the time and addressed it on return. That droplet was deprecated and destroyed, and it was never part of Huge Networks infrastructure.”
The malicious software that powers the botnet of TP-Link devices used in the DDoS attacks on Brazilian ISPs is based on Mirai, a malware strain that made its public debut in September 2016 by launching a then record-smashing DDoS attack that kept this website offline for four days. In January 2017, KrebsOnSecurity identified the Mirai authors as the co-owners of a DDoS mitigation firm that was using the botnet to attack gaming servers and scare up new clients.
In May 2025, KrebsOnSecurity was hit by another Mirai-based DDoS that Google called the largest attack it had ever mitigated. That report implicated a 20-something Brazilian man who was running a DDoS mitigation company as well as several DDoS-for-hire services that have since been seized by the FBI.
Nascimento flatly denied being involved in DDoS attacks against Brazilian operators to generate business for his company’s services.
“We don’t run DDoS attacks against Brazilian operators to sell protection,” Nascimento wrote in response to questions. “Our sales model is mostly inbound and through channel integrator, distributors, partners — not active prospecting based on market incidents. The targets in the scripts you received are small regional providers, the vast majority of which are neither in our customer base nor in our commercial pipeline — a fact verifiable through public sources like QRator.”
Nascimento maintains he has “strong evidence stored on the blockchain” that this was all done by a competitor. As for who that competitor might be, the CEO wouldn’t say.
“I would love to share this with you, but it could not be published as it would lose the surprise factor against my dishonest competitor,” he explained. “Coincidentally or not, your contact happened a week before an important event – one that this competitor has NEVER participated in (and it’s a traditional event in the sector). And this year, they will be participating. Strange, isn’t it?”
Strange indeed.
2026-04-21, 14:53
A 24-year-old British national and senior member of the cybercrime group “Scattered Spider” has pleaded guilty to wire fraud conspiracy and aggravated identity theft. Tyler Robert Buchanan admitted his role in a series of text-message phishing attacks in the summer of 2022 that allowed the group to hack into at least a dozen major technology companies and steal tens of millions of dollars worth of cryptocurrency from investors.
Buchanan’s hacker handle “Tylerb” once graced a leaderboard in the English-language criminal hacking scene that tracked the most accomplished cyber thieves. Now in U.S. custody and awaiting sentencing, the Dundee, Scotland native is facing the possibility of more than 20 years in prison.

Two photos published in a Daily Mail story dated May 3, 2025 show Buchanan as a child (left) and as an adult being detained by airport authorities in Spain. “M&S” in this screenshot refers to Marks & Spencer, a major U.K. retail chain that suffered a ransomware attack last year at the hands of Scattered Spider.
Scattered Spider is the name given to a prolific English-speaking cybercrime group known for using social engineering tactics to break into companies and steal data for ransom, often impersonating employees or contractors to deceive IT help desks into granting access.
As part of his guilty plea, Buchanan admitted conspiring with other Scattered Spider members to launch tens of thousands of SMS-based phishing attacks in 2022 that led to intrusions at a number of technology companies, including Twilio, LastPass, DoorDash, and Mailchimp.
The group then used data stolen in those breaches to carry out SIM-swapping attacks that siphoned funds from individual cryptocurrency investors. In an unauthorized SIM-swap, crooks transfer the target’s phone number to a device they control and intercept any text messages or phone calls to the victim’s device — such as one-time passcodes for authentication and password reset links sent via SMS. The U.S. Justice Department said Buchanan admitted to stealing at least $8 million in virtual currency from individual victims throughout the United States.
FBI investigators tied Buchanan to the 2022 SMS phishing attacks after discovering the same username and email address was used to register numerous phishing domains seen in the campaign. The domain registrar NameCheap found that less than a month before the phishing spree, the account that registered those domains logged in from an Internet address in the U.K. FBI investigators said the Scottish police told them the address was leased to Buchanan throughout 2022.
As first reported by KrebsOnSecurity, Buchanan fled the United Kingdom in February 2023, after a rival cybercrime gang hired thugs to invade his home, assault his mother, and threaten to burn him with a blowtorch unless he gave up the keys to his cryptocurrency wallet. That same year, U.K. investigators found a device at Buchanan’s Scotland residence that included data stolen from SMS phishing victims and seed phrases from cryptocurrency theft victims.
Buchanan was arrested by Spanish authorities in June 2024 while trying to board a flight to Italy. He was extradited to the United States and has remained in U.S. federal custody since April 2025.
Buchanan is the second known Scattered Spider member to plead guilty. Noah Michael Urban, 21, of Palm Coast, Fla., was sentenced to 10 years in federal prison last year and ordered to pay $13 million in restitution. Three other alleged co-conspirators — Ahmed Hossam Eldin Elbadawy, 24, a.k.a. “AD,” of College Station, Texas; Evans Onyeaka Osiebo, 21, of Dallas, Texas; and Joel Martin Evans, 26, a.k.a. “joeleoli,” of Jacksonville, North Carolina – still face criminal charges.
Two other alleged Scattered Spider members will soon be tried in the United Kingdom. Owen Flowers, 18, and Thalha Jubair, 20, are facing charges related to the hacking and extortion of several large U.K. retailers, the London transit system, and healthcare providers in the United States. Both have pleaded not guilty, and their trial is slated to begin in June.
Investigators say the Scattered Spider suspects are part of a sprawling cybercriminal community online known as “The Com,” wherein hackers from different cliques boast publicly on Telegram and Discord about high-profile cyber thefts that almost invariably begin with social engineering — tricking people over the phone, email or SMS into giving away credentials that allow remote access to corporate internal networks.
One of the more popular SIM-swapping channels on Telegram has long maintained a leaderboard of the most rapacious SIM-swappers, indexed by their supposed conquests in stealing cryptocurrency. That leaderboard previously listed Buchanan’s hacker alias Tylerb at #65 (out of 100 hackers), with Urban’s moniker “Sosa” coming in at #24.
Buchanan’s sentencing hearing is scheduled for August 21, 2026. According to the Justice Department, he faces a statutory maximum sentence of 22 years in federal prison. However, any sentence the judge hands down in this case may be significantly tempered by a number of mitigating factors in the U.S. Sentencing Guidelines, including the defendant’s age, criminal history, time already served in U.S. custody, and the degree to which they cooperated with federal authorities.
2026-04-14, 21:47
Microsoft today pushed software updates to fix a staggering 167 security vulnerabilities in its Windows operating systems and related software, including a SharePoint Server zero-day and a publicly disclosed weakness in Windows Defender dubbed “BlueHammer.” Separately, Google Chrome fixed its fourth zero-day of 2026, and an emergency update for Adobe Reader nixes an actively exploited flaw that can lead to remote code execution.

Redmond warns that attackers are already targeting CVE-2026-32201, a vulnerability in Microsoft SharePoint Server that allows attackers to spoof trusted content or interfaces over a network.
Mike Walters, president and co-founder of Action1, said CVE-2026-32201 can be used to deceive employees, partners, or customers by presenting falsified information within trusted SharePoint environments.
“This CVE can enable phishing attacks, unauthorized data manipulation, or social engineering campaigns that lead to further compromise,” Walters said. “The presence of active exploitation significantly increases organizational risk.”
Microsoft also addressed BlueHammer (CVE-2026-33825), a privilege escalation bug in Windows Defender. According to BleepingComputer, the researcher who discovered the flaw published exploit code for it after notifying Microsoft and growing exasperated with their response. Will Dormann, senior principal vulnerability analyst at Tharros, says he confirmed that the public BlueHammer exploit code no longer works after installing today’s patches.
Satnam Narang, senior staff research engineer at Tenable, said April marks the second-biggest Patch Tuesday ever for Microsoft. Narang also said there are indications that a zero-day flaw Adobe patched in an emergency update on April 11 — CVE-2026-34621 — has seen active exploitation since at least November 2025.
Adam Barnett, lead software engineer at Rapid7, called the patch total from Microsoft today “a new record in that category” because it includes nearly 60 browser vulnerabilities. Barnett said it might be tempting to imagine that this sudden spike was tied to the buzz around the announcement a week ago today of Project Glasswing — a much-hyped but still unreleased new AI capability from Anthropic that is reportedly quite good at finding bugs in a vast array of software.
But he notes that Microsoft Edge is based on the Chromium engine, and the Chromium maintainers acknowledge a wide range of researchers for the vulnerabilities which Microsoft republished last Friday.
“A safe conclusion is that this increase in volume is driven by ever-expanding AI capabilities,” Barnett said. “We should expect to see further increases in vulnerability reporting volume as the impact of AI models extend further, both in terms of capability and availability.”
Finally, no matter what browser you use to surf the web, it’s important to completely close out and restart the browser periodically. This is really easy to put off (especially if you have a bajillion tabs open at any time) but it’s the only way to ensure that any available updates get installed. For example, a Google Chrome update released earlier this month fixed 21 security holes, including the high-severity zero-day flaw CVE-2026-5281.
For a clickable, per-patch breakdown, check out the SANS Internet Storm Center Patch Tuesday roundup. Running into problems applying any of these updates? Leave a note about it in the comments below and there’s a decent chance someone here will pipe in with a solution.
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
6. HOT FOR SECURITYby Graham CluleyComputer security news, advice and opinion.
2026-05-29, 08:04
Dutch police have arrested a 35-year-old man suspected of hacking into the computer systems of Amsterdam football giant Ajax, after the personal data of hundreds of thousands of supporters was put at risk. Read more in my article on the Hot for Security blog.
2026-05-28, 13:39
A notorious ransomware gang claims to have stolen MyPillow's private data, but CEO Mike Lindell calls it a politically motivated "hit job." With the countdown ticking toward a massive dark web leak, who is telling the truth? Read more in my article on the Hot for Security blog.
2026-05-27, 23:05
CISA, the US government agency whose entire job is keeping America's critical infrastructure safe from hackers, has had a contractor publish dozens of plain-text credentials to a public GitHub profile. Meanwhile, your Oura ring is quietly transmitting some of its data unencrypted - and when one journalist asked the company how often it hands user data to law enforcement, the answer was quite telling. Plus don't miss our featured interview with OPSWAT's Benny Czarny about his new book "Cybersecurity Upside Down." All this and more in episode 469 of the "Smashing Security" podcast with cybersecurity expert and keynote speaker Graham Cluley, and special guest Lesley Carhart.
2026-05-26, 16:24
So, you've enabled multi-factor authentication. You've taught your staff never to type their passwords into dodgy-looking login pages. Surely your Microsoft 365 accounts are safe now? Well, think again. Read more in my article on the Hot for Security blog.
2026-05-21, 17:13
For almost 20 years, stolen credentials have been the most common route for attackers into organizations, according to the Verizon Data Breach Investigations Report (DBIR). But that's no longer the case. Read more in my article on the Fortra blog.
2026-05-20, 23:04
A 23-year-old radio enthusiast spent £300 on a piece of kit from the internet, and used it to bring four packed high-speed trains to a screeching halt. His defence in court? Possibly the most creative excuse we've heard all year. Meanwhile, owners of $4,000 robot lawnmowers are discovering that their gadget can be hijacked over the internet, redirected at journalists who foolishly lie down in front of it, and used to harvest Wi-Fi passwords, email addresses, and GPS coordinates. Change the default password? Sure - until the next firmware update silently resets it back. Plus - don't miss our featured interview with XBOW's Brendan Dolan-Gavitt about how AI is transforming penetration testing. All this and more in episode 468 of the "Smashing Security" podcast with cybersecurity expert and keynote speaker Graham Cluley, and special guest Geoff White.
2026-05-20, 08:28
Having receive a ransom payment for its attack on Canvas, ShinyHunters and other extortion gangs are only likely to be further incentivised to launch similar attacks in future. Read more in my article on the Hot for Security blog.
2026-05-14, 19:46
Lesson one for aspiring dark web kingpins: don't have your laundered gold bars shipped to your home address. Read more in my article on the Hot for Security blog.
2026-05-14, 09:28
Pay up, or we'll pay someone to pay you a visit. Cybercrime gangs are increasingly turning to real-world threats - and even hiring local muscle to deliver the message. Read more in my article on the Hot for Security blog.
2026-05-13, 23:05
Welcome to the largest educational data breach in history - affecting nearly 9,000 institutions, every Ivy League university, and 30 million students mid-finals. When Canvas's parent company refused to pay and announced they had deployed "security patches" instead, the hackers were less than impressed. So they came back through the cat flap. Meanwhile, a famous finance expert's face has been showing up on Facebook adverts promising hot stock tips and exclusive WhatsApp investment groups. Spoiler: it isn't him, the tips aren't real, and you're about to be scammed. Plus we chat to Mike Nichols of Elastic, about how the SOC isn't dying, attackers and defenders are both deploying AI agents, and how the real security crisis is no longer human users - it's the bots acting on their behalf. All this and more in episode 467 of the "Smashing Security" podcast with cybersecurity expert and keynote speaker Graham Cluley, and special guest Danny Palmer.
2026-05-08, 15:20
One in eight UK workers admits to selling their company login credentials - or knowing someone who has - in the past 12 months. The really alarming bit? Their bosses are even more relaxed about it. Read more in my article on the Fortra blog.
2026-05-08, 14:36
Most universities have a careers fair. At Bauman Moscow State Technical University, however, an elite group of students appear to have something rather more unusual: a direct pipeline into some of the world's most notorious state-sponsored hacking groups. Read more in my article on the Hot for Security blog.
2026-05-08, 09:30
You don't need to live near a scam compound for it to wreck your life. Americans lost $5.8 billion to crypto investment scams last year alone - and a raid in Sri Lanka this month shows exactly how the operations behind them keep finding new places to hide. Read more in my article on the Hot for Security blog.
2026-05-06, 23:30
Meta's smart glasses promise privacy "designed for you" - but everything they record was being beamed off to workers in Nairobi to label by hand. When those workers blew the whistle, Meta sacked all 1,108 of them. Meanwhile, the IT press is in a frenzy over a new Linux bug called "Copy Fail" - complete with logo, dedicated website, and a marketing-friendly name. But is it really the disaster everyone's making it out to be? And in our featured interview, Jake Moore of ESET explains how he tricked a company into offering his deepfake clone a job - after a perfectly normal-looking video interview. All this and more in episode 466 of the "Smashing Security" podcast with cybersecurity expert and keynote speaker Graham Cluley, joined this week by special guest Paul Ducklin.
2026-05-04, 11:42
Here's a tip for you all. Unless you want to draw attention to yourself as a cybercriminal, don't flaunt your diamond-encrusted "HACK THE PLANET" necklace on Snapchat, or pose as a Sopranos crime boss while the FBI is reportedly closing in. Read more in my article on the Hot for Security blog.
2026-04-30, 08:13
US Marines stationed around the Persian Gulf have been receiving WhatsApp messages from strangers suggesting they call home and make their final goodbyes. Read more in my article on the Hot for Security blog.
2026-04-29, 23:15
A developer at an AI startup wanted to cheat at Roblox. They downloaded a dodgy script on their work laptop. That one decision triggered a cascade of failures that ended with a $2 million data breach affecting hundreds of thousands of organisations. All for some free in-game currency. Meanwhile, there's a 1980s phone protocol called SS7 that lets shadowy surveillance companies track anyone, anywhere, via their mobile phone. Governments know about it. Telecoms know about it. Nobody's fixing it. All this and more in episode 465 of the "Smashing Security" podcast with cybersecurity keynote speaker and industry veteran Graham Cluley, joined this week by special guest James Ball. Plus! Don't miss our featured interview with Rob Edmondson of CoreView, discussing how to lock down Microsoft 365 before it's too late.
2026-04-29, 12:14
A man accused of working as a hacker for China's Ministry of State Security has been extradited to the USA from Italy, and faces - if found guilty - the prospect of decades behind bars. Read more in my article on the Hot for Security blog.
2026-04-28, 08:43
A 21-year-old man suspected of conducting approximately 100 data breaches since late 2025 - including a hack of the French Ministry of National Education that exposed records on almost a quarter of a million employees - has been arrested at his home in western France. Read more in my article on the Hot for Security blog.
2026-04-22, 22:20
A company that ran anonymous tip lines for 35,000 American schools - handling reports of bullying, weapons, and self-harm - boasted on its website that it had suffered zero security breaches in over 20 years. A hacker called Internet Yiff Machine thought that sounded like a challenge, with predictable results... Meanwhile, Rockstar Games gets hacked again - and the stolen data turns out to be less embarrassing than the financial secrets it accidentally revealed. GTA Online is still making half a billion dollars a year. Red Dead Redemption is not. All this and more in episode 464 of the "Smashing Security" podcast with cybersecurity keynote speaker and industry veteran Graham Cluley, joined this week by special guest BBC cybersecurity correspondent Joe Tidy. Plus! Don't miss our featured interview with Ryan Benson of Meter.
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
7. BLEEPING COMPUTERby Lawrence AbramsA blog & a free community of computer users.
2026-06-03, 15:36
The U.S. Cybersecurity and Infrastructure Security Agency (CISA) is warning that hackers are exploiting vulnerabilities in the Linux kernel and Android operating system. [...]
2026-06-03, 14:02
A two-week penetration test can leave roughly 345 days of real-world exposure unvalidated. Sprocket Security explores why continuous testing is becoming critical as attack surfaces constantly change. [...]
2026-06-03, 11:35
Acer is working to address two maximum-severity zero-day vulnerabilities affecting its Wave 7 mesh routers. [...]
2026-06-03, 10:12
European and international law enforcement agencies have dismantled nine organized crime groups and arrested 29 suspects in a major crackdown on illegal streaming operations. [...]
2026-06-03, 09:02
Google is introducing a new Android security feature that will detect and flag phone calls in which scammers use artificial intelligence to impersonate a user's personal contacts. [...]
2026-06-03, 06:50
A security researcher has released exploit code for a Visual Studio Code (VS Code) zero-day vulnerability that allows attackers to steal GitHub authentication tokens by tricking users into clicking a link. [...]
2026-06-02, 22:52
Microsoft announced today at its Build 2026 developer conference the release of Coreutils for Windows, bringing many commonly used Linux command-line utilities to Windows as native applications. [...]
2026-06-02, 22:44
OpenAI says it's rolling out a new update that improves the existing GPT-5.5 Instant model, and this move comes ahead of the scheduled retirement of multiple legacy models, including o3. [...]
2026-06-02, 22:12
Hackers are exploiting a critical privilege escalation vulnerability (CVE-2026-8206) in the Kirki plugin for WordPress to take over any user account, including those belonging to administrators. [...]
2026-06-02, 21:54
A large-scale malware campaign dubbed WeedHack is targeting Minecraft players and has infected more than 116,000 systems since January. [...]
2026-06-02, 20:01
A threat actor is using an AI-built ransomware attack toolkit that automates Active Directory discovery and helps evade endpoint detection and response (EDR) solutions. [...]
2026-06-02, 17:02
Microsoft is working to address a widespread service issue affecting the mail flow pipeline for Exchange Online customers across North America and Germany. [...]
2026-06-02, 15:47
Multiple Instagram users had their accounts hijacked after attackers convinced Meta's AI-powered support tools that they were the legitimate owners. [...]
2026-06-02, 14:30
AI-powered attacks and shadow AI adoption are creating new security risks inside the browser. Push Security explains why browser visibility is becoming critical for both threat detection and AI governance. [...]
2026-06-02, 12:40
CISA has ordered government agencies to secure their systems against a high-severity Oracle WebLogic Server vulnerability that was patched two years ago and is now actively exploited in attacks. [...]
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
8. RESTORE PRIVACYby Heinrich LongPrivacy Blog & Knowledge Base
2024-11-12, 12:01
Signal, the privacy-focused messaging app, has announced new features to enhance its calling experience, making it easier for users to initiate and manage group calls. The primary addition, “Call Links,” allows users to share a link to initiate a call with any contact on Signal without the need to create a group chat. This feature …
The post Signal Introduces Call Links for Simplified Private Group Calls appeared first on RestorePrivacy.
2024-11-08, 18:11
The Tor Project is currently facing an unusual, ongoing attack aimed at its infrastructure. For several weeks, an unknown threat actor has been spoofing the IP addresses of Tor relays and directory authorities, sending fake TCP SYN packets over SSH’s port 22. This technique has led to a flood of abuse complaints directed at Tor …
The post Tor Relays Targeted in IP Spoofing Campaign Causing Widespread Disruptions appeared first on RestorePrivacy.
2024-10-28, 18:34
Proton has launched its much-anticipated Black Friday sale for 2024, offering incredible discounts on services like Proton VPN, Proton Mail, Drive, and Pass. These Proton deals all include a 30-day money-back guarantee, allowing you to assess the service risk-free. This sale is the perfect chance to boost your online privacy and access premium features at …
The post Proton Black Friday Deals Go Live: VPN, Mail, Drive, Pass appeared first on RestorePrivacy.
2024-10-22, 17:16
Session, the encrypted messaging app known for its commitment to privacy and decentralization, announced a change of base from Australia to Switzerland. The app will now be overseen by the newly formed Session Technology Foundation (STF), based in central Europe. This move follows increasing regulatory pressure on privacy technologies in Australia, where the app was …
The post Encrypted Messenger Session Moves to Switzerland Amid Privacy Concerns appeared first on RestorePrivacy.
2024-10-16, 16:37
Mullvad VPN announced that macOS users may experience traffic leaks after applying recent system updates due to a firewall malfunction. According to a bulletin published earlier today on Mullvad’s blog, the macOS firewall fails to enforce certain routing rules properly, allowing some applications to bypass the VPN tunnel and send traffic outside of it. Mullvad …
The post Mullvad VPN Warns About Traffic Leaks on Latest macOS Sequoia appeared first on RestorePrivacy.
2024-10-09, 13:48
Discord, a popular communication platform, has been blocked in both Russia and Turkey, sparking widespread backlash from users in both countries. In Russia, the block took place yesterday, with the government citing concerns over illegal content, while Turkey implemented blocks a day prior, on October 7, 2024, claiming the platform was being used for criminal …
The post Discord Blocked in Russia and Turkey Amid Government Crackdowns appeared first on RestorePrivacy.
2024-10-01, 16:07
NordVPN, one of the world’s leading VPN service providers, has launched its first application featuring quantum-resilient encryption. Post-quantum cryptography support is currently available on NordVPN’s Linux client, with plans to extend this security to all applications by the first quarter of 2025. The move represents a significant step toward preparing for potential future threats posed …
The post NordVPN Adds NIST-Approved Quantum Encryption on the Linux Client appeared first on RestorePrivacy.
2024-09-25, 17:19
The European privacy rights organization noyb has filed a formal complaint against Mozilla for enabling a new feature in its Firefox browser that allegedly tracks users without their consent. The feature in question, called Privacy-Preserving Attribution (PPA), is designed to measure the effectiveness of online advertisements while minimizing data collection, but noyb claims it violates …
The post Mozilla Faces GDPR Complaint Over Firefox Tracking Users Without Consent appeared first on RestorePrivacy.
2024-09-23, 20:05
Telegram CEO Pavel Durov announced significant updates to the app’s Terms of Service and Privacy Policy, aimed at bringing the popular communications platform in alignment with the request of authorities to bring criminal activity under control. Most notably, Telegram will now share user IP addresses and phone numbers when responding to valid legal requests. Putting …
The post Telegram to Share User Data with Authorities on Legal Requests appeared first on RestorePrivacy.
2024-09-19, 18:06
The Tor Project has issued a statement in response to recent claims of a targeted de-anonymization attack on a Tor user. The attack, reportedly a “timing analysis” method, involved the long-retired Ricochet application. Although the incident raises concerns about the security of Tor’s Onion Services, the project maintains that its network remains healthy and that …
The post Tor Project Reassures Users Amid Claims of De-Anonymization Attack appeared first on RestorePrivacy.
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
9. HAVE I BEEN PWNED?by Troy HuntAccount login credential breaches
Is your e-mail address compromised? Check it on this page.
2026-06-01, 07:39
In January 2026, the automotive research and car-shopping platform Edmunds was listed by the ShinyHunters hacking group as having been breached. Data purportedly obtained in the incident was later published publicly and included 178k unique email addresses, usernames, passwords, IP addresses, phone numbers and vehicle-related records.
2026-05-30, 23:35
In May 2026, the GTA V and CS2 cheat service Atlas Menu suffered a data breach. An attacker claimed to have gained access to all Atlas systems and published the service's database to a public GitHub repository. The incident exposed 64k unique email addresses along with usernames, IP addresses, support tickets and passwords stored as bcrypt hashes.
2026-05-28, 20:00
In May 2026, the telecommunications company Charter Communications (the parent company behind the consumer broadband and cable brand Spectrum) was named by the ShinyHunters group in a "pay or leak" extortion campaign. The group later published the data, which exposed 4.9M unique email addresses along with names, phone numbers and physical addresses. A subset of approximately 85k records originating from an internal employee directory also included job titles. Charter confirmed the incident, but stated that no sensitive personal information or customer proprietary network information (CPNI) was exfiltrated.
2026-05-28, 07:22
In April 2026, the American insurance holding company Kemper Corporation was named by the ShinyHunters ransomware group in a "pay or leak" extortion campaign. The attackers allegedly accessed Kemper's Salesforce environment via social engineering as part of a broader campaign targeting hundreds of organisations using the same method. The group later published tens of gigabytes of data they claimed included internal directory data, Salesforce records and Stripe payment logs. Among the 269k unique email addresses were names, phone numbers, physical addresses and partial payment card data including the last 4 digits, expiry dates and card brands. Kemper confirmed the incident and stated they had engaged third-party cybersecurity experts and notified law enforcement.
2026-05-27, 05:17
In April 2026, the luxury fashion e-commerce platform Mytheresa was listed as a victim of the ShinyHunters "pay or leak" extortion group. After the ransom deadline passed, the group publicly released the data which contained 84k unique email addresses. The exposed data also included names, phone numbers, physical addresses, purchases and partial credit card data including card type, last 4 digits and expiry date.
2026-05-26, 22:03
In March 2026, the financial services firm Ameriprise Financial was named by the ShinyHunters group in a "pay or leak" extortion campaign. The group claimed possession of more than 200GB of compressed data exfiltrated from Ameriprise's Salesforce environment and internal SharePoint infrastructure, and subsequently published the data after negotiations allegedly failed. The published data contained 500k unique email addresses as well as names, phone numbers, physical addresses and employer information. In their disclosure to state attorneys general, Ameriprise reported 47,876 affected people; the larger email address population represents contacts from Ameriprise's broader operational systems, including internal staff. Ameriprise further advised that they have "implemented heightened monitoring of your account(s) to include enhanced identity verification procedures".
2026-05-24, 05:15
In April 2026, 7-Eleven was the victim of a "pay or leak" extortion campaign by ShinyHunters, with the data later published that month. The incident exposed 185k unique email addresses, along with names, physical addresses, dates of birth and phone numbers. A small number of records also contained additional exposed data fields. The company later advised the breach was limited to "certain 7-Eleven systems used to store franchisee documents", a statement consistent with the exposed data.
2026-05-21, 04:41
In December 2025, the European Dragonica private server Dragonica Lunaris suffered a data breach. The incident exposed 126k email addresses, usernames, dates of birth and bcrypt password hashes. The service operator confirmed the breach and advised it has since been fixed.
2026-05-21, 03:45
In January 2021, the parody site Windows93 suffered a data breach of the Myspace93 sub-site after a beta application was exploited to download server files. The compromised data was later leaked in June and included 46k Myspace93 accounts containing email and IP addresses, usernames and passwords stored in plain text.
2026-05-19, 00:28
In April 2026, data allegedly obtained from CTT, Portugal's national postal service, was posted to a public hacking forum. The data included 468k unique email addresses along with names, phone numbers and parcel tracking numbers which can be used to retrieve the tracking history of the parcel.
2026-05-18, 20:55
In March 2026, the Colombian fintech company Addi identified unauthorised activity on its platform and advised customers that "it is possible that your personal information may have been compromised". The "pay or leak" extortion group ShinyHunters subsequently claimed responsibility and published a large trove of personal data allegedly obtained from Addi. The data included 34M unique email addresses from credit scoring requests, credit bureau records, customer identity records and email validation logs. It also contained government issued IDs (Cédula de Ciudadanía), estimated income, socioeconomic levels, purchases and other credit-related data points.
2026-05-14, 03:37
In April 2026, the fintech software company Abrigo was targeted in a "pay or leak" extortion attempt by the ShinyHunters group. Shortly after, data allegedly taken from the company's Salesforce instance was published publicly and contained over 700k unique email addresses belonging to both Abrigo staff and external contacts. Whilst separate from Abrigo's Salesforce compromise via the Drift application connector the previous year, the data fields described in that incident are consistent with the ShinyHunters data, namely that it was "business contact information" including "institution name, employee name, email addresses, and phone numbers".
2026-05-13, 06:51
In April 2026, Canada Life was the victim of a "pay or leak" extortion campaign by the ShinyHunters group. The group subsequently published the data which contained over 200k unique email addresses along with names, phone numbers, physical addresses and, in some cases, customer support tickets. In their disclosure notice, Canada Life advised that "it is a small proportion of our customers who may have been impacted". In the wake of the incident, Canada Life also published an alert cautioning customers to be wary of phishing attacks, a pattern often seen after the public release of breached data.
2026-05-12, 06:58
In May 2026, the real estate services firm Cushman & Wakefield was the target of a "pay or leak" extortion campaign by the ShinyHunters group. Following the threat, the group publicly published data they alleged had been obtained from the firm, consisting mostly of C&W email addresses along with tens of thousands of external email addresses and corporate contact records. The exposed data was primarily business information, including names, job titles, company addresses and phone numbers.
2026-05-08, 07:14
In April 2026, the fashion brand Zara was among a number of organisations targeted by the ShinyHunters extortion group as part of their "pay or leak" campaign. The group claimed the breach was related to a compromise of the Anodot analytics platform and subsequently published a terabyte of data allegedly including 95M support ticket records. The data contained 197k unique email addresses alongside product SKUs, order IDs and the market the support ticket originated in. Zara's parent company Inditex advised that the incident didn't affect passwords or payment information.
2026-05-07, 06:48
In March 2026, the AI-driven merchant data platform Woflow was named as a victim by the ShinyHunters data extortion group. The group subsequently published tens of thousands of files allegedly obtained from the company, comprising more than 2TB of data. The trove included hundreds of thousands of email addresses, names, phone numbers and physical addresses, with the data indicating it related to Woflow customers and, in turn, the customers of merchants using their platform.
2026-05-06, 10:11
In April 2026, the commercial residential and ISP proxy network LegionProxy suffered a data breach. The incident exposed 10k email addresses, bcrypt password hashes, names and purchases.
2026-05-05, 02:08
In April 2026, the ShinyHunters extortion group listed Vimeo on their extortion portal as part of their "pay or leak" campaign. They subsequently published hundreds of gigabytes of data, predominantly consisting of video titles, technical data and metadata. The data also included 119k unique email addresses, sometimes accompanied by names. Vimeo attributed the exposure to a breach of Anodot, a third-party analytics vendor, and advised the incident does not include "Vimeo video content, valid user login credentials, or payment card information".
2026-05-04, 03:43
In April 2026, the gaming community Reborn Gaming suffered a data breach due to a vulnerability in cPanel and WebHost Manager (WHM). The breach exposed 126 unique email addresses along with IP addresses and Steam IDs. Reborn Gaming self-submitted the data to Have I Been Pwned.
2026-05-03, 22:53
In April 2026, the commercial real estate brokerage firm Marcus & Millichap was named as one of multiple alleged victims of the ShinyHunters hacking and extortion group. Data alleged to have been obtained from the company was subsequently released publicly and included 1.8M unique email addresses, along with names, phone numbers and employment-related information including employer, job title and physical company address. In their disclosure notice, Marcus & Millichap advised that data which may have been accessed appeared limited to "company forms, templates, marketing materials, and general contact information".
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
10. AI RESEARCHby Sophos NewsCybersecurity in AI and AI in cybersecurity
2026-03-30, 00:00
“We’ll have a generation of security professionals who can supervise AI but can’t function without it."
Categories: AI Research, Sophos Insights
Tags: AI, AI Cybersecurity, AI RESEARCH, Generative AI, SOC
2025-10-24, 06:00
Following on from our preview, here’s the full rundown on LLM salting: a novel countermeasure against LLM jailbreaks, developed by AI researchers at Sophos X-Ops
Categories: AI Research
Tags: AI, CAMLIS, Featured, jailbreak, LLM, salting, Sophos X-Ops
2025-10-21, 06:00
On October 22-24, SophosAI will present research on ‘LLM salting’ (a novel countermeasure against jailbreaks) and command line classification at CAMLIS 2025
Categories: AI Research
Tags: AI, CAMLIS, Featured, LLM, Sophos X-Ops
2025-06-30, 07:00
Analyzing dark web forums to identify key experts on e-crime
Categories: AI Research, Threat Research
Tags: AI, cybercrime, Dark Web, Featured, threat activity cluster, threat actors
2025-03-19, 06:30
Sophos X-Ops’ research, presented at Virus Bulletin 2024, uses ‘multimodal’ AI to classify spam, phishing, and unsafe web content
Categories: AI Research
Tags: Featured, Large Language Models, Multimodal AI, Sophos X-Ops, spam detection, Web Content Filtering
2024-12-13, 06:30
SophosAI’s framework for upgrading the performance of LLMs for cybersecurity tasks (or any other specific task) is now open source.
Categories: AI Research
Tags: deepspeed, Featured, LLM, LLM tuning
2024-12-10, 10:35
“LLMbotomy” research reveals how Trojans can be injected into Large Language Models, and how to disarm them.
Categories: AI Research
Tags: AI Trojans, Featured, LLM
2024-10-23, 11:02
On October 24 and 25, SophosAI presents ideas on how to use models large and small—and defend against malignant ones.
Categories: AI Research
Tags: AI Trojans, anti-phishing, CAMLIS, Featured, Google, LLM, small model machine learning
2024-10-02, 00:00
Applying generative AI, bad actors could tailor disinformation campaigns to affect election outcomes on a massive scale with relatively little effort.
Categories: AI Research
Tags: adversarial ai, Featured, Generative AI, misinformation, scampaign
2024-10-01, 12:49
Sophos' Younghoo Lee will present his research on the use of AI to analyze both text and image data to classify spam, phishing, and unsafe web content in Dublin.
Categories: AI Research
Tags: anti-phishing, Featured, Large Language Models, Multimodal AI, spam detection, Web Content Filtering
2024-03-18, 06:00
Comparative Sophos X-Ops testing not only indicates which models fare best in cybersecurity, but where cybersecurity fares best in AI
Categories: AI Research
Tags: Featured, Large Language Models
2023-11-27, 06:30
Categories: AI Research, Threat Research
Tags: adversarial ai, artificial intelligence, Featured, Generative AI, scams, Sophos X-Ops
2023-10-18, 08:42
The conference on machine learning in cybersecurity is key to open exchange of research and knowledge.
Categories: AI Research
Tags: artificial intelligence, CAMLIS, Featured, Large Language Models, scams, Web Content Filtering
2023-08-07, 07:00
AI Village talk highlights how generative can be used to automate the creation of fraud campaigns, generating hundreds of fraudulent sites.
Categories: AI Research
Tags: adversarial ai, DEF CON, Generative AI, Large Language Models, web scams
2023-06-22, 07:30
Sophos AI team employs GPT and other large language models as teachers to train smaller models to label websites.
Categories: AI Research
Tags: BERT, Featured, GPT-3, Large Language Models, Sophos X-Ops, T5 Large LLM, Web filtering, website categorization
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
11. SAFETY DETECTIVESby Safety DetectivesSafety Blog
2025-10-27, 10:48

An anonymous cybersecurity researcher discovered and reported to Safety Detectives about an unencrypted and non-password-protected database that contained approximately 7,000 records. Exposed data included names, email addresses, phone numbers, security clearance status or level, and other personal information.
The publicly exposed database was not password-protected or encrypted. It contained 7,028 records marked as “resume bank data” with potentially sensitive applicant information. In a reverse DNS search, it was identified that the IP address that hosted the documents traced back to a website called DomeWatch.us. According to information posted on House.gov by the Democratic Whip, DomeWatch is the House Democrats’ Official Online Resume Bank. On its Jobs section, DomeWatch posts current openings across Democratic Members’ offices and committees on Capitol Hill as well as related internships or fellowships. Individuals can submit their resumes using either the employment portal (which was created in November 2012) or the official mobile apps for both iOS and Android. The submissions are accessible by Senate Democratic offices.
The registration and technical contacts of the domain were promptly notified of the exposure. Public access to the database was restricted the same day, and it was no longer visible. Later on, they replied with a message that read: “Thanks for flagging”. In the About Us section of the website, it states that resumes remain in the bank for 90 days; once 3-months-old, the resume is automatically archived. However, nearly all of the records exposed were indicated with timestamps circa 2024-2025. It is unclear if this was a backup of archive data or otherwise. It is also unclear why these records appeared to have been kept for longer than the stated dates of storage.
The records indicated fields with information such as: internal ID numbers, application codes, first name, last name, phone number, email address, bio or congress experience, education, military service, security clearance and level, office interest, interest issues, home state, languages, political party affiliation, action tokens, and more. In total, the records listed 469 individuals with “top secret” federal security clearance as well as 4,221 individuals with congress experience. In regards to political affiliation, 6,300 individuals listed marked the Democratic Party; 17, the Republican Party; and 265, “Independent” or “Other”. The database also contained weblinks to Google forms and other documents.
According to the description on the Google Play Store: DomeWatch is a product of the Office of Democratic Whip Katherine Clark. It is designed to help House staff, the press, and the public better follow the latest developments from the US House of Representatives Floor. The app uses data from both majorityleader.gov and demcom.house.gov, which is the official intranet for House Democratic staff (available only within the House of Representatives firewall).





Any data exposure of a resume bank that contains potentially sensitive applicant information presents significant cybersecurity and privacy risks. When it comes to social engineering and phishing, the more personally identifiable information available, the more it may increase the potential success rate of a targeted attack. These records pose additional risks due to the fact that many of these individuals have working or volunteering experience in the government, Congress, political campaigns, or the military. Many of them also have security clearances, language skills, and political party affiliations that may potentially be of interest to malefactors.
In the current political environment, profiling and targeted harassment are notable potential risks. Another serious concern would be adversaries targeting specific individuals with privileged access to government systems, making them potentially high-value targets for espionage, recruitment, or blackmail. This isn’t an assertion that there are any national security risks to this exposure or that the data was ever at risk. These details are only here to provide hypothetical risk scenarios for educational purposes.
According to reports by AP, in July 2025, criminals used AI to create a deepfake of US Secretary of State Marco Rubio and attempted to contact foreign ministers. This raises serious potential concerns of how these individuals could be targeted for AI-assisted social engineering attempts, as many of them are currently (or have been previously) employed by members of Congress.
It is highly recommended that individuals who believe their PII or contact details may have potentially been exposed in any data breach take additional steps to validate job opportunities or suspicious communications. It is a good idea to enable MFA on email and mobile accounts that are associated with the potentially exposed data. Change passwords of affected accounts and never reuse passwords or variants of previously used passwords. For individuals with security clearance, there may be additional requirements to report the potential exposure so the incident is documented and any necessary mitigations can be applied. Strictly communicate through official channels and validate that the person or office is who they claim to be.
It is not known what internal safeguards are in place to protect congressional staff, interns, and volunteers. Hypothetically, these individuals could be potential targets because attackers might believe that their email accounts or contacts could provide policy intelligence, influence campaigns, or access government systems. It is not implied that there was ever any risk to this exposure. It is not known if the data was accessed by anyone else or how long the database was publicly exposed.
No wrongdoing by DomeWatch, or its employees, agents, contractors, affiliates, and/or related entities is implied here. It is not claimed either that any internal, applicant, or user data was ever at imminent risk. This report was published to raise public awareness and help strengthen data protection and cybersecurity practices. The hypothetical data-risk scenarios presented in this report are strictly and exclusively for educational purposes and do not reflect, suggest, or imply any actual compromise of data integrity.
The Safety Detectives’ Cybersecurity Team didn’t get access to the database, which means we could not download, retain, or share any data. This report has been shared with our team by an anonymous cybersecurity researcher. The limited number of redacted screenshots included in this article are used solely for verification and documentation purposes. We disclaim any and all liability arising from the use, interpretation, or reliance on this disclosure. We publish our findings to raise awareness of issues of data security and privacy.
Safety Detectives’ Previous Work
The Safety Detectives research lab is a pro bono service that aims to help the online community defend itself against cyber threats while educating organizations on how to protect their users’ data. The overarching purpose of our web mapping project is to help make the internet a safer place for all users.
Our previous reports have brought multiple high-profile data leaks to light, including 61 million records allegedly belonging to Verizon USA and listed for sale on a well-known hacker’s forum.
Our previous work also includes the discovery of a clear web forum post where a threat actor publicized a database with 10,000 records allegedly belonging to VirtualMacOSX.
2025-10-03, 12:19

A ransomware attack targeting Collins Aerospace’s MUSE check-in software caused widespread disruption across European airports beginning Friday, with continued delays and flight cancellations reported through the weekend.
The European Union Agency for Cybersecurity (ENISA) confirmed the incident on Monday, stating that “the type of ransomware has been identified. Law enforcement is involved to investigate.” Affected airports included London Heathrow, Brussels Zaventem, Berlin Brandenburg, and others using Collins’ automated check-in systems.
The attack disabled critical airline services, forcing airports to revert to manual boarding processes. Heathrow Airport told Reuters that “airlines across Heathrow have implemented contingencies whilst their supplier Collins Aerospace works to resolve an issue.” By Sunday, about half the airlines operating from Heathrow had restored partial access using backup systems.
The BBC obtained internal crisis memos showing Heathrow staff were instructed to continue manual check-ins while Collins rebuilt infected systems. However, the same memo warned that “more than a thousand computers may have been ‘corrupted’” and cleanup was mostly being done in person due to continued hacker presence within systems.
Brussels Airport canceled more than 130 outbound flights on Monday, while Berlin reported over an hour of delays for many departures. The Berlin Marathon worsened congestion at Brandenburg Airport, with passengers describing the experience as similar to early commercial air travel.
Collins Aerospace, a subsidiary of RTX, said on Monday it was “in the final stages of completing necessary software updates.” The company has not disclosed the exact nature of the ransomware strain, but reports suggest it may be linked to a group using the HardBit variant.
UK police have since arrested a man in his 40s in West Sussex in connection with the attack under the Computer Misuse Act. He has been released on conditional bail pending further investigation.
While ENISA and national agencies continue their inquiry, security experts like Sophos’ Rafe Pilling caution that “disruptive attacks are becoming more visible in Europe, but visibility doesn’t necessarily equal frequency.”
2025-10-03, 12:06

Cloudflare has successfully mitigated the largest distributed denial-of-service (DDoS) attack ever recorded, showcasing a concerning escalation in the scale of cyber threats.
“Cloudflare just autonomously blocked hyper-volumetric DDoS attacks twice as large as anything seen on the Internet before — peaking at 22.2 Tbps & 10.6 Bpps,” the company said in a tweet.
The previous record was an 11.5 Tbps UDP flood attack, which lasted 35 seconds. In contrast, Cloudflare’s report indicates that the latest attack lasted only about 40 seconds, which is a “hit-and-run” tactic designed to overwhelm defenses before they can respond fully.
This record-breaking incident combined multiple attack techniques in a single, massive multi-vector assault. Experts say such attacks are typically launched from enormous botnets (networks of compromised computers and IoT devices) that flood servers with traffic, rendering online services inaccessible to legitimate users.
Crucially, Cloudflare’s systems detected and blocked the attack autonomously, without any human intervention. By neutralizing the traffic at the network edge, close to its source, Cloudflare ensured that the intended targets remained fully operational.
Cloudflare’s success proves the growing importance of automated, machine learning-powered defenses, as traditional DDoS “scrubbing” centers, which are often reliant on manual traffic analysis, are ill-equipped to respond at this speed and scale.
As cybercriminals continue to refine their methods and expand their botnets, industry experts warn that hyper-volumetric DDoS attacks will likely become more frequent and more intense.
2025-10-03, 05:33

Valve has pulled the 2D platformer BlockBlasters from Steam after a malicious update enabled it to steal over $150,000 in cryptocurrency from users, including $32,000 from a Latvian streamer raising funds for cancer treatment. As reported by BleepingComputer and confirmed by malware researchers at G Data, the game was originally published on July 30, 2025, by Genesis Interactive and appeared legitimate, even earning more than 200 “Very Positive” reviews.
But a patch released on August 30 silently injected a cryptostealer, which began exfiltrating sensitive data such as crypto wallets, Steam credentials, browser extensions, and IP information from users’ machines. The campaign appears to have been targeted, with vx-underground reporting that “the Steam game was actually a cryptodrainer masquerading as a legitimate video game” and that some streamers were approached with fake promotional offers.
G Data’s analysis of the infected patch found a staged malware structure starting with a batch script named game2.bat, which checked for antivirus tools, harvested user information, and uploaded the data to a remote C2 server. Additional scripts (launch1.vbs, test.vbs) and executables (Client-built2.exe, Block1.exe) then loaded a Python-based backdoor and the StealC info-stealer. The malware added folder exclusions to Microsoft Defender and hid its actions behind the game’s launcher.
Latvian streamer Raivo Plavnieks (RastalandTV), who has stage 4 cancer, said they were infected during a live fundraiser. “For anybody wondering what is going on … my life was saved … until someone tuned in my stream and got me to download verified game on @Steam,” he posted on X.
Steam removed BlockBlasters on September 21. The incident follows a growing pattern of malware-laced games slipping past Valve’s initial screening, including Chemia and PirateFi. G Data noted that “hundreds of users are potentially affected” by the BlockBlasters campaign, which used password-protected archives and deprecated RC4 encryption to bypass detection.
As of early September, the game still had active players and was flagged as suspicious on SteamDB, reinforcing concerns about malware threats on mainstream game platforms.
2025-10-01, 15:50

Mexico’s Senate is moving forward with a new cybersecurity work agenda that could reshape the country’s digital regulation landscape. Led by the Senate’s Digital Rights Commission, the initiative seeks to develop and approve a comprehensive national cybersecurity law covering data protection, digital commerce, and online expression.
“With the Agency for Digital Transformation and Telecommunications, we discussed several topics, one of them being the organization of dialogue tables on cybersecurity to prepare the ruling on three initiatives that are in commissions for a national cybersecurity law,” said Luis Donaldo Colosio, President of the Digital Rights Commission.
The Senate aims to respond to the country’s fragmented cybersecurity framework, which currently lacks unified regulation. Existing laws criminalize certain cyber activities and mandate data protection, but oversight is split across multiple agencies. A recent legislative reshuffle has intensified the urgency, after the dissolution of Mexico’s data protection authority INAI and growing concerns about centralized power over digital governance.
According to the Digital Rights Commission, the absence of robust legislation “creates uncertainty for companies operating in the digital sector and exposes citizens to significant risks.” The new work plan includes cybersecurity training workshops during October, designated as Cybersecurity Month, as well as forums in November to update the General Law of Digital Rights.
The effort also includes a gender lens. A workshop titled “Legislating with a Gender Perspective in the Ecosystem” will be held in collaboration with Mujeres por más mujeres to help legislative teams embed equality into new digital policies.
If passed, the law would establish safeguards across digital platforms, social networks, and e-commerce tools, with a specific emphasis on protecting minors. The framework would also address the intersection of cybersecurity and free speech, a point that has drawn scrutiny in previous legislative proposals.
The final objective, Colosio noted, is to “establish a safer, more predictable, and equitable digital environment for all stakeholders.”
2025-09-27, 14:11

The Central Bank of Kenya (CBK) has launched the Banking Sector Cybersecurity Operations Centre (BS-SOC), a centralized facility aimed at improving cyber resilience across the country’s financial system.
Hosted within the CBK’s Cyber Fusion Unit, the BS-SOC will provide cyber threat intelligence, incident response, digital forensics, and cyber investigations. According to CBK, the centre is “a key part of the implementation of the Computer Misuse and Cybercrime (Critical Information Infrastructure and Cybercrime Management) Regulations, 2024” and aligns with the CBK Strategic Plan 2024–2027.
The launch comes amid a sharp rise in cyberattacks. Kenya’s Communications Authority reported 4.5 billion cyber threat events between April and June 2025, up 80.7% from the previous quarter. CBK’s own stress tests in May modeled a 5% chance of successful cyberattacks, with potential losses ranging from KSh 32.8 million to KSh 2.9 billion depending on severity.
CBK said it is working to harmonize the Commercial Banks Cybersecurity Guidelines (2017) and the Payment Service Providers Cybersecurity Guidelines (2019) with the 2024 regulations. In the meantime, regulated institutions are expected to comply with all three and report incidents to the BS-SOC within the stipulated timelines.
“The successful implementation of this initiative requires the full collaboration and cooperation of all stakeholders,” the CBK noted in its official statement. Governor Kamau Thugge added that “cyber threats continue to evolve. A sector-wide response is essential to protect Kenya’s financial system.”
Data from CBK also shows that cybercriminals siphoned KSh 1.59 billion from customer accounts in 2024, further underscoring the need for coordinated monitoring and response.
By integrating enforcement and threat response under one roof, CBK hopes to reduce fragmentation and give regulators better visibility into systemic cyber risks affecting banks and payment providers across Kenya.
2025-09-25, 08:51

The City of Yellowknife says its network has been safely restored following a cybersecurity incident that disrupted services for over a week.
The attack, first disclosed on September 15, forced the city to limit internal access and temporarily disable online services. Debit and credit card payments were suspended, library computers were offline, and patrons were restricted to borrowing five items at a time. As of Monday, most systems have returned to normal.
Public safety and critical infrastructure continued to operate throughout. “The city enacted its incident response protocols to contain the incident, including the implementation of additional measures to further enhance its network security,” officials said in a statement cited by NNSL.
Click and Fix YK, the city’s issue-reporting portal, remains offline, as does CityExplorer, its interactive mapping tool. Residents are being asked to email non-emergency issues while restoration continues.
There is no evidence of data loss so far. “To date, we have no evidence that any personal information was compromised in the incident,” the city confirmed. “In the event our investigation determines that personal information was compromised, we will contact those individuals directly.”
City Manager Stephen Van Dine told Cabin Radio the network breach was being handled carefully, saying, “We believe it is under control at this stage… we’re certainly more confident than we were 48 hours ago.” He noted there was no ransom demand and declined to label the event a confirmed cyberattack, only that “there was some kind of activity to get into our systems that shouldn’t be there.”
Third-party experts continue to assist with the investigation, and the city has promised a thorough post-incident review to evaluate the timeline, impacts, and potential long-term upgrades to network defenses.
2025-09-25, 08:26

SonicWall has disclosed a security incident involving its MySonicWall cloud backup service, confirming that threat actors gained access to a subset of firewall configuration files. The company said that fewer than 5% of its firewall install base was affected, but acknowledged the potential severity of the breach.
The attack involved a series of brute force attempts targeting the MySonicWall.com portal, allowing unauthorized access to firewall preference files stored in cloud backups. While credentials within the files were encrypted, SonicWall warned that “the files also included information that could make it easier for attackers to potentially exploit the related firewall.”
Security researchers noted that these configuration files often contain DNS, log, and user/group settings — sensitive data that could be leveraged in future attacks. As Arctic Wolf researchers pointed out, “nation-state hackers and ransomware groups previously have exploited such information to conduct subsequent attacks.”
SonicWall emphasized that this was not a ransomware event, stating it was “a series of brute force attacks aimed at gaining access to the preference files stored in backup.” The company has terminated the unauthorized backup point and is working with cybersecurity partners and law enforcement to assess the full scope of the breach.
The Cybersecurity and Infrastructure Security Agency (CISA) also issued an alert urging immediate action. “Customers with at-risk devices should implement the advisory’s containment and remediation guidance immediately,” the agency said.
SonicWall has published detailed guidance for users to determine if their firewall devices are affected. Impacted customers are advised to log in to their MySonicWall accounts, check for flagged serial numbers under the Product Management section, and follow the remediation steps, including credential resets and service reviews.
At present, there is no indication that the compromised files have been leaked online. However, the company stated that it will continue to monitor the situation and release further updates as necessary.
2025-09-23, 16:22

OpenAI is preparing stricter safety features for ChatGPT as it faces mounting lawsuits and scrutiny over teen protection. CEO Sam Altman confirmed the company will soon require users to verify their age if it suspects a user is under 18, saying the changes are meant to “prioritize safety ahead of privacy and freedom for teens.”
“When you log in to ChatGPT, a banner will appear asking you to verify your age,” the company explained. “You will have 60 days to complete this process, after which your access to ChatGPT will be blocked until you successfully complete the age verification process.”
OpenAI will rely on third-party service Yoti to perform the checks. “You will be asked to enter the necessary details to confirm your age,” the post continued. “Depending on the method you choose, you may be asked to take a selfie, upload a valid ID, or use the Yoti app. Once your age is verified, you will be redirected to ChatGPT and can continue using the service as usual.”
The system will automatically place under-18 users into a restricted version of ChatGPT, which blocks sexual content and adds safeguards. Parents will soon be able to link accounts to monitor chats, disable history, enforce blackout hours, and receive alerts if the AI detects signs of acute distress. OpenAI noted that in some cases, “we may involve law enforcement as a next step.”
The rollout comes as lawmakers question whether AI can reliably predict age. Researchers warn that language-based cues are easily manipulated, while recent lawsuits accuse ChatGPT of failing to prevent harm in long sessions with vulnerable teens.
Despite concerns about privacy trade-offs, Altman stood by the decision. “Not everyone will agree with how we are resolving that conflict,” he said, “but we believe it is a worthy tradeoff.”
2025-09-23, 15:54

CrowdStrike and Meta have jointly released CyberSOCEval, a new open-source benchmark suite designed to evaluate how large language models (LLMs) perform across critical security operations center (SOC) tasks like malware analysis, incident response, and threat detection.
Built on Meta’s CyberSecEval framework and integrated with CrowdStrike’s threat intelligence, the tool aims to give organizations a standardized way to test the effectiveness of AI models under real-world attack conditions. The benchmark suite, now available on GitHub, includes documentation, sample datasets, and guidance for integrating the tests into existing SOC environments.
The rise of AI in cybersecurity has made it harder for teams to choose the right tools. Many security products now claim AI capabilities, but without clear benchmarks, it’s been difficult to assess which models deliver real-world value. CyberSOCEval addresses this by simulating adversarial tactics and complex security scenarios, allowing teams to validate LLM performance before deployment.
Vincent Gonguet, Director of Product, GenAI at Superintelligence Labs at Meta, said the collaboration “introduces a new open source benchmark suite to evaluate the capabilities of LLMs in real world security scenarios. With these benchmarks in place, and open for the security and AI community to further improve, we can more quickly work as an industry to unlock the potential of AI in protecting against advanced attacks.”
Daniel Bernard, Chief Business Officer at CrowdStrike, added that “when two leaders like CrowdStrike and Meta come together, it’s larger than collaboration, it’s about setting the direction of cybersecurity for the AI era,” emphasizing the benchmark’s role in helping security teams adopt AI with confidence.
The companies hope CyberSOCEval will support both enterprise users and AI developers. Businesses get a transparent framework for comparison, while developers gain feedback on how their models handle realistic security workflows, including complex reasoning and industry-specific language.
ALL RSS FEEDS
