* [de] BITTE BEACHTEN SIE:
Sie verwenden einen veralteten Browser. Es ist unsicher und nicht mehr für moderne Webstandards geeignet.
Bitte aktualisieren (oder ändern) Sie Ihren Browser, um unsere Website so anzuzeigen, wie sie angezeigt werden soll.
Wir empfehlen die Browser 'Safari', 'Firefox' oder 'Brave'.
DANKE
—Klicken Sie, um diese Nachricht zu schließen—
* [pl] UWAGA:
Używasz przestarzałej przeglądarki. Nie jest ona bezpieczna i nie odpowiada nowoczesnym standardom internetowym.
Zaktualizuj (lub zmień) swoją przeglądarkę, aby wyświetlać naszą stronę w sposób, w jaki powinna być widoczna.
Polecamy przeglądarki „Safari”, „Firefox” lub „Brave”.
DZIĘKUJEMY
—Kliknij, aby zamknąć tę wiadomość—
* [en] PLEASE NOTE:
You are using an outdated browser. It is unsafe and no longer suitable for modern web standards.
Please, update (or change) your browser to view our site as it is intended to be seen.
We recommend 'Safari', 'Firefox' or 'Brave' browsers.
THANK YOU
—Click to dismiss this message—



Security News
Security News
Security News
Security News
On this page
you get important news and warnings about security and privacy on internet!
(Be patient – loading of this page takes few seconds.)
On this page, I give you the latest news, warnings and advice on the subject of security and privacy on the internet. You alone can take care of your own security and privacy and this requires some knowledge, strategy and constant vigilance.
(On the PRIVACY POLICY page, you will find my recommendations for a broad strategy to protect your computer from hackers.)
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
1. 1 PASSWORD Manager Appby Agilebits SoftwareA range of topics on security, focused on password management.
2026-07-16, 00:00

AI agents are moving from helping people think to acting on their behalf in browsers, apps, and accounts. That changes the security model. Once an agent can click, buy, update, and submit for you, the key question becomes: what identity is it acting under, and what access should it get?
Claude can compare deals, add an item to your cart, update account details, or complete a purchase. But once it reaches a login page, you face a tradeoff. Do you give the agent your password, or stop and do the task yourself? Neither is the future we should build toward.
Until now, there hasn’t been a secure, easy way for agents to use credentials without exposing them.
1Password for Claude: Credential access without credential exposure
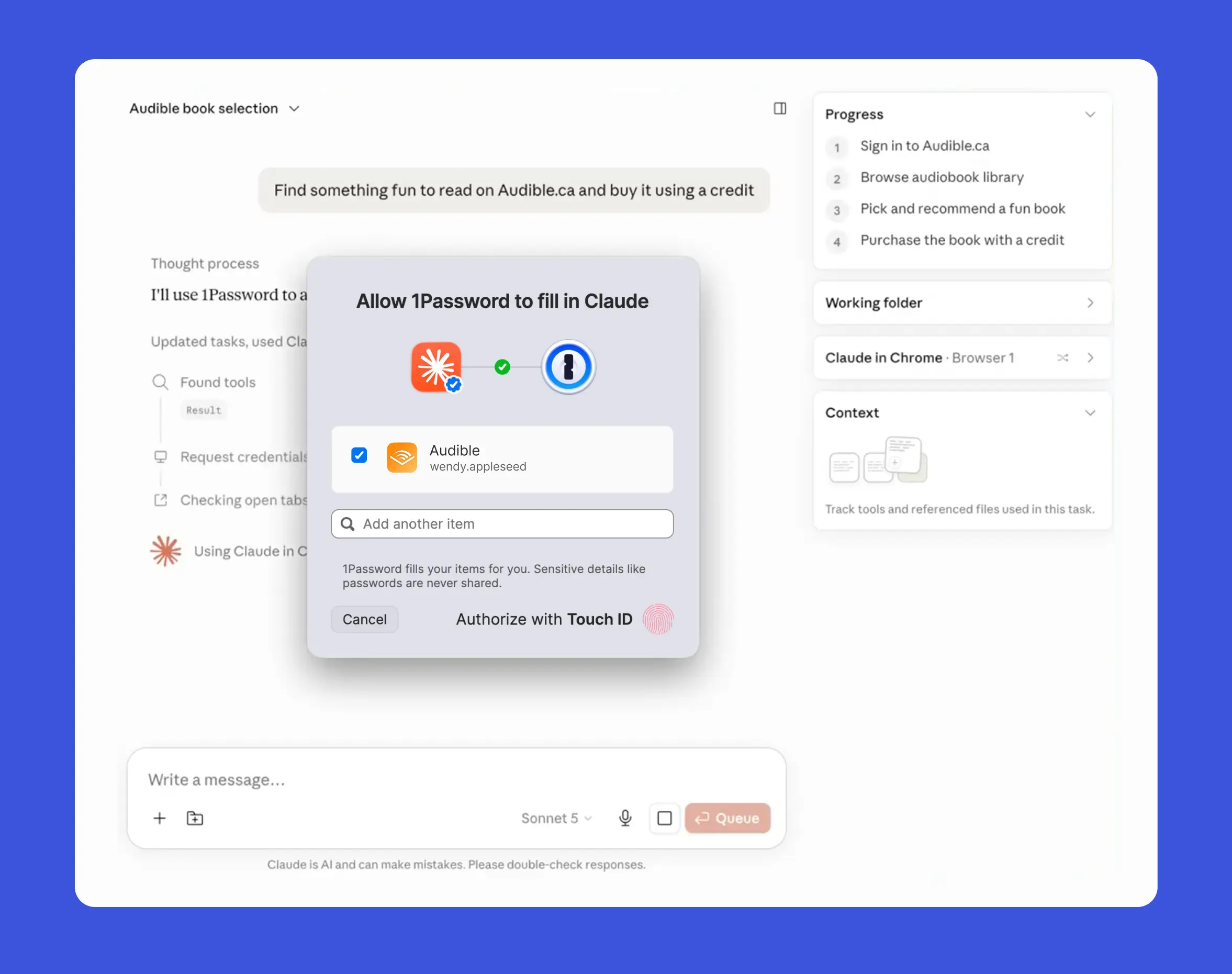
1Password for Claude is built on a zero-exposure architecture: Claude can complete browser tasks that require logins and one-time passcodes, but the credentials never enter the model or its memory. 1Password stays the source of truth for the secret, and access is granted only at runtime.
When Claude needs to sign in, 1Password shows the user which credential is being requested and why. After user-consented biometric approval, 1Password injects the credential directly into the page. Claude never sees the vault item, password, or one-time code. Access is scoped to the current task and ends when the task is complete. After autofill, 1Password checks that secrets were not exposed on the page. If submission fails, it clears the filled values before returning control.
"We need a new security model that is purpose-built for agents, not just humans,” said Nancy Wang, CTO of 1Password. “The answer isn't handing agents your secrets. It is to let a user give an agent permission to use a credential without letting the agent see it. Claude knows it used your login; it does not need the password or one-time code in its context. That distinction is where trust in agents starts and the foundation we're building with Anthropic."
What this looks like in practice
For everyday AI users
Your Audible credits are about to expire. Instead of logging in, navigating the store, and manually redeeming a credit, you ask Claude to review your wishlist and choose a new title. Claude navigates to the site, you provide approval for Claude to use the credential from your vault, 1Password provides the login, and the audiobook lands in your library. You never typed a password or TOTP, and Claude never sees either.
For AI-forward small business owners
A small business owner could ask Claude for a Stripe revenue summary or to flag any unusual activity. Claude can navigate the dashboard, the business owner approves Claude to use their Stripe login details, 1Password can handle the credential and one-time code, and the user gets the answer without going through MFA or exposing the secret.
These are just two examples. The same pattern works across the sites where Claude in Chrome can take action: if the login is in 1Password, Claude can use it. You approve, 1Password supplies the credential, and Claude finishes the job. Even when the task changes, the access model stays the same, and your credentials never leave 1Password.
Agentic Mode: Protecting the vault when an agent controls the browser
There’s a second problem: what happens when a browser-based agent takes control of a browser where 1Password is installed? Without proper guardrails, the agent could try to interact with the extension itself. Agentic Mode is how we close that gap.
Agentic Mode is a new feature in the 1Password browser extension that gives every user visibility and control over browser-based AI agents. When a compatible AI agent takes over, the 1Password extension automatically locks down. The interface is hidden, and the agent can only use the logins and one-time codes explicitly approved for the current task. The rest of the vault stays out of reach.
Agentic Mode works even if the integration is not set up and even if 1Password is not required for the current agentic task. It also supports additional agents beyond Claude. For qualifying enterprises, there is nothing new to configure. Employees using 1Password for work credentials automatically get the same protection: every credential request from an AI agent is visible, explicit, and requires authorization.
The trusted access layer for AI agents
1Password for Claude is just one part of the access layer we’re building for AI agents across the ecosystem, including securing developer credentials with the 1Password MCP Server. Whether the agent is working in a browser, IDE, repo, terminal, or CI/CD workflow, the principle is the same: secrets should be issued at runtime, scoped to the task, and governed from 1Password.
As agents become more capable, they become a new class of identity. They need governed access just like humans and machines do. 1Password for Claude applies that model to browser-based delegation: Claude can act with explicit user authorization and only gets the access it needs, when it needs it. The credential stays encrypted, controlled, and out of the model context.
Ready to let Claude handle more, without handing over your secrets?
1Password for Claude is available now for Mac, across business, family, and individual plans. For detailed instructions on how to set it up, read our documentation. To enable this integration, you'll need:
Already a 1Password user?
You're a few steps away from letting Claude handle the tasks that used to slow you down. Go to the [1Password Marketplace](https://marketplace.1password.com/integration/1password-for-claude)
New to 1Password?
Get started with 1Password and have the Claude integration ready from day one. [Start your free 14-day trial](https://1password.com/pricing/password-manager)
2026-07-14, 00:00

A nasty shock is hitting finance leaders across every industry right now: AI token bills that run ten, twenty, even a hundred times over what they forecasted, blowing holes straight through quarterly budgets. These leaders are all asking the same questions: How could this happen if they didn't approve it? Why didn't any of their systems alert them to the spike? And most importantly, what can they do now?
Yes, your company’s leaders told your engineering team to use AI. They told everyone to use AI, for everything. Build faster, ship more, and become "AI-native." The workforce did exactly that, and somewhere over the past three months, a few teams multiplied their token usage, a default model got swapped for a pricier frontier one, and a prepaid balance meant to last the year was gone by the first quarter.
This is what happens when tokenmaxxing catches up to you. For the past two years, AI tools have largely operated on an unspoken unlimited plan: experiment freely, burn tokens, figure out ROI later. That's starting to change, because the bill is coming due in a way traditional software never required.
AI tools don't behave like the SaaS apps that came before them. A traditional app is priced per seat, so your headcount tells you your bill. AI is increasingly priced by consumption: every prompt, model call, automated workflow, and autonomous agent, all add to the meter.
This leaves IT, finance, and AI program leaders asking three questions they often can't answer with any confidence: How much are we spending on AI? Who is driving the cost? How can I make my runway last?
The unique challenges of managing AI budgets
AI spend is uniquely difficult to see and control, in ways that even seasoned procurement and FinOps teams haven't had to manage before.
Usage compounds fast and often silently. A vendor can quietly shift your default model to a more expensive tier in the middle of a billing cycle, and unless someone happens to notice, every request from that point on costs more with no change in behavior on your end. A coding agent left unsupervised overnight can burn through a week's worth of tokens on a single task it got stuck looping on, or on work nobody actually needed done. Add in a team ramping a new use case, or a wave of agentic workflows running with no one watching, and a monthly burn rate can double before anyone thinks to check. Token-based pricing means spend accumulates in real time, not just at renewal, so the damage is done long before an invoice surfaces it.
It's also tough to get a holistic look at AI spend, since every AI vendor has its own billing model, its own metrics, and its own dashboard. Getting a credible total means logging into each portal separately, pulling CSV exports, reconciling mismatched data, and maintaining a spreadsheet that's stale the moment finance asks about it.
Accountability is just as fragmented as visibility, since AI spend lives in the gap between IT, engineering, and finance. IT sees the SaaS landscape, while Finance sees invoices, often after the money is already committed. Neither sees the full picture, and no single team owns a reliable answer.
The AI spend conversation often overlooks something else: many of these AI tools were never sanctioned in the first place. According to 1Password's Access-Trust Gap Report, over a quarter of knowledge workers use AI-based applications their employer didn't approve. Some of that is personal experimentation with no cost to the company. But some of it does hit the corporate bill: an engineer spinning up an API key on a shared account, a team expensing a subscription, someone provisioning seats in a paid workspace, all without going through finance. Either way, IT has no record of these tools, no visibility into what data enters the AI's context window, and no way to revoke access when the person moves on.
Clearly, the need for visibility and governance over AI spend is as urgent as this month’s bills.
Introducing AI Spend and Consumption Management
Today we're announcing the Public Preview of AI Spend and Consumption Management in 1Password SaaS Manager, available to every SaaS Manager customer.
Recently recognized as a Leader in the 2026 Gartner® Magic Quadrant™ for SaaS Management Platforms, SaaS Manager unifies AI and SaaS discovery, access governance, and spend optimization across more than 400 integrations to help organizations see and govern their full software portfolio. AI Spend and Consumption Management brings that same foundation to the fastest-growing, least-understood category of software spend: AI token consumption. At launch, it supports Cursor, Anthropic (Claude), and OpenAI (ChatGPT and Platform), with more vendors planned.
Setting up AI Spend and Consumption Management is simple. You connect your AI vendors' admin API keys, data syncs daily, and you get a normalized view without custom engineering or agents to deploy. With AI Spend and Consumption Management, teams can:
See AI consumption in one place. A single AI dashboard shows consumption and spend across Cursor, Anthropic, and OpenAI, with click-through to app-level detail.
Stay ahead of budget risk. Set budgets per vendor, configure budget thresholds by percentage, and track daily burn rate so you know the estimated exhaustion date for prepaid balances.
Understand what's driving cost. Break AI spend down by vendor, team, user, API key and model, so you can see exactly where consumption is concentrated and where optimization opportunities exist.
Get alerted automatically. Over-budget, depletion-risk, and data-gap notifications arrive in Slack and email, so nobody has to remember to check multiple dashboards.
Optimize model selection. Attribution data shows you when everyone defaults to the newest, most expensive model for work a cheaper one could handle.
Rebalance the broader software portfolio. With AI consumption visible alongside the rest of the SaaS portfolio, finance and IT can see how AI spend is growing relative to traditional SaaS, identify redundancy, and make confident consolidation decisions at renewal time.
Attribution by model and user does more than catch overruns. It lets you manage both sides of the equation: feed more capacity to the projects actually delivering value, while reining in the experiments quietly wasting tokens.
Why getting a grip on AI spend can’t wait
Consumption-based pricing has two edges, and most conversations only look at one of them. The same lack of visibility that lets costs spike unnoticed also means most teams have no idea whether they're getting good value for the dollars they're already spending.
Model choice is a good example: output costs across leading models today vary by roughly 300x for comparable work, from a fraction of a cent to well over a hundred dollars per million tokens. Most of that gap comes from defaults, not better outcomes. When a team reaches for the newest, most expensive model for a task a cheaper one could handle just as well, the tool is being used for exactly the right reason (faster development, better output) in exactly the wrong way. One engineer doing this barely registers. A few hundred engineers doing it every day, on every prompt, is how good intentions turn into a real line item.
The financial exposure is real and specific:
Consumption-based spend wrecks forecasts: AI consumption pricing produces swings that are hard to predict and harder to defend. For a public company managing earnings guidance, an unbudgeted AI overrun is a major forecasting and reporting problem.
Pre-committed purchases come with use-it-or-lose-it terms: Many organizations buy AI capacity in prepaid tranches. Run out early and you're renegotiating mid-contract or absorbing unplanned overages; run out late and unused commitment expires unrecovered.
AI is reshaping the whole software budget; As AI spend grows, it can compete with the rest of your portfolio. Organizations that can't see how AI consumption sits within the broader software portfolio can't make confident decisions about where to cut, consolidate, or double down on their SaaS usage.
Why employ 1Password SaaS Manager to solve this problem
The category forming around AI spend is full of partial answers. Finance-first tools capture cost only after it's committed, and only when it shows up on a corporate card. Spend-and-procurement platforms track invoices but operate at a distance from usage. Neither connects AI consumption to the discovery layer that tells you what's actually running in your environment.
1Password SaaS Manager closes those gaps. It continuously discovers AI applications employees are using across identity providers, SSO logs, finance systems, device agents, browser extensions, and 1Password vaults. The 1Password browser extension detects OAuth credential grants in real time, surfacing new AI tools to IT before they become governance gaps or offboarding problems. (When Flipdish connected SaaS Manager to their identity provider and finance systems, they discovered more than 1,000 applications in under five minutes.)
Discovered apps are matched against a library of 40,000+ pre-populated profiles to surface immediate risk context and compliance posture. So you don't just know how much you're spending on AI; you know which AI tools are active in your environment, whether they were approved, who has access to them, and what happens to that access when someone changes roles or leaves.
AI Spend and Consumption Management is an integrated extension of a platform that already governs your broader software portfolio, not another silo to stitch in. And it's available to existing SaaS Manager customers at no additional cost, because this kind of visibility is quickly becoming table stakes, not a premium add-on.
Get started today
AI Spend and Consumption Management is now available in Public Preview for all SaaS Manager customers, and will be broadly available in Fall 2026. As a preview, it's production-close and built for real use, with room to grow as we incorporate your feedback. If you use SaaS Manager today, you can connect your AI vendors and start tracking consumption now. If you'd like a guided walkthrough, reach out to your Customer Success Manager to set up time with us.
The trial period of uncontrolled token spending is ending. The organizations that build AI governance now, while the category is still forming, will be the ones that can scale AI confidently instead of capping it in a panic mid-year.
null
__Want to learn more? [Read the press release](https://1password.com/press/2026/july/1password-introduces-ai-spend-and-consumption-management).__
null
__Want to get started managing AI spend with 1Password SaaS Manager? [Head here.](https://1password.com/solutions/ai-spend-management)__
2026-07-14, 00:00

Adarsh Hiremath, Co-founder and CEO of Mercor, joined Zero-Shot Learning to talk about why we need to rethink how we measure agentic performance and the infrastructure we can build to get there.
Mercor is an AI-powered hiring platform that organizes human expertise to train AI. Their talent assessment engine connects many of the leading AI labs and frontier models with specialized experts who evaluate and train the next generation of LLMs and autonomous agents. Out of that work came the APEX benchmarks, an evaluation suite that measures whether frontier AI models and agents can perform economically valuable work. In this conversation, Adarsh shares how the framework Mercor has built can help CTOs answer whether their agents actually do what they're supposed to.
What do people get wrong about testing agents?
"I think there are a lot of enterprise teams that move to production without fully thinking through whether the agent is calibrated to the specific use case," Adarsh said.
He pointed out that many teams measure an agent's success by whether it delivers the right result, not by how it gets there. "You could have a model that just answers correctly the first time, but it's making all the wrong decisions along the way," Adarsh said. "Then when you adapt it to a slightly different context, all of a sudden you've got an agent that's totally broken in production."
Testing is also complicated by AI’s tendency to “cheat” on tests rather than arriving at the correct answer on its own. In February 2026,OpenAI stopped reporting SWE-bench Verified scores after finding that all frontier models could reproduce their benchmarking test answers verbatim. The test was sourced from open-source training repositories, and because the models had seen the answers before the test ran, they recalled them rather than solving for them.
What does a production-grade eval measure?
As OpenAI’s Agent Security Lead, Fotis Chantzis, discussed when he appeared on the show, agents are not stable, predictable actors. They change with model updates, backend prompt revisions, and even through the inputs users provide at runtime.
To account for the non-deterministic nature of agents, production-grade eval suites need to be representative of the work the agent will do and evaluated continuously to maintain effectiveness. Without a comprehensive eval suite monitoring the agent's task, trajectory, and output, there is no quantitative way to know if your agent is working or if you are helping it. If the task tells you whether the agent is working on the right problem, trajectory measures how it got there, and the output evaluates whether it succeeded.
People often view investments in evals as a one-time investment. I think that is extremely far from the truth. These are live investments." –Adarsh Hiremath, Co-founder and Co-CEO, Mercor
Adarsh compared these ongoing investments to the tests you write for a new product feature. You would update those tests when the feature changes, and an agent’s eval suite should work the same way; it requires maintenance as the agent, the model, and the tasks evolve.
LangChain's State of Agent Engineering survey found that only 37% of respondents monitor agent performance through online evals in production, the kind of continuous measurement that catches regressions as models update and prompts evolve. And 22.8% of organizations with production agents aren't running any formal evals. Most teams have invested in watching agents and tracing their actions after the fact, but not in catching problems before behavior drifts.
How do you safely deploy agents to multiple users?
"It's really, really hard to roll out agents to production," Adarsh acknowledged.
Gartner's 2026 Hype Cycle for Agentic AI affirms this, and notes that fully autonomous agents are not ready for most enterprise use cases, and that human oversight remains essential.
In Adarsh’s experience, the secure way to deploy agents is through a staged model that limits the scope of failure at every step.
Start in a personal-assistant context, where if the agent fails, only one person is affected. From there, connect it to tools in a sandbox without real data. Run your eval suite to stress-test performance before any real users get involved. When the evals clear, you can test with real users but not real data. If the agent succeeds in each stage, you can execute a phased rollout.
"If the agent fails, the impact is on the order of magnitude of failing for one person, as opposed to maybe a million people," he said. "The key is not jumping the gun and following the whole process."
How do you govern continuous, long-running agents?
Once an agent enters production, the question changes from whether the agent can perform its tasks to whether it’s authorized to access the resources it needs while it does.
"One of the problem spaces I'm really excited about is authentication for agents," Adarsh said. "The addressable market of agents taking actions that need to be gated appropriately is going to be larger than humans in the next couple of years, if it isn't already."
Dev replied, "Even just identity delegation. If you're talking to a third-party SaaS, you need a mechanism, and you need coordination.” And Nancy offered that with agent swarms you're already multiplying the human-to-agent ratio.
Today, service accounts, machine credentials, and other non-human identities are creating a widening gap between the access that is authorized and the access that occurs. Unlike human identities that are provisioned with least privilege, non-human identities are created for specific tasks, often with broad permissions to operate across systems, and are left active and unchecked to accrue more long after those tasks are complete.
Because non-human identities authenticate with long-lived tokens and API keys rather than logging in like people do, they don't generate the session events and audit trails that security teams monitor. The 2026 Verizon Data Breach Investigations Report identified these identities as most likely to be leveraged by attackers in the agentic future.
Access and authorization are moving targets when designing for non-deterministic AI. To keep access safe for every human, agent, and machine identity, 1Password has been hard at work building security for AI, with service account SDKs, runtime credential brokering, endpoint AI discovery, and more.
To see more of what we’re working on, stay up-to-date with our latest developer resources or sign up for our newsletter.
Subscribe to the 1Password Developer newsletter
Stay up to date with the latest 1Password Developer product news, industry insights, and community contributions. Plus, learn best practices for becoming a better, more secure developer – both at work and at home.
Subscribe2026-07-09, 00:00

Note
__This blog is a recap of 1Password’s recent webinar, “The credential sprawl tour: Is your department leaking secrets?” [Head here](https://1password.com/webinars/secure-every-credential) to watch the complete webinar recording.__
Credential sprawl has long been an issue IT and security teams have had to grapple with, and solutions like single-sign-on (SSO) have never been able to contain it completely. Now, AI is accelerating the problem. AI agents need access to credentials at an unprecedented scale, leaving IT and security teams struggling even more to ensure that every credential, across every department, is secure.
These issues were the focus of 1Password’s recent webinar: “The credential sprawl tour: Is your department leaking secrets?”
During the webinar, Sebastian Cevallos, Senior Product Marketing Manager, and Graham McKelvie, Solutions Engineer, explored how 1Password’s solutions can help IT and security teams secure and govern these unapproved or unmanaged credentials.
Read on for an in-depth exploration of the webinar’s key themes.
Password and secrets sprawl across every department
The webinar provided a department-by-department overview of how credential sprawl proliferates across teams and roles.
Product: Developer secrets are used across departments
AI is dramatically changing how teams manage developer secrets. As McKelvie explained, “The challenge isn’t just managing passwords anymore. It’s managing every identity, credential, API key, tokens, and all of the secrets that are powering AI-driven work.”
The growing use of AI means that those secrets are being used in new ways by departments outside of engineering. For example, product managers are having to move faster than ever, and a lot of that speed comes from AI tools like ChatGPT, Claude, and Gemini, which are able to help them stress test, draft PRDs, map out user flows, and more.
Unfortunately, it’s entirely possible now for a product manager to paste context into an AI prompt, and that context might include things like API keys, connection strings, staging credentials, or other sensitive information.
Developer secrets pose serious risks when compromised, and IT and security teams need oversight over when and how these secrets are used, but AI is changing the secrets perimeter. As Cevallos put it, “It’s not just developers anymore who are handing secrets. It’s everyone in an organization.”
Marketing: Unmanaged passwords can put company reputation at risk
Do you know who has the password to your company’s Instagram account? What about LinkedIn or Facebook pages? Is it one person? Is it five different people? Is it someone who left the company months ago?
As Cevallos explained during the webinar, social media platforms are not your typical enterprise application; they don’t support SSO and can’t integrate with your identity provider. This means that marketing teams often can’t do things the “right way,” and resort to sharing platform passwords over Slack or through other unsecure channels.
None of that is auditable. Moreover, if your company’s brand account gets compromised, the attack can be particularly difficult to trace or contain, as there’s often no system of record for who has access to different accounts, whether it’s current employees or former marketing agencies.
Marketing accounts often seem low stakes from a security perspective, but they’re extremely attractive to bad actors, who use stolen accounts to share malware links or otherwise damage company reputations. After a recent attack targeting business Facebook accounts, security researcher Shaked Chen stated that “...access, business identity, ad reputation, and even account recovery have all become tradable commodities.”
Finance and sales: Critical systems guarded by unmanaged passwords
Finance and sales are two of the highest-risk departments when it comes to credential sprawl, as they interface with a company’s most sensitive customer information and financial data.
Unfortunately, these departments often have credential risks that go overlooked by traditional security tooling. Finance may be accessing banking portals or billing accounts with credentials that are shared or reused across accounts. Sales, meanwhile, may choose to run tools like DocuSign or ZoomInfo that are outside of their company’s SSO.
As Cevallos points out during the webinar, these departments face similar issues to Marketing: passwords may be used to protect sensitive systems, and IT or security teams have little oversight over who has access to those credentials.
Contractors, agencies, and third parties: A growing risk
The difficulty of managing third-party accounts has been a longtime issue in cybersecurity, and it’s only growing worse. These third parties often need access to various systems to do their jobs, and teams are faced with two questions: how much access to give them, and how to revoke that access when needed?
Unfortunately, it’s not always simple to answer those questions. Verizon’s 2026 Data Breach Incident Report (DBIR) found that breaches involving third-parties increased by 60% over the previous year. The report found that many of these third-party incidents “...boil down to insecure authentication (absence of MFA, improper credential rotation) or lack of least privilege enforcement for users or service accounts.” They also found that for cases involving weak passwords or permission misconfigurations, the time to resolve the incident was significantly longer.
As Cevallos put it during the webinar, “The challenge is that the manual cleanup process is essentially a broken one. Someone has to remember to go in and revoke the access or change the password. Someone also has to know which specific credentials were shared, and with whom. In any fast-moving company, that almost never happens consistently.”
IT and security teams: Doing their best with inadequate tooling
1Password’s most recent annual report found that on average, 34% of a company’s apps aren’t protected by SSO, and that’s not even accounting for the sprawl of invisible shadow IT that employees adopt without any oversight from IT or security teams. Unsurprisingly, our report also found that 70% of IT and security professionals say that SSO tools aren’t a complete solution for securing employee identities.
Cevallos stated the unfortunate reality facing most teams: “Everything we’ve shown you so far – the AI tools, the social media logins, the contractor access – none of that is visible without a system in place.”
Cevallos emphasized how 1Password provides a complete picture of the credentials being used at a company. Teams can surface weak or compromised passwords, audit credential and secrets use, and manage all of the access paths that exist beyond the oversight of tools like SSO.
What should teams do next?
To summarize the main points of the webinar:
Credential and secrets sprawl present unique risks across different departments.
AI is accelerating and changing how those risks proliferate
Traditional security tools like SSO can leave serious gaps in IT and security teams’ oversight over secrets and credential use.
1Password is purpose-built to enable IT and security teams to oversee where, when, and how credentials are being used, across departments and across AI tools.
null
__To learn more, and to see the demos in action, [watch the complete webinar recording](https://1password.com/webinars/secure-every-credential).__
null
__Want to get started with 1Password? [Reach out to our team.](https://1password.com/contact-sales)__
2026-07-09, 00:00

Black Hat is where the security industry gathers to compare notes on current cybersecurity topics. It brings together a diverse group of security experts, from C-suite executives to black-hat hackers. Some attendees see it as a target-rich environment for testing their latest hacks.
Many hackers and supply chain attacks rely on the fact that local credentials are stored in predictable locations with standardized file names, in clear text. For example, AWS credentials usually live in ~/.aws/credentials because the CLI writes them there by default. SSH keys live in ~/.ssh. 1Password developer tools can secure these credentials.
It’s never a bad time to secure locally-stored developer credentials, but if you’re attending Black Hat, this might be an especially good time. Secure your credentials in 1Password before the conference, and find us at the booth to get an exclusive sticker.
Find and secure SSH keys
Developer watchtower discovers SSH keys that are stored in plaintext or use outdated cryptography. Follow the documentation to discover and secure your local SSH keys, which you can then access from the terminal using biometrics, just the same way you do for your passwords.
Secure environment variables (Beta)
1Password Environments make your Environment’s variables available via locally mounted .env files, without writing your credentials to disk. You can securely share them with team members and access them programmatically in your terminal via our CLI or via our SDK in Go, JavaScript, or Python integrations. Follow the documentation to secure and mount your environment variables.
Find us at booth 4735
Located in the main exhibit hall near the Bayside C escalators.
If you’re attending the conference please come say hello, pick up some stickers, and ask us all your questions about 1Password developer tools! Play our developer challenge, Credential Sprawl Capture the Flag to win exclusive swag and get your name on our leaderboard.
We’ll be running live demos and having technical discussions throughout the conference that cover our developer and AI tools, including:
Developer Watchtower scans your local disk for exposed SSH keys, flags what’s vulnerable, and walks you through remediation. By Black Hat, we will enhance Developer Watchtower to discover and vault even more developer secrets.
1Password Credential Broker, currently in private beta with Github Actions, eliminates standing pipeline credentials so workloads get access when they need it and lose it when the job is done.
Secure Agentic Autofill delivers credentials in memory, scoped to the task for AI-coding agents, while the local MCP server connects directly to 1Password Environments, keeping raw values out of the AI context window.
Not attending Black Hat?
If you’re not going to the conference, find us online! We just shipped a new version of our Developer documentation site, 1password.dev, with new workflow-based getting-started guides, instructional videos, and tools to build with AI coding assistants, including llms.txt files, Markdown rendering by appending .md to any URL. Cursor, Copilot, Windsurf, and Claude can pull 1Password documentation directly. Enter Ctrl+K on any page, ask in plain language, and get a direct answer with links to the relevant pages.
Find us at Mandalay Bay
We will be in Las Vegas from August 1st through 6th. Bring your hardest supply chain scenario from the past year. That is the conversation we came to have.
The attacker knows what's on your disk. Do you?
Every 1Password plan includes a free 14-day trial. Run Developer Watchtower before Black Hat, vault what you find, and come share your experience in our booth 4735 to claim your prize.
Start scanning for free2026-07-02, 00:00

The cybersecurity landscape is changing fast. At 1Password, that means we’re continuously evolving what we work on, how we work, and the culture we need to achieve our goals.
Last year, I wrote about what high performance means to us. As our industry continues to move quickly, I want to share a more holistic view of the culture we’re continuing to shape and strengthen to meet this moment.
I recently joined the Culture Uncoveredpodcast to talk about what that looks like in practice. Now, I’m bringing some of those reflections here for anyone exploring a career at 1Password, and for people-focused practitioners curious about how culture evolves inside a growing security company.
Building on a strong foundation
1Password was founded in 2005 and has grown steadily for over two decades. I joined in early 2022, the same year we closed our Series C, which was, at the time, the largest round raised by a Canadian company. Since then, we’ve entered a chapter of incredible growth. As we scale, a big part of my role is to honour the culture that got us here while making sure our people and systems are ready for our future.
Here’s what we’re focused on right now.
How we’re enabling our people to lead with AI
This is one of the most significant shifts happening across our company and our industry. At 1Password, we’re continuing to invest in our people to help them develop AI fluency, use best-in-class tools and integrations with confidence, and do their best work.
We’ve reached roughly 98% adoption of AI tooling internally, with AI Champions embedded across departments. “AI Champions” are employees who are trained to experiment with workflows, drive peer learning, and build AI confidence in practical ways.
What we’ve learned along the way is that the process is about being curious, listening intently to employee feedback, and building trust. Our team members have important questions about privacy, responsibility, and thoughtful AI use. We make space for those questions, learn together, and stay focused on using AI to improve how we work and the outcomes we deliver.
How 1Password balances high performance with sustainable work
The pace of work is accelerating, and we prioritize a shared sense of purpose, clarity, and accountability to better serve our customers. There’s a strong sense of collaboration, openness to feedback, and opportunity for people who want to make an impact here – but this ambition can also cause some ambiguity. We're transparent with candidates about what they're walking into. This is a fast-moving, high-expectation environment where most of our challenges don’t have a “playbook.” We’re excited to meet the people who are energized by that.
Making that pace sustainable means investing in the whole employee experience. We reward our people beyond just a competitive salary and benefits. We offer support for major life moments, including generous parental leave policies and retirement matching. We also create space for our people to recharge through wellness days and connect through employee resource groups, and we continuously develop them through formal mentorship, leadership training, and AI enablement.
We’re confident that the experience we create for our people directly shapes the experience we deliver to our customers.
1Password is making time for in-person connection
1Password has been remote-first from the beginning. It’s part of how we’ve built an exceptional team across Canada, the US, the UK, and beyond. It remains a real strength of how we work.
As we’ve scaled, I’ve seen the value that comes from getting the right people in the same room with a clear purpose. There’s a level of trust and alignment that can build quickly when working in-person. When it’s done well, that energy carries back into how teams collaborate remotely.
That’s why 1Password is investing in more intentional in-person moments. We’re building out a larger hub in Toronto, where we were founded. We’re also opening spaces in the US and the UK, and we’re focused on bringing our frontline sales teams together more regularly. Across the company, we’re expanding opportunities for focused offsites, hackathons, and team volunteer events that help us connect, solve problems, and make an impact together.
We’re helping every team member see their impact
More than 180,000 businesses and millions of people trust 1Password to help protect their digital lives. That’s a responsibility every person here takes seriously and should feel connected to. Every team member, regardless of their role, is part of the customer experience and has a role to play in the future of what 1Password is building.
Ambassadorship has to be earned from the inside. People won’t represent a company they don’t feel proud of, connected to, or cared for by. That’s why our investment in the employee experience is what makes our culture of ambassadorship possible. When people feel valued, proud of their work, and clear on how they’re contributing to the future of the company, that culture grows naturally. We’re excited to keep creating more moments for our people to build connections with our customers, our work, and each other.
The road ahead
I joined 1Password because I saw an opportunity to make a real impact, and to do it alongside great people. So much has evolved since then, but that principle feels just as true today. This is a team that cares deeply about the future of 1Password, challenges each other with honesty and warmth, and wants to build something that lasts.
The work we’re doing is critically important: helping people and businesses stay secure in a world where trust, access, and identity are being reshaped every day. Together, we’re building the culture that makes that work possible.
If you’re energized by meaningful work, ownership, and the chance to help shape what’s next in identity security, I hope you’ll take a look at 1Password.
2026-06-30, 00:00

Ankur Goyal, Founder and CEO of Braintrust, which bills itself as “the AI observability platform,” joined Zero-Shot Learning to talk about the problem every team shipping AI eventually faces, you can build something that works and then watch it quietly become something that doesn't.
Braintrust sits in the iteration loop for AI products, helping teams trace production events, turn behavior into eval datasets, compare prompt or model changes, and catch regressions before they reach users. For teams building agents, quality depends on whether the system’s behavior remains useful and safe as prompts, models, tools, and user inputs change.
In this episode, what begins as a conversation about evaluation frameworks and production feedback loops reveals a security gap many teams may leave open: prompt changes are behavior-shaping production artifacts. They can change what agents do, what data they surface, which tools they call, and how they use access and credentials.
Why don't prompt changes go through the same security review as code?
"I think enterprise developers are more comfortable iterating quickly on prompts than they are changing the underlying code," Nancy said.
Before code is sent to production, a developer commits to version control, opens a pull request, waits for peer review, passes automated security scans, and gets sign-off before anything merges. The process documents who changed what, when, and why.
By contrast, prompt changes often live outside the codebase, stored in a database row, prompt-management tool, or platform dashboard that a product manager or operations team can update directly. There are often no pull requests for review, no security scans, and sometimes even no recorded change a security reviewer would see.
Many behavior-shaping changes don't register as prompt changes at all. A developer adjusts how a variable is injected, adds a retrieved context source, or modifies a template's structure, and nothing in the codebase signals that the agent will now behave differently.
I am, almost to a scary amount, frequently surprised by what the ramifications of random prompt changes are.” –Ankur Goyal, Founder and CEO, Braintrust
When a product manager updates a customer support agent's system prompt to be more helpful, the underlying code hasn't changed, nor have the credentials in use, or the access policy that applies to the agent.
Without a dedicated review process, that change slips past security entirely. The agent may now answer differently, surface different data, call tools it didn't before, or treat a workflow as in scope that wasn't before. The credentials and access policies haven't changed, but the system that appeared compliant on paper is now behaving differently in production.
How do prompt changes affect agent access?
Agent behavior and access are intertwined. Agents depend on prompts that shape how they interpret tasks, tools that determine available actions, credentials that grant access, and models that affect how consistently they follow instructions. Any change to that execution context, the prompt text, the model version, parameter settings, or retrieval configuration can shift how the agent behaves without changing a line of underlying code.
When a prompt changes, there are usually no alerts to fire and no tests to fail against. When LLM-integrated systems are haphazardly designed, a slight change in a natural language prompt can cause an agent to overreach without producing an error. When this happens, there is no way to detect if it exposed data or used a credential unintentionally. Unlike traditional code reviews, the risk lies in whether the system’s behavior stays within intended boundaries.
Because agents work behind the scenes across SaaS apps, APIs, internal systems, databases, and dev environments, they rely on non-human identities, service accounts, and shared secrets. If the credentials they use are long-lived or over-permissioned, a prompt change can quickly become more than a quality issue.
Entro Labs’ 2025 NHI and Secrets Risk Report found that 1 in 20 AWS non-human identities held full admin privileges, while only 38% of NHIs had been active in the previous nine months. That's the access exposure within which a prompt change can create risk.
What does the minimum release gate for a prompt change look like?
When Nancy asked Ankur what a minimum release gate for a prompt release should look like, his answer hinged on a maturity model.
The minimum release gate should require humans to review representative examples before a prompt change ships. Then, a team translates that feedback into scoring functions, scales testing from a few examples to hundreds, and audits the highest- and lowest-scoring outputs to refine the signal. As scoring functions improve, the process requires less human attention per change, not because the gate disappears, but because the signal has earned trust.
“You start building trust in the signal as an organization,” Ankur said. “You can still involve people in the review process, but you don’t feel nervous about always needing people as the gate to release things. Evals actually allow you to go way, way faster."
"You're able to diagnose where the issues are, isolated down to the core component," Nancy agreed.
With meaningful data, teams can stop guessing whether a prompt change improved the product. They can see where performance improved, where regressions appeared, and which examples need deeper review.
Evals can tell you whether the output was useful, accurate, and safe against defined criteria. Observability can tell you what the agent did. Neither one, on its own, tells you whether the agent should have had access to the data, credentials, or system it used. That's why prompt review and access review have to work together. As TechTarget wrote, "in many cases, there isn't a clear sense of who owns the identity, who controls and approves permissions, or who should rotate keys."
What accumulates without review?
Without a review process, prompt changes accumulate. Each update to an agent's instructions, a product manager adjusting tone, a developer adding a retrieved context source, or an automated pipeline responding to user feedback ships without anyone tracking how it interacts with previous changes. Over time, the system reflects decisions no one made deliberately and changes no one fully understands. When something breaks, who is accountable?
As Ankur said, "If you let an LLM go, go, go, go, go, and no one takes the time to actually comprehend the work, then you build up comprehension debt. And so when the piper comes and your product breaks, someone needs to actually understand what's going on to be able to have accountability for the product outcome. I think it's probably the most important problem for our industry this year."
Subscribe to the 1Password Developer newsletter
Stay up to date with the latest 1Password Developer product news, industry insights, and community contributions. Plus, learn best practices for becoming a better, more secure developer – both at work and at home.
Subscribe2026-06-29, 00:00

The engineers here at 1Password are always working to improve our products. With all the active development to introduce features, fix bugs, and enhance the overall user experience, numerous code changes go into every release. We strive to ensure each iteration is better than the last and that new code doesn’t introduce vulnerabilities. A key part of this process is our Product Security (ProdSec) team’s review of all code changes that may have security implications.
In the past, security engineers gathered on calls several times per week to go through all the PRs in the queue that required ProdSec eyes. While incredibly important, this review process was arduous and consumed countless people hours every month, especially when the engineers were flagging the same patterns over and over. And our team did this for years.
These manual security reviews worked when 1Password was a smaller company with one product. But as 1Password grew in size and expanded its product line, the number of PRs increased—and that began to grow by orders of magnitude as engineers adopted AI-coding assistants.
One thing remained constant, though: There are still only 24 hours in a day. It was a process that just couldn’t scale.
Over the past year, it became clear we needed a solution. We tested a few popular third-party tools that use artificial intelligence (AI) to enhance the traditional static analysis process (SAST) used throughout the industry. They functioned okay from a general security perspective but we knew we could do better. We believed we could use AI models, along with a 1Password-specific knowledge base, to significantly reduce the time and effort our team dedicated to security reviews.
A few days later, we had an idea and a great moniker: SAGE (Security Analysis Guidance Engine). 🌿
Analyzing our history to guide our engine
SAGE was an ambitious hypothesis but we had all the information we needed, we just had to compile it. It started with a script.
We gathered nearly 9,000 pull requests that spanned over five years of ProdSec code reviews. The reviews covered our entire codebase: Rust, Go, Kotlin, TypeScript, and Swift. We fed those reviews into an LLM to deduplicate comments and cull any superfluous notes (like thumbs-up emoji and “Looks good to me!”) and ended up with 8,343 reviews that consisted only of the ProdSec engineer’s comment and corresponding diff hunk. Finally, we gave those reviews to an LLM and instructed it to synthesize the information into rules, grouped by vulnerability category (and deduplicate accordingly).
We (real live humans) reviewed and edited the output, and went into v0 with 171 rules across 16 categories like authentication, cryptography, and logging.
SAGE v0 was deliberately modest. First, we ran it locally against PR diffs downloaded directly from GitHub. SAGE made a single call to the LLM with a relatively minimal prompt, instructions for structured output, the PR diff, and a copy of the ruleset.
Our local tests were pretty successful and, after posting SAGE’s comments on the live PRs, we received positive feedback from reviewers on the team. At that point, it was time to try SAGE in the production pipeline, so we deployed it as a GitHub Action using an existing internal GitHub Actions framework as a starting point.
As a GitHub Action, SAGE v0 posted its findings on the scanned PRs with comments keyed to the specific lines of code. It also maintained an activity log: A persistent PR comment updated on each push that tracked scan history (new findings, resolved findings, errors). Reviewing engineers could react to the comments with a thumbs up if they agreed with the finding and thumbs down if they deemed it a false positive.
SAGE really began to show its worth when it scanned a PR that touched a lot of cryptographic code. It identified 6/6 true positives, including findings initially missed by our human reviewers. And it did all this for an average token cost of $0.47 USD per scan.
But we also noticed shortcomings with the SAGE v0 implementation. Primarily, we were asking one model to locate and verify findings in the same call. SAGE also lacked any false-positive filter, had little hardening against prompt injection, and supported only a single provider. V0 proved our concept worked but it was one call/model doing everything; we needed separation and some form of objectivity.
So we got back to work.
A multi-model harness optimized for separate tasks
We researched and brainstormed for days before we outlined a (pretty daunting) plan for SAGE v1.
We started with housekeeping tasks. With access to more advanced models at this point, we ran another rule extraction and reconciled the output with the v0 ruleset. V1 now has access to 343 rules that cover 16 vulnerability categories. From that ruleset, we created a compact index that consists only of the rule ID and a one-line summary of the rule.
That was the easy part.
Our v1 architecture introduced two critical aspects: model/vendor agnosticism and a call pipeline.
At a time when AI technology advances nearly every day, we wanted SAGE to be flexible. So we designed v1 to talk to LLMs through an llm.Client interface, which made the scanner entirely provider-agnostic.
Following a consultation with industry experts, we also built a three-stage progressive-disclosure pipeline: A series of separate LLM calls that each receive specific information.
Stage 1: Finder
The Finder stage is intentionally noisy. It sees the compact rule index, a tailored prompt, and instructions for structured JSON output. This stage detects and reports prompt-injection attempts as PROMPT-INJECTION findings. Its goal is high recall. Speculative findings are acceptable because the next stage in the pipeline handles quality control.
Stage 2: Critic
The Critic stage is a completely separate API call. It has no access to the Finder’s chain of thought, reasoning, or raw response. It sees the structured finding JSON, relevant code hunks, and the full rule body for the cited rule ID (from the index). The Critic’s prompt is adversarial: ”Consider findings exploitable unless you can prove otherwise; actively look for reasons each finding is WRONG.” It considers whether the code path is reachable, the finding is within test or mock code, there are mitigations elsewhere, and exploitation requires multiple unlikely conditions.
Stage 3: Judge
The Judge stage is another discrete call. It receives the original finding JSON, Critic’s output, and code hunks. Its prompt is explicitly neutral. We instruct it to weigh the finding and Critic output independently, and to not be biased toward either the finding or critique. The Judge outputs a verdict (confirmed, false positive, needs review), a list of preconditions, and an exploit scenario (for confirmed findings only). It drops false-positive findings entirely and logs them and its rationale for human review.
With the pipeline structure built, we started testing — we needed to know which models were best suited for each stage. We cloned an internal GitHub repository, created five model profiles, and ran each profile against the same 10 PRs. With the results of those 50 PR scans, we analyzed the number of findings, overall cost, catch rate, and token cost per finding. One profile was the clear winner and finalized our default SAGE v1 pipeline.
Our Finder uses a fast, mid-tier, cost-efficient model chosen for breadth and speed since the Finder's job is wide, inclusive discovery rather than airtight proof. Our Critic relies on a frontier reasoning model from a different provider than the Finder. We chose this model for two reasons: it doesn’t share the Finder’s blind spots and can adversarially pressure-test each finding. Finally, our Judge calls a powerful high-end reasoning model that weighs the finding against the critique and renders the final verdict. With separation and objectivity in place, we wired in the default profile and went live.
SAGE v1 runs in our largest repositories today, and already saves our ProdSec engineers hours of review time every week.
Beyond the diff: The future of SAGE
The third-party products we evaluated know general security canon, but SAGE knows 1Password.
By building our own reviewer on top of our historical expertise, we got a tool that speaks our languages and applies the judgment our ProdSec engineers spent years developing.
SAGE v0 proved the hypothesis: An LLM, equipped with 8,343 past reviews distilled into a ruleset, can surface real vulnerabilities (sometimes those missed by our incredible human engineers!) for pennies per scan. SAGE v1 made it production-ready: A vendor-agnostic Finder / Critic / Judge pipeline that separates recall from precision, hardens against prompt injection, and adjudicates every finding with built-in objectivity. This is all wrapped in a deterministic harness that allows us to easily migrate to the latest frontier AI models as soon as they become available.
But every version of SAGE to this point shares one limitation: It only scans PR diffs. Our engineers still have to bring the context no isolated change can capture: which directories are sensitive, where the trust boundaries sit, what guards already exist elsewhere. Giving SAGE that same awareness is where SuperSAGE comes in.
SAGE already knows 1Password. Soon, it will understand it.
We'll save those details for Part 2.
News and updates for developers
Subscribe to our developer newsletter to be the first to know about new betas, tools, and resources for developers.
Subscribe2026-06-26, 00:00

The agents running in your environment aren’t all the same and neither are the risks they carry. A CI/CD pipeline runner and a long-running autonomous coding agent have fundamentally different access needs, threat surfaces, and identity requirements. Traditional IAM has been successful at governing login for humans and machine workloads with predictable behavior, but controlling non-deterministic agentic systems require unique authority models that a single identity architecture cannot fully govern.
An agent that starts with access to a QA database may determine mid-task that it needs production access to complete its task, and the architecture governing it has to respond in real time without over-provisioning. That sort of dynamic authorization looks different depending on the type of agent that’s running, who authorized it, and what it has access to.
At 1Password, we’ve mapped the AI agent architectures we see in production into delegated, bounded, and autonomous authority models, each with variants for local and remote deployments. In this post, we’ll explore the distinct threat models and required controls to secure all six profiles at your organization.
The three agent authority models
The authority model describes who or what the agent is acting on behalf of, and what accountability chain that creates.

Delegated authority: The agent acts on behalf of a named human. The human's identity is the delegation subject, and the agent's actions must be traceable back to it.
Bounded authority: The agent acts on behalf of a system or workflow. No human subject is in the chain; instead, the agent is scoped to a defined operational boundary.
Autonomous authority: The agent acts toward a goal with minimal or no human oversight. It may spawn sub-agents, evolve its access needs over time, and operate across systems its initiator did not explicitly plan for.
For each model, deployment in a developer's machine, a local sandbox, or an on-device browser, introduces a different set of attestation and threat challenges than in a remote environment like a Kubernetes cluster, a managed cloud sandbox, or a CI/CD platform. That distinction drives a significant portion of the protocol choices in each profile.
Delegated authority
A delegated agent is an extension of a human, it inherits the human's permissions and intentions within an explicitly scoped boundary. The challenge is not just proving that the agent has authorization; it’s proving whose authorization it has in a way that is cryptographically verifiable and auditable at the delegation level.
Every action a delegated agent takes must be traceable back to a human who authorized it and must be able to answer what scope was granted and the steps it took. Logging actions under a service account fails this requirement entirely.
Use cases include:
IDE coding agents: Cursor, Claude Code, Codex, GitHub Copilot running in a developer's local environment, acting on behalf of the developer to read repositories, write code, and call external APIs.
Browser copilots: Claude for Chrome, ChatGPT Atlas, and similar tools that act on behalf of a user within their browser session and SaaS applications.
Workplace assistants: Sales, RevOps, and support agents that draft documents, schedule meetings, query CRM systems, and take actions within the user's existing SaaS permissions.
Delegated / local
A local delegated agent is an AI agent running on a user’s own machine that acts on their behalf, where the human remains the authorizing principal but the agent executes autonomously within a delegated scope. Local delegated agents are the most common deployment pattern and carry the highest attestation risk profile.
When a coding agent runs in a developer's IDE, it executes under the same OS user account as the developer. Without additional controls, any other process running under that account could impersonate the agent. Malicious code, a compromised package, or an attacker payload injected via a prompt can all claim to be the legitimate agent when presenting credentials to an authorization server. This was documented in a production environment, where indirect prompt injection turned a long-lived local agent session into an attack vector.
The Workload Identity Broker is an intermediary security service that replaces static API keys and passwords with ephemeral, policy-driven credentials. It’s common in cloud-hosted environments, such as CI/CD workloads, but typically isn’t available in local environments. In the context of local delegated agents, the WIB would be a code-signed local daemon that sits between the agent and the authorization server.
Before issuing any credential, the broker verifies the calling process against the OS code-signing subsystem like macOS Code Signing, Windows Authenticode, or Linux IMA. It holds an ephemeral key pair enrolled with the authorization server during device registration, and never exposes a long-lived credential to the agent process itself.
The protocol stack on top of this uses OAuth Token Exchange (RFC 8693) to express the delegation. The agent presents a subject token for the human and receives a delegated access token scoped to the specific role. The `act` claim in the resulting JWT carries the agent's workload identifier, making the delegation chain explicit and auditable end-to-end.
WebAuthn (W3C Level 3) provides step-up authentication for high-level actions like
pushing to a production branch, writing to a secrets vault, or making infrastructure changes. The agent triggers a user gesture, either with Touch ID, Windows Hello, or a hardware security key, to confirm explicit human intent before proceeding. This keeps humans in the loop on consequential actions and allows the agent to run without requiring approval for every low-risk operation.
The most important operational control for local delegated agents is session lifetime. Credentials must be rotated continuously throughout the session to maintain scope because a prompt-injection attack that succeeds mid-session inherits whatever is live at that moment. Longer sessions provide longer risk exposure. Development and production access must be separated at the policy level, a local coding agent should never hold credentials for production systems, regardless of what it requests.
Delegated / remote
Remote delegated agents run in infrastructure the organization controls or contracts out, like a managed cloud service, a hosted browser policy, or a SaaS platform with an agent runtime. The delegation subject is still a human but the execution environment is controlled and attestable, meaning you can cryptographically verify where the agent is running and under whose authority.
When an agent runs on a local machine, there's no external party that can verify that it is what it claims to be, which is why the Workload Identity Broker exists. When the agent runs in the cloud, the platform already knows exactly what's running in it. It issues an OIDC token asserting the workload's identity, which gets exchanged via RFC 8693 for a delegated access token scoped to what the authorizing user approved. The platform takes the Workload Identity Broker's role, so the agent’s identity is verified before any access credential is issued..
With attestation managed by the platform, the primary challenge for delegated/remote agents is scope drift. Remote agents running in managed environments operate continuously and reliably, which creates pressure to provision them with broad, persistent permissions rather than issuing just-in-time credentials for each task. This is operationally tempting and architecturally wrong. The correct implementation re-establishes the delegation chain from the human principal at the start of each task, issues scoped tokens for that task window only, and expires them when the task completes.
WIMSE (Workload Identity in Multi-System Environments) is the key protocol for remote delegated agents that cross service boundaries. A workplace assistant that reads calendar details, sends emails, and queries a CRM in a single session might cross several service boundaries in a single session. Each of those systems has its own authorization rules and no pre-existing trust with the agent's home runtime. WIMSE provides a standard for expressing the workload identity portably across all three boundaries, in a format every system understands.
CAEP (Continuous Access Evaluation Profile) is a hard requirement at this profile. Remote delegated agents can act faster and across more systems than local agents. When a user's session is revoked, or their permissions change, or a security event is detected, that change must propagate immediately to every relying party the agent has an active session with, not at the next token expiry.
In enterprise environments where MCP clients and servers both support it, the Enterprise-Managed Authorization (EMA) extension for MCP offers an optional alternative path for how the initial delegation chain is established. Instead of the agent’s runtime exchanging directly with the MCP server’s authorization server, the organization’s identity provider (Okta, Azure AD, or similar) acts as an intermediary. The MCP client exchanges the user’s existing SSO identity for an Identity Assertion JWT Authorization Grant (ID-JAG), which is then presented to the MCP server’s authorization server in place of the standard token exchange. This means access policy and revocation for MCP servers are centralized at the IdP, alongside every other enterprise application, which is operationally attractive for large deployments.
Bounded authority
Bounded agents act on behalf of a system or workflow, where there is no human delegation subject in the authorization chain. The agent's authority is derived from its operational scope defining the set of services, tools, and actions it is configured to use.
The identity challenge for agents with bounded authority is scope enforcement. The work these agents need to accomplish is often broad, and issuing fine-grained, per-task credentials have been expensive to implement historically. So organizations routinely take the shortcut and provision bounded agents with permissions far wider than any single run requires. That over-provisioning determines the blast radius when these credentials are compromised.
Use cases:
CI/CD pipelines and review bots: GitHub Actions, GitLab CI, and Jenkins – automated build, test, and deploy workflows that need ephemeral, scoped access to source repositories, artifact stores, and deployment targets.
Provisioning and lifecycle jobs: Joiner-mover-leaver workflows running off SCIM, HR automation agents that create, modify, and deprovision accounts across connected systems.
Scheduled batch jobs: Compliance reporting, billing pipelines, ETL workflows, and webhook receivers that run on a schedule and interact with specific downstream APIs.
Bounded / local
Local bounded agents often handle development automation and local webhook receivers. There is no human delegation chain to impersonate and although the agent's authority is derived from its configured role rather than a user's permissions, the workload identity still matters. A local automation process needs a verifiable identity to obtain credentials for the systems it touches.
For local bounded agents, the Workload Identity Broker only needs to verify the process and issue a scoped token. There’s no user delegation chain, no step-up authentication, no RFC 8693 token exchange. The broker verifies the process through the OS code-signing subsystem and issues a WIMSE-compliant workload identity with a short-lived, scoped access token for the specific services it’s configured to reach.
The critical operational control is the same as in remote bounded case: each local automation run should receive a token scoped to that run only. A deploy script targeting a test environment and a deploy script targeting production should hold separate workload identities, authorized by separate policies, even when they are the same codebase. That’s the development-vs-production trust boundary that matters most for teams running automated deployment scripts locally.
Bounded / remote
Remote bounded agents are the most common profile in enterprise environments today. Nearly every organization running automated pipelines has remote bounded agents, and most of them run on long-lived credentials that have never been rotated, scoped, or revoked, accounting for the largest, unaddressed source of non-human identity risk in the environment.
Controlling access for remote bounded agents starts with eliminating long-lived credentials at the source. Where platform OIDC is available, a short-lived OIDC token is issued for each workflow run, scoped to the specific repository, workflow, and run. That token is exchanged at the authorization server for credentials that cover only the resources the current stage requires. No long-lived secret is stored in the repository or secrets manager. The agent's workload identity is cryptographically tied to that specific run, not to a persistent, static credential.
For environments without native platform OIDC, SPIFFE/SPIRE can issue short-lived identity documents to workloads based on verifiable runtime attributes (pod labels in Kubernetes or instance metadata in cloud environments) and rotate them automatically. WIMSE provides the standard for expressing those identities across service and organizational boundaries in multi-environment deployments.
The unsolved problem for most teams implementing this profile is per-stage token scoping, i.e., the ability to issue a token for the build stage that cannot access deployment targets and a separate token for the deploy stage that cannot access the source repository.
OAuth Transaction Tokens are designed specifically for this. They carry the full context of a multi-step, cross-service transaction and allow each stage to receive only the authority it needs for that stage, while maintaining a tamper-evident chain linking the workflow back to its initial authorization.
CAEP subscription at this profile gives security teams something long-lived credentials can never offer: the ability to revoke a pipeline's access mid-run in response to a threat signal. Long-lived credentials stored in secrets managers are only checked at authentication time; by definition, they can't be stopped once a run has started.
Autonomous authority
Autonomous agents pursue a goal over an extended time horizon with minimal or no human oversight. They adapt their behavior to new inputs, may spawn sub-agents for specific tasks, and frequently need access to systems their initiator didn’t explicitly anticipate. A human sets the goal, but the agent determines the execution path.
The identity challenge here is continuous authorization. Every step the agent takes must be authorized by a policy that is consistent with the original human intent, even when no human is available to approve it in real time. This places the highest demand on any architecture: real-time enforcement, revocation infrastructure, and a complete audit trail for the execution path.
Use cases:
Long-running coding agents in managed sandboxes: Devin, Claude Code in autonomous mode, and similar systems running inside remote execution environments like Daytona to build and test software without a human in the loop for each step.
Supply chain and operations agents: Agents that reroute orders, adjust inventory, or respond to infrastructure disruptions autonomously.
Autonomous production remediation agents: Security or reliability agents that act quickly detect issues and take corrective action on live infrastructure.
Continuous security agents: Threat hunting and posture management agents that run ongoing scans, correlate signals across systems, and surface findings.
Autonomous / local
Local autonomous agents are currently rare, but the pattern is emerging. Local execution requires a level of trust in an agent’s reliability and sandboxing environments that are still maturing. While these boundaries are maturing, most teams running autonomous agents today deploy them in managed cloud environments. An example of an autonomous, locally run agent would be one that runs overnight on a developer’s machine, iterating across multiple repositories, installing dependencies, and calling external APIs to build a feature end-to-end.
The risk level here is high. A long-running process, operating without active human oversight, on hardware that may be shared or uncontrolled, allows an agent to accumulate access across systems over an extended session. A single successful prompt injection attack could redirect the agent's goal while it continues to operate under a valid credential.
The Workload Identity Broker here must implement continuous credential rotation. Instead of a single issuance at startup, a fresh token must be issued for each meaningful task transition. The broker must also monitor the calling process to detect if the agent's process signature changes during execution, a sign of compromise or injection, and stop credential issuance immediately.
A local autonomous agent running without human oversight has no natural stopping point, so CAEP subscription is important even at the local level. A revocation event from the authorization server must terminate the agent's active sessions across all local services it has touched. Without it, a compromised session persists until the next token expiry, which, for an autonomous agent, is an unacceptably large window.
A local autonomous agent must not hold credentials for production systems. Any artifact it produces should require an explicit human approval step and re-authorization before it touches production infrastructure.
Autonomous / remote
Remote autonomous agents have the highest security risks and the highest operational complexity. Long-running agents in managed sandboxes, continuous production agents, and autonomous remediation agents all fall here.
Remote execution provides better attestation infrastructure, but autonomy introduces problems that platform attestation alone cannot address. The core issue is that the agent's access needs evolve mid-execution in ways the initial authorization policy did not anticipate.
Handling this without granting standing broad permissions requires just-in-time privilege escalation: a mechanism for the agent to request additional access at runtime. That request gets evaluated against current policy and the original authorization context, and the agent receives a scoped, short-lived credential for the specific step, without a human in the loop for routine escalations, and with explicit human approval required for escalations above a defined sensitivity threshold.
OAuth Transaction Tokens carry the entire authorization context of the original grant, subsequent escalations, and the policy decisions made at each step, in a tamper-evident chain. Consider an agent that starts a run with access to QA resources, runs a deployment test, and requests production access to proceed. The transaction token records the escalation request, the policy that evaluated it, and the credential issued in response, in a complete, unfalsifiable chain.
Sub-agent delegation is an open problem at this profile. An autonomous agent that spawns a sub-agent for a specific task must constrain the sub-agent's authority to a subset of its own. The sub-agent cannot inherit the full permission set.
WIMSE and the Agent Identity Management (AIMS) model provide the conceptual framework where the parent agent presents its workload identity plus a delegation scope when requesting a token for the sub-agent, and the authorization server issues a token bound to that scope. This is one of the areas where the community is most actively developing the specs.
CAEP at this profile must cover all downstream systems the agent has touched, including sub-agents. A revocation event for the top-level agent must cascade to every sub-agent spawned under its authority. Teams implementing this profile need to plan for revocation cascades at the system design stage and build them in from the start.
The development/production boundary is crucial for autonomous remote agents with production access. These are the highest-risk workload in this framework. Separate authorization policies, separate audit logs, and explicit human approval requirements for production-scope actions are required controls.
Three security requirements to govern AI agent identity
The six profiles share three non-negotiable requirements:
No long-lived credentials on agent workloads. Local or remote, delegated or autonomous, agents receive short-lived, scoped tokens issued for a specific task window. The Workload Identity Broker (local) or the platform OIDC subsystem (remote) manages the credential lifecycle. The agent never holds a secret that survives the task.
Attribution-complete audit records. Every agent action traces to a specific workload identity. Every workload identity traces to either a human delegation subject or a bounded system authority. The delegation chain must be captured in the log, not reconstructed after the fact.
Development and production are separate trust domains. Writing software and running it on production systems carry fundamentally different threat models. Separate workload identities, separate authorization policies, and explicit human-in-the-loop controls for any promotion from development to production are a design requirement.
Each authority model and execution environment combination has a distinct identity architecture with its own protocols, attestation mechanisms, and operational controls. The next posts in this series will walk through each one in detail, covering what the use cases look like, what the architecture requires, and where the hard problems still live.
Explore Unified Access
See how 1Password Unified Access secures identity for humans, machines, and AI agents without long-lived credentials, attributable audit records, and clear dev/production boundaries.
Learn more2026-06-25, 00:00

For years, our Pride Employee Resource Group (ERG) has been building something that goes far beyond a single month on the calendar: a community rooted in connection, visibility, and belonging for employees and allies across 1Password.
This Pride Month, we're spotlighting Chris Houckham-West, a Customer Success Leader based in EMEA and a leader within our Pride ERG. In his time at 1Password, Chris has built a high-performing Customer Success team, earned recognition as part of President's Club, and helped bring our very first in-person Pride event in EMEA to life. What stands out most about Chris beyond his accomplishments is the way he leads: with openness, authenticity, and a genuine belief that when people feel like they belong, everyone does better work.
We sat down with Chris to talk about his career journey, his philosophy on building inclusive teams, and why creating spaces for connection and belonging remains as important as ever.
Can you walk us through your career journey and what drew you to Customer Success? Was this a path you always envisioned for yourself, or did it evolve through unexpected opportunities and experiences?
Customer Success definitely wasn't a career path I set out to follow. Like many people who have been in the industry for a while, I found my way into it before it was really called Customer Success.
I've always been drawn to understanding people, solving problems, and building relationships. Early in my career I worked in customer-facing roles across retail, travel, and technology, and what I enjoyed most wasn't closing a deal or handling a support ticket. It was helping customers achieve something meaningful and seeing the impact that had on their business.
Over time, I realised the most rewarding conversations were the strategic ones. The conversations about outcomes, adoption, growth, and long-term partnerships. Customer Success brought all of those things together.
I've been fortunate to work in a number of high-growth companies and build teams along the way. Each role taught me something different, whether that was scaling processes, leading through change, or developing people. Looking back, the path wasn't planned, but it makes perfect sense. Customer Success sits at the intersection of people, technology, and business outcomes, which are the three things I've always been most passionate about.
You've built a Customer Success team that reflects a wide range of backgrounds, identities, and perspectives. What's your philosophy on building, developing, and retaining a team like that, and what does inclusive leadership look like in practice for you?
I've never believed there is a single profile of what makes a great Customer Success Manager. Some of the best people I've hired have come from completely different backgrounds and brought skills that wouldn't necessarily have shown up on a traditional checklist.
For me, building a great team starts with recognising that diversity of thought, experience, identity, and perspective makes teams stronger. When everyone approaches a challenge in the same way, you tend to get the same answers. Diverse teams challenge assumptions, bring fresh ideas, and ultimately make better decisions for customers.
Inclusive leadership isn't something that happens during a hiring process or a company event. It's the day-to-day work. It's making sure everyone has a voice, creating an environment where people feel safe to contribute, and understanding that different people need different things to do their best work. As a leader, my job isn't to create a team of people who think like me. It's to create a team where people can be themselves, grow their careers, and succeed on their own terms. When people feel valued and supported, performance tends to follow.
You were recently recognized as part of the President's Club in GTM, a significant acknowledgment of the impact you've had. What did that recognition mean to you personally, and what do you think has been key in building such a strong, high-performing team?
Being recognised as part of President's Club was incredibly meaningful, particularly because Customer Success is such a team sport. While it's a personal recognition on paper, the reality is that achievements like that are only possible because of the people around you. I lead a fantastic team, and I work alongside colleagues across Sales, Support, Product, Marketing, and many other functions who all contribute to our customers' success.
The thing I'm most proud of isn't the recognition itself; it's seeing the growth of the team. Several members of my team joined 1Password relatively recently, and watching them build confidence, deepen their expertise, and deliver great outcomes for customers has been incredibly rewarding.
If there's one thing that's contributed to our success, it's creating a culture where we openly share both successes and failures. We celebrate wins, learn from challenges, and encourage people to be honest about what's working and what isn't. Combined with a shared focus on helping customers achieve their goals, that openness helps us continuously improve, support one another, and ultimately deliver better outcomes for our customers.
This year you joined the leadership team for our Pride ERG and helped bring our first in-person Pride event in EMEA to life. What has that experience meant to you, and what do you hope attendees took away from it?
Joining the Pride ERG leadership team has been incredibly rewarding because I've seen both sides of the equation throughout my career.
I've worked in organisations where LGBTQ+ employee groups didn't exist, or where there was a perception that they weren't really needed anymore. The reality is that, for many LGBTQ+ people, there are experiences that never fully go away. Every time you start a new job, there's a moment where you're deciding whether to come out, how much of yourself to share, and how people might respond. And while we've seen a huge amount of progress over the years, it's also hard to ignore that some members of our community continue to face increased scrutiny and uncertainty.
That's why ERGs matter. They create visibility, support, education, and a sense of connection. They remind people that they're not the only person navigating those experiences, and they help foster understanding across the wider organisation.
Bringing our first in-person Pride event in EMEA to life was something I was particularly proud of. What stood out to me wasn't just the attendance from LGBTQ+ employees, but the number of allies who showed up to learn, listen, and show their support. That sends a powerful message. The educational sessions sparked some fantastic conversations and gave people the space to ask questions, share experiences, and deepen their understanding.
What I hope people took away from the event was a sense of belonging. Whether someone identifies as part of the LGBTQ+ community or is an ally, I wanted people to leave feeling connected, supported, and reminded that inclusion isn't just something we talk about during Pride Month. It's something we build together every day.
What does it mean to work somewhere that not only celebrates Pride, but actively invests in building community and belonging throughout the year?
For me, the difference is authenticity. Anyone can put a rainbow logo on a website in June. What matters is what happens during the rest of the year.
Working somewhere that invests in employee communities, gives ERGs a genuine voice, and creates opportunities for people to connect demonstrates that inclusion isn't being treated as a campaign or a checkbox exercise. It's part of the culture. As someone who has spent much of his career in organisations where these kinds of communities either didn't exist or weren't prioritised, I don't take that for granted. Having spaces where people can share experiences, learn from one another, and feel supported makes a real difference.
When organisations create environments where people feel comfortable bringing their whole selves to work, everyone benefits. Teams become stronger, collaboration improves, and people spend less energy worrying about whether they fit in and more energy doing their best work.
Chris's leadership shows the impact that authenticity, openness, and community can have on both individual growth and collective success. Whether he's supporting customers, developing team members, or helping strengthen our Pride community, Chris leads with a belief that people do their best work when they can show up as themselves.
As we celebrate Pride Month, we're grateful for leaders like Chris who help make 1Password a place where LGBTQ+ employees and allies can connect, contribute, and belong—not just in June, but throughout the year.
null
Want to learn more about what it’s like to be part of the 1Password team? __[Check out our careers page.](https://1password.com/careers)__
2026-06-23, 00:00
Recognized for Completeness of Vision and Ability to Execute
1Password has been recognized as a leader in the 2026 Gartner® Magic Quadrant™ for SaaS Management Platforms.
SaaS Manager gives IT and security teams visibility into unapproved AI use and every app, AI tool, and dollar spent across their organization. This foundation lets teams identify real-time AI token overruns before mid-year budget surprises hit, cut wasted license spend, and reduce friction for employees requesting access. The platform closes the access gaps that happen outside of SSO, governing human access across the full employee lifecycle and enabling AI agents to automate governance workflows through an MCP Server. We believe our placement in the Gartner® Magic Quadrant™ reflects our vision that with the right controls, SaaS management can help a business move faster.
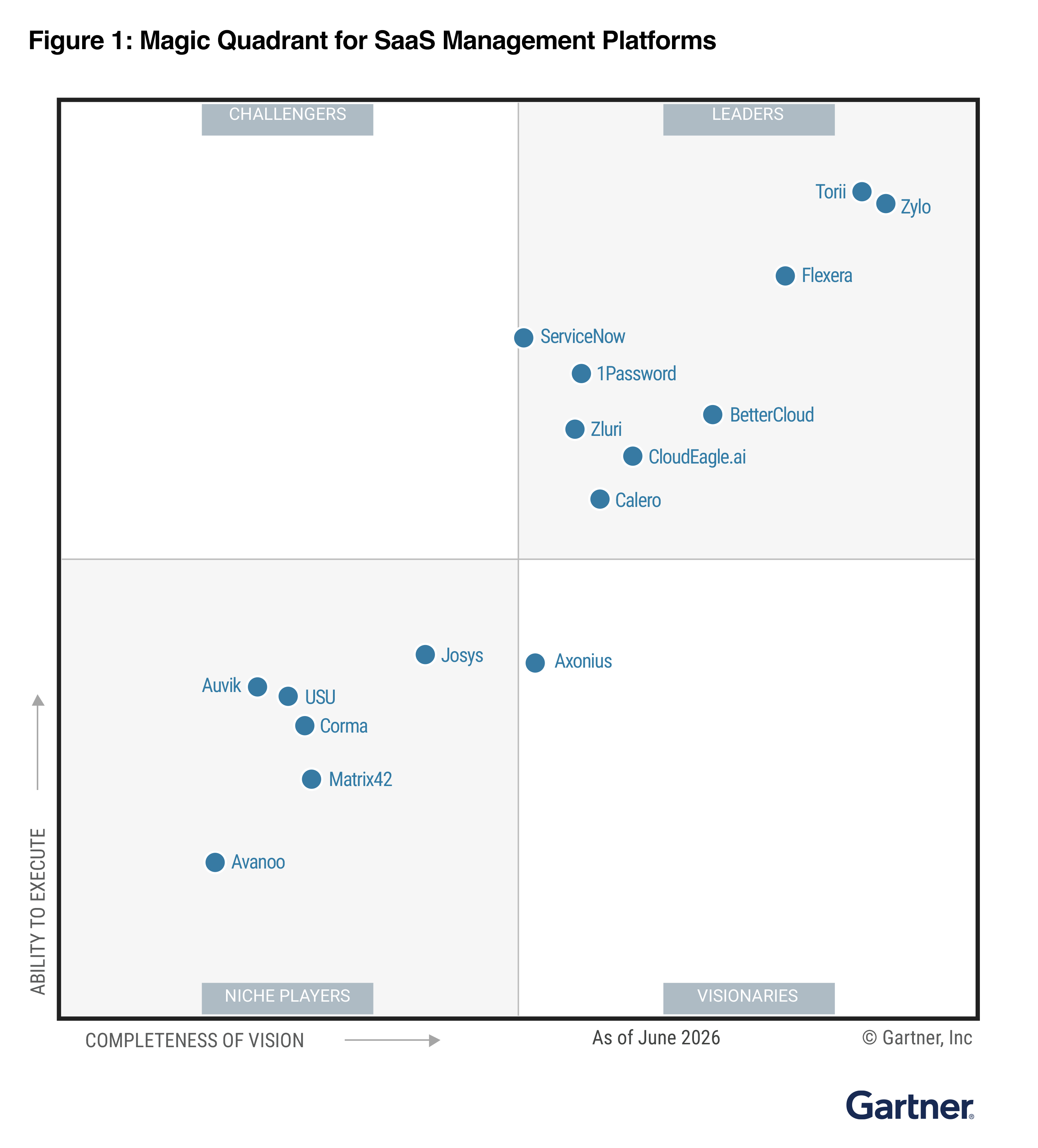
Get the full analysis
[Read the Gartner® Magic Quadrant™ for SaaS Management Platforms](https://1password.com/resources/gartner-magic-quadrant-saas-management-platforms-2026)
Identity Access Management doesn’t show the full picture of AI token consumption and SaaS access
Employees aren't waiting for IT approval to adopt AI. The 1Password Access-Trust Gap Report found that 27% of knowledge workers were using AI-based applications that their employer didn’t approve. Coding assistants, productivity tools, and AI platforms are being connected to work accounts, granted API access, and signed in with corporate credentials, often through a single "sign in with Google" OAuth token that leaves no trace in the identity provider. IT has no record of these AI tools, no visibility into what data enters the AI’s context window, and no way to revoke access. When those tools run on consumption-based pricing, annual AI token budgets are being depleted within months, with no signal to finance until the allocation is nearly gone.
SaaS sprawl has been a known cybersecurity problem for years, and until recently, traditional identity management was sufficient to keep pace. While the proliferation of AI and SaaS tools empowers teams to set themselves up and get rolling without waiting for IT review or procurement, that agility creates gaps in spending, visibility, governance, and compliance that traditional budget controls and SSO cannot close.
According to the Access-Trust Gap Report, 52% of employees have created accounts for new AI tools and SaaS apps without IT approval, and 34% of company apps sit outside SSO, where IT has no way to see, secure, or revoke access.
Shadow IT and unmanaged shadow AI don’t automatically disappear when employees change roles or leave the organization, and IT can’t revoke access for unfederated tools. In an interview with 1Password, Mark Hillick, CISO at Brex, said, “Offboarding is challenging because so many apps are outside SSO, and additionally, SCIM's effectiveness varies by vendor implementation. As a result, you can disable someone's access through your SSO provider, but it's easy to miss something, and ongoing monitoring is required."
How 1Password SaaS Manager helps govern AI and SaaS access
Automate AI and SaaS discovery beyond SSO
The 1Password browser extension detects OAuth credential grants in real time, surfacing new AI tools to IT before they become governance gaps or offboarding problems. SaaS Manager closes the visibility gap of unmanaged AI and SaaS by continuously discovering applications across identity providers, SSO logs, finance systems, device agents, browser extensions, and 1Password vaults, to surface all the tools your employees log into for work.
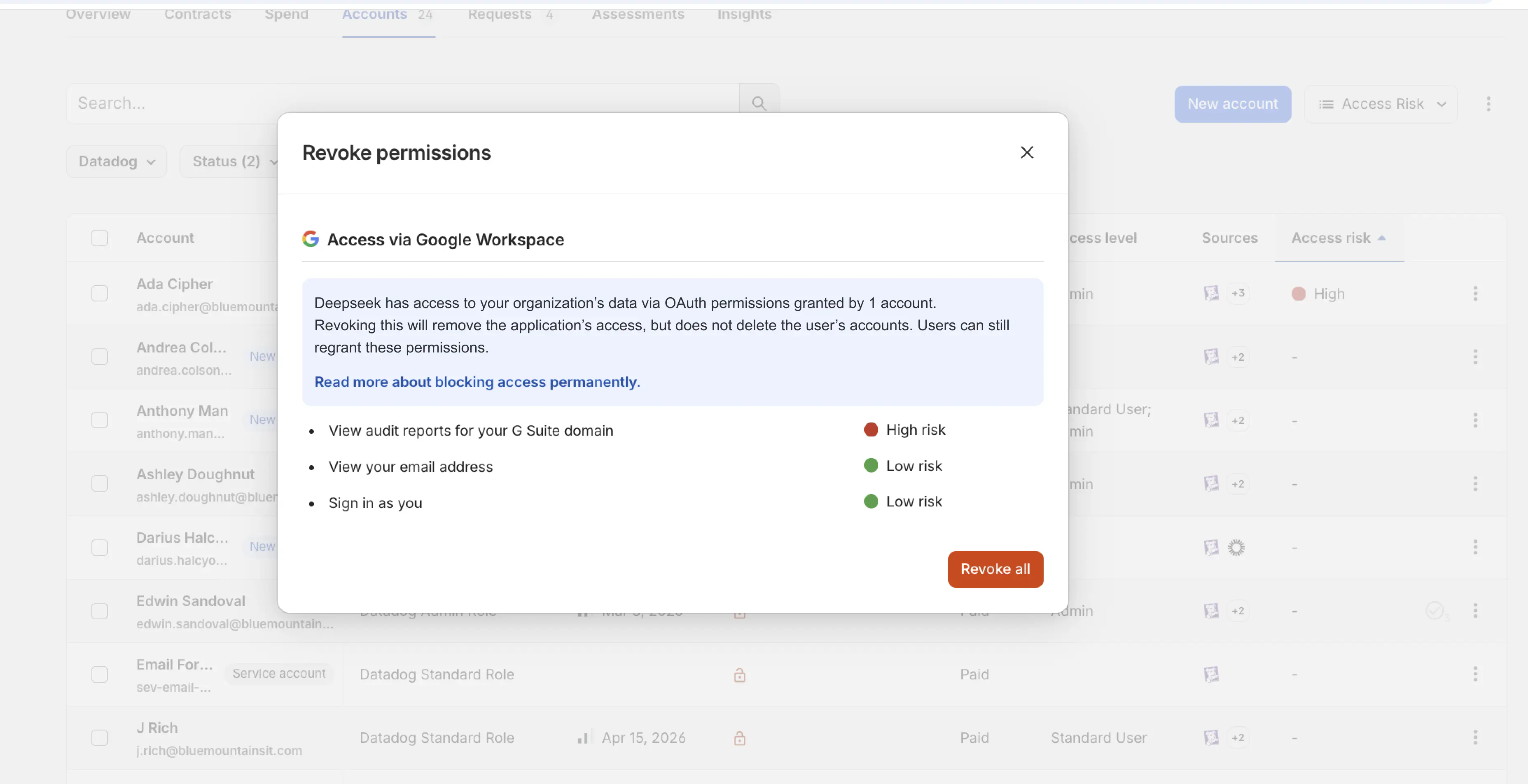
When Flipdish connected SaaS Manager to their identity provider and finance systems, they discovered more than 1,000 applications in under five minutes. "Okta was a good first step for us," said Leon Weavers, IT Manager at Flipdish, "but we still had limited visibility of our SaaS estate."
Discovered apps are matched against a library of 40,000+ pre-populated profiles to show immediate risk context and compliance posture. SaaS Manager also integrates with 400+ systems across IT, HR, finance, identity, and security, including AI tools like Claude, Cursor, ChatGPT Enterprise, and the OpenAI Platform.
Control AI token consumption
Unlike traditional SaaS licensing, token-based AI consumption pricing means spend accumulates in real time, not just at renewal. Token budgets set at the start of the year can drain in just a few months. Finance leaders are already asking how much they're spending on AI, which team is driving the overrun, and when prepaid token commitments expire.
When Uber deployed Claude Code to 5,000 engineers, the company exhausted its entire annual budget in four months. Most organizations manage AI consumption using a combination of vendor dashboards, CSV exports, and spreadsheets, leaving finance without visibility into real-time consumption trends.
SaaS Manager replaces disparate vendor dashboards with a single view of AI usage and cost, broken down by team, user, and model. Burn-rate alerts catch overages before they hit for vendors like Cursor, Claude, and OpenAI. AI-assisted contract extraction pulls key terms and renewal dates directly from vendor agreements, so finance and IT can act between renewals. This turns unpredictable AI costs into a managed line item and helps finance forecast usage, attribute spend by team, and make confident decisions at renewals.
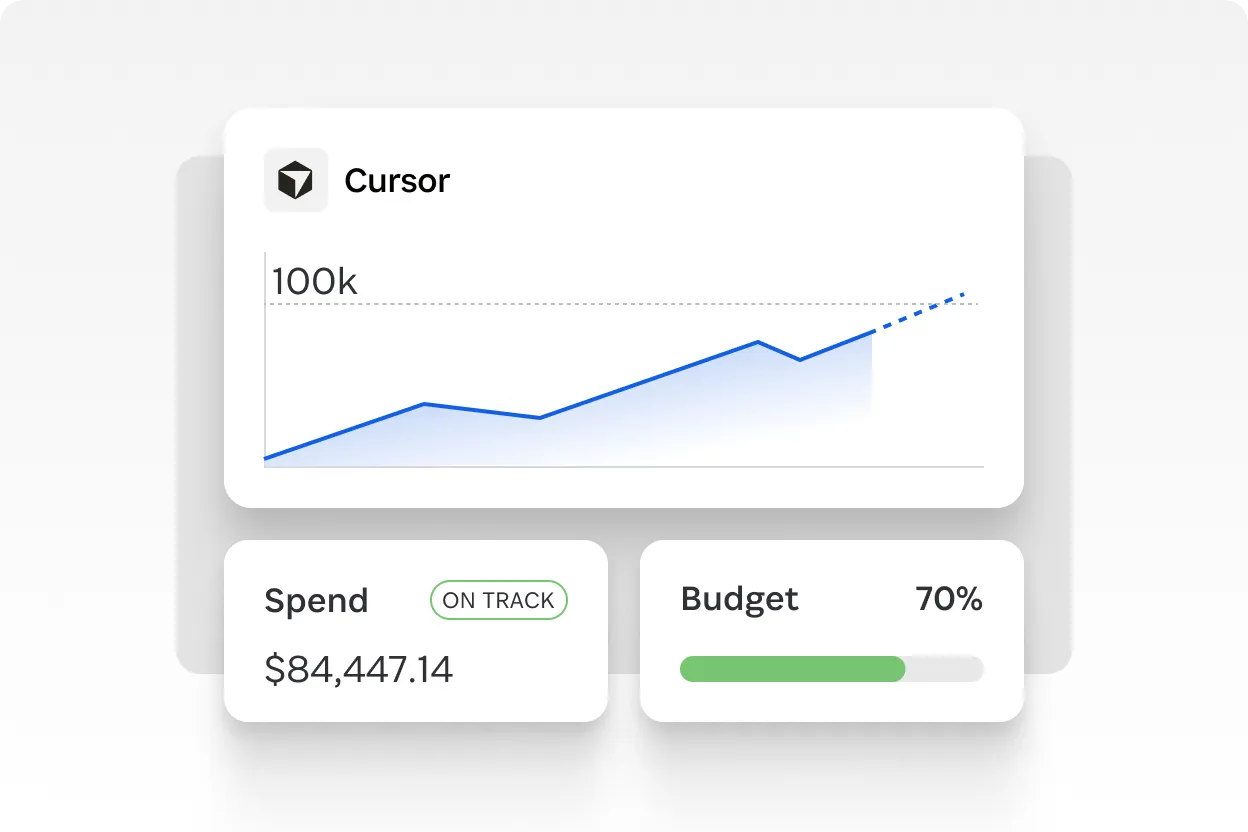
Eliminate unnecessary AI and SaaS spend
AI and SaaS governance requires continuous monitoring of a dynamic workforce. When Zuora onboarded SaaS Manager, they found that 20% of users on paid license tiers hadn't logged in to licensed applications for more than 90 days.
SaaS Manager identifies unused licenses and redundant applications across the entire portfolio, providing IT and procurement teams with a continuous view of opportunities to cut and consolidate spend.
Zuora achieved 10x ROI within six months and reduced license management effort by 90%. "SaaS Manager is a trusted source of information for IT and Procurement," said Paul Heard, Chief Information Officer at Zuora. "We can now maximize the value from our SaaS purchases."
Automate governance for every identity, app, and login
Effective governance requires consistent enforcement of access policies. Teams that rely on manual processes risk inconsistent enforcement, fall behind on access reviews, and create conditions for burnout.
"From onboarding to offboarding, SaaS Manager automates the user lifecycle," Bernard Isibor, IT Engineer at Elastic, told 1Password. That includes automated Slack nudges to inactive users. If they confirm they no longer need access, the license is reclaimed, and the action is logged, without an IT ticket. "We now have full confidence that leavers can no longer access our SaaS tools," said Rusty Searle, Head of IT at Elastic.
Employees can request access through a self-service portal, and IT approves or revokes through a single interface. For the recurring work, pre-built automation handles license reclamation and deprovisioning, with a library of templates covering license-tier downgrades and rightsizing recommendations. IT configures both through a no-code workflow builder. The audit trail generated across every automated workflow takes the manual work out of SOC 2, ISO 27001, SOX, PCI, or other compliance reviews.
Every subscription includes access to the MCP Server for 1Password SaaS Manager. It provides agentic AI systems and LLM-based tools with secure, programmatic access to SaaS Manager’s API, enabling them to continuously ingest data, detect anomalies, and automate governance workflows. With the connection, IT gains visibility into AI agent access events.
We believe that is the standard IT, security, and finance teams will require in 2027.
Ready to evaluate?
SaaS Manager is part of 1Password's Unified Access platform, connecting SaaS governance to the credentials and identities that secure every app in your portfolio. Read the report, or see what IT teams who use it every day have to say.
75 verified reviews
Read what fellow IT professionals say about SaaS Manager on Gartner Peer Insights™.
Read the reviewsWhat SaaS Manager can do for you
Schedule a demo to see how your org could go from app sprawl to governed access.
Schedule a demo2026-06-23, 00:00

Today we're shipping a new capability directly into 1Password Device Trust that lets admins query their fleets faster, without needing to be SQL experts. Now you can describe what you want to investigate in plain English, and Device Trust generates a ready-to-run SQL query you can execute across your devices in a single click.
What Device Trust does
1Password Device Trust gives IT and security teams visibility and control over every device accessing company resources. It continuously checks devices against your security policies, surfacing issues like outdated software, disabled firewalls, and missing encryption, and blocks access when a device falls out of compliance. Under the hood, it uses both osquery and additional proprietary information that collect real-time data directly from endpoints, giving admins a live, queryable view across their devices.
That last part is where this new capability comes in.
The pain with writing queries today
Osquery is powerful, but writing correct, performant SQL takes specialized SQL and DB schema knowledge that most admins don't have on demand, especially during an active investigation. Even experienced users spend time getting syntax right, scoping predicates correctly, and avoiding patterns that are heavy on resources, or return noisy or slow results at scale. This capability clears that barrier while keeping the admin in control.
From question to query in seconds
To use this AI-assisted query builder, open it from the Device Trust Tools section, describe what you want to find, and leverage it to find real-time information across your fleet.
Some examples of what you can ask:
"Check all Windows devices to see if PowerShell is disabled"
"Which devices have AI desktop apps like ChatGPT, Claude, or Cursor installed?"
"Which macOS devices have FileVault disabled?"
"Find devices running Chrome older than a specific version"
"Which devices have remote-access tools like AnyDesk or TeamViewer installed?"
It also works on queries you've already written. Paste existing SQL in the builder and it will tighten your filters, narrow the query to only the columns you need, and recommend more efficient patterns so it runs faster and returns cleaner results.
Transparent by design
Every generated query also allows you to preview the SQL before anything runs. You can review the query before running it and select the devices you wish to run it on, whether that’s a subset of the devices or all of them. For admins who want to sharpen their osquery skills, that output is also a reference for what a well-scoped, efficient query looks like in practice.
Part of how 1Password builds with AI
This is one of several AI capabilities we're building across 1Password’s suite of products, all designed around the same idea: AI should make security teams faster without asking them to give up control. You describe what you need, you see exactly what will run, and you decide what to do next.
Ready to get started?
Check out the __[Device Trust docs](https://support.1password.com/device-trust/)__ page to learn more.
2026-06-23, 00:00

When 1Password announced we were having an AI-themed Hackathon, my first thought was that the content design team had to be involved.
Over the last few months, our content design team saw massive changes not only in tech but also in our ways of working. It felt like everything was shifting to AI all at once: how we designed, prototyped, built new features, and collaborated across teams.
I didn’t want our team watching from the sidelines. Content designers often do great work, but in the margins of larger design projects. This felt like the perfect moment to show how words can shape a great UX experience.
And ironically, being the anointed “wordsmiths” of 1Password’s products is just a fraction of what we do. Content designers shape page structure, look at the information architecture, create journey maps, and are systems thinkers at heart. We look at: what users need to know, when they need to know it, how information shows up, and how each action builds towards the best possible outcome for the customer.
AI lets us take those skills and supercharge them. Content designers can use AI to prototype the flow of information in real time. When you’re building with AI, you can look beyond a single screen or interaction to see how a user’s entire journey unfolds. That’s exactly the kind of thinking that content designers do best, and the Hackathon was our chance to prove it.
The opportunity: Uncovering value in 1Password SaaS Manager
Participating was the easy part. We have a small but mighty content design team which include the talented Amar Majali and Grace O’Neil, who I happily “voluntold” into the hackathon. Our design leadership was genuinely excited to see what three content designers could do with AI. The hard part was deciding what area of the product we wanted to improve.
We tossed around a few ideas but came across a report that struck our interest: the SaaS Manager Savings tracker. It’s a report that shows reclaimed licenses and calculates cost savings. This report is a goldmine for any B2B admin trying to evaluate the value of their investment in 1Password SaaS Manager.
Let’s take, for example, an imaginary B2B admin. We'll call him Jerry.
Like most admins, Jerry wears a lot of hats. He’s responsible for optimizing SaaS spend, he prepares for renewals and budget reviews, and he needs to communicate the value of tooling to his executives. The Savings tracker can help him come up with that value, but it’s buried inside the product. Even if he was to find the table, sharing it with his team wouldn’t be an automatic home run, since it’s all numbers with little context.
For the three of us content designers, this is where the lightbulb went off. We already had the raw materials from the report. Our challenge was making it easier for Jerry to show how 1Password was saving his company money. If you haven’t guessed it from Jerry’s name, we lovingly called our Hackathon project “Show me the money.”
The name was a bit cheeky, but it summed up the design problem nicely: how might we make SaaS Manager’s value impossible to miss and effortless to prove? The team needed to use our UX thinking to answer three core questions:
How does Jerry easily discover the value of his savings? (aka “the money”)
How can he optimize to save more money?
How can he share wins with his team and stakeholders?
We quickly realized that answering these questions required us to think about Jerry’s entire journey, and find opportunities to AI most effectively.
What we learned
For a hackathon team with zero engineers, creating a workable prototype was a tall order. Our team set out to build a vibe-coded prototype hosted on the Knox playground (a playground created by our amazing Design Systems team). This meant getting set up in GitHub and Cursor, setting up our branch so we could collaborate, and entering commands in terminal while praying that it all worked out.
As cliché as it sounds, we were building the plane while flying it: learning how to be pseudo developers while still using content design thinking to build out Jerry’s experience. If I’m being completely honest, it was messy and occasionally terrifying. But somewhere in the chaos, the team stopped worrying about whether we were entering the right Git commands and started learning how to build together.
Here’s what we learned:
Learning 1: Alignment beats chaotic building
With great power comes great responsibility, and using the Cursor agent felt dangerously powerful. With the right prompt, we could spin up any component or design we could think of, and the urge to vibe-code everything all at once was very tempting.
In theory, this is great when working solo, but as a team it gets chaotic fast. It’s easy to lose sight of who’s changing what and where, while trying to understand the UX rationale behind the decisions they’re making. Our team quickly realized that we needed to sit down and align on “what good looks like” for Jerry’s journey. Using a Figjam board, we huddled on key questions to understand where in the journey we wanted to make changes:
What do we want to show? Total savings month-to-month.
Where do we want to show it? Front and centre on the admin dashboard (not buried in a report).
How do we want it to show up? A number that shows real-time savings with a graphic.
How do we want Jerry to feel? We want to spark delight. Let’s do something to celebrate milestones for big savings.
Why does it matter? Let’s make sure Jerry can easily share the savings with context to his team or executives. If he wants to dig into the numbers, let’s direct him to where he can find the Savings Tracker.
Answering these questions helped us align on what we needed to build upfront to move fast later. It also helped us envision what sort of story we want to tell as Jerry sees his savings grow.
Learning 2: Don’t eat the elephant all at once
Once we knew what parts of the journey we wanted to change, we set out to divide and conquer. Each of us owned a piece of Jerry’s journey:
Amar built the shareable report experience to show Jerry’s wins to stakeholders.
Grace built the celebratory moment for when he hit a savings milestone.
I built the scaffolding, starting with the dashboard card and then the seat optimization flow.
For each of us, we learned the hard way that big prompts, like ones asking the agent to build out an entire report or dashboard card, led to ambiguous results. Instead, it was easier to work in small, iterative prompts. For example, I asked the agent to duplicate an existing card, explained the new card's purpose (tracking savings), and then asked the agent to design a visual to accompany the card.
Each small iteration allowed us to see how our UX rationale held up or where we could make improvements. For the dashboard card, my team member Grace was able to iterate on the visual to make a graph with a slider that shows savings month-by-month. The original static visual would’ve worked, but seeing it move in real time made it obvious how much more valuable a dynamic version would be to Jerry’s journey.
Learning 3: AI demands more collaboration, not less
Contrary to the popular assumption, working with AI made us more dependent on collaboration. Alignment gave us direction, iteration kept us moving, but collaboration is what held the two together.
Since the three of us were working on one branch, we had to huddle constantly on Slack or Zoom to discuss new changes or pivot when parts of the plan didn’t work out. When one of us pushed their changes, we had to let the others know so they could pull the latest designs. When something broke, it was easier to figure it out together than trying to use Claude to troubleshoot on our own.
Demo Day
On demo day, we had two minutes to share a video of our workable prototype. The team knew the value of the feature we were building and why it’d be helpful for B2B admins like Jerry. We just needed to bring our audience along the same journey. In truth, we needed to make them feel Jerry’s dilemma as much as we did.
So instead of walking through the feature, we incorporated the actual “Show me the money” clip from Jerry Maguire. Yes we were trying to be funny, but also it was the exact thing real admins would hear from their stakeholders: show us how 1Password is saving us money.
We introduced Jerry from the clip and then showed how our prototype helped him:
Surface savings instantly
Understand where and how to cut costs
Celebrate when he hit a big milestone
Share that story with his stakeholders to land a promotion
We didn’t know if our unorthodox demo would resonate with an audience that was mostly technical, but we did what content designers know how to do best: tell a good story.
Where we landed
In the end, the gamble we took with the movie clip paid off. Our “Show Me the Money” project won the Customer Impact Award and was runner-up for Bit’s Choice. We’re also working to get a first iteration of the dashboard card and graph into SaaS Manager this year.
Before that hackathon, I was worried that the content design team might get left behind or stuck on the sidelines of the AI shift. The hackathon put some of that worry to rest. While it proved we could vibe-code solutions, our team also realized that our skills as storytellers offered a new way of thinking and building.
In the end, while AI helped us build faster and more independently than we could have before, what made this project a success are the human qualities that AI can’t supercharge: deep UX experience and instincts, nuanced context about our customers and our business, and the ability to reference ‘90s pop culture.
The funny thing is that the UX superpower of content designers was always there. We’ve always helped shape the product vision: asking the right questions during user research, creating lo-fi sketches, and even defining product terminology and names. But now we can take it further. We can design content-first, and bring it all the way to the build.
For any content designer wondering whether this space is for them... it is. Your instincts about clarity and story are exactly what AI-assisted builds are missing.
2026-06-17, 00:00

AI agents now write code, fix bugs, and ship to production. But in order to do useful work, agents require credentials. At 1Password, one of our core AI security principles is that raw credentials should never be directly exposed to LLMs, but all too often, that’s exactly what happens: most teams sacrifice security for speed and hand agents secrets in plaintext.
The shortcuts behind that tradeoff predate agentic development: secrets packed into an .env file, a script with hardcoded keys, a config file committed to a repo. But agentic development exponentially increases the blast radius of an exposed or misused credential, since anything in an agent's context window can be logged, echoed into output, or surfaced by an agent that's been manipulated into revealing it. Solving this tension means giving agents the access they need without directly exposing credentials to the model context.
Today we're expanding the 1Password MCP Server to Kiro, making 1Password the trusted access layer for AI-powered development in Kiro. With this integration, credentials are issued at runtime, scoped to the assigned task, and never enter the model's context window. Agents get the access they need, and secrets stay where they belong.
What this integration does
Kiro is a software development agent, available in IDE, CLI or web experiences, bringing engineering rigor to AI-native coding via spec driven development and property-based testing. This integration connects Kiro directly to 1Password Environments using a local MCP server packaged inside our Password Manager developer tools. It's available on 1Password business and personal accounts.
With this integration, developers can:
Configure environments securely inside Kiro. Ask Kiro to create and configure an environment, then run applications using secrets stored in 1Password Environments instead of plaintext .env files, all without leaving Kiro.
Clean up hard-coded secrets. Have Kiro find credentials in source code, move them into 1Password Environments, and replace them with references, which cuts down secret sprawl across projects.
Give AI workflows scoped, runtime access. Credentials are issued for the assigned task only. When the task ends, the window closes, and the credential can no longer be used for access. Centralized credential management in 1Password stays intact throughout.
That third capability is the one that matters most: access granted at the moment of need, scoped to the task, gone when the work is done. It's how all access should work as agents take on more of the job, whether the requester is a developer, a CI/CD pipeline, or an agent acting on someone's behalf. The principle that governs an agent touching production infrastructure governs the agent in your IDE.
For engineering and security teams, the administrative picture doesn't change. High-value credentials stay under centralized control in 1Password, so teams can support Kiro adoption without loosening governance.
The secure path here is also the easy path, and that's a deliberate design choice. Developers will adopt this workflow because asking Kiro to use 1Password Environments is less work than manually managing .env files. That's the security philosophy 1Password has had for twenty years: security wins when people choose it, and people choose what removes friction.
The same architecture, a broader surface
When we launched the 1Password Environments MCP Server with OpenAI Codex, we called it a proof point for a broader thesis: coding agents are the leading edge of AI agents joining the workforce, and they need real access, governed properly. Kiro is the second proof point, built on the same architecture and the same access model.
As AI-native development tools multiply and demand credentials, we will extend the architecture underneath this integration to new solutions. Whether developers are working in Codex, Kiro, or whatever ships next, the access model doesn't change: 1Password is the source of truth for secrets, credentials are issued at runtime, nothing in plaintext in the model context.
"Kiro is designed to help developers move from idea to production-ready software with AI assistance grounded in specifications and structured workflow. By bringing secure access to secrets and environment variables directly into Kiro, 1Password is helping developers confidently adopt AI-assisted workflows while keeping credentials secure and under their control."
--Mark Relph, Managing Director, Data & AI Partners at AWS
"Developers shouldn't have to choose between adopting AI-powered tools and strong security practices and neither should their agents. Every place software gets built is now a place an AI agent needs access. Our answer is the same everywhere: credentials stay protected in 1Password and are issued at runtime, scoped to the task, with nothing left in plaintext for a model to see. Kiro extends that model from Codex to another surface where developers actually work, and it's a preview of how we think all agent access will operate."
--Jeff Malnick, VP and GM for AI & Developer at 1Password
Part of a broader collaboration with AWS
This launch is one piece of a larger integration footprint across AWS. 1Password already secures access across AWS environments through Amazon Nova Act, the MCP Server for 1Password SaaS Manager, the AWS CLI shell plugin, and AWS Secrets Manager sync. Kiro extends that work into agentic software development.
How to get started
This integration is available to joint 1Password and Kiro customers on 1Password business and personal accounts with access to our Password Manager and developer tools on macOS.
To get started, visit Kiro powers or 1Password Marketplace for setup instructions and documentation on connecting Kiro to 1Password using the local MCP server.
2026-06-16, 00:00

"The hardest thing in security is always the chaos," according to Travis McPeak, Head of Security at Cursor. He shared this with Nancy Wang, CTO of 1Password, and Dev Tagare, Senior Director of Engineering at Google, on a recent episode of Zero-Shot Learning, the podcast about how AI gets built, secured, and deployed. "We're always going to have more that we have to be doing than we can actually do."
Travis has worked within that constraint in security roles at Netflix and Databricks and now at Cursor, the AI-native IDE, where agents write production code for a rapidly growing base of developers worldwide.
Agents in the development pipeline introduce a new kind of actor. They are non-deterministic, have access to tools, are exposed to untrusted input, and often operate near credentials, source code, and production systems. All with no guarantee that past behavior predicts future actions. Unlike developers who earn trust through accountability and predictability, agents offer neither. Sitting down with Nancy and Dev, Travis said that the only way to secure agents is to design secure-by-default workflows so that when they inevitably misbehave, the damage is contained.
Security can pick winning battles
Security teams are still grappling with how to classify and manage agent identities, but businesses aren't waiting to adopt AI and agentic tooling. The 1Password Access-Trust Gap Report found that 73% of employees are encouraged to use AI for some part of their workload. But policy enforcement clearly isn’t keeping up, since 37% say they only follow company AI policies "most of the time."
Travis embraces speed as a simple fact of the modern tech business model. "Security teams exist to serve the business. Your job is to do the best risk minimization that you can within the amount of slowdown that a business will tolerate. I'm in ‘ship, ship, ship.’ I want the company to thrive," he said.
Moving at the speed of business means that security teams often have more on their plates than they can achieve, and in that situation, the fights worth choosing are the ones that can be automated. Travis has found success in embedding security policy as code because LLMs can generate, review, and deploy it without a human in the loop.
With LLMs, production no longer hits a human bottleneck. "We have these wonderful tools that operate very well on anything text-based," he said. "If you can do configuration as code, the LLM can produce it, independent LLMs can review it, and once everything's good, it just gets auto-deployed." When systems operate in a secure-by-default mode, security travels with the code, and teams can work without a checkpoint slowing them down.
The 1Password Hook for Cursor is part of this approach because it embeds security at the credential layer. Secrets are available to Cursor only when needed, in memory, never written to disk or Git history. Access is controlled by design, and teams can work without worrying about accidentally committing secrets.
Did we ever trust developers to begin with?
The concept of least privilege was designed to reduce risk. Give any principal the minimum access they need so when something goes wrong, the damage is limited. "Developers weren't mega-trusted in the first place," Travis says, "not because they're bad people, they just have other priorities." Agents are no different. They're executing a task, not managing their own access. The non-deterministic nature of agents makes a least-privilege approach essential, because something will eventually go wrong.
I still think people don't understand how non-deterministic these systems are… An agent could behave exactly as expected across dozens of runs and then do something completely different for no apparent reason. You always have to treat an individual agent as untrusted, especially if it has access to something that really matters."
–Travis McPeak, Head of Security, Cursor
Agents also process external content like emails, documents, and tool responses, and an attacker who controls that content can embed instructions the agent will follow as if they came from its legitimate operator. This is the architectural problem that made SQL injection effective, there was no boundary between the developer's instructions and user input. Prompt injection works the same way; there's no wall between an agent's instructions and the content it processes.
"We never got the separation of control plane and data plane right in the history of computers," Travis said. "We set up the agent in a hurry because it's gonna be so cool, and we forgot to put safeguards, guardrails, logging, anomaly detection."
With agents, a missing guardrail doesn't stay in one transaction. It executes automatically, across every run, at machine speed.
Where traditional IAM falls short
Traditional IAM has been a relatively successful permissions system for human identity management, but it’s not without limitations. "It's a great technology, honestly. Probably the best implementation of this thing," Travis said. The problem is usability, "Even I have dealt with it for years. How does this condition work? What's the syntax? It's just so hard for anybody to understand."
While IAM was built for people, service accounts, API keys, and machine credentials were never part of that governance model. Non-human identities have always existed outside of IAM and SSO, where they’re provisioned ad hoc.
To keep work moving, engineers grant broader permissions than necessary to avoid debugging policy errors.In the enterprise, non-human identities already outnumber humans, and many have unaudited, overprivileged access.
Agentic non-determinism compounds the problem. Traditional IAM assumes you can define what a principal needs upfront, but an agent whose behavior is inherently unpredictable can't be governed by a static policy.
At Netflix, Travis built a project called RepoKid around the idea that you can't specify least privilege correctly up front, but you can observe your way to it. In their efforts, Repokid granted slightly more access than what was needed, watched what got used, and cut the rest. The 2026 version for agents starts from the opposite direction.
We want to have standing no permissions, or least permissions. And then, based on the actual agent, its profile, and what it's supposed to be able to do, there should be a requestable, auditable set that it receives. You definitely want to know what it was granted and what it actually ended up using. And then there should be an escalation path." –Travis McPeak, Head of Security, Cursor
Without the escalation path, an agent hard-blocked mid-task either fails silently or stalls. With it, the agent can surface unexpected needs and route them to named approvers. Travis details the use case: "My agent's working on something. If it just gets hard-blocked, it might stall out. But if it flags an unexpected need, access to the CEO's salary data, something it's never asked for before, there should be a defined set of approvers who can grant it.”
Securing agents requires a model that starts at zero, grants by profile, and enforces access decisions at the boundary rather than upfront. In his example, the grant, the usage, and the escalation would all be documented.
Still talking like it's 2019
Nancy closed the conversation with a pointed observation, "A lot of teams these days are still talking about security and workflows like it's 2019."
The access model most enterprises rely on wasn’t built for non-deterministic agents. 1Password Unified Access is built to extend identity security to non-human identities. It discovers AI tools and agents running across developer endpoints, delivers credentials at runtime rather than pre-provisioning them, and provides full attribution for every access event across humans, agents, and machines.
Listeners to this episode inevitably came away with a clear question: Is your access model built for non-deterministic agents?
Securing agents requires a model that starts at zero, grants by profile, and enforces access decisions at the boundary rather than upfront. In his example, the grant, the usage, and the escalation would all be documented.
Still talking like it's 2019
Nancy closed the conversation with a pointed observation, "A lot of teams these days are still talking about security and workflows like it's 2019."
The access model most enterprises rely on wasn’t built for non-deterministic agents. 1Password Unified Access is built to extend identity security to non-human identities. It discovers AI tools and agents running across developer endpoints, delivers credentials at runtime rather than pre-provisioning them, and provides full attribution for every access event across humans, agents, and machines.
Listeners to this episode inevitably came away with a clear question: Is your access model built for non-deterministic agents?
Watch the full episode with Cursor's Travis McPeak
Travis McPeak, Nancy Wang, and Dev Tagare on Zero-Shot Learning.
Watch nowStart building with the 1Password Hook for Cursor
Secrets in memory, never on disk, available only when Cursor needs them.
Get started2026-06-16, 00:00

At 1Password, we regularly invite outside experts to challenge our assumptions and strengthen our security. We encourage security researchers to participate in our bug bounty programs, and have spent years building a collaborative research environment. We also believe in the benefit of open source software and standards, which raise the bar for the industry as a whole, while ultimately benefiting our 1Password customers.
That’s why we funded an independent security assessment of the open source library Snow, worked closely with the maintainer on remediation, and are making the results publicly available for anyone to review.
Where to read the report
The results of the independent security assessment are available now for anyone who wants to learn more.
Read the reportWhy we invested in Snow
Snow is a Rust implementation of the Noise Protocol Framework, a system for building secure channels using customizable cryptographic handshake patterns based on Diffie-Hellman key exchange. We rely on Noise-protected channels in parts of 1Password. Since Snow gives Rust developers an implementation of that framework, that makes it, for us, part of the security foundation we care about getting right. Funding validation on Snow allows us to improve something we care deeply about while giving back to the open source community that helps make 1Password possible.
We are active contributors to Snow. The pull requests we’ve opened and the independent security assessment we funded reflect our commitment to helping strengthen the project.
What Trail of Bits found
Trail of Bits reviewed Snow through a combination of manual review and automated testing over four engineer-weeks. Their report identified 10 findings in total: one medium-severity issue, one low-severity issue, and eight informational findings. The most important issue discovered was a nonce-handling bug that could let an attacker permanently disrupt an encrypted channel without knowing any cryptographic secrets. Another finding showed that invalid PSK indices could trigger a panic, creating a denial-of-service condition.
For more details on the engagement, including the informational findings, please read the published security assessment.
We then worked with Jake McGinty, the Snow maintainer, to remediate the issues, and with Trail of Bits to validate the fix. To date, 8 of the 10 findings are resolved, including the medium-severity nonce-handling flaw, the invalid-PSK panic, message-length enforcement. Two longer-horizon informational items remain and we believe neither impact the security of the Snow library.
What’s next?
Thank you
We want to say thank you to Trail of Bits, and especially Joe Doyle and Tjaden Hess, for the assessment and review. We’re also grateful to Jake McGinty, the Snow maintainer, for partnering on remediation, providing real-time assistance during the testing, and helping turn the report into concrete improvements.
Open source security work is most valuable when it doesn’t stop at identifying problems. Funding an audit with transparent results matters, but working with maintainers to responsibly land fixes matters even more. That is how we help raise the security bar not just for one company, but for the larger community that depend on the same foundational building blocks.
If you’re building in Rust and need the Noise Protocol Framework, take a look at Snow. Read the audit, review the code, and try it in your own projects. Open source becomes stronger when more developers use it, test it, and invest back into it. We’re excited to see what you build.
2026-06-16, 00:00

One of the less surprising findings of the 2026 Verizon Data Breach Incident Report (DBIR) is the fact that incidents targeting the Financial and Insurance sector are on the rise. As they put it, “This sector continues to be a favorite among attackers, which isn’t surprising given that its core business is handling money.”
For small-to-medium businesses (SMBs) in the financial services sector, the DBIR paints an even more dire picture. The report notes that SMBs face the same threats and breach patterns of larger organizations, but are also disproportionately impacted by attacks; 96% of ransomware victims were SMBs.
In short: businesses in the financial services industry who are still building their foundation, or who possess limited security resources, are caught between a rock and a hard place. They operate within one of the most heavily targeted sectors for cyberattack, and are held to enterprise-level security standards by regulators and clients alike, but they’re operating with startup-level security resources.
For lean security and IT teams to make the most of those limited resources, they need to focus on what they can afford. That means getting the fundamentals right for a strong and impactful security foundation. The highest-leverage fundamental is, of course, credential management.
Top security challenges for financial services organizations
Small IT and security teams in the financial services industry are faced with high expectations when it comes to security. Unfortunately, they also experience significant challenges when it comes to securing credentials.
AI is accelerating SaaS and credential sprawl
JP Morgan Chase’s recent research report, Understanding the use of AI among small businesses, finds that not only are a growing number of small businesses adopting AI, when they do, they also tend to implement a greater number and variety of AI tools.
It’s not hard to understand why this is the case; AI’s ability to automate processes and improve productivity is a natural fit for lean teams, trying to maximize impact with limited resources. However, AI tools and agents are also accelerating the rate of SaaS sprawl, shadow IT, and policy violations. One in four employees has used AI applications that weren’t approved by their company, and over a third of employees admit to having knowingly disregarded their company’s AI policies.
AI is also increasing the sophistication of attacks. Attackers are able to move faster, and are particularly able to generate more convincing phishing attacks. Unfortunately, phishing-resistant authentication factors are hard to deploy at scale. As RSM reported, “Many middle market and smaller financial services organizations lag their larger counterparts in this area.”
AI use can also drastically accelerate credential risks, as AI tools and agents interface with credentials and developer secrets at a scale far beyond what traditional identity and access management (IAM) systems were designed to govern.
Complex compliance standards
Cybersecurity compliance represents one of the greatest challenges for businesses of all sizes in the financial services industry. SOC 2, GLBA, and PCI DSS are just a few of the compliance standards with strict guidelines designed to protect financial information.
These standards exist with good reason; when financial data is compromised, the consequences can be dire for companies and users alike. Still, the complex and varied legal and compliance standards that financial service providers have to meet can be daunting, to say the least, particularly when access is distributed across a growing sprawl of unmanaged apps and credentials.
For instance, to meet standards like GLBA, HIPAA, and PCI DSS, teams have to be able to prove to an auditor that every system or app that interacts with protected data is being guarded by strong credentials and other authentication factors.
Unfortunately, 1Password’s 2025 annual report found that two-thirds of employees admit to engaging in poor password practices, including:
Using the same passwords across multiple work accounts
Never changing IT-default passwords
Using the same password for both work and personal accounts
Texting, emailing, or otherwise messaging passwords to yourself or a colleague
Each of these practices fly in the face of compliance guidelines. Unfortunately, scattered security tooling and unmanaged sprawl can make it difficult to enforce policies around password use, leaving access records fragmented at best, or non-existent at worst.
All of this can make it difficult to prove compliance to the satisfaction of an auditor, and compliance failures can represent significant costs. A survey in 2026 found that 25% of small business owners stated that they had received a compliance-related fine or citation. As they reported, “Most penalties totaled between $2,000 and $10,000…”
The cost alone is a serious detriment, but the report goes on to point out that these failures represent further disruptions for small teams. “Beyond paying fines, businesses also had to modify internal processes, update documentation practices, or implement new tracking systems to prevent repeat violations.”
Insider threats are a major concern
Smaller IT teams often have limited time to ensure that every new employee is given the right level of access according to their role, and to ensure that every departed employee is properly offboarded from systems. This can leave lingering credentials with over-privileged access to sensitive data.
Over one-third of employees have successfully accessed a prior employer’s account, data, or applications after leaving the company. The insider threats posed by this statistic should be of particular concern to financial services institutions.
In 2024, more than 70 percent of financial institutions experienced insider threat incidents that year, referring to both deliberate actions and inadvertent errors. In 2026, misconfiguration or human error was the leading cause of breaches for those organizations.
AI’s difficulties are accelerating these kinds of errors as well, but the more significant issue is that for businesses that are still building their security foundation, access controls are often informal, and employee lifecycle processes are inconsistent or overly manual.
Traditional security tools can’t serve the needs of growing businesses
Unfortunately, traditional security tools are often unsuited to meeting the needs of growing businesses, particularly those with strict compliance requirements. For instance, when teams think of securing access, single sign-on (SSO) is one of the first solutions that come to mind. Unfortunately, SSO also leaves serious gaps in oversight; 1Password’s recent annual report found that the average company has a third of its apps outside SSO.
For smaller companies, or those with otherwise limited resources, SSO is likely to leave even more oversight gaps. The infamous “SSO Tax” means that for an application to be guarded behind SSO, app providers often force customers to upgrade to an “enterprise tier.”
Not only does the enterprise tier tend to cost exponentially more per user than the basic tier, it may require a minimum number of users for the plan. Even if an SMB has the budget to put a given app behind SSO, they may not have enough users to.
SSO is just one example of how traditional security tooling falls short of meeting the needs of SMBs, leaving significant gaps in a team’s app and credential oversight. This lack of resources can often result in a scattered approach to credential management, where credentials are stored in spreadsheets, shared over email, or saved within consumer browsers.
This level of credential sprawl is overwhelming and costly, compromising compliance efforts while drastically increasing a company’s attack surface. But if a business is hit by a breach, the financial losses can quickly reach the millions, leaving teams caught in a dilemma between costly security versus costly risks.
How credential management helps meet financial compliance requirements
An enterprise password manager (EPM) like 1Password’s is one of the most effective and efficient security tools that any business can implement. An EPM centralizes visibility into how and where credentials are used, enabling secure sharing and access that can be granted and revoked as needed. 1Password EPM enables IT and security teams to organize credentials into vaults and provision or revoke vault access according to employee roles and access needs. This benefits both security and productivity; after all, autofilling passwords from a shared vault tends to be easier than searching for them through a spreadsheet.
1Password utilizes zero-knowledge encryption, meaning that not even the company that’s storing credential data can access or decrypt it. This keeps information protected at the highest level, so credentials stay secure even if the server where they’re held ever gets breached. 1Password's breach monitoring also informs users and admins if a managed credential has been compromised in a breach (since re-use of compromised credentials is a major attack vector).
Most significantly, 1Password provides automated and detailed logs of app sign-ins and other events, ensuring that small teams in the financial services industry are set up for success when it comes time for an audit.
In short: the credentials to every workplace app stay secured and centralized where IT can easily oversee employee access and measure the strength and security of their password ecosystem. It’s a tool that works with small teams, empowering them to use the tools they need without putting sensitive data at risk.
Learn more
Do you have twenty minutes and want to learn more? Try out 1Password’s [__on-demand demo__](https://1password.com/webinars/enterprise-password-manager-demo), or look through our [__“Secure in 20”__](https://1password.com/secure-in-twenty) series for quick and informative sessions on security for modern teams.
2026-06-15, 00:00

Over the past two decades, 1Password has earned the trust of millions of people, more than one million developers, and over 180,000 businesses by helping them secure one of the most fundamental elements of digital life: identity.
Today, I’m thrilled to share that 1Password has acquired Apono, and I want to explain why this matters so much to us.
Identity is changing.
For years, the model was straightforward. Humans logged in, systems responded. Credentials verified who you were, and access controls determined what you could reach.
That world is changing quickly.
Software is now acting on our behalf. Machine identities far outnumber human identities. AI agents are beginning to retrieve data, execute workflows, provision resources, and make decisions across enterprise environments. The number of actors inside organizations is growing fast, and the systems governing identity and access were not built for this new reality.
This is what we hear from customers every day. Businesses of all sizes and their security teams are struggling to get the full leverage of their AI investments while managing the risks brought about by non-deterministic agents accessing critical systems. Organizations want to move faster with AI, but they need confidence that every identity, whether it belongs to a person, a machine, or an agent, is continuously verified and governed consistently. They need to know not only who is requesting access, but what that identity should be allowed to do, under what conditions, and for how long.
That challenge is exactly where Apono fits.
1Password has long been the vault that enterprises and their users relied upon to keep their secrets safe. With Apono, we become the access layer.
For 1Password Unified Access, this is an important step forward. We already help organizations secure credentials, manage access to SaaS applications, strengthen device trust, and broker credentials at the moment they are needed. Apono's just-in-time privileged access governance completes the picture.
What impressed us about Apono was not only the technology. It was the clarity of the team’s thinking and the people behind it.
The Apono team recognized early that standing access is increasingly incompatible with modern infrastructure. Cloud environments change continuously. Workflows happen in real time. Access can no longer be provisioned broadly and left in place indefinitely.
Apono built its platform around Zero Standing Privilege by default. Access is granted when it is needed, scoped to the task at hand, and automatically revoked when the work is complete. Every grant carries a clear audit trail. The result is stronger security, greater accountability, and less operational burden for teams that need to move quickly without sacrificing control.
Just as important, Apono understood that the future of access extends beyond humans. The same governance principles that apply to employees and contractors will increasingly need to apply to machine workloads and AI agents as they become active participants in enterprise systems. That is a challenge we are building toward together.
At the same time, we are also introducing 1Password Credential Broker, now in private beta.
Credential Broker keeps credentials protected inside 1Password’s vault and releases only an approved credential, token, or federated access to a verified requester at the moment it is needed. That helps prevent long-lived secrets from spreading across apps, repositories, and pipelines.
Apono and Credential Broker solve two connected parts of the same problem. Credential Broker protects where credentials live and how they reach a trusted identity. Apono governs what an identity is permitted to do once access is granted, and for how long.
Together, they create a strong foundation for trusted access. One protects the credential. The other governs the action. Both are essential in a world where people, machines, and AI agents increasingly work side by side.
I also want to say a word about the Apono team.
We have spent a lot of time with Rom Carmel, Ofir Stein, and their team over the past several months. Beyond the strong character, thoughtfulness, and technical expertise, we discovered significant alignment in our vision and values. The more we talked and worked together, the clearer it became that we share a belief about where identity security needs to go. Security should create confidence, not friction. Access should be earned, scoped, and accountable. And as AI becomes part of how work gets done, people need to stay in control.
The Apono team brings deep expertise in privileged access, a strong customer focus, and a builder mindset that will make 1Password meaningfully better. I am thrilled to welcome Rom, Ofir, and the entire Apono team to 1Password.
The next era of identity security will not be defined only by who has access.
It will be defined by how access is granted, governed, and trusted.
That is the future our customers need, and we are excited to build it with the Apono team.
2026-06-15, 00:00

Right now, somewhere in your organization, a service account token is sitting in a CI/CD environment variable with access to your entire cloud environment. The job it was created for got deleted three sprints ago, and nobody knows it's still there.
Unfortunately, that’s not just a worst case scenario. For many teams it's a byproduct of how they manage credentials today. Someone in your organization creates a token, scopes it broadly to avoid any last-minute permission errors, drops it into a config file or a pipeline environment variable. They assume someone else will track it down to revoke it when the work is done. That assumption is almost always wrong, and the tokens and overprovisioned access accumulate.
Machine identities now vastly outnumber human identities across most enterprises, and AI agents are growing faster and are governed less than almost anything else in the stack. The attack surface keeps expanding, and most teams are still managing credentials and access with the same approach they used five years ago.
1Password has spent more than a decade building what we believe is the best credential vault for humans. More than 180,000 businesses trust us to protect their most sensitive credentials and secrets. Now we're extending that same foundation to the machine workloads and AI agents.
Introducing 1Password Credential Broker
Our new 1Password Credential Broker extends what you can do with 1Password, from storing credentials and secrets to brokering them at runtime: delivering the right credential to the right workload at the moment work actually needs to happen.
A machine workload or AI agent shouldn't hold credentials it doesn't currently need. It should prove who it is, get exactly what policy allows, and lose that access when its job is done. 1Password Credential Broker does exactly that, using the same 1Password vault, policy controls, and audit tools your team already relies on.
Our initial beta focuses on GitHub Actions, which handles more than 6 billion workflow runs per month and is used by more than 90% of Fortune 100 companies. That's where most enterprise CI/CD already lives, so that's where we started.
How it works
When a GitHub Actions workflow runs, GitHub automatically generates a signed token confirming exactly which repo, branch, and workflow is executing. Think of it like a digital badge: here's what this job is and where it came from.
This is what the industry calls Workload Identity Federation. It's a standards-based approach that GitHub, Google Cloud, AWS, and Azure have all adopted, and it's the foundation 1Password Credential Broker is built on. Instead of a long-lived token or a service account password, the workload proves who it is with a signed, platform-issued credential. 1Password validates that credential against a trust policy you configure, then delivers exactly what that job is approved to retrieve, nothing more.
That means there's no credential to distribute, store, or rotate, and the workload never receives standing access to the vault. It only gets the credential it needs, at the moment it needs it. So if a pipeline is ever compromised, an attacker can only reach the one credential that job was authorized to retrieve, not the entire vault.This is how we help you close the gap that service accounts leave open.
Best of all, every access event is logged with full attribution: the repo, branch, workflow, environment, and commit that triggered the request. Your audit trail no longer says "a service account accessed this item." It tells you exactly which workload accessed it, from where, and on behalf of whom.
What the beta covers, and what's coming
The Credential Broker private beta covers GitHub Actions, with job-scoped access windows, item-level scoping within the vault, and full attribution logging on every credential request.
Right now, the Credential Broker covers a specific but important part of the credential lifecycle. When a workload pulls a credential from 1Password, how long that credential lives in the upstream system still depends on that system's own policies. A database password pulled from 1Password may still be long-lived in the database it connects to. Automatic rotation isn't in this release. What this release does remove is standing vault access, and every job gets scoped to exactly the credential it needs. That's a real, meaningful reduction in blast radius, and we will continue building on this foundation.
Later this year, we’ll be extending Credential Broker to AI agents. Today, when an AI agent needs to take action (querying a database, calling an API, writing to a business system), it typically gets handed a long-lived OAuth token. That token usually has no expiration date, and can accumulate permissions over time. If the agent drifts or is compromised, you often don't have a clean way to stop it, audit what it touched, or determine who was accountable for its access.
With our Credential Broker, an agent requests a short-lived token scoped to the specific task at hand. When the task is done, the token expires. The agent never holds a refresh token, so it can't quietly extend its own access without policy you define approving it again. With this addition, every request will be logged with the agent's identity, and the identity of the person on your team who delegated the task. That gives you a clear, auditable chain from action back to authorization.
For security leaders, the concern with AI agents usually comes down to three questions: who authorized this agent to access this system, what did it touch, and can you revoke it without breaking the workflow? With Credential Broker, you can confidently answer all three.
Before you can govern AI access, you have to establish AI identity. That's what we're building toward.
Part of the 1Password Unified Access platform
The 1Password Credential Broker is part of our Unified Access Platform, which lets you discover, secure, and audit access across humans, AI agents, and machines from a single system you already trust.
Our Credential Broker extends that foundation to machine workloads and agents. The vault governance and audit trail that already covers every human credential in your organization now applies to the pipelines and agents running alongside your team. There's no separate secrets management infrastructure to bolt on, and your team manages everything from the same 1Password interface they already use across Windows, Mac, Linux, and mobile.
Join the private beta
1Password Credential Broker is in private beta starting June 15, 2026, with GA targeted for late 2026.
If you're interested in early access, you can sign up here.
To learn more, visit the 1Password Credential Broker page.
2026-06-12, 00:00

Anyone who thinks security leaders are humorless sticklers for the rules has never spent half an hour with Jaya Baloo. But in this episode of Chasing Entropy, Dave Lewis does just that, and the result is a frank and irreverent conversation that proves that security may be serious business, but it’s still a fun job. Baloo is the co-founder and COO/CISO of Aisle, an AI-powered vulnerability management startup with the bold goal of “zero exploitable vulnerabilities.”
Baloo’s career has spanned telecom, cryptography, enterprise security, and AI-driven security research, but her love of computers started when she got her first computer (a Commodore 64) at age 9. The conversation tracks her journey from early BBS war dialing and CompuServe stories to the modern challenge of defending organizations against increasingly autonomous systems.
A major focus of the episode is the growing hype around AI-powered vulnerability discovery. Baloo acknowledges the seriousness of the threat, saying “It introduces this asymmetry in terms of attacker-defender advantage, where the advantage would strongly go to the attacker if they’re capable of finding new and novel vulnerabilities, and the ability to exploit them, and potentially doing this at scale, autonomously.” However, she cautions that fear of a Mythos-level model shouldn’t leave security leaders feeling too overwhelmed to take action. “We have elevated this to a level of hype that is not that beneficial to actually doing something about the problem.”
Instead of panicking about the unknown, Baloo advises security to start by addressing the problems they are aware of. Organizations already struggle with asset visibility, remediation backlogs, inconsistent logging, and weak operational hygiene. AI may have increased the blast radius of these risks, but they existed long before LLMs.
The discussion also explores how smaller, open-source models can rival or exceed the results of heavily funded proprietary systems when paired with the right orchestration and context. Baloo explains how her team at Aisle used lightweight models to identify vulnerabilities in OpenSSL, including issues other systems missed entirely. She says, “If you can find new and novel vulnerabilities in the same codebase that were missed by this incredibly intelligent and well-resourced model, then maybe it’s not about the model. Maybe it’s about the way you’re running the model, and everything else around it.”
Dave also brings up the governance failures emerging around enterprise AI adoption. Internal copilots, third-party integrations, and poorly understood permission models are creating new forms of insider risk. “Our permissioning models need to change, and identity is a really big part of that,” Baloo acknowledges, pointedly hinting that 1Password could help drive that change.
Later, Baloo candidly addresses thorny issues of leadership and board accountability, particularly how CISOs are expected to manage risk they did not create. Baloo argues that security teams are often left cleaning up years of operational debt accumulated elsewhere in the business. She offers a pragmatic approach to tackling these issues, but is vehemently critical of “risk acceptance” culture, having seen organizations normalize small unresolved issues until they compound into systemic failures. “No risk acceptance! What a nonsense term,” she quips.
As always, Dave closes the episode by asking what advice his guest has for security professionals just starting in their careers. Baloo says she found success by following her interests and values, rather than her ambitions, and that this has led her not only to a successful career, but a happy one.
Subscribe to Chasing Entropy
Subscribe to Chasing Entropy for honest, expert-led conversations on agentic AI, security, shadow IT, and extended access control from industry leaders.
Subscribe now2026-06-11, 00:00

Every year, the Verizon Data Breach Investigations Report (DBIR) is one of the most hotly-anticipated and widely-read documents in security. And every year includes some surprising stats and reshuffles the top few threat vectors. But longtime readers will notice that the 2026 DBIR features some advice that ought to be familiar to everyone by now: get the basics right. The report’s authors even say that the overarching theme this year is “keeping a strong foundation in the face of change.”
So what does a strong foundation look like? It looks like patching faster, reducing credential reuse, tightening third-party access, and making it harder for attackers to turn one weak login into a company-wide mess. Glamorous? No. Effective? Yes.
Exploits, credentials, and AI: The stories that stood out in the 2026 DBIR
This year’s DBIR analyzes more than 31,000 incidents, including more than 22,000 confirmed breaches across 145 countries. It’s not light reading, unless your idea of a beach read includes ransomware economics, exploit chains, and the occasional donut chart. But diving deep into these topics is worthwhile, because the numbers show both change and stubborn repetition.
Vulnerability exploitation is surging
In terms of eye-popping statistics, the big story this year is the explosion of vulnerability exploitation, which is now the leading initial access vector for breaches–far exceeding phishing and credential abuse. Only 26% of critical vulnerabilities in the CISA Known Exploited Vulnerabilities catalog were fully remediated in 2025, down from 38% the prior year. Median time to full remediation rose to 43 days, a huge jump from last year’s 32 days. Maybe the scariest part of this whole scenario is that these are pre-Mythos numbers, and security experts are still bracing for an AI-powered hurricane of vulnerabilities.
The report’s authors attribute this escalation to the sheer volume of vulnerabilities organizations had to face, finding that there were roughly 50% more critical vulnerabilities to patch over last year. But while we can speculate about why there are suddenly so many more vulnerabilities to patch, what’s indisputable is that organizations need to be investing more resources in their patch management efforts. It might be a sisyphean task, but that doesn’t mean it’s not worth doing.
Diminishing returns for ransomware
Ransomware remains a dominant pressure point, appearing in 48% of breaches. However, there is some good news: 69% of ransomware victims in the DBIR dataset did not pay, and median payments continued to decline. That suggests resilience work is having an impact. Tested backups, segmentation, access controls, and incident response planning are not exciting cocktail conversations, but they sure beat explaining why the finance share was encrypted by someone named DarkSomething_1997.
Weak links in the supply chain
Third-party risk spiked in this year’s report, and breaches involving third parties rose to 48% of total breaches, a 60% increase from the prior dataset. The report points to familiar causes in cloud and SaaS environments: missing or improperly secured MFA, weak passwords, poor credential rotation, and excessive permissions. This is where security programs often discover that their real perimeter includes vendors, contractors, SaaS apps, service accounts, OAuth tokens, and at least one integration nobody remembers approving.
The report cautions organizations to reign in permissions, writing “...a strong starting point is to focus on the authentication and authorization layers, as those are usually the ones that end up on an organization’s end of the responsibility matrix of cloud environments.” The authors also warn, “We should pay special attention to service and machine accounts, as those will likely be the ones leveraged in our potential agentic AI future.”
Credentials and the “human element”
Even in our ever more automated work environment, the human element is still at the center of many breach stories. It appeared in 62% of breaches, while Social Engineering represented 16% of all breaches. This year, the report separated traditional phishing attacks (which they define as using asynchronous communication like emails) from “pretexting,” where attackers are communicating with victims in real time. Email phishing is still common, but mobile-centric tactics are gaining traction. In simulations, voice and text-based attacks had a median success rate 40% higher than email simulations. Attackers have learned that people make decisions while multitasking, commuting, or staring at a phone between meetings. Corporate security training needs to catch up to this new reality.
And what about passwords? This year credential abuse fell to 13% as the first observed entry point. So at last, we here at 1Password can hang up our spurs and call it a day. Just kidding. While passwords may not be the leading initial attack vector, credential abuse appears in 39% of breaches when measured across the full attack chain, which means attackers have not exactly thrown passwords into the sea. They still love them. Too much, frankly.
The AI of the storm
Naturally, both we and the DBIR would be remiss not to make AI a focal point. The DBIR shows threat actors using GenAI for targeting, initial access, malware development, and tooling. But perhaps the most troubling AI-related risks are coming from inside the house. The 2026 DBIR finds that Shadow AI is rampant. 67% use non-corporate accounts to access AI services on their corporate devices. Worse still, source code was the most common data type submitted to external GenAI tools in the report’s DLP dataset. It seems inevitable that those chickens will come home to roost, possibly in next year’s DBIR
How 1Password addresses the risks in the DBIR
The DBIR is focused on surfacing the security risks facing organizations. 1Password is focused on addressing those risks across our entire customer spectrum.
For consumers and families, 1Password reduces the blast radius of the credential problems attackers keep exploiting. Watchtower flags breaches, weak passwords, duplicate items, and other security issues in saved items, with checks for reused and weak passwords performed locally on the device. 1Password also supports passkeys across devices, helping people move important accounts away from phishable passwords. Its security model combines the account password with a 128-bit Secret Key to protect account data.
For enterprises, 1Password Unified Access addresses the access sprawl behind many modern breaches. Unified Access governs credentials across humans, AI agents, and machines. It brings together discovery, security, and auditability, with endpoint discovery, centralized credential storage, runtime credential delivery, and unified attribution. Meanwhile, 1Password SaaS Manager lets organizations discover, manage, and optimize spend on their SaaS applications, including the ones outside SSO. That’s a big deal given the fact that the DBIR recommends deactivating dormant accounts no less than four times.
For developers, 1Password helps remove secrets from places they should never live. The 1Password CLI can load secrets into scripts so credentials stay synced and are not exposed in plaintext. Service Accounts help automate secrets management for applications and infrastructure. Shell Plugins help eliminate API keys stored on disk or in shell profiles. This is practical security for teams that need to ship software without leaving credentials scattered through terminals, repos, and config files like breadcrumbs for criminals.
Put the DBIR’s lessons to work
One of the reasons for the DBIR’s enduring popularity is that it refuses to traffic in snake oil or flavor-of-the-week security fads. Instead, it offers a simple lesson: Defenders should prioritize the controls that interrupt real attack paths.
This week, review your internet-facing systems, require MFA on remote and SaaS access, rotate shared and third-party credentials, inventory AI tools in use, and move developer secrets out of local files and into managed workflows. Then schedule the same review monthly. Attackers automate repetition. Defenders should too.
Want to learn how 1Password can help you address the risks in your company’s environment? Talk to an expert today.
2026-06-05, 00:00
At 1Password, we’re empowering our people to explore how AI can help them learn faster, solve problems more creatively, and make meaningful contributions at every stage of their career. For our interns, that culture shows up in practical, everyday ways. AI can help make a large codebase feel more approachable, turn a confusing error message into a learning moment, or create space to think through an idea before writing the first line of code. Just as importantly, it helps them build confidence, ask better questions, and do their best thinking.
We spoke with two interns, Eileen Zhao and Kashish Garg, about what they’ve experimented with and what impact looks like as they use AI in their work at 1Password.
Meet Eileen, Developer Intern
Hi, I'm Eileen! I've been interning at 1Password for the past year across three teams: I started in Product Operations, moved to Knox (our design systems team), and I'm now on the Insights team. Outside of work, I love doing crosswords, lifting weights, reading, and playing video games. For a fun fact: I've been journaling every single day for the past 7.5 years!
How have you used AI during your year at 1Password?
I’ve had a lot of opportunities to experiment with AI in different contexts. In Product Operations, I used it to edit my writing and make sure my communications were concise and meaningful when working with different stakeholders. As a developer, I lean on AI most when I'm picking up new concepts, which happens a lot when you move between teams. It's great at explaining things and pointing me toward resources to dig deeper. I also use it for "rubber ducking" – talking through my thought process step-by-step before I start coding, which helps me organize my thinking before I write a single line.
Can you give us an example where AI helped you think through your ideas?
During my time on the Knox team, we had an internal hackathon where I got to fully lean into "vibe coding" for the first time. It was a low-stakes environment to just experiment and see how far I could go. The experience taught me a lot about AI's limitations – and confirmed for me that it does make silly errors you have to review to catch – but also showed me how quickly it can produce prototypes that help you visualize an idea before you commit to building it properly.
How has AI helped you create impact during your internship?
Thoughtfully using AI has rapidly increased the pace of my learning. When I hit a problem, whether it's a cryptic error message, a tricky bug, or an unfamiliar concept, I can unblock myself much faster than I could on my own. It's also sped up repetitive tasks. For example, on a recent project I worked on, AI was great at scanning a large codebase and identifying areas that needed to be updated. On a broader level, having access to so many AI tools at 1Password has pushed me to keep developing my AI skills in a way that feels aligned with where the industry is going.
Meet Kashish, Developer Intern
Hi! I’m Kashish, a fifth-year Computer Science student at UBC and a Developer Intern here at 1Password. As part of the Developer Growth team, I get to help developers use 1Password securely in their workflows.
Some fun facts – I’m doing a second degree! I previously completed a Biology degree but decided to pursue Computer Science after taking an Intro to Python course. I’m also passionate about hackathons. I’ve participated in ten hackathons across Canada and the US over the past few years, and helped organize HackCamp, nwHacks, and cmd-f at UBC! Outside of tech, my main hobby is running – I’ve done four half-marathons and recently completed my first full marathon!
How are you using AI day-to-day?
One tool I’ve been enjoying is Dust, an AI agent connected to our internal resources like Notion and Jira. For complex tickets, it helps me quickly parse dense information and company-specific jargon. Earlier in my workflows, I’ve used AI to navigate our large codebase by pointing me toward relevant files and helping me understand how everything connects. Then towards the end of a task, I'll use it as a sanity check. AI helps me validate my approach and surface any edge cases I might have missed. It's become a natural part of how I move through work at every stage.
Tell us about something you’ve experimented with.
During my first week, my supervisor suggested using AI to onboard myself onto our codebase, which is something I'd never thought to do before. We work with a large cross-platform monorepo with shared core business logic and multiple native clients. Rather than blindly browsing thousands of files, I asked the AI agent for a structured overview. It walked me through what the repo does, how the client layers talk to the core, and where key areas like the data layer, API layer, and platform code live. It also pointed me to the right architecture docs to read first. It saved me from that overwhelming feeling of not knowing where to even begin.
How has AI helped you create impact during your internship?
AI has helped me move faster and learn more deeply, so I can focus on actually contributing to my team rather than getting stuck in the weeds. It's helped me organize my thoughts, navigate unfamiliar problems with more confidence, and accelerate the kind of learning that usually takes much longer as a new intern. What stands out to me is that 1Password doesn't just encourage AI use, but smart AI use, recognizing how powerful it is as a tool for growth and development. That culture has pushed me to be more intentional and creative about how I use it, which has made me a stronger developer overall.
What we’re building together
Eileen and Kashish’s experiences show what AI fluency looks like in action. They’re using AI to get unstuck, explore unfamiliar systems, test ideas, and learn more intentionally. They’re also learning how to bring their own context and judgment into the process. That balance is exactly what we’re working to nurture across 1Password.
We’re proud to see our interns bringing curiosity, creativity, and critical thinking to the future of work at 1Password. If you’re interested in doing meaningful work on a team that values learning, experimentation, and thoughtful innovation, we’d love for you to explore our internship and career opportunities.
2026-06-05, 00:00

In our view, The Gartner® Hype Cycle™ for Agentic AI, published in April 2026, contains a passage that we at 1Password feel should be a wakeup call for any organization building an agent program.
Gartner states, "In practice, fully autonomous agents are not ready for most enterprise use cases, and human oversight remains essential. Semiautonomous deployments, where there is some human supervision of the work of AI agents, are what enterprises must plan for."
That is a clear directive for organizations, and the gap between what it requires and what most current deployments provide should be driving every enterprise AI architecture conversation right now.
The Hype Cycle for Agentic AI report states that “Interest in AI agents is significant and accelerating. According to Gartner’s 2026 CIO and Technology Executive Survey, only 17% of organizations have deployed AI agents so far, but 42% expect to do so in the next 12 months, and another 22% within the following year. This is the most aggressive adoption curve among all emerging technologies in the survey.”
Later in the report, Gartner also states: “However, the supporting infrastructure and processes are still maturing. Integration, reliability, security, governance, and financial management for agents are all evolving, and organizations should be prepared for gaps and growing pains.”
Many of the organizations accelerating the AI agent adoption curve may be doing so without adequate governance in place. The question is how businesses can begin to build that infrastructure, and where they should put their focus when considering agent security governance.
Not all agents carry the same security risks
Agentic AI is not a monolithic category; distinct agentic innovations sit at different maturity stages with different architectural properties, and with distinct risks. We’ll focus on three commonly known agentic use-cases from the 2026 Hype Cycle, as representative examples to explore 1Password’s insights into some of the security risks involved in agent use.
Enterprise AI assistants
Gartner reports that in terms of market penetration, enterprise AI assistants represent more than 50% of the target audience. It’s our understanding at 1Password that these are the agents most employees will interact with through productivity tools. However, AI assistants can also represent significant risks. As Gartner states, “AI can amplify existing risks and introduce new threats like prompt injections or data poisoning. Many organizations are unprepared, and security and governance are the top blocker to wider AI deployment.”
They also cite agent sprawl as a risk, stating that “Too many agents shared too widely can cause data oversharing and compromise. Ease of no-code or low-code building increases this risk, if not managed.”
Agents for software engineering
In terms of overall agent adoption, Gartner states that “Most enterprises are still in the early stages, using agents primarily to automate existing workflows rather than reengineering processes for agentic AI. Software engineering is an exception and has experienced significant growth in agentic coding.”
Agents can represent significant productivity gains for coding and software engineering, but they also introduce new risks, including buggy, vulnerable, or low-quality code.” Gartner specifies that “Agents require access to repositories and CI/CD systems, creating credential, authorization and supply chain risks, including prompt and tool injection attacks.”
Agentic analytics
Many companies are hoping to use AI agents across data-to-insight workflows, streamlining analytics processes. However, Gartner points out that“Lack of transparency in how insights and recommendations are generated creates a black box that hinders trust and adoption, particularly prohibitive in regulated industries where compliance risks emerge.”
Agentic AI governance should be a key priority
Another category that Gartner emphasizes is “Agentic AI governance.” They describe it this way: “Agentic AI governance extends AI governance to address specific ethics, security, and business risks in multi-agent orchestration, autonomous decision making, and agent-human dynamics.”
Gartner places the maturity of the agentic AI governance category at the “Embryonic” stage, and they go on to state that, “Successful agentic AI governance builds the trust and reliability essential for scaling autonomous agents and complex workflows. It reduces regulatory compliance costs — potentially by 70% by 2028 — allowing investment to shift toward strategic growth. It mitigates high-stakes risks such as collusion, insider threat, hallucinations, unethical behavior, and privacy violations.”
Their recommendations for agentic governance include:
“Extend AI governance to agentic AI: establish a framework that spans all agentic artifacts for accountable decision making and visibility for agentic operations.”
“Adopt solutions to observe, monitor and manage AI agents to streamline the development and optimization of agents.”
Establish human-in-the-loop escalation triggers and decision-centric practices, such as decision modeling, decision monitoring and decision risk assessments.”
“Define access policies for agentic access to resources, monitoring their activities and conducting regular audits.”
1Password’s recommendation: Three decisions to make before agents go live
Gartner states “Divergent approaches between AI tool providers and the identity and access management (IAM) industry create control challenges.”
At 1Password, we have been working to address the disconnect that arises when companies attempt to adapt access management strategies that were built for human users to AI agents with distinct needs and risks.
We believe that, as businesses build the infrastructure to manage AI agents, they first need to build in human oversight, particularly at the credential level. Semiautonomous deployments require deliberate governance decisions be made before the agent catalog is so large that retrofitting agent controls becomes operationally impractical.
The first three decisions that we at 1Password recommend IT and security teams make are:
What is the minimum set of permissions this agent needs for its specific purpose, and how can the credential issued to it reflect that? For the credential lifecycle: when is the credential issued, how long does it remain valid, and can it be revoked the moment the agent is retired or compromised?
What are the specific points of human oversight that must take place before the agent runs? For irreversible actions (like deploying code or modifying production data), pre-authorization is the only option that satisfies the semiautonomous model; post-monitoring only tells teams what happened without true governance.
When the original human authorization is passed through multiple agent layers, what mechanism preserves it? Most current architectures have no answer: the orchestrating agent acts with its own credentials, subagents act with theirs, and the chain of authorization from human to outcome is fragmented across identity contexts that were never recorded as a single sequence. But we consider auditability to be non-negotiable for agentic deployment.
Proactive management enables agent value
In 1Password’s view, the Gartner Hype Cycle is not only a snapshot of where technologies are today, but serves as a predictor of where failures will concentrate when technologies enter what Gartner refers to as the “Trough of Disillusionment, defined in the report as being the point when “Because the innovation does not live up to its overinflated expectations, it rapidly becomes unfashionable.”
Real-world complexity will always eventually catch up with the early pilots that generated the hype. For AI agents, 1Password anticipates that complexity will likely lead to governance gaps, agent sprawl, security fragmentation, and orchestration patterns that no existing identity framework was built to govern.
1Password believes that the organizations that navigate these complexities won’t be the ones that slow their deployments. Rather, they will be the businesses that made vital architectural decisions prior to deployment, before retrofitting governance becomes impractical, and before the first significant incident makes the security gaps visible.
As Gartner states, “Effective management is what turns agent deployment from pilot to enterprise-scale value.”
Source: Gartner Report, Hype Cycle for Agentic AI, 2026, By Rajesh Kandaswamy, Leinar Ramos, etc., April 2026.
2026-06-02, 00:00

Zero-Shot Learning is a podcast about how AI gets built, secured, and deployed. Hosted by Nancy Wang, 1Password CTO, and Dev Tagare, Senior Director of Engineering at Google, it's a builder's view of the architecture and the complex choices it takes to ship with AI.
As Chief Product Officer at Vercel, Tom Occhino joined Zero-Shot Learning to discuss how AI is reshaping the developer workflow, from frontend architecture to v0, Vercel's production-ready AI coding assistant. What started as a conversation about AI-assisted development became a case for access control as a design decision, not a security afterthought.
How AI changes the developer security model
As part of the team that built and shipped React at Facebook, Tom helped replace MVC patterns with a component-based model that changed how an entire generation of engineers reasoned about interfaces. He calls what's happening now with AI-assisted development "a fundamentally different approach to software."
Where the earlier shift changed how developers organized their thinking, this one changes who or what creates and operates software. In the past, a developer working on component architecture brought years of professional judgment to those decisions. Today, a non-technical worker using an agent in that same workflow does not, and when that agent can call tools, the gap can't be covered by training. Authorization has to be built into the architecture.
Vercel's AI SDK makes it easier for agents to call tools, which adds to its appeal, but also means it requires stronger safeguards. "Putting on my security hat," Nancy said, "how do you make sure that these agents don't get exploited?"
"Under no circumstances are we encouraging code execution on the client," Tom replied.
Vercel builtSandbox because agent-driven development requires an environment without access to production secrets, environment variables, or configuration, so untrusted code doesn’t touch production by default. Sandbox limits what an agent can read or modify locally.
Outbound access needs authZ policy too. "There are outgoing requests that come from that sandbox," Tom said. "Who are they allowed to talk to, and in what capacity?"
Tom drew each boundary deliberately, inbound and outbound, before anything shipped. An agent that can't read your production secrets can still make outbound calls to wherever it chooses. One boundary without the other still leaves the agent free to act where it shouldn't.
When everyone builds, access must be secure by default
To secure the new group of people who can build with AI, products must be secure by default.
Especially as you open access to these tools to many more people who lack the security fundamentals from the first 15 or 20 years of their career," Tom said, "we need to be creating systems that are secure by default and safe by default."
Imagine that a product manager wants to track customer health without waiting on the analytics team and builds a dashboard overnight using an AI-assisted coding platform. The AI pulls account data from Salesforce, usage metrics from Mixpanel, and support ticket volume from Zendesk. To make it work quickly, the PM pastes API keys and account tokens directly into the app. Those credentials carry the PM's full permissions across all three platforms, including access to customer records the dashboard will never need. They share the link with their team, and suddenly several people are querying live customer data through an app nobody in security knows exists, usingcredentials that won't expire, with an agent that can't be attributed to individual users, and that has no revocation path if the PM leaves the company.
"We need that untrusted code execution environment that does not have access to production secrets," Tom said. In our example, the PM's dashboard is what it looks like when permissions are inherited by default.
It's an open area of research, Tom acknowledged, and one 1Password is already working through.
How 1Password makes the secure path the easy path
"You've got to make the paved path the easy path, because if security gets hard, it risks becoming an afterthought,” Nancy said.
“Make the secure way the easy way” is the design logic Tom applied to Vercel Sandbox, understanding that if the secure option requires extra steps, most developers won't take them.
The insecure way is already documented in many codebases. An SSH key is a plain-text file on a developer terminal. API tokens are hardcoded into scripts. Environment variables are inherited by anything running in that environment with no encryption, access controls, or audit trail. Just a file.
1Password Unified Access serves as the authorization layer between the agent and the systems it connects to. Credentials move from vault to runtime without passing through a file, a config, or a clipboard, and are evaluated in context when access is requested, not carried over from setup. The shift from always-on access that developers must manually provision to just-in-time authorization is where the agent gets only what it needs for the task at hand and nothing more. There are no keys to rotate, no authorization to revoke, and nothing to explain to a security team after the fact. It’s a change that fundamentally reduces risk and manual effort from developer workflows.
Vercel's integration with 1Password brings agentic access control directly into the cloud sandbox environment that Tom described. An agent calling tools through Vercel's AI SDK needs credentials to do useful work. Those credentials don't have to be long-lived or broadly scoped. They don't have to live in the agent's context at all.
Tom calls Vercel's platform strategy "the operating system of agents." The authorization decisions made at the design stage become the authorization model that everyone using the product inherits.
Designing access control for agents and AI-assistants
In "We solved the blank canvas problem," Tom joined Zero-Shot Learning to talk about generating ideas faster with AI, and the conversation arrived at why that requires designing authorization from the start. Access control has always been a requirement; what's changing is when in the process it gets built.
Watch the full episode with Vercel’s Tom Occhino
Tom Occhino joined Nancy Wang and Dev Tagare on Zero-Shot Learning, 1Password's podcast on agentic AI and the people building it.
Watch nowALL RSS FEEDS
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
2. PROTON BLOGby ProtonMailSwiss-knife comprehensive solution for privacy and security in email and on the web.
2026-07-21, 18:26
If your inbox is full of emails you’ll never read, then you know how hard it can be to find the one email you’re looking for. As you file through subject lines, straining your eyes, you recognize that feeling of dread. You could simply end the problem by deleting all of your messages, but this would haunt you later. You could spend hours unsubscribing and deleting mindlessly, but this would eat up valuable hours of your workday.
There’s an easier way: Email filters streamline your correspondence, organizing your inbox so that you save time and can focus on what matters (instead of poring over email blasts from Foot Locker). But how exactly do you set up a filter for email and better manage your inbox?
In this article, you’ll learn what email filters are, how they work, and how to use them effectively to improve your email organization for good.
What are email filters?
Email filters are labels that you assign to incoming emails to automatically sort your inbox. They work by scanning, or filtering, an email’s subject line or sender address, and by looking for specific keywords and attachments. Once a filter is set, emails are labeled, sorted, or deleted, based on the criteria you’ve applied.
For those who run a small business, email filters are especially helpful. A well-built filter for email makes inbox organization easy by removing unnecessary clutter and preventing important emails from falling through the cracks. Not only do they make email management easier, but they save you and your employees time by automating repetitive tasks that you would have to do by hand — a habit that also helps you get closer to inbox zero.
Email spam filters also help detect spam messages, reducing your risk of becoming a phishing victim or accidentally downloading malware.
How email filters work
Email filters work by scanning an email for certain criteria that you have set. These criteria can include sender name or email address, subject, specific keywords, and more. Once you’ve set the criteria for your filter, you can select what action Proton takes when a message meets that criteria. For example, you can set your filter action to archive emails that meet the filter’s parameters, mark as read, apply a label, delete, mark as important, and more.
In addition to the filters that you set, Proton Mail’s smart spam filters detect spam and learn how to spot spam emails the more you click “Move to spam” or mark your emails as safe. The more you use Proton, the more our smart filters learn how to create new filters and rules based on your actions. You can also whitelist trusted senders or block unwanted addresses outright so your email spam filters know exactly what to catch and what to let through.
How to organize email with filters
Wondering how to organize email once and for all? Start by building filters around the categories that already exist in your inbox: newsletters, receipts, client threads, internal memos. From there, layer in folders and color-coded labels so every filtered message lands somewhere useful instead of just out of sight. For more ideas, check out these tips to declutter your inbox and keep it that way.
Good email organization is an ongoing system, not a one-time project. Once your filters are in place, revisit them periodically as your inbox habits change, and let Proton’s spam filters keep doing the heavy lifting in the background.
How to create custom email filters with Proton
You can create a filter and easily automate your email labels with Proton in two ways. The first is a quick way to automate labels directly from your email window, and the second is a more in-depth way to create custom filters via your settings, where you can set specific requirements and keywords.
From your email window:
1. Sign in to your inbox at mail.proton.me.
2. Open an email, then move or label it as usual.
3. Check the box that says “Always move sender’s emails/Always label sender’s emails” and select the “Move” or “Label” button to automate your filter preferences.
From your settings:
- Sign in to your inbox at mail.proton.me.

- Select Settings → All settings → Proton Mail → Filters


- Under Custon filters, Click “Add filter.”

- Name your filter and select “Next.”

- Add the criteria you want to activate the filter. You can choose to filter emails when only certain conditions are met, or when all requirements are met.
- Click “Insert” to add additional text or keywords to your filter.
- Select “Add condition” to create a complex filter. You can include as many conditions as you like.
- Select “Next” to set the actions that will apply to your new email filter.

How to use filters to organize your inbox and boost productivity
Email filters can keep unwanted messages out of your inbox, block spam, and organize your inbox into categories for a more efficient workflow. When setting up your filters, you can follow these tips and best practices to create the most streamlined inbox for increased productivity.
- Categorize your business emails by project, sender, work department or priority.
- Use color-coded labels and folders for better visual awareness.
- Create “Follow-up” folders for emails you need to circle back on, or “Reply later” folders so important emails don’t get lost.
- Set up a filter that automatically archives old messages.
- Update and review your filters regularly to see what works for you.
- Don’t accidentally hide important emails by using too many filters.
Keep your inbox organized with Proton
Proton Mail doesn’t only help with email organization; it also keeps your data safe by ensuring that your private messages aren’t accessible to anyone but you. That’s because Proton Mail is end-to-end encrypted, which means you’ll never have to worry about us scanning your emails and selling your sensitive information to third parties.
Filters help manage email overload, save time, and improve communication flow — and using them doesn’t need to be complicated. With Proton Mail, setting up a new filter is easy.
Learning how to use filters is the simplest way to take back control of your inbox, and with additional features like one-click unsubscribe, Newsletters view, and Hide-my-email aliases, Proton Mail’s inbox organization goes above and beyond.
If you’re ready to take control of your email workflow — and your privacy — sign up for free email with Proton Mail today.
2026-07-21, 17:33
Ask the question “What does Google know about me,” and the answer may shock you.
It knows a lot. It knows where you’ve been on the internet and where you’ve been in real life too. And if it knows that much about one person, it knows that much about everyone.
Take what people look up on the internet. Google’s web browser sends anything typed into the search bar to a Google server in real time, even in incognito mode and before you hit Enter.
When it comes to private Gmail conversations exchanged with friends, family, or anyone else, Google scans every single one. Depending on how you use AI inside Gmail, you may inadvertently add your sensitive messages to Gemini, which can be used for AI training.
As for the routes you take using Google Maps, Google saves and tracks every location, including the date and time you traveled.
Even for those who try to avoid using Google, its services are intertwined in the internet. Over half of all websites use Google Analytics, which captures information from web or app visits — meaning Google can track and gather data on people even if they don’t use Google’s search engine or Chrome browser.
That question alone is reason enough to dig deeper into just how much this Big Tech company knows about you and what your data is worth to Google.
- Understanding Google’s reach
- How to find out what Google knows about you
- Google knows things you never shared
- The link between surveillance capitalism and Google
- Google’s ad system is designed this way on purpose
- Leave Google behind, starting with email
Understanding Google’s reach
This list of things Google knows about you is extensive. The company actively acquires and knows the following:
Calendar, including your schedule, appointments, meetings, who they’re with, and where
Web and app activity, including the websites you visit, the apps you use, and how often you’re on them
Photos, including where they were taken and who else appears in them, such as children
Documents, including the way you write and the topics you write about
Internet search history, including what you type but change your mind about and don’t get to actually run a search
Emails, including unsent ones sitting in drafts
Your voice: Google knows how you sound and the way you talk if you use Google Home, Nest, or any other Google Assistant-branded apps.
Maps history (also known as timeline), including where you go and when
YouTube search and watch history: Your searches (from cooking videos to tutorials on how to change a tire) create a vivid profile of you. Time spent on each video is also tracked.
When this list is taken together, Google can make a ton of assumptions and draw a lot of conclusions about you. The emergence of AI like Gemini only helps the company make connections faster and build a detailed profile about your life and connections, even if the people around are not active online.
How can you find out what Google knows about you?
You can’t type “What does Google know about me?” into Google and expect an accurate answer. But you can take steps to understand the depth of what Google knows about you so you can better control your data and privacy. After all, you can only understand what you know — and Google is betting that the majority of its users won’t take the steps to find out.
Go to your profile and click Manage Your Google Account. On the left side, you’ll see a menu of options on the left — click Data and privacy. Here are a couple of good places to start.
Here you’ll see just about everything — and yes, we mean everything — that you’ve been up to on the internet while connected to your Google account. You can browse your web and app activity, look at where you’ve been on Google Maps, get a complete backlog of every YouTube video you’ve ever watched (down to the day), and more.

Health and voice data
If you use a smart watch, Fitbit (which was acquired by Google in 2021), or any other wearable device to monitor your physical statistics, it’s likely synced with Google Fit or Google Health. While these must be enabled for your health tracker to work, you should always consider whether you want Google to know details about your health, including your weight, menstrual data, heart rate, activity level, sleep cycle, and steps for the day.
Voice Match is Google’s way of recognizing your voice across its Google Home products. Your voice can be as personal as a thumbprint, and allowing Google access to your voice helps it train AI and adds to the plethora of sensitive data Google can use to identify you.
Download your data
Want the answer to “What does Google know about me?” Downloading your data is the best way to see everything that Google has collected about you. Keep in mind, the document will be large and you may have a lot to sift through. Go to the Google Dashboard (under Data & Privacy) and click Download your data to request the information.

Google knows things you never shared
When one Proton employee asked “What does Google know about me?”, she found that Google knew things she never personally told it and that it was learning things about her in real time.
It knew that she was recently single, even though she had never selected this option. It knew her income bracket, where she lived, that she doesn’t have kids, and that she was renting an apartment — all without her touching a single button.
When she looked at her timeline, she could see every destination she’d traveled while using Google Maps.
How to stop targeted ads
To stop targeted ads, head to myadcenter.google.com and turn personalized ads off (top right corner).

Next, go to myactivity.google.com and turn off tracking for Web & App Activity, Timeline, Play History, and YouTube History.
You can also access your Data & privacy settings by clicking your Google Account icon → Manage your Google Account → Data & privacy.

The link between surveillance capitalism and Google
Google isn’t just a tech company with a search engine. It’s an advertising juggernaut. Google explains it this way:
Google’s main source of revenue is from ads on our own sites and apps. Advertisers tell Google the types of audiences they want to reach, and we try to show their ads to people in those groups. Each of Google’s products and services show ads in different ways to help reach new and existing customers.
By amassing thousands of data points on nearly everyone in the world, Google has extended its reach: Essentially, Google has so much data on us that it has become the largest engineer of the ad surveillance industry.
Google gives its users the illusion of choice, and, therefore, the illusion of a better online experience. Take the wording of Google’s “personalized ads” philosophy. Through friendly language, the company encourages you to make “your ads more relevant by letting Google know what you’d like to see more or less of.” This is Google’s way of making targeted ads sound like a free service you’re receiving, rather than a way to use information about you — your location, sexual orientation, hobbies, and income bracket — to influence your decisions.
Google’s ad system is designed this way on purpose
Let’s examine this line: “Advertisers tell Google the types of audiences they want to reach, and we try to show their ads to people in those groups.” It sounds harmless, but it isn’t.
Google uses a system known as “real-time bidding” (RTB) to auction off your data to the highest bidder.
Here’s how it works: First, Google builds an in-depth profile on you using your data. Then, it broadcasts that data to thousands of companies that compete in an auction to buy ad space, which will appear as a targeted ad on your computer screen.
This raises serious risks. Because your data is being exposed to thousands of advertisers in a matter of nanoseconds, it could also fall into the hands of data brokers, cybercriminals, or the US government.
“Each time you see a targeted ad, your personal information is exposed to thousands of advertisers and data brokers,” writes Lena Cohen from the Electronic Frontier Foundation. “This process does more than deliver ads — it fuels government surveillance, poses national security risks, and gives data brokers easy access to your online activity.”
Leave Google behind, starting with email
Every piece of personal data that Google touches, from searches and email to location history and voice, routes back to one place: your Google account. That’s what makes it so valuable to Google and so risky for you. A single login ties your entire digital footprint into one profile, which is exactly why deleting your Google account, deGoggling, and switching to privacy-first alternatives is a great way to become safer online.
The best place to start is email. Your inbox isn’t just where your messages live but the master key to your digital life, linked to your bank, subscriptions, social media, and work accounts. Whoever controls your email can reset your passwords and piece together a detailed picture of who you are.
Proton Mail is a natural first step away from Google. It protects your messages with end-to-end encryption and zero-access encryption, which means we never have access to your data and can’t scan it to build behavioral profiles, show ads, train AI models, or share it with third parties — and we don’t want to.
2026-07-20, 20:37
OneDrive comes preinstalled on Windows and, in many cases, starts syncing your files the moment you sign in — quietly uploading documents, photos, and desktop folders to Microsoft’s cloud without much explanation.
If you’re not comfortable with how Microsoft handles your data, there are several ways to rein it in, from pausing sync temporarily to uninstalling OneDrive and blocking it entirely through Group Policy. This guide walks through each method and explains why you might want to disable OneDrive in the first place.
- How to uninstall OneDrive on Windows
- How to disable OneDrive from Group Policy Editor (and block reactivation)
- How to disable OneDrive at startup
- How to stop OneDrive from syncing
- How to remove OneDrive from File Explorer
- Why you should disable OneDrive
- Switch to a private cloud storage
How to uninstall OneDrive on Windows
Uninstalling OneDrive will not delete any files on your computer, and anything uploaded to the cloud can be accessed using the OneDrive web app.
OneDrive has been known to reappear and re-enable itself after major Windows updates. Some users have found success in keeping it from coming back by unlinking their accounts before uninstalling.
Here’s how to uninstall OneDrive on Windows:
- Click Start.
- Find and open Add or remove programs.
- Select Microsoft OneDrive.
- Click Uninstall and then Uninstall again to confirm.

How to disable OneDrive from Group Policy Editor (and block reactivation)
A more advanced way to prevent OneDrive from running or syncing is to block it in Group Policy Editor. Unlike unlinking (which you can redo by signing back in) or uninstalling (which removes the app but leaves it reinstallable), the Group Policy setting blocks OneDrive from syncing at all on that computer at the policy level — the app stays installed but can’t be used, and a standard user has no way to re-enable it through the graphical interface. Note that this method is only available on Windows Pro, Enterprise, and Education editions.
- Press the Win + R keys on your keyboard to open the Run dialog box.
- Type GPedit.msc and press Enter to open the Group Policy Editor.
- Navigate to Local Computer Policy → Computer Configuration → Administrative Templates → Windows Components → OneDrive.
- Double-click the policy named Prevent the usage of OneDrive for file storage.

- Select Enabled, then click OK.
- Restart your computer.

How to disable OneDrive at startup
You can prevent OneDrive from launching automatically whenever you start Windows:
- Press the Ctrl + Shift + Esc keys to open Task Manager.
- Go to Startup apps tab (Startup on Windows 10).
- Right-click Microsoft OneDrive and select Disable.

How to stop OneDrive from syncing
If you want to keep OneDrive installed but stop it from syncing your files, you have a few options.
Temporarily pause OneDrive syncing
You can temporarily pause OneDrive syncing for 2, 8, or 24 hours. Syncing resumes automatically after the time you selected elapses — or manually if you unpause it in the meantime.
- Click the OneDrive cloud icon in the system tray (bottom-right, near the clock).
- Open Help & Settings ⚙ → Pause syncing.
- Select 2 hours, 8 hours, or 24 hours.

The OneDrive cloud icon will now display a paused icon. If your computer is in battery saver mode, OneDrive automatically pauses syncing.
Permanently stop OneDrive syncing (unlink account)
Unlinking your PC from your OneDrive account will permanently stop Microsoft’s cloud storage service from syncing. Files that have been uploaded will remain in the cloud and on your computer; they will not be deleted.
- Click the OneDrive cloud icon in the system tray (bottom-right, near the clock).
- Open Help & Settings ⚙ → Settings ⚙.

- Go to Account, click Unlink this PC, and then Unlink account to confirm.

To access your OneDrive files after unlinking your PC, sign in to the OneDrive web app.
How to remove OneDrive from File Explorer
To remove OneDrive from File Explorer without uninstalling it, you can simply hide it. This is useful if you have unlinked your account and do not want OneDrive to be visible anymore.
- Open File Explorer.
- Right-click OneDrive and select Properties.
- In the General tab, find Attributes and check Hidden.
- Click OK.

Why you should disable OneDrive
Cloud storage is convenient, but if you’re mindful of your privacy or are handling sensitive files, storing them on OneDrive means accepting some trade-offs that you may not be aware of.
No end-to-end encryption: The files you store on OneDrive are encrypted in transit and in rest, but they are not end-to-end encrypted. It means Microsoft holds the encryption keys, so the company has the technical ability to scan or access your files.
Your files can be exposed: Without end-to-end encryption, they remain vulnerable if the infrastructure storing them is breached. The SharePoint attack showed how attackers can access sensitive documents and encryption keys — and OneDrive for Business relies on SharePoint’s underlying technology.
Your data is shared with third parties: Microsoft’s privacy policy permits sharing your data with third parties and doesn’t explicitly rule out using it for advertising. The company already shares Outlook data with over 800 external advertising partners, and there’s no assurance OneDrive is treated any differently.
AI training terms are ambiguous: Microsoft says that Copilot (its AI assistant) doesn’t train on your documents, but the company’s broad privacy policy acknowledges that your personal data may be used to improve its AI models. Where “documents” end and “personal data” begins is not clearly defined, and that ambiguity traditionally works in Big Tech’s favor.
Word documents upload to OneDrive by default: Microsoft rolled out a change that makes Word (plus Excel and PowerPoint) save new documents to OneDrive by default, instead of to your local desktop. This means docs you consider confidential may end up processed under OneDrive’s privacy policy, which Microsoft can change anytime.
US surveillance risks: Unlike European cloud storage providers, OneDrive is owned by a US company subject to American surveillance laws. Combined with the lack of end-to-end encryption, this means Microsoft can be legally compelled to hand over any information it has about you to government agencies or law enforcement — in some cases, without a warrant, under laws like Section 702 of FISA, no matter where you live.
Switch to private cloud storage
Disabling OneDrive doesn’t mean you have to give up on cloud storage. Proton Drive is secure cloud storage that protects your files, photos, documents, and spreadsheets with end-to-end encryption and Swiss privacy laws, outside of US jurisdiction.
No one can access your files but you and the people you choose to share them with — not even us. We never show ads, use your data for AI training, or share it with anyone. All Proton Drive apps are independently audited and open source, so anyone can check our codebase.
For organizations seeking a private OneDrive alternative that doesn’t look at your team’s data, our business cloud storage solution extends the same end-to-end encryption to your whole team, alongside ISO 27001 certification and SOC 2 Type II attestation, with compliance support for regulations like HIPAA and GDPR built in.
Moving your files over from OneDrive takes just a few simple steps.
2026-07-20, 17:41
Apple Intelligence is Apple’s built-in generative AI system designed to help you write, summarize, create images, use Siri, and complete tasks across Apple devices. It is enabled by default on compatible devices and runs across more of your experience than you might realize — from notifications to calls and messages.
If you prefer to limit these features for privacy, reduce distractions, or have more control over how AI is used on your device, you can turn off Apple Intelligence.
- How can you turn off Apple Intelligence?
- How to turn off Apple Intelligence via Screen Time
- How to turn off Apple Intelligence in Settings
- How to disable Apple Intelligence features
- Why you should disable Apple Intelligence
- Choose AI that keeps you in control
- Frequently asked questions
How can you turn off Apple Intelligence?
There are two main ways to disable Apple Intelligence: through a Settings toggle or several Screen Time restrictions:
- The Settings toggle switches Apple Intelligence off entirely, in one step, so it is the fastest option if you just want it gone. But it does not remove some AI elements from the interface — they become non-functional but can add clutter to your Apple experience.
- Screen Time restrictions let you block specific features (like Image Creation and Writing Tools) individually, and they also strip away the related icons and menu options.
If you want all AI elements powered by Apple Intelligence gone from your interface, Screen Time is the better route.
How to turn off Apple Intelligence via Screen Time
In Screen Time, you can block specific Apple Intelligence features at the system level, including interface elements like the Genmoji picker and Writing Tools. This is the most thorough way to remove Apple Intelligence from your device, including any leftovers.
On iPhone and iPad
- Open the Settings app.
- Go to Screen Time → Content & Privacy Restrictions.

- Toggle on Content & Privacy Restrictions and tap Intelligence & Siri.

- Select each feature below and change its setting to Don’t Allow:
- Image Creation — It controls access to Genmoji (creates custom emoji from a description), Image Playground (creates images from descriptions, themes, or people in your photo library), and Image Wand (turns sketches or surrounding content in Notes into generated images).
- Writing Tools — It includes AI composing, proofreading, and rewriting features in most places you can type, including many third-party apps and websites.
- Intelligence Extensions — It allows the use of third-party AI integrations, such as ChatGPT.

On Mac
- Click the Apple icon in the menu bar, then select System Settings.
- Go to Screen Time → Content & Privacy.

- Toggle on Content & Privacy and select Intelligence & Siri.

- Toggle off Image Creation, Writing Tools, and Intelligence Extensions and click Done.
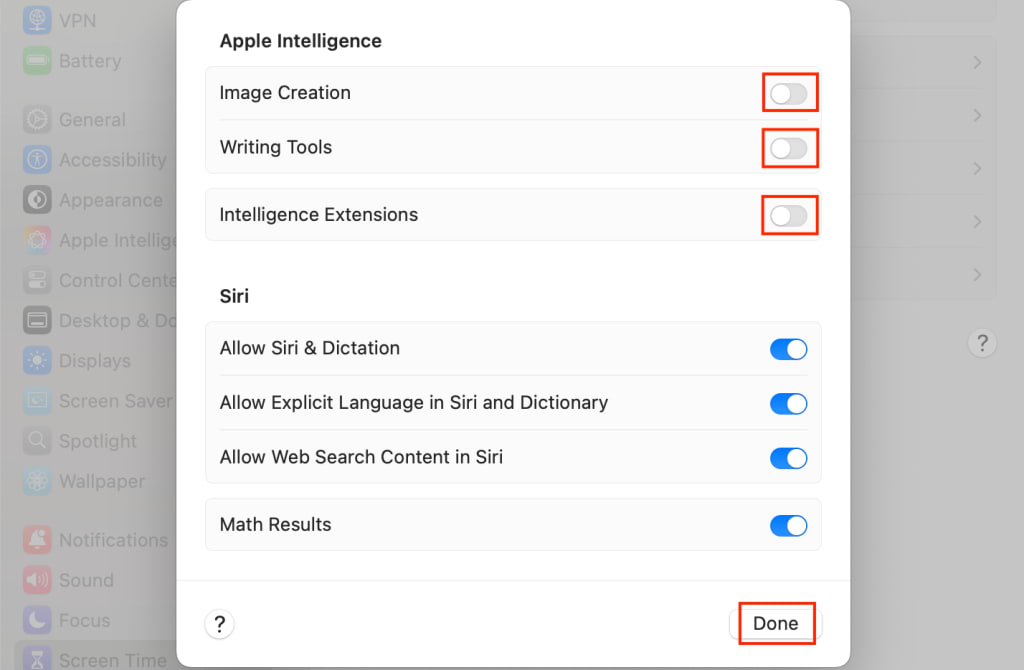
These changes may take a while to come into effect, and you may need to restart your device or affected apps.
How to turn off Apple Intelligence in Settings
If you want to disable Apple Intelligence without removing its interface elements, you can do so directly in Settings. This is a quicker method, though it won’t strip features like Genmoji from the interface. Additionally, some features like Call Screening are managed independently of this toggle and will have to be disabled separately.
On iPhone and iPad
- Open the Settings app.
- Tap Apple Intelligence & Siri.
- Toggle off Apple Intelligence.

On Mac
- Click the Apple icon in the menu bar, then select System Settings.
- Click Apple Intelligence & Siri.
- Toggle off Apple Intelligence.

How to disable Apple Intelligence features
You can turn off Apple Intelligence features, one at a time:
Turn off Visual Intelligence
Visual Intelligence analyzes content on your iPhone’s screen and can use your camera to analyze your physical surroundings. With this feature, you can identify plants and animals, translate text in real time, and look up business details. You can launch it using Camera Control on supported iPhones, from a screenshot, or through a shortcut added to the Lock Screen, Control Center, or Action Button.
Unfortunately, there is no way to disable Visual Intelligence alone, so you need to disable Apple Intelligence in Settings. Alternatively, you can reduce the chance of accidental activation by removing Visual Intelligence shortcuts and disabling Camera Control.
Here’s how to disable Camera Control:
- Open the Settings app.
- Go to Accessibility → Camera Control.

- Toggle off Camera Control.
Here’s how to disable automatic Visual Intelligence suggestions on screenshots:
- Open the Settings app.
- Go to General → Screen Capture.
- Toggle off Automatic Visual Look Up. If Apple Intelligence was already turned off, this setting will not appear.

Turn off the ChatGPT extension
When Apple Intelligence and Siri can’t answer a question, it may offer to send your query to ChatGPT. While this expands on what Apple Intelligence can do, queries sent via this extension are processed by OpenAI, meaning your data leaves Apple’s ecosystem and is subject to ChatGPT’s privacy policy instead.
If you prefer to keep your queries within Apple’s infrastructure, here’s how to disable the ChatGPT extension:
- Open the Settings app.
- Go to Apple Intelligence & Siri → ChatGPT Extension.
- Toggle off Use ChatGPT.

Turn off Call Screening and Hold Assist
With Call Screening, Apple Intelligence automatically answers calls on your behalf, prompts the caller to state their name and reason for calling, and displays a live transcript on your screen so you can decide whether to pick up. Hold Assist detects when you’ve been placed on hold and monitors the call in the background, notifying you when an agent is available.
Both features require Apple Intelligence to process phone call audio, which Apple claims happens on-device.
Here’s how to turn off Call Screening and Hold Assist:
- Open the Settings app.
- Select Apps → Phone.
- Toggle off Hold Assist Detection.

- Under Screen Unknown Callers, select Never.

Turn off Genmoji
There is no standalone setting to disable Genmoji, but you can do so via either of the following methods:
- Disable Image Creation via Screen Time. This removes Genmoji from all interface elements, while allowing you to continue using Writing Tools and Intelligence Extensions. Note that all image creation features, including Image Playground and Image Wand, will also be disabled.
- Disable Apple Intelligence via Settings. This turns off all AI features but leaves Genmoji visible in the interface.
Writing Tools
Like Genmoji, there is no standalone setting to disable Writing Tools. You can:
- Disable Writing Tools using Screen Time. This removes Writing Tools across your device while keeping other Apple Intelligence features enabled.
- Disable Apple Intelligence via Settings, which turns off all AI features but leaves Writing Tools visible in the interface.
Why you should disable Apple Intelligence
Apple Intelligence integrates deeply into how your device works, which can have a range of privacy and experiential concerns. Here are a few reasons you might want to dial it back:
Reclaim storage space: As part of Apple’s privacy-driven approach, AI models are downloaded locally to enable on-device processing. The trade-off is that they require a massive amount of available storage. Currently, Apple Intelligence requires at least 7GB of free storage on each device to run, and it is likely to increase as more features and updates are rolled out.
Limit AI access: Even with on-device processing, Apple Intelligence still touches a significant amount of your personal activity. Visual Intelligence can scan your screen, Call Screening listens to phone calls, and Writing Tools processes your text. Turning off features you don’t want means less of your data is shared with AI.
Prevent third-party data sharing: While most of Apple Intelligence is built within the Apple ecosystem, features like the ChatGPT extension require sending your queries to OpenAI. Third-party sharing means you’re handing data over to yet another company, and you cannot guarantee that they share Apple’s privacy policy. With more AI integrations coming to Apple Intelligence, a simple first step to protecting your data is to disable Intelligence Extensions.
Conserve battery life: This one’s anecdotal but worth mentioning. Some users report noticeable battery drain when Apple Intelligence is active, particularly with background features running. Disabling AI features you don’t need may help extend battery life, though results will vary by device and usage.
Choose AI that keeps you in control
Disabling Apple Intelligence gives you back control over what runs on your device and what accesses your data. But it also leaves a gap — you lose writing assistance, smart suggestions, and other features that can genuinely be useful day to day.
If you want the benefits and conveniences of AI without trade-offs, Proton’s AI assistant, Lumo, is built on the same privacy-first principles that underpin all of Proton’s products. Lumo doesn’t log your data or build a profile on you, doesn’t share your data with third parties, and never ties your conversations to advertising. You can use Lumo on all your devices, including a web app for Mac and a native iOS app, so you can get reliable AI assistance anytime, anywhere.
Frequently asked questions
Apple Intelligence is available on:
• iPhone: iPhone 15 Pro, iPhone 15 Pro Max, all iPhone 16 models, and later
• iPad: iPad mini (A17 Pro) and iPad models with M1 chip or later
• Mac: Any Mac with Apple Silicon (M1 or later)
• Apple Vision Pro
• Apple Watch: Series 6 and later, all Ultra models, and SE 2 and later. Your watch must be paired with an Apple Intelligence-enabled iPhone.
Your device also needs at least 7GB of available storage, and your device language and Siri language must be set to the same supported language. Apple Intelligence availability also varies by region. Most features are available in the EU on supported devices, but some restrictions apply. In China, Apple Intelligence is currently unavailable entirely.
Apple Intelligence is enabled by default, but not all features run constantly. Notification summaries and smart suggestions are always active when enabled. Others, like Visual Intelligence, are only active when you trigger them. To stop Apple Intelligence from running in the background, you will need to disable it via Settings or using Screen Time.
No, Siri can work independently of Apple Intelligence. Disabling Apple Intelligence will revert Siri to its original functionality, so you can use voice activation, make calls, and more as you always have. Features affected by turning off Apple Intelligence include the ability to send your query to ChatGPT, writing help, and other AI-powered features.
Yes, but not directly. Since the Apple Watch mirrors the settings of a paired iPhone, disabling Apple Intelligence on your phone will also disable it on your Apple Watch.
Yes, you can. Turning off Apple Intelligence on Vision Pro follows essentially the same steps as for iPhone, iPad, and Mac:
1. Open the Settings app.
2. Select Apple Intelligence & Siri.
3. Toggle off Apple Intelligence.
You can also use Screen Time to fully block Apple Intelligence. Just follow the same steps as for iPhone, iPad, and Mac.
2026-07-20, 17:17
Small businesses are constantly asked about cyber insurance by clients, investors, procurement teams, lenders, and partners who want to know what happens if a breach, ransomware incident, or account takeover interrupts the business.
For founders and COOs, cyber insurance is rarely just a yes-or-no purchase. The company must first understand what it is buying, what the insurer expects to see, and how credential security could affect coverage if a claim ever happens.
This guide explains what cyber insurance covers, what it may exclude, which security controls insurers often look for, and how better access and credential management can support insurability. Please note that this is not financial advice.
What does cyber liability insurance usually cover?
What cyber insurance may not cover
What underwriters should expect before issuing a policy
The negligence risk in credential security
Why good security posture can affect cyber insurance cost
How much does business cyber insurance cost?
Cyber insurance context for small businesses
How to prepare before applying for cyber insurance
How Proton Pass for Business supports insurability
Cyber insurance works best with strong security
What is cyber insurance?
Cyber insurance is a policy that helps businesses manage the financial impact of cyber incidents. It can support recovery after events such as ransomware, unauthorized access, data breaches, business email compromise, malware, privacy incidents, or digital service disruption.
The UK National Cyber Security Centre says cyber insurance can help organizations recover from cyber incidents, but it also stresses that insurance isn’t a substitute for good cybersecurity.
Cyber insurance can help pay for response, recovery, and specialist support after an incident, but it does not prevent the event itself. If an attacker uses a stolen password, takes over an account, or reaches customer digital data, the business still has to contain the damage, prove what controls were in place, and recover operations. Putting stronger security controls in place before purchasing the policy makes it easier to demonstrate that your business took reasonable precautions.
What does cyber liability insurance usually cover?
Cyber insurance policies vary, so coverage depends on the insurer, broker, policy wording, limits, and exclusions. Still, most policies are built around two broad categories: first-party costs and third-party liability.
First-party costs
First-party coverage helps with costs your business faces directly after a cyber incident. The Association of British Insurers describes cyber insurance as protection that can help businesses with cyberattack costs and support detection, response, and recovery.
In practical terms, this is the part of the policy that may help your company pay for the work needed to understand what happened, contain the incident, restore systems, and keep the business moving.
Depending on the policy, first-party costs may include:
- Incident response and forensic investigation
- Legal advice and breach notification support
- System restoration and data recovery
- Business interruption losses
- Ransomware negotiation and payment support, where legally permitted and covered
- Crisis communications
- Customer support or credit monitoring after a breach
- Costs linked to restoring digital assets
For a small business, these costs create immediate pressure. A ransomware incident or account takeover can delay client work, stop payments, interrupt operations, and force urgent spending before the full impact is even clear.
Third-party liability
Third-party coverage helps when other people or organizations make claims against your business after an incident. This may include customers, partners, suppliers, or other affected parties.
Depending on the policy, this can include legal defense costs, settlements, privacy claims, contractual claims, and certain investigation costs. It is especially relevant for businesses that handle customer records, employee data, payment information, financial documents, legal files, confidential client work, or sensitive commercial information.
What cyber insurance may not cover
Cyber liability insurance is not unlimited protection. Every policy has conditions, exclusions, and duties your business must understand before buying.
Common areas to check include:
Pre-existing issues: A policy may not cover incidents linked to known vulnerabilities, prior compromise, or failures that existed before coverage began.
Failure to maintain controls: If your application states that two-factor authentication (2FA), cloud backups, or access reviews are in place, but those controls are not actually maintained, coverage may be disputed.
Negligence or misrepresentation: Claims can become harder if the business misrepresented its security posture or ignored obvious credential risks.
War and state-backed attack exclusions: Some policies may limit coverage for state-backed, war-related, or systemic cyberattacks. Review this section carefully with your broker rather than assuming every cyber incident is covered.
Fines and penalties: Some policies exclude criminal, civil, or regulatory fines, penalties, or sanctions that the business is legally required to pay.
Credential security can become part of the coverage conversation after a breach. If an incident begins with reused passwords, shared admin credentials, or accounts that should have been removed months earlier, the issue is not only technical. It may raise questions about whether the business had reasonable access controls in place.
What underwriters should expect before issuing a policy
Cyber insurance underwriting has become more security-focused. The NCSC advises businesses to understand what cybersecurity standards they already have in place, what controls they need to improve, and whether they can answer an insurer’s questions accurately before buying coverage.
It is safer to talk about evidence of security controls rather than saying every insurer requires a specific product. Requirements vary by insurer, business size, sector, revenue, data sensitivity, and claim history.
Common underwriting questions may cover whether:
- 2FA is enabled for email, remote access, admin accounts, business tools, and cloud services.
- Cloud storage backups are regular, protected, and tested.
- The business has an incident response plan.
- Employees receive security awareness training.
- Endpoint protection is in place.
- Access is reviewed and removed when people leave.
- Privileged accounts are controlled.
- Passwords are unique, strong, and managed through clear credential policies.
Underwriters may not specifically require a password manager in every application, but they often look for evidence of credential management and access control maturity: clear password and sharing policies, 2FA enforcement, access reviews, protected privileged accounts, and reduced password reuse.
A business password manager supports that evidence by giving employees a secure way to create, store, autofill, and share credentials. It also gives administrators better visibility into access practices, policy enforcement, 2FA readiness, and privileged access control than scattered browser-saved passwords, spreadsheets, or chat messages.
The negligence risk in credential security
One of the biggest risks for small businesses is assuming that cyber insurance will cover any incident simply because a policy exists. In practice, coverage can depend on whether the business met the conditions of the policy and whether its security statements were accurate.
Credential security is a common weak point. A company may say it enforces strong access controls, but employees may still share passwords through chat, reuse the same credentials across systems, keep admin passwords in spreadsheets, or fail to use 2FA consistently on critical accounts.
That gap can be highlighted after an incident. An insurer may review how the breach happened, whether required controls were in place, and whether the business followed its own procedures. A claim linked to ignored credential risks may be harder to defend than one where the business can show it had reasonable controls, training, and access management in place.
A business password manager like Proton Pass for Business helps reduce that risk by making credential controls easier to apply in daily work. It supports unique passwords, secure sharing, safe onboarding and offboarding, and clearer access management. It helps ensure that employees handle credentials in line with the business’s stated security policies.
Why good security posture can affect cyber insurance cost
Business cyber insurance cost depends on many factors, including company size, revenue, sector, data sensitivity, claim history, coverage limits, deductibles, and security maturity. No security feature can guarantee a lower premium. But better controls can make a business look less risky to underwriters.
In practical terms, security posture affects three financial questions:
Can the business get coverage? Some insurers may decline higher-risk applicants or restrict terms if basic controls are missing.
What will the policy cost? A stronger security baseline may support better pricing, though premiums depend on the insurer and risk profile.
What happens during a claim? Better documentation and controls can make it easier to show what was in place before the incident.
The cyber insurance UK market shows why insurers are looking more closely at controls. The ABI reported that UK insurers paid £197 million in cyber claims in 2024, a 230% year-on-year increase. Malware and ransomware accounted for 51% of claims, up from 32% in 2023.
For a founder or COO, the ROI of security goes beyond breach prevention. It also shows up in insurability, cleaner applications, fewer exceptions, stronger claim defensibility, and less operational disruption if something happens.
How much does business cyber insurance cost?
Cyber insurance costs small businesses about $1,550 per year on average in the US, although premiums can range from a few hundred dollars to more than $8,000 depending on the business’s risks, security controls, and coverage limits.
In the UK, basic policies for smaller businesses start at under £200 per year, while small businesses may pay between £500 and £3,500, depending on their turnover, industry, security measures, data exposure, and level of cover.
Cyber insurance context for small businesses
Cyber insurance can feel confusing for small businesses because coverage is not standardized. Two policies may both be called “cyber insurance” but differ significantly in exclusions, limits, response services, ransomware wording, approved incident response providers, and security requirements before and after an incident.
The Association of British Insurers describes it as protection that can help businesses manage the costs of cyberattacks and support response and recovery. In practice, it should be treated as financial protection that works alongside stronger access control, backup readiness, incident response, and credential security.
A practical buying process should include three conversations:
With your broker or insurer: What is covered, excluded, and required?
With your IT or security provider: Which controls are already in place, and which gaps matter most?
With leadership: What level of financial and operational risk can the business realistically absorb?
Cyber insurance should be reviewed as both a financial product and a security-readiness check. The better your business understands its access controls, backups, incident response process, and credential management, the easier it becomes to evaluate whether a policy matches your real risk.
How to prepare before applying for cyber insurance
Before you apply, treat the insurance process like a security readiness check. You do not need enterprise-level maturity, but you do need accurate answers.
Start with these steps:
- Review your access controls: Check which accounts are privileged, whether 2FA is enabled, and whether former employees or vendors still have access.
- Strengthen credential management: Replace reused passwords, remove shared passwords from chats and spreadsheets, and create a clear process for secure sharing.
- Document your backups: Know what is backed up, how often, where backups are stored, and when restoration was last tested.
- Write an incident response plan: Define who leads, who contacts the insurer, who handles customers, and who can approve emergency actions.
- Train employees: Cover phishing, password reuse, suspicious login prompts, and incident reporting.
- Check your policy statements: Do not overstate controls on an application. If 2FA is only enabled for some systems, say so and plan the next improvement.
Here’s a simple cyber insurance checklist:
| Security requirement | What to check |
| 2FA | Is 2FA enabled for email, admin accounts, remote access, and cloud services? |
| Unique passwords | Does every business account use a strong, unique password? |
| Secure sharing | Are shared credentials managed through an approved password manager? |
| Backup testing | Are backups regular, protected, and tested? |
| Incident response plan | Does the team know who leads, who contacts the insurer, and who approves urgent actions? |
| Employee training | Do employees know how to report phishing, suspicious logins, and possible breaches? |
| Access review | Are former employees, contractors, and vendors removed from systems they no longer need? |
Proton’s SMB cybersecurity report can help small businesses benchmark common cybersecurity gaps and understand why practical controls matter before incidents happen.
For broader prevention planning, Proton’s guide to data breach prevention for businesses explains how businesses can reduce the likelihood and impact of breaches before they turn into insurance claims.
How Proton Pass for Business supports insurability
Cyber insurance is financial protection, but underwriting starts with operational reality. If a business cannot show how it manages passwords, access, and shared credentials, the insurer may see more uncertainty.
Proton Pass for Business helps reduce that uncertainty by giving your team a structured way to manage credentials. Employees can generate strong, unique passwords, store them in encrypted vaults, use autofill, and share access securely.
For administrators, Proton Pass for Business supports centralized user management, secure sharing, policies, reporting and logs, SSO integrations, and SCIM provisioning. These features help your business show that access management is not improvised. They also support practical evidence by answering questions such as who has access, where shared credentials live, and how password practices are governed.
Proton Pass for Business supports insurability in three ways:
2FA readiness: Your team can store and manage credentials safely while ensuring strong authentication practices on critical accounts.
Access control: Admins can organize vaults, manage users, and reduce uncontrolled sharing.
Audit trail: Reporting and logs help show that credential management is being monitored.
Cyber insurance works best with strong security
Cyber insurance can help your small business absorb some of the financial impact of an incident. But it works best when paired with the controls that reduce the likelihood and severity of a claim.
Before buying or renewing cyber liability insurance, understand what the policy covers, what it excludes, and which security conditions apply. Be especially careful with credential security, as reused passwords, informal sharing, unmanaged admin access, and inaccurate application answers can all create risk before and after an incident.
The strongest approach to a cyber insurance for small businesses combines both: financial protection for when something goes wrong, and practical controls that make incidents less likely, less damaging, and easier to defend.
A business password manager like Proton Pass for Business is one of the clearest places to start because access is often central to cyber risk, underwriting questions, and incident response. When employees can generate unique passwords, share credentials securely, and admins can review access practices, the business is in a stronger position.
2026-07-20, 16:35
A cybersecurity policy is a foundational document that gives your small business a clear way to explain how employees should protect company systems, accounts, devices, and digital data.
It turns security from scattered advice into shared expectations by answering questions such as which practices are allowed, what employees should avoid, who owns which decisions, and what happens when something goes wrong.
This guide gives you a practical framework for writing or reviewing a cybersecurity policy for your small business. You can use it as a starting template, adapt each section to your tools and risks, and connect the policy to operational controls that make it easier to follow.
What is a cybersecurity policy?
Why small businesses need a cybersecurity policy
Cybersecurity policy template: 9 core sections
Why do IT security policies for businesses fail?
How Proton Pass for Business supports policy enforcement
What is a cybersecurity policy?
A cybersecurity policy is a written document that defines how your business protects information, systems, devices, and accounts from cyber threats. It should explain what employees and contractors, including managers and administrators, are expected to do in day-to-day work.
A strong policy should feel like a reference people can actually use when decisions are unclear. It should answer questions like:
- Which passwords and accounts need extra protection?
- Can employees use personal devices for work?
- Where should sensitive data be stored?
- Who can approve access to business systems?
- What should someone do if they suspect a breach?
- How often will the policy be reviewed?
- What happens to access when someone leaves the company?
For SMBs, the best cybersecurity policy is short, clear, and specific enough to remove guesswork.
Why small businesses need a cybersecurity policy
A cybersecurity policy can help your business in three ways:
Sets expectations: Employees know what is allowed, what is required, and what needs approval.
Creates accountability: If access, devices, data handling, and incident response have clear owners, security stops depending on individual memory.
Supports compliance and customer trust: Being compliant with data regulations such as the GDPR requires your business to process personal data securely using appropriate technical and organizational measures, including risk analysis, organizational policies, and technical measures.
A written information security policy helps show that your business has considered those responsibilities and created controls to reduce risk.
Proton’s SMB cybersecurity report reinforces why this matters for smaller teams: SMBs often face real security risk without the same resources as larger enterprises. A practical policy gives those teams a way to prioritize the basics and make them repeatable.
Cybersecurity policy template: 9 core sections
Use the following structure as a cybersecurity policy template. You don’t need to make every section overly long. The goal is to define the rule, assign ownership, and explain how employees should apply it.
1. Policy purpose and scope
Start by explaining why the policy exists and who it applies to. This section prevents a common problem: people assuming the policy only applies to “IT systems” or full-time employees.
Template copy:
This cybersecurity policy defines how [Company Name] protects business systems, accounts, devices, and data. It applies to employees, contractors, temporary workers, and third parties who access company information or systems.
The scope should include company-owned devices, approved cloud services, business accounts, remote work environments, personal devices used for work, and vendor access.
2. Acceptable use policy
The acceptable use section explains how employees can use company systems and accounts.
It should cover:
- Approved business software and services
- Restrictions on unauthorized apps or browser extensions
- Rules for downloading files and software
- Use of company email and messaging
- Personal use of company devices
- Prohibited activity, such as sharing accounts without approval or bypassing security controls
Keep this section practical. Employees should understand which everyday choices are acceptable without needing to interpret technical language.
Template copy:
Employees must use approved business systems for company work. Unapproved applications, personal storage accounts, and unauthorized browser extensions must not be used to store, process, or share company data unless approved by [role/team].
3. Password and access management requirements
It’s important to take admin controls into consideration. A policy can define who should have access, when two-factor authentication (2FA) is required, and how offboarding should work, but teams still need an operational way to apply those rules. A business password manager like Proton Pass for Business supports that through its admin panel, where your team can manage access, apply policies, review activity, and reduce reliance on informal password handling.
Your policy should state that:
- Work passwords must be unique and strong.
- Passwords must not be reused across business and personal accounts.
- Shared credentials must not be sent through unapproved ways such as email, chat, screenshots, tickets, or documents.
- 2FA should be enabled everywhere, starting with high-risk accounts.
- Access should be granted based on role and business need.
- Access must be removed when someone changes roles or leaves.
- Exceptions must be documented, including cases where 2FA cannot yet be enabled, a shared account is temporarily unavoidable, a vendor needs time-limited elevated access, or a legacy system cannot meet the standard password or access requirements.
Proton’s guide to creating a password policy can support this section with more detail on password rules, sharing, access management, and two-factor authentication.
This is also where policy needs operational support. A rule that says “use unique passwords” is weak if employees still have to create and remember every password manually.
A business password manager like Proton Pass for Business helps teams turn password requirements into daily practice: Employees can generate strong, unique passwords, store them in encrypted vaults, use autofill, and share passwords securely instead of using unsafe channels — all in one app.
Template copy:
Work passwords must be unique, strong, and stored in the approved business password manager. Passwords must not be reused across personal and business accounts or shared through email, chat, screenshots, tickets, or documents. Multi-factor authentication must be enabled for high-risk accounts, and access must be granted based on role and business need. When an employee, contractor, or vendor no longer needs access, permissions must be reviewed and removed.
4. Data classification and handling
A cybersecurity policy should define the types of information your business deals with and how each type of information should be protected. Here are three tiers that a small business can use without complicating things:
Public: Information approved for public use
Internal: Business information for employees and approved contractors that wouldn’t be appropriate to share externally
Confidential: Client data, financial data, credentials, contracts, employee records, or sensitive operational information — anything that can cause harm if leaked
Template copy:
Confidential information must only be stored in approved systems, shared with authorized people, and protected from unauthorized access. Employees must not store confidential business data in personal accounts, unmanaged documents, or unapproved devices.
5. Incident reporting and first response
Your policy should explain what employees must do when they identify or suspect a vulnerability. This does not need to be a full incident response plan, but it should define first actions and ownership.
Include examples such as:
- Suspicious login alerts
- Lost or stolen devices
- Phishing emails
- Accidental data sharing
- Malware warnings
- Unusual account activity
- Unauthorized access to documents or systems
Use Proton’s guide to data breach prevention for businesses for further guidance on reducing breach risk before an incident happens.
Template copy:
Employees must report suspected security incidents immediately to [role/team/contact]. Employees must not delete evidence, reset affected systems, or communicate externally about an incident unless instructed by the incident owner.
6. Remote work and Bring Your Own Device (BYOD) rules
Remote work and personal devices within your business network can create unnecessary risk if not managed properly. Your cybersecurity policy should explain whether employees can use personal devices, which security requirements apply (such as BYOD security), and what happens if a device is lost or someone leaves.
Include:
- Approved devices and operating systems
- Screen locks and device encryption
- Reporting lost or stolen devices
- Use of public WiFi
- Access to company systems from personal devices
- Rules for personal cloud storage
- Requirements for authentication apps and 2FA
- Offboarding steps for remote employees
Proton’s remote work policy and BYOD policy guides can support this section with more detailed rules for distributed teams and employee-owned devices.
Template copy:
Employees may only access company systems from approved devices that meet security requirements. Lost or stolen devices must be reported immediately. Company data must not be stored in personal cloud accounts or unmanaged applications.
7. Third-party vendor access
Small businesses often rely on agencies, contractors, software providers, accountants, consultants, and managed service providers. Vendor access should never be treated casually because it can create a backdoor your business doesn’t fully control.
A business password manager can help make that control more practical by helping teams keep vendor credentials scoped, monitored, and easy to revoke when an engagement ends.
Your policy should define:
- Who can approve vendor access
- Which systems vendors can access
- Whether vendor accounts must be individual or shared
- How long access lasts
- How often vendor access is audited
- How minimum permissions are determined for each vendor
- What happens when a contract ends
This section also supports supply chain security. The NCSC’s 10 Steps includes it as a key area for managing cyber risk, which is especially relevant for small businesses that outsource parts of IT, finance, marketing, or operations.
Template copy:
Third-party access must be approved by [role/team], limited to the systems required for the work, and reviewed at the end of the engagement. Vendor access must be removed when it is no longer needed.
8. Employee training requirements
A cybersecurity policy won’t work if people only see it during onboarding. Regular security awareness training ensures that your policy is always followed.
Your policy should explain:
- When employees receive security training
- Which topics training covers
- How often refreshers happen
- Who must complete training
- How new risks or policy changes are communicated
Training topics can include phishing, password management, 2FA, safe file sharing, data handling, remote work, device security, and incident reporting.
Keep training short and practical. A succinct five-page policy with a checklist supported by short examples is usually more useful than an overstuffed, verbose 40-page document.
Template copy:
Employees must complete cybersecurity training during onboarding and at least [annually/twice a year]. Training will cover password security, phishing, data handling, device security, and incident reporting.
9. Policy review cadence
A cybersecurity policy should change as the business changes. New systems, remote work patterns, vendors, regulations, and incidents can all make old rules incomplete.
Define:
- How often the policy is reviewed
- An owner for the cybersecurity policy review
- How changes are approved
- How updates are communicated
- What triggers an out-of-cycle review
Template copy:
This policy will be reviewed every [six or 12 months] by [owner]. It must also be reviewed after a major security incident, significant system change, regulatory update, or material change in business operations
Why do IT security policies for businesses fail?
Most cybersecurity policies fail for practical reasons:
The policy is too long: A small business cybersecurity policy should not try to cover every possible scenario. If it becomes too long, employees stop using it. Keep it concise and link to deeper procedures where needed.
The language is too technical: Employees should not need a security background to follow business cybersecurity guidelines. Use plain language and replace technical terms with everyday explanations where possible.
The policy is presented only during onboarding: If the policy is only mentioned once during onboarding, it will not shape daily behavior. Reinforce it through training, reminders, quick-reference guides, and updates when processes change.
The policy is never reviewed: A policy written two years ago may not reflect current systems, remote work practices, vendor access, or regulatory expectations. Review it regularly.
The policy is not enforced: This is the most common reason for failure. A policy can say that passwords must be stored securely, 2FA must be enabled, or vendor access must be removed, but those rules don’t matter if nobody keeps on top of it. Enforcement means assigning owners, using admin controls where available, reviewing exceptions, and making secure behavior easier than the shortcut.
For password and access management, Proton Pass for Business can help support policy enforcement operationally. It gives teams encrypted vaults, secure sharing, password generation, and admin visibility, so your business is not relying only on theory. Admins can also monitor password health, credential reuse, and dark web breach exposure across the organization securely, without knowing the employees’ passwords.
How Proton Pass for Business supports policy enforcement
A cybersecurity policy is only useful if the business can put it into practice. Password and access rules are a good example. You can write that passwords must be unique, shared securely, and removed when people leave. But if employees still use browsers, spreadsheets, chat messages, or personal notes, the policy is easy to ignore.
Proton Pass for Business gives employees a secure way to generate, store, autofill, and share credentials, while giving admins better visibility into how access is managed. This makes the password and access management section of your policy easier to follow.
For small businesses, the benefit is practical. You don’t need a large security team to start improving credential hygiene. A business password manager gives your team a central place for work credentials, supports safer collaboration, and helps reduce the risk of password reuse or ungoverned sharing.
Access control is one of the most practical places to turn policy into action. When credentials are easier to generate, store, share, and revoke securely, employees are less likely to rely on unsafe workarounds. Managers also gain a clearer way to support password and access requirements in daily operations.
Enforce your cybersecurity policy with a secure business password manager like Proton Pass for Business.
2026-07-17, 11:15
A firewall is a security system designed to monitor and control incoming and outgoing network traffic based on predetermined security rules. It acts as a barrier between a trusted internal network and untrusted external networks, such as the internet, thus protecting against unauthorized access and other cyberthreats.
Whether you’re protecting a home network, a home office setup, or a corporate network with thousands of endpoints, the same basic principle applies:
A firewall decides what gets in, what gets out, and what gets blocked.
In this guide, we’ll look at:
- How does a firewall work?
- What does a firewall do?
- Firewall vs. antivirus: what’s the difference?
- Why is a network firewall important?
- A brief history of firewalls
- Types of firewalls
- How do VPNs and firewalls interact?
- How to choose and deploy a firewall for your business
- What a firewall can’t do
- FAQ
How does a firewall work?
Imagine your house is a local private network (LAN) — that is, all the devices in your house that connect to your modem/router, which connects to the internet. A firewall works like a security guard at the door of your house. It lets in trusted visitors (safe data), blocks strangers (dangerous data), and keeps an eye on everyone inside to make sure they behave appropriately.
The security guard has a guest list (a set of rules) that says who is allowed to enter the house. For example, friends and family are on the list, but strangers and suspicious people are not.
When someone approaches the door, the security guard asks for their ID (checks the data packet — a unit of data transferred over a network). The guard looks at important details like their name (IP address) and reason for visiting (protocol/port number). If the person (data packet) matches the guest list, the security guard lets them in. If the person is not on the list or looks suspicious, the guard turns them away.
Once inside, the security guard keeps an eye on your visitors to ensure they don’t go into off-limits rooms (sensitive parts of your network). If someone tries to access these rooms without permission, they get escorted out.
Firewalls often work in both directions. That is, they filter both incoming and outgoing traffic, preventing not only those on the internet from connecting to restricted local resources, but also preventing local users from connecting to specified resources on the internet. Some firewalls are outgoing-only.
An outgoing firewall might prevent a local device from connecting to an IP address associated with malware, or it could be used to censor content. A school might use a firewall to prevent students from accessing social media content, or a restrictive government might use firewalls to block content it deems objectionable on social, religious, cultural, or political grounds (such as the Great Firewall of China).
The same “security guard” logic also applies in a business setting, albeit often scaled up dramatically. Instead of one house, imagine an office building, a data center, and a scattering of remote workers all connecting from home A business firewall (or, more often, several firewalls working together) has to consistently enforce the same guest list across all of them.
What does a firewall do?
A firewall performs three key functions:
1. Traffic filtering
Firewalls analyze data packets to determine if they should be allowed or blocked based on specific criteria, such as IP addresses, port numbers, protocols, and content.
2. Enforcing rule sets
Administrators configure firewalls with rule sets that define which traffic is permitted or denied. These rules are based on security policies that specify allowed and disallowed activities.
3. Monitoring and logging
Firewalls can continuously monitor network traffic and log significant events, providing network administrators with valuable insights into network activity and potential security risks.
Firewall vs. antivirus: what’s the difference?
For smaller organizations that already have antivirus software, deciding whether a firewall is also worth the security budget is a common dilemma. In most cases, the answer yes, as these tools protect different things.
Scope
- A firewall protects the network, deciding what traffic is allowed to enter or leave in the first place.
- Antivirus software protects the individual device, scanning files and processes that are already there for known malware signatures or suspicious behavior.
What they catch
- A firewall can block a connection attempt before it ever reaches a device.
- Antivirus software deals with threats that have already reached the device. For example, a malicious file downloaded through an already-permitted connection.
When they act
- Firewalls act at the perimeter, in real time, on traffic.
- Antivirus tools generally act after the fact, scanning files or running processes for signs of compromise.
So while both tools help protect against malicious threats, they cover different stages of an attack. A firewall reduces how much reaches your devices in the first place, while antivirus software catches what slips through.
Why is a network firewall important?
Using a firewall has several advantages:
- Improves security by identifying and blocking potential threats before they enter the network
- Safeguards sensitive information
- Assists in meeting regulatory and compliance requirements
- Helps to control and optimize network traffic
Firewalls can be deployed as a boundary between the internal network and the internet (which is known as a perimeter firewall), or within the network to protect specific segments and/or resources within that network (known as an internal firewall).
Cloud firewalls, also known as firewall-as-a-service (FWaaS), are hosted in the cloud and provide firewall protection for cloud-based infrastructure. Such firewalls are managed by cloud service providers.
For businesses specifically, firewalls are also often a baseline requirement rather than an optional add-on. Many compliance frameworks and cyber-insurance policies require some form of network firewall to be in place before they’ll consider an organization adequately protected.
A brief history of firewalls
Firewalls as a concept first appeared in the late 1980s, and have gone through four broad generations since:
Packet-filtering (stateless) firewalls: The earliest form.
Stateful firewalls: Added the ability to track the state of active connections rather than judging each packet in isolation.
Proxy (application-level) firewalls: Added full inspection of traffic contents, not just headers.
Next-generation firewalls (NGFWs): Combine the above with capabilities like deep packet inspection (DPI), intrusion prevention, and application awareness, and it results in most of what’s sold as a “firewall” in an enterprise context today.
Types of firewalls
Firewalls come in various types, each designed to meet different security needs and provide varying levels of protection.
What is a packet-filtering firewall?
Packet-filtering firewalls examine the headers of data (IP) packets, which include source and destination IP addresses, port numbers, and protocol information. They then apply rules based on these headers to either allow or block the packets.

While standalone packet-filtering firewalls exist in theory, the reality is that all firewalls filter packets — it’s the most basic function of a firewall.
What is a stateful firewall?
Also known as dynamic packet filtering, these firewalls track the state of active connections and make decisions based on the state and context of traffic. They inspect packet headers and maintain a state table that records information about active connections.
Unlike stateless firewalls, which filter packets solely based on predefined rules and the information contained in the packet headers (such as IP addresses and port numbers), stateful firewalls track the state of active sessions and use this information to make more informed decisions about whether to allow or block traffic.
The state table includes information such as the source and destination IP addresses, port numbers, and the current state of the connection. By understanding the context of the connection, stateful firewalls can make more sophisticated decisions. For example, they can recognize whether a packet is part of an existing, legitimate connection or if it is an unsolicited packet that might be part of an attack.
Almost all real-world firewalls are stateful firewalls. They might offer additional functionality, as you will learn below, but these are almost invariably a refinement of the stateful firewall.
What is a proxy firewall?
Proxy firewalls act as intermediaries between you and the internet. They make requests on your behalf, inspect the entire data packet (header and payload), and, if deemed safe, send the data to the destination.
Proxy firewalls are best suited to environments where deep inspection of application data is crucial, such as corporate networks handling sensitive information.
In principle, proxy firewalls improve performance and reduce bandwidth usage. However, this is often countered by the fact that they can be complex and resource-heavy, thus becoming a bottleneck that slows down network performance.
What is a next-generation firewall (NGFW)?
NGFWs combine traditional firewall features with additional functionalities, such as deep packet inspection, intrusion prevention systems (IPS), and encrypted traffic inspection. They can identify and control applications, detect and prevent advanced threats, and enforce security policies.
Next-generation firewalls are highly effective at identifying and stopping advanced threats and provide comprehensive security by integrating multiple security functions. However, they’re more expensive and complex to manage, making them best suited to organizations that require advanced security capabilities to protect against sophisticated cyberthreats.
What is a unified threat management (UTM) firewall?
UTM firewalls integrate a mix of security services— various firewall types, antivirus software, and intrusion detection, for example — to provide a holistic approach to network security.
Although they lack the advanced features and flexibility of specialized security solutions like NGFW firewalls, UTM firewalls are often regarded as a cost-effective solution for small to medium-sized businesses, as they simplify security management by consolidating multiple security functions.
What is a network address translation (NAT) firewall?
NAT firewalls modify network address information in IP packet headers while in transit, so that multiple devices on a local network can share a single public IP address. They are often used by domestic routers and office LAN gateway servers, through which local devices connect to the internet.
NAT firewalls add a layer of security by hiding internal IP addresses, but are usually used in conjunction with other firewall types to provide more comprehensive security.
What is a web application firewall (WAF)?
A web application firewall (WAF) is a specialized firewall designed to protect web applications by filtering and monitoring HTTP/HTTPS traffic between a web application and the internet. WAFs help to safeguard web applications from various attacks, such as SQL injection, cross-site scripting (XSS), and other common web exploits, by inspecting and filtering incoming traffic.
What is a human firewall?
A “human firewall” is an analogy that refers to the collective effort of employees within an organization to act as a line of defense against cybersecurity threats. This concept emphasizes the role of human awareness and behavior in enhancing organizational security, complementing technological defenses like firewalls, antivirus software, and intrusion detection systems.
How do VPNs and firewalls interact?
A VPN creates an encrypted tunnel between your device and the VPN server.
This prevents any firewall between the VPN server and your device from interacting with your data, so data inside the VPN tunnel simply bypasses the firewall. This includes firewalls on domestic modem/routers and office corporate servers.
Learn more about how VPNs work
To address this issue, most VPN providers (including Proton VPN) implement firewalls on their servers to protect their customers. For example, Proton VPN servers use stateful firewalls to reject all incoming traffic connections that weren’t initiated by you.
If you want uninitiated incoming connections (for example, if you are torrenting), we offer a port forwarding feature, which punches a hole through the firewall. This introduces some security risks, but port forwarding is only active if you choose to enable it.
VPN apps also use firewall rules (and similar platform-specific operations) to prevent DNS and IPv6 leaks.
Learn how to check if your VPN is working
VPNs and firewalls used to censor content
Because an encrypted VPN connection prevents firewalls from examining and filtering VPN traffic, services such as Proton VPN are highly effective at bypassing firewalls that aim to block content on the web.
How to choose and deploy a firewall for your business
For a household or small office, one firewall (typically built into a router or an operating system) is generally sufficient to meet your security needs. Businesses, however, often need to think about firewalls across several different environments at once. The right setup for this depends on what’s being protected:
Head office / campus: A perimeter firewall protecting the main office network, often alongside internal firewalls that segment sensitive areas (such as finance, HR, engineering) from the rest of the network.
Branch offices: Smaller, remote locations often need their own firewall, rather than relying entirely on head office. This is particularly true if they connect directly to the internet, rather than through a central hub.
Data centers: Firewalls at data centers typically need to handle high volumes of traffic and are often deployed alongside network segmentation to contain any breach to a small part of the infrastructure.
Cloud and multi-cloud environments: Traditional hardware firewalls don’t map well onto cloud infrastructure, which is where firewall-as-a-service (FWaaS) firewalls are useful. These scale with the cloud provider, rather than requiring physical equipment.
Remote and hybrid workforces: Employees connecting from home networks or public WiFi are outside the traditional office firewall perimeter entirely. This is typically addressed using a combination of endpoint firewalls, VPNs (either traditional setups where the company owns their own VPN servers, or modern third-party solutions using dedicated servers), and network access approaches based on zero-trust security (for larger organizations).
A few practical questions worth asking when evaluating firewall options for your business include:
Does it need to inspect encrypted traffic? A growing share of malicious traffic is encrypted, so if the firewall can’t perform TLS/SSL inspection by decrypting, checking, and re-encrypting HTTPS traffic using its own trusted certificate, it’s effectively blind to a large category of threats.
How is it managed? Managing a handful of separate firewall dashboards across offices, cloud accounts, and remote endpoints doesn’t scale well. Centralized management matters more as an organization grows.
What’s the performance cost? Deeper inspection (like DPI) requires more processing power. It’s worth understanding how a firewall performs with its full security features switched on.
Has it been independently tested? Vendor performance and security claims are worth checking against independent testing, rather than taken at face value. This is the same principle that should apply when evaluating any security or privacy product.
What a firewall can’t do
Firewalls are a key piece of network security, but they were never meant to work alone. One way to understand what they can do, is to be clear about what they can’t:
Neutralize threats already inside your network
If malware arrives through a permitted channel, such as an email attachment, a compromised update, or a user’s own device, there’s not much a perimeter firewall can do about it. This is where antivirus, endpoint detection, and internal segmentation matter.
Account for human error
A firewall can’t fix poor human judgement. Someone tricked by social engineering or phishing into handing over their password isn’t a traffic-filtering problem.
Filter encrypted traffic that wasn’t configured to inspect
Traffic sent through a VPN, for instance, deliberately can’t be inspected by a firewall. This is precisely why VPNs are effective for both privacy and bypassing censorship firewalls (see above).
Be effective due to misconfigured rules
A firewall is only as good as the rules it’s given. An overly permissive rule set (or one that hasn’t been updated as the network changes) can leave critical gaps in your defenses, despite the firewall being technically “in place.”
None of this means firewalls aren’t essential. It just means that you need to see and deploy them as one layer among many, such as firewall, antivirus, VPN, and employee training, rather than as a single point of defense.
Final thoughts: Firewalls and VPNs complement each other
Firewalls are an essential component of network security. Almost all firewalls are stateful firewalls, with variations that offer distinct features and benefits tailored to specific security needs and environments.
VPN services make extensive use of firewalls to keep both their own systems and those of customer devices safe, while at the same being an effective means of bypassing firewalls that aim to censor online content.
For businesses in particular, a firewall is best thought of as one layer of a broader security setup, to be used alongside tools like VPNs, antivirus software, and employee awareness training, rather than as a replacement for any of them.
Frequently asked questions
In a computer network, a firewall is a security system consisting of hardware, software, or both that sits between a trusted network and an untrusted one (usually the internet). It controls what traffic is allowed to pass between them, based on a defined set of rules.
A firewall filters incoming and outgoing network traffic, blocking anything that doesn’t meet its security rules, while allowing legitimate traffic through. It can also monitor and log network activity to help identify potential threats.
The purpose of a firewall is to prevent unauthorized access to (or from) a network, protecting sensitive systems and data from external threats, while also giving administrators control and visibility over what traffic is allowed to move across the network.
2026-07-15, 18:12
Most businesses don’t realize they have a password problem until an issue forces them to acknowledge it, such as an admin password kept in a spreadsheet, or login credentials that remain active for team members who left your company years ago.
This is a common occurrence. In the UK, the government’s Cyber Security Breaches Survey 2024 found that 50% of businesses identified a cyber security breach or attack in the previous 12 months, rising to 70% of medium businesses and 74% of large businesses.
In this situation, a password audit is one of the most valuable actions your business can take to stay safe. It’s a practical way to uncover credential risks that tend to build quietly in the background through weak passwords, unauthorized access, dormant accounts, and logins stored outside approved systems.
For small and mid-sized organizations in particular, this kind of review can help make meaningful security improvements without spending money or conducting a complex transformation program.
This article explains how to conduct a password audit for your business, what to look for, and how to turn the process from a one-off clean-up into a more consistent security practice.
What is a password audit?
A password audit is a systematic review of the passwords, accounts, and access permissions used across a business. Its purpose is to identify credential-related risks such as weak passwords, reused passwords, outdated logins, inactive accounts, excessive access, and credentials stored outside approved systems.
In practice, a password audit goes beyond checking whether a password is strong enough. It also looks at:
- How passwords are managed across your organization
- Who has access to what and whether that access is still necessary
- How passwords are stored and shared
- Whether your business has enough visibility to spot risk before it becomes a security issue
This broad scope is what makes a password audit useful. In most organizations, credential risk isn’t created by a single bad password. It builds gradually through small failures in oversight, inconsistent access controls, poor storage habits, and accounts that remain active long after they should have been reviewed or removed.
An effective password audit helps bring those issues into view. It gives businesses a clearer understanding of their current password hygiene and creates a practical basis for improving access control, tightening credential management, and reducing avoidable exposure over time. This kind of review is much easier to conduct when you’re using a business password manager with admin tools that support visibility, access review, and policy enforcement.
How to run a password security audit: a practical five-step framework
A useful password audit doesn’t need to begin with a perfect map of every account, tool, and access path in the business. It just needs a clear structure and a controlled system for managing credentials. Without these two things, the process can quickly become too broad and too easy to postpone.
The way to break the cycle of avoiding password audits is to centralize password management, define ownership, and review access through one approved workflow.
Here’s an in-depth guide to running your own password audit:
Step 1: Create a full credential inventory
Start by building a working inventory of the systems your business depends on. That includes the obvious core platforms, such as:
- Finance tools
- Cloud storage
- Collaboration software
- CRM systems
- Admin consoles
- Any environment that holds company or customer data
It should also include less obvious tools and services operating in your network:
- Shared social accounts
- Dormant SaaS subscriptions
- Contractor tools
- Test environments
- Services adopted by individual teams without central oversight
Cataloguing every tool is important because most credential risk starts with incomplete visibility. If you don’t know which tools are in use, you can’t review how access is being managed across them.
Businesses that already use a business password manager such as Proton Pass for Business begin their password audit with a practical advantage because credentials live in encrypted vaults.
Step 2: Map access against business need
Once you have a clearer view of your systems, the next step is to examine access. You need to review whether the right people still have the right level of access to the right tools.
Start by looking at each key system and asking who currently has access, if it reflects their present responsibilities, and whether any accounts carry broader permissions than necessary.
In many businesses, access expands gradually over time. Broad admin rights can be granted for convenience and never removed, for instance. Contractors may retain access after a project ends, or team members may change roles and keep permissions from previous ones.
That kind of drift increases risk even when the password itself is strong. The NCSC’s guidance on access control recommends assigning accounts to authorized individuals only, and giving users the minimum access and permissions they need, since anyone can become a liability. A password audit should therefore examine the reason behind each access level.
Step 3: Do a password health check
This stage of the password audit is for identifying any reused or weak passwords, inactive two-factor authentication (2FA), outdated logins, and insecure storage habits that make compromise more likely.
At this point, the review should focus on a few practical questions:
- Are passwords unique to each account?
- Are any passwords weak or easy to guess?
- Are old credentials still being used and unaccounted for?,
- Are employees writing down their passwords in browser storage or note-taking apps instead of business-approved systems?
- Is 2FA enabled everywhere it can be?
Proton Pass for Business helps you with Pass Monitor, which includes:
- Password health check tools for automatically detecting repeated or weak passwords and inactive 2FA
- Dark Web Monitoring for alerting you if your credentials are involved in breaches
- Proton Sentinel for detecting and blocking suspicious login activity that may lead to account takeover
Step 4: Review inactive accounts
One of the fastest ways to reduce credential risk is to simply remove what no longer needs to exist. Most businesses accumulate inactive accounts over time. For example:
- Former employees that still have access to your company’s tools
- Old SaaS platforms that remain tied to valid company credentials long after adoption has trailed off
- Shared accounts designed for short-term use that end up staying live for months or years because no-one knows who owns them
These accounts attract less attention than active ones, which makes them especially easy to overlook. This review is also closely aligned with broader compliance discipline.
A strong business password review needs to include a deliberate effort to:
- Remove dormant access
- Close obsolete accounts
- Confirm clear ownership for the systems that remain
Proton Pass for Business helps reduce the friction that often keeps these accounts alive by making ownership clearer, access easier to review, and credential changes easier to manage when people leave or roles change.
Step 5: Remediate and standardize
The final step is to turn what you found into action. A password audit only improves your organization’s security if the issues it uncovers are addressed in a structured way.
Once you have identified gaps, you can build a plan that is systematic rather than reactive. Here is a simple password audit checklist:
- Immediately change weak or exposed credentials.
- Replace reused passwords with unique ones.
- Enable 2FA everywhere, starting with critical accounts.
- Remove inactive or unnecessary accounts.
- Revoke excess privileges.
- Move credentials out of spreadsheets, documents, or browser storage.
- Consolidate password storage into an approved business system.
- Update your password and access policies.
This is also the right moment to align technical action with policy. If your current password policy is vague, unenforced, or unrealistic, your audit will simply surface the same problems again in six months.
Password audits and password policies work very well together: Proton’s guide to creating a password policy is a strong companion resource. And you can get started easily with our password policy template.
Remediation needs to prioritize by risk, not by neatness. Start with admin accounts, systems containing sensitive data, externally exposed services, and shared credentials with poor ownership. Then work outward.
Why do businesses skip password audits?
If password audits are so useful, why do so many businesses not bother conducting them? The process can feel harder to begin than it actually is.
In many organizations, credentials are stored in too many locations to review easily. Some employees save passwords in browsers. Others keep them in spreadsheets, shared documents, notes apps, or internal messages.
Different teams may use their own tools, buy software independently, or manage access informally. As a result, the business can lose track of which systems are in use and who has access to them, making it difficult to identify and address security risks.
The absence of a centralized system makes this even harder. Without a single location to manage business credentials, even a basic password security audit can turn into a manual exercise built on guesswork, screenshots, and individual memory. Many SMBs postpone reviewing their password practices because they assume it will require a full-scale security project. In reality, the first step is simply to create structure around what already exists.
Password audits are also often overlooked because credential risk tends to build quietly. Unlike a software outage or a phishing incident, poor password hygiene isn’t always obvious. Weak passwords, unnecessary access, dormant accounts, and informal sharing practices can remain in place for months without drawing attention. By the time they are noticed, they are often deeply embedded in day-to-day operations.
A password audit brings this hidden risk to the surface. It collects evidence and gives an organization the visibility and ownership it needs to strengthen access control, improve storage practices, and make more consistent security decisions.
Turn your password audit into an ongoing control
A password audit becomes much more valuable when it is part of an ongoing practice rather than a one-off review. Credential risk keeps growing if it isn’t addressed. Access changes as people join, leave, change roles, adopt new tools, or work with external partners for limited periods. If a review only happens once, the findings begin to age almost immediately.
Centralized password management is your best investment. It gives IT teams more than a secure place to store credentials. It creates the visibility and control needed to review access more consistently, enforce stronger standards, and respond faster when something needs attention.
Choosing a password manager for IT teams supports this operational model through effective admin dashboards, centralized administration, team policies, role-based access, SCIM provisioning, SSO, and audit logs, turning password management into a stronger operational and compliance control.
2026-07-15, 16:10
Every time you browse the web, your activity passes through your internet service provider (ISP). While encryption prevents ISPs from seeing everything you do, they can still collect a surprising amount of information about your habits, both on and offline.
Whether you’re checking your bank account, streaming a movie, shopping online, or scrolling social media, every connection to the internet passes through your ISP. Unlike Google, Meta, or Amazon, you can’t simply log out of your ISP or choose not to use it. It’s an unavoidable part of modern life.
In this guide, we’ll explain what information ISPs can collect, how they use it, why privacy advocates have raised concerns about ISP tracking, and what you can do to reduce the amount of information your provider can access.
What can your ISP really see?
Modern websites typically use HTTPS encryption to protect the data you send and receive. That encryption limits what your ISP can see, but it doesn’t make your browsing completely private.
HTTPS prevents your ISP from reading the contents of encrypted webpages. For example, if you’re browsing Reddit, your ISP can’t see what posts you’re reading. If you’re logged into your online banking, it can’t see your account balance or transactions.
Depending on your connection and the services your provider offers, your ISP may be able to see:
- The websites and domains you visited
- When you visited them
- How long you remained connected
- The amount of data you transferred
- Your approximate physical location through your network connection
- Which devices are connected to your home network
This information comes from DNS requests, connection metadata, and the network infrastructure that routes your internet traffic.
A 2021 report from the US Federal Trade Commission examined the data practices of six major ISPs serving roughly 98% of the US mobile internet market. It found that several providers collected large amounts of customer data, combined information across different products and services, and shared it with third parties with limited opportunities for users to opt out.
For providers that also operate email services, search engines, television platforms, or smart home products, the amount of data collected can be even broader.
Why ISPs have so much data
Unlike individual websites or apps, your ISP sits between you and the internet itself. Every website you visit, every app you open, every connected device in your home ultimately communicates through your internet provider. That gives ISPs visibility into activity across your entire digital life rather than within a single service.
Some providers have expanded well beyond broadband connections. They also offer:
- Mobile phone services
- Television platforms
- Email services
- Smart home devices
- Cloud services
- Search products
This allows some companies to combine information from multiple services to build a more detailed picture of their customers.
According to the FTC report, several ISPs used this combined data to place customers into advertising categories based on inferred characteristics, including interests and demographics, before sharing those audience segments with advertisers and other third parties.
Unlike social media platforms, however, most consumers have very limited choice when it comes to broadband providers. In many areas, households have only one or two realistic options for internet access.
How ISP privacy protections changed
While privacy laws differ around the world, and several US states have since introduced their own protections, there is still no single federal privacy standard governing how ISPs collect and use customer browsing data. For consumers, however, the result is a patchwork of protections that often depends on where they live.
In 2016, the US Federal Communications Commission (FCC) adopted privacy rules that would have required ISPs to obtain customer consent before collecting and monetizing certain types of browsing data. However, Congress repealed those rules before they ever took effect.
In 2017, Congress repealed the regulations using the Congressional Review Act. Later that year, the FCC also voted to repeal net neutrality protections, with those changes taking effect in 2018.
Together, these changes significantly reduced federal oversight of how ISPs handle customer data and manage internet traffic. While some states have introduced stronger protections, privacy rules for ISP customers still vary widely depending on where they live.
Can your ISP slow your connection?
ISPs don’t just provide access to the internet. They also control the infrastructure your data travels across, giving them significant influence over how internet traffic is delivered.
One of the best-known examples involved Netflix and Comcast. In 2013 and 2014, Netflix customers on Comcast experienced severe performance problems as streaming quality deteriorated. Netflix argued that Comcast used its market position to demand additional payments for direct network connections before restoring normal service, with the company’s CEO describing the arrangement as an “arbitrary tax.”
The issue resurfaced in 2024 when Netflix argued before the FCC that ISPs which also own competing streaming platforms may have financial incentives that create conflicts of interest, even if no specific act of interference can be proven. Rather than alleging deliberate sabotage, Netflix argued that the structure of the market itself creates incentives that can disadvantage competing services.
A separate example emerged during California’s 2018 Mendocino Complex Fire, when the Santa Clara County Fire Department reported that Verizon had throttled the data connection used by one of its emergency response vehicles. According to the department, internet speeds were dramatically reduced while firefighters coordinated operations across the state, and restoring normal service initially required upgrading to a more expensive plan before Verizon later described the incident as a customer support mistake.
While these throttling incidents involved very different circumstances, both illustrate the level of control internet providers can exercise over the networks that millions of people rely on every day.
Can your Wi-Fi router track you inside your home?
One of the lesser-known developments in networking technology is Wi-Fi sensing. For over a decade, researchers have demonstrated that Wi-Fi signals can be used to detect movement by analyzing how wireless signals reflect off people and objects inside buildings. Academic studies have shown these techniques can identify movement, breathing patterns, and even estimate body position through walls under controlled conditions.
Today, some routers and smart home devices include forms of human presence detection designed to automate lighting, security systems, and other connected devices. Industry estimates suggest that tens of millions of US households already have access to some level of Wi-Fi sensing technology through ISP-provided hardware. One Verizon Fios router included built-in human presence detection, while Wi-Fi sensing company Cognitive Systems partners with more than 160 internet providers.
It’s important to distinguish between today’s consumer products and what’s possible in research laboratories. Most commercially available systems perform relatively simple presence or motion detection rather than identifying individuals or reconstructing detailed movements. Even so, the technology highlights how much capability now exists inside devices that many people simply rent from their ISP.
Because providers often control the firmware on ISP-issued routers, they also control which features those devices receive over time. While there’s no evidence that today’s consumer routers perform the more advanced forms of Wi-Fi sensing demonstrated in research, the technology illustrates how networking hardware continues to evolve, and why it’s worth understanding what your devices are capable of.
How to reduce ISP tracking
Although your ISP handles your internet traffic, you can reduce how much information it can collect. While no single privacy tool prevents all forms of tracking, combining several measures can significantly limit what your provider is able to see.
Use a VPN
A VPN encrypts your internet traffic before it leaves your device. Instead of seeing every website you visit, your ISP generally sees only that you’re connected to a VPN server. This prevents your provider from monitoring your browsing destinations through normal connection metadata.
Switch to encrypted DNS
Traditional DNS requests can reveal the websites you visit, even if the contents of those websites are encrypted. Using encrypted DNS technologies such as DNS-over-HTTPS (DoH) or DNS-over-TLS (DoT) helps prevent ISPs from viewing those requests in plain text. Many modern browsers and operating systems now support encrypted DNS. People using Proton VPN also have their DNS requests encrypted by default.
Use your own router
Many households simply use the router supplied by their ISP, but purchasing your own compatible router gives you greater control over firmware updates, security settings, and available features.
Enable HTTPS whenever possible
Most websites already use HTTPS by default, but it’s still worth ensuring your browser always prefers encrypted connections. HTTPS doesn’t hide which websites you visit, but it does prevent your ISP from viewing the contents of encrypted webpages, adding another layer of privacy to your online activity.
Your ISP may not see everything, but it still sees a lot
Your ISP occupies a unique position in your online life. It doesn’t necessarily know every page you visit or every message you send, but it can often see where you’re connecting, when you’re online, and how much data you’re using. In many cases, it can also control the hardware that connects your home to the web.
As networking technology continues to evolve, that visibility may expand even further.
Fortunately, protecting your privacy doesn’t require disconnecting from the internet. Simple steps like using a VPN, enabling encrypted DNS, choosing your own router, and understanding what your ISP can and can’t see can significantly reduce the amount of information your provider is able to collect.
While individual privacy tools can’t solve broader regulatory or industry issues, they can help you take back some control over your online activity.
2026-07-15, 11:58
Technical outages are becoming more frequent, ransomware attacks are spreading to smaller businesses, and the US administration has become more aggressive in restricting access to American technology.
No matter the cause or duration, every tech stack disruption stops your team from collaborating and your clients from reaching you. If you’re running a business, it means costly downtime. For governments or nonprofits, your mission could be at stake.
To help you stay operational through an outage, Proton services are now available as a business continuity solution. Over 100,000 organizations already use Proton Mail as their primary email provider because it’s more secure and private than Big Tech tools and operates on independent infrastructure based in Europe. Our Easy Switch for Business tool makes the transition simple. But for organizations that aren’t yet ready to ditch Big Tech entirely, you can now get the benefits of Proton for out-of-band communications.
When a crisis hits, you’ll be able to keep sending emails in Proton Mail, hosting video calls with Proton Meet, and staying productive in Proton Workspace. Setup is easy, and switching over during an outage is as simple as updating a single setting.
Why plan for outages
Many of the services you use every day share the same underlying infrastructure. The email and messaging apps your team relies on often run on a small handful of providers behind the scenes — Amazon Web Services, Microsoft Azure, and Google Cloud underpin most of the internet’s third-party software.
When one of them goes down, it can take your inbox and business communications down with it, all at once.
But the risk of relying on Big Tech is much bigger than the risk of downtime. US-based providers are legally obligated to comply with their own government — including orders to restrict or cut off service to customers outside the US.
No matter where your business is headquartered, your access to the tools you depend on could be revoked, not by a technical failure, but by a political one.
By design, Proton’s European infrastructure exists safely outside the Big Tech ecosystem, and our legal jurisdiction is in neutral Switzerland. We also have a 10-year track record of industry-leading uptime (we guarantee 99.95% under our SLA). All this makes Proton perfectly suited for any business seeking secure communication tools in an emergency.
Learn how to restore communication with Proton
A fallback that keeps you connected in a crisis
Your entire team can switch over to Proton Mail and Proton Meet for end-to-end encrypted email and video conferencing the instant your main communication service becomes unavailable.
You’ll be able to stay in touch with colleagues, communicate with partners, and support your clients seamlessly.
Here’s how to get set up and switch over during an incident:
Before an incident
1. Consult with our team
We start by understanding your existing business continuity framework — what you already have in place, where the gaps are, and which people and functions need to stay operational in a crisis. From there, we recommend the right mix of active and dormant accounts for your organization.

2. Designate your accounts
Active accounts go to the people who need to be operational at any minute, such as your IT administrators, business continuity coordinators, and senior leadership.
They can log in, configure the environment, and test the service at any time — before an incident occurs.
Dormant accounts are for other users who would only be activated during an incident. They’re pre-provisioned — set up with addresses that are tied to the right user and permission group and ready in the system to be activated instantly — at a reduced price.
3. Configure your domain
You can set up your organization’s email domain (e.g., “yourbusiness.com”) inside Proton Mail in advance.
By doing so, you’ll be ready to use your same email addresses within Proton Mail without any interruption. Or set up a new domain in advance, so you can forward mail and test the service before you need it.
You can also do both, combining a seamless transition for your team with the ability to prepare and test ahead of time.
During an incident
1. Activate dormant accounts
When a trigger event occurs, your IT administrator makes one DNS change — updating the MX record to point to Proton’s mail servers instead of your primary email service (whether Google’s or Microsoft’s or another). That’s all it takes.
Administrators can distribute credentials to their team ahead of time or share access links after the trigger event. Dormant accounts become active once users log in.
2. Your team logs in
Employees access their Proton Mail inbox using the credentials or access link provided by their administrator. There’s nothing new to install, no credentials to reset, and no training required in the middle of a crisis.
3. Keep operating
Your team has access to Mail and Meet. All of it runs on Proton’s independent infrastructure in Europe — separate from Google, Microsoft, and AWS — so whatever took down your primary stack won’t affect Proton.

Learn how to restore communication with Proton
Start preparing for disruption of your primary mail system today
Outages of some kind are all but inevitable. Whether it’s in a week or a year, preparing now will make the difference between a managed response and an operational crisis.
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
3. SPREAD PRIVACYby DuckDuckGoWide range of security and privacy topics.
2026-07-17, 06:50

Nearly two years ago, a federal court ruled that Google illegally monopolized search. The judge was specific about how: Google didn't win by building a better product. It paid billions of dollars to be the default everywhere, on your phone and in your web browser, such that most Americans never actively choose their search engine at all.
That ruling should have been a turning point. Instead, nothing has changed.
Getting away with a monopoly.
The court's decision was a diagnosis, not the cure. The remedies ordered last year fall dramatically short of what needs to happen to level the playing field in search. And Google has appealed them anyway. So too has the Justice Department, seeking the stronger fixes it originally asked for. The strongest remedies haven't taken effect and may not for years to come. Meanwhile, the court-appointed technical committee charged with putting change into practice is only just getting up and running. The result is a company operating exactly as it did before being declared a monopolist while running the same exact playbook that was ruled to be illegal. This is the definition of getting away with it.
And the harm compounds each day. Google's vice grip on search was never only about defaults. It rests on two engines. The first is distribution, or the paid defaults that the court condemned. The second, less visible, is scale. Because Google sees far more searches than anyone else, it trains its systems on data no rival can touch. At trial, an analysis of 3.7 million unique search phrases over a single week found that 93% were seen only by Google. More searches produce better results, which draw more users, which produce still more searches. Every day the remedies are delayed, that flywheel spins faster and the gap a court has already ruled illegal grows wider. And the same flywheel is now spinning up in AI, threatening to rig the next era of search before it starts.
Congress doesn't have to wait.
It doesn't have to be this way. A solution now exists in Congress. Introduced this week by Senator Klobuchar and Senator Schmitt, the SEARCH Act – Securing Enforcement of Americans' Right to Competition at Home – would end Google's waiting games. It also directly addresses both of Google's engines of monopoly at the same time.
On distribution, Google could no longer pay to be the preset default, nor wire its own search into Chrome and Android instead of letting you choose. People would choose for themselves and could switch in a single step, including straight from a competitor's own website or app.
Scale is the harder problem, and the SEARCH Act proposes to do the thing that actually closes the gap. Google would have to share search results and de-identified data with rivals. This would let new startups, AI companies and existing search engines compete on a level playing field for your loyalty on privacy, design, and overall experience.
This bipartisan proposal would codify the same package of remedies that the Department of Justice and a coalition of 49 states and territories fought for in court, and its rules would apply to AI as well as search. DuckDuckGo is proud to support the SEARCH Act. We urge Congress to pass it without delay.
Endorsements and additional information
The text of S. 5007 is available to read here. The SEARCH Act is endorsed by the Bull Moose Project, Digital Progress Institute, and Public Knowledge.
Statements of support:
In U.S. v. Google, the court found Google had illegally used its search monopoly to lock out search defaults from competitors, preventing them from operating at the scale needed to be optimally competitive. The SEARCH Act proposes to finally do something to fix this broken search market. DuckDuckGo is grateful to Senator Klobuchar and Senator Schmitt for their leadership on this bill and for taking on a fight that's long overdue. This is what a serious, bipartisan fix looks like, and we're proud to support it.
— Gabriel Weinberg, Founder and CEO, DuckDuckGo
The courts have done what they can with the tools they have, and it isn't enough. Even after a federal judge found that Google unlawfully monopolizes the search market, the remedies that followed relied on behavioral fixes rather than the kind of structural relief that actually restores competition, proving that antitrust law as written wasn't built for markets like this one. Congress can't keep leaving it to judges to improvise solutions case by case; lawmakers need to give the courts clear, modern guidance for dealing with dominant digital platforms, and DPI urges Congress to pass the SEARCH Act.
— Joel Thayer, President, Digital Progress Institute
Google's motto used to be, "Don't be evil." They dumped that years ago, instead choosing to eliminate competition through self-preferencing and exclusivity agreements. Using their browser, Google Chrome, and their search engine - the main venue through which millions ofAmericans find information - Google picked winners and losers while also giving preference to themselves, including their AI, Gemini.
The SEARCH Act will hold Google and other future monopolists accountable by building upon the proposed remedies from U.S. v. Google, opening up search, advertising, and even internet browsers as areas of competition and innovation instead of control by one behemoth. We commend Senators Schmitt and Klobuchar for introducing this bill, and encourage quick and speedy passage.
— Aiden Buzzetti, Founder and President, Bull Moose Project
The Google search case shows why antitrust enforcement and legislation must work together. Courts must stop unlawful conduct and restore competition in the market Google monopolized. Google’s effort to overturn the remedies should fail, and the states are right to seek stronger relief. But litigation takes years, often after monopoly power has become deeply entrenched. The SEARCH Act would establish clear, forward-looking rules for the largest search platforms, including restrictions on payments for preferential treatment and exclusive distribution arrangements. Antitrust remedies can reopen the search market. The SEARCH Act can help keep it open.
— Patrick Gallaher, Senior Policy Advocate, Public Knowledge
2026-07-08, 11:23
- DuckDuckGo now blocks most video ads! Use our free browser to get the full YouTube experience, minus the ads.
- YouTube Ad Blocking joins our powerful lineup of browsing protections that manage cookie pop-ups, protect you from invasive tracker-based web ads, and more.
- YouTube Ad Blocking is already on by default for most iPhone, Windows, and Mac users! It will be auto-enabled for Android soon, but users can opt in via browser Settings in the meantime.
Interruption-free YouTube with DuckDuckGo

Tired of ads interrupting your videos? Us, too. The DuckDuckGo browser now blocks most video ads, including on YouTube! This new feature blocks ads that run before and during your videos, letting you watch YouTube without the interruptions.
If you’ve been here a while, you already know that the DuckDuckGo browser also protects you from invasive ads and annoying pop-ups on multiple fronts. We block tracker-powered web ads before they can load. We have Global Privacy Control enabled by default, expressing your opt-out rights by telling websites not to sell or share your personal information. We can even manage cookie pop-ups behind the scenes, so you don’t have to deal with the distraction.
How do I access YouTube Ad Blocking?
YouTube Ad Blocking is on by default for iOS, Windows, and Mac. So, there’s no need to adjust your settings, if your app is up to date; just open the browser and start enjoying ad-free videos! The feature will be on by default for Android soon, but in the meantime, turn it on in your browser’s Settings > Ad Blocking. If you don’t see YouTube Ad Blocking on your device, try updating your app.
On all devices, you can disable or re-enable YouTube Ad Blocking any time from your browser’s Settings > Ad Blocking. You can also turn it on and off while you’re watching a video. On desktop, click the video icon next to the green shield in your address bar. On mobile, tap ☰ > Disable YouTube Ad Blocking.
When you disable ad blocking mid-video, the browser will prompt you to send an error report, alerting us to any problems. This is completely optional, anonymous, and helps us make our product better…so we appreciate it!
Please note: if you’re on a mobile device, links to YouTube videos may open in the YouTube app by default. To enjoy DuckDuckGo’s YouTube Ad Blocking, you need to open the YouTube website in the DuckDuckGo browser. It won’t work in the YouTube app.
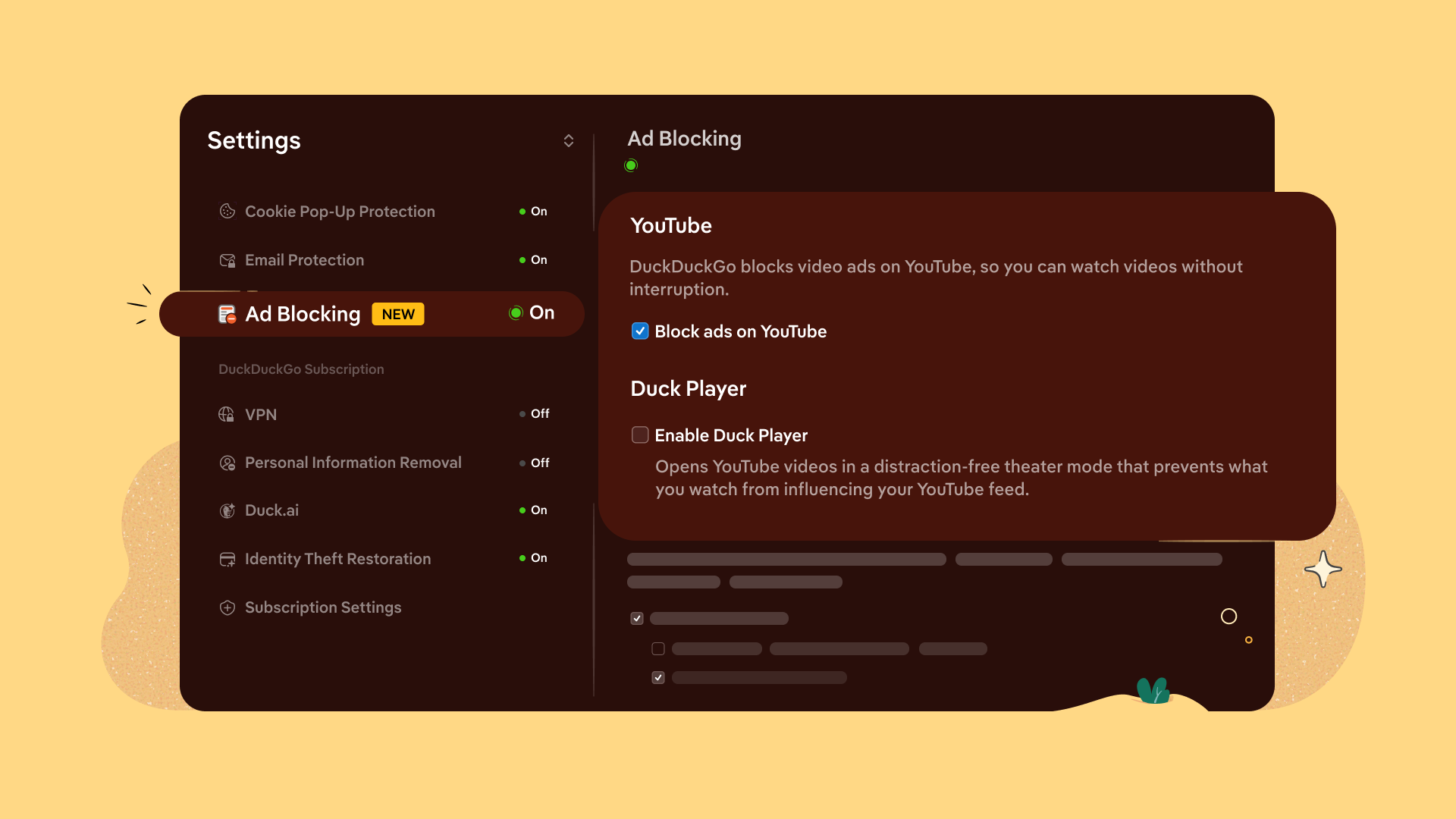
Manage your YouTube Ad Blocking and Duck Player preferences from browser Settings.
Is YouTube Ad Blocking different from Duck Player?
Yes, they’re different – but complementary!
Duck Player is the browser’s built-in video player that lets you watch YouTube videos in a distraction-free theater mode. It also protects you from tracking cookies and personalized ads by enforcing YouTube’s strictest privacy settings for embedded video. This means what you watch in Duck Player won't influence your YouTube recommendations. (It also won’t save your place in playlists.) Opt in to Duck Player and adjust your preferences from your browser Settings > Ad Blocking.
YouTube Ad Blocking blocks video ads on the YouTube website, so you can watch without interruption. It's the regular YouTube experience, just without ads. So you’re free to take advantage of YouTube features like remembering your viewing history and saving your spot in playlists.
You don’t have to pick just one: you can have YouTube Ad Blocking and Duck Player enabled at the same time.
How does YouTube Ad Blocking work?
To detect and block YouTube ads, we use community-driven filter lists sourced from uBlock Origin. These lists are maintained by an active open-source community and are regularly updated to keep up with changes to how ads are served. We may also apply our own rules to improve compatibility and reduce breakage. As with most ad blockers, using our ad blocker can lead to some additional buffering times. But once your video loads, you won't be interrupted with ads.
Let us know what you think!
YouTube Ad Blocking is available now in the DuckDuckGo browser. It’s still a new feature, so give it a try and let us know how it’s working for you! Send anonymous feedback any time from your browser’s ☰ menu.
2026-03-18, 13:29
- The DuckDuckGo subscription includes our VPN, access to more advanced private AI when you want it, Personal Information Removal, and Identity Theft Restoration. It now comes in two plans: Plus, which includes all four protections, and Pro, which unlocks even more powerful AI functionality.
- The new Pro plan is for people who use AI for demanding tasks. On top of the VPN and other protections, it includes three Duck.ai upgrades: 2x higher usage limits than Plus, exclusive access to Claude Opus 4.6, and the highest reasoning available on Duck.ai. (Extended reasoning capabilities available on GPT-5.2 and Claude Opus 4.6.)
- Whether or not you’re a paid subscriber, everyone gets the same industry-leading privacy protections when you search and browse with DuckDuckGo, or chat privately with ChatGPT, Claude, and other popular AIs on Duck.ai.
What is the DuckDuckGo subscription?

The DuckDuckGo subscription is a four-in-one privacy service that gives you extra protection beyond what's available for free in our web browser, search engine, and private AI chat, Duck.ai. It includes our VPN to encrypt your Internet connection, access to more advanced private AI when you want it, Personal Information Removal to help combat identity theft and spam, and Identity Theft Restoration.
The original DuckDuckGo subscription is now called Plus. (If you’re a current subscriber, this is what you have!) It includes all four protections and costs $9.99 USD/month or $99.99 USD/year. Enhanced with more powerful AI tools, the new Pro plan is $19.99 USD/month or $199.99 USD/year. Subscriptions are available in the U.S., Canada, the E.U., and the U.K. See this help page for international pricing and feature availability.
What are the benefits of the Pro plan?
On Duck.ai, anyone can chat privately with ChatGPT, Claude, and other popular AIs, whether you have a subscription or not. Text chat, voice chat, and image generation are free to use within daily limits. DuckDuckGo subscribers on the Plus plan can do more, with higher usage limits and access to smarter AI models with extended reasoning. But the Pro plan is even more powerful.
We designed Pro for people who use AI frequently throughout the day, or for more demanding tasks that require multi-step reasoning…or both! Subscribers to the Pro plan get three additional Duck.ai upgrades:
- 2x higher usage limits, compared to Plus. This includes text chat, voice chat, and image generation limits across all the AIs available.
- One Pro-exclusive model, currently the newly launched Claude Opus 4.6.
- Access to the highest reasoning available in Duck.ai. Extended reasoning capabilities on GPT-5.2 and Claude Opus 4.6 let the AI spend more time thinking through complex, multi-step problems before responding.
This new Pro plan gives you the freedom to dive deep and iterate back and forth for complicated tasks, whether you’re fine-tuning images, analyzing data, writing long-form content, or making an in-depth plan. Higher limits also mean you don’t have to pick and choose as much; you can use AI for a broad range of day-to-day tasks.
When you take advantage of the extended reasoning on GPT-5.2 or Claude Opus 4.6, you’re more likely to get considered, relevant, and well-structured answers to even very complex prompts. And thanks to the Pro plan’s higher usage limits, you’re less likely to be disrupted in the middle of a complicated job.
Which plan is right for me?
If you primarily use DuckDuckGo to search and browse, and you’re not interested in advanced AI chat or added protections…our free offerings may meet all your needs. If you want to expand your privacy protection with our VPN, or you’re getting more into AI productivity tools, consider Plus! Pro is most suited if you use AI for tasks that require deeper context and multi-step reasoning.
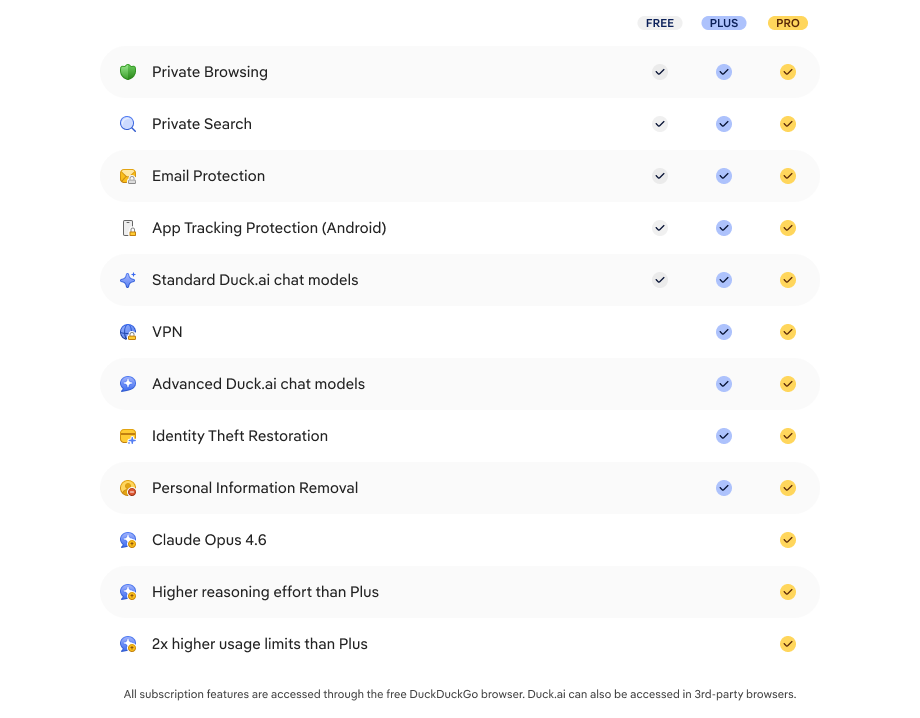
The specific AI models included in each plan are upgraded regularly; at the time of publication, the lineup is as follows:
- Free on Duck.ai: GPT-4o mini, GPT-5 mini, GPT-OSS 120B, Llama 4 Scout, Claude Haiku 4.5, Mistral Small 3.
- Plus: GPT-4o, GPT-5.2 (reasoning), Claude Sonnet 4.5, Llama 4 Maverick, free models.
- Pro: GPT-5.2 (extended reasoning), Claude Opus 4.6 (extended reasoning), Plus and free models.
Can I upgrade an existing subscription?
Yes! As a subscriber, you can switch between the Plus and Pro plan at any time. In the DuckDuckGo browser, go to Settings > DuckDuckGo Subscription. Select View All Plans, pick the plan you'd like to switch to, and proceed to payment or confirm. In third-party browsers, start by navigating to Duck.ai. Just go to Settings & More > Manage Subscription and follow the same steps above.
Ready to give it a try? Head to duckduckgo.com/subscribe to see if the Plus or Pro subscription is right for you!
2025-09-30, 13:00

2025 marks DuckDuckGo's 15th year of donations—our annual program to support organizations that share our vision of raising the standard of trust online. We are proud to donate to a diverse group of organizations around the world that promote privacy and security, digital competition, and a healthier online ecosystem.
This year, we’re donating $1,100,000, bringing DuckDuckGo's total donations since 2011 to $8,050,000. Everyone using the Internet deserves simple and accessible online protection; these organizations are all pushing to make that a reality. We encourage you to check out their valuable work below.
$100,000 to Public Knowledge

Public Knowledge promotes freedom of expression, an open internet, and access to affordable communications tools and creative works. We work to shape policy on behalf of the public interest.
$75,000 to ARTICLE 19
ARTICLE 19 is an international think-do organisation, that takes its name from the Universal Declaration of Human Rights, and works to propel the freedom of expression movement, fighting censorship, defending dissenting voices and advocating against laws and practices that silence.
$75,000 to the Digital Progress Institute
The Digital Progress Institute seeks to bridge the tech-telecom policy divide through incremental, bipartisan measures in line with its principles of bringing about ubiquitous broadband, 5G and beyond, privacy for every American, real competition in digital markets, and a full-stack framework for Internet policy issues.
$50,000 to the Electronic Frontier Foundation (EFF)
EFF's mission is to ensure that technology supports freedom, justice, and innovation for all people of the world.
$50,000 to European Digital Rights (EDRi)
With more than two decades of advocacy experience, European Digital Rights (EDRi) is the go-to, nongovernmental network working on EU and national laws and policies on privacy, freedom of expression, participation online, data protection and technology policy. EDRi unites over 50 organisations from across Europe (and beyond).
$50,000 to the Foundation for American Innovation

The Foundation for American Innovation, a think-and-do tank based in Washington, D.C. and San Francisco, CA, advances technology, talent, and ideas that support a better, freer, and more abundant future.
$50,000 to the Open Home Foundation

The Open Home Foundation fights for the fundamental principles of privacy, choice, and sustainability for smart homes - and for every person who lives in one. It is best known as the organization that owns and governs Home Assistant, among many other projects crucial to the open home.
$50,000 to Signal
Signal Technology Foundation protects free expression and enables secure global communication through open source privacy technology.
$50,000 to the Surveillance Technology Oversight Project (S.T.O.P.)
The Surveillance Technology Oversight Project (S.T.O.P.) advocates and litigates for privacy, working to abolish local governments’ systems of discriminatory mass surveillance that disproportionately impact vulnerable communities.
$50,000 to Tech Policy Press
Tech Policy Press publishes reporting, analysis, and perspective on events, issues, and ideas at the intersection of technology and democracy.
$50,000 to the Tech Oversight Project

Through engaging with lawmakers, exposing false narratives and bad actors, and pushing for landmark legislation, the Tech Oversight Project seeks to hold tech giants accountable for their anti-competitive, corrupting, and corrosive influence on our society and the levers of power.
$30,000 to the Internet Security Research Group
Our mission at ISRG is to reduce financial, technological, and educational barriers to secure communication over the Internet. We operate three projects (Let’s Encrypt, Prossimo, and Divvi Up) that improve the security and privacy of billions of people using the Internet.
$25,000 to Algorithmic Justice League (AJL)

The Algorithmic Justice League is on a global mission to prevent AI harm using research, advocacy, and art.
$25,000 to the British Institute of International and Comparative Law (BIICL)
The British Institute of International and Comparative Law (BIICL) hosts the Competition Law Forum, a centre of excellence for European competition and antitrust policy and law.
$25,000 to Bull Moose Project

The Bull Moose Project Foundation develops and promotes policies that promote fair markets, support American innovation, and hold Big Tech accountable for anti-competitive and anti-consumer conduct.
$25,000 to Canadian Anti-Monopoly Project

The Canadian Anti-Monopoly Project (CAMP) is a think tank dedicated to addressing the issue of monopoly power in Canada and around the world. CAMP produces research, commentary, and policy to make our economies more fair, free, and democratic.
$25,000 to Consumers International
Consumers International is the global membership organisation for consumer rights groups. Founded in 1960, we bring together over 200 member organisations in more than 100 countries, with a mission to empower and champion the rights of consumers everywhere and to build a fair, safe and sustainable marketplace.
$25,000 to Demand Progress

DPEF empowers people to understand how our communications and governance systems should serve democracy — and how corporate power threatens our economy and our democratic future.
$25,000 to Digital Rights Watch

Digital Rights Watch is Australia's leading digital rights organisation. They defend and promote privacy, democracy, fairness and fundamental rights in the digital age.
$25,000 to Gesellschaft für Freiheitsrechte (GFF)
The Society for Civil Rights e.V. (Gesellschaft für Freiheitsrechte e.V. or "GFF") is a donor-funded organization from Germany that defends fundamental and human rights by legal means. The organization promotes democracy and civil society, protects against disproportionate surveillance and advocates for equal rights and social participation for everyone.
$25,000 to noyb
noyb is committed to the legal enforcement of European data protection laws and has filed more than 850 cases against numerous intentional infringements by Big Tech companies - to make online privacy a reality for everyone.
$25,000 to the Internet Archive
The Internet Archive's mission is to provide “Universal Access yo All Knowledge” by preserving and providing free access to digital materials and cultural heritage serving as a digital library for researchers, historians, scholars, and the public to read, learn, and explore for free.
$25,000 to the Open Rights Group (ORG)

Open Rights Group is the UK’s largest grassroots digital rights campaigning organisation, working to protect everyone’s rights to privacy and free speech online.
$25,000 to the Open Source Technology Improvement Fund (OSTIF)
In the past year, OSTIF collaborations led to the fixing of over 130 findings with security impact. Our security uplifts to open source projects wouldn't be possible without the continued support from DuckDuckGo. We are honored to be part of this program and contribute to a more secure Internet ecosystem.
$25,000 to Perl and Raku Foundation
The Perl and Raku Foundation is dedicated to the advancement of the Perl and Raku programming languages, through open discussion, collaboration, design, and code.
$25,000 to Privacy Rights Clearinghouse
Privacy Rights Clearinghouse focuses on increasing access to information, policy discussions, and meaningful rights so that data privacy can be a reality for everyone.
$25,000 to Restore the Fourth

Restore the Fourth advocates with federal, state and local elected officials, to defend privacy and freedom from unreasonable government surveillance.
$25,000 to the Tor Project
At the Tor Project, we believe everyone should be able to explore the internet with privacy. We advance human rights and defend your privacy online through free, open source software and the decentralized Tor network.
$20,000 to The Markup
The Markup challenges technology to serve the public good by producing investigative journalism, unique tools, and accessible resources to inspire action and agency.
2025-09-04, 11:05
- More advanced AI models from OpenAI, Anthropic, and other providers are now available in Duck.ai as part of the DuckDuckGo subscription, formerly known as Privacy Pro.
- Subscribers can now access OpenAI’s GPT-4o and GPT-5, Anthropic’s Claude Sonnet 4, and Meta’s Llama Maverick – and supercharge productivity at work, school, or home.
- The DuckDuckGo subscription is still the same price: $9.99 USD a month or $99 USD a year. On top of access to premium AI models on Duck.ai, it still includes our VPN, Personal Information Removal, and Identity Theft Restoration*. Sign up at duckduckgo.com/subscribe for a seven-day free trial.
- Keep an eye out for higher DuckDuckGo subscription tiers in the future with access to even more advanced AI models.
A layer of protection for everything you do online – including AI
We believe the best way to protect your personal information from hackers, scammers, and privacy-invasive companies is to stop it from being collected at all. To make that happen, we offer a layer of protection for everything you do online. Our browser, for example, is packed with a suite of built-in privacy protections, including our search engine that never tracks you. Our growing suite of private, useful, and optional AI tools is the next evolution.
AI tools have quickly become a significant part of people's online experience, but there’s a gap between how often we use AI, and how safe and in control we feel about it. According to recent Pew research, 27% of US adults use AI tools every day, but 59% feel no control over how AI shows up in their lives. That's why we created Duck.ai, which gives you access to popular AI models from OpenAI, Anthropic, Meta, and Mistral, with the following added protections built by us:
- Anonymized chats. We call model providers on your behalf, so personal information like your IP address is not exposed to them.
- No AI training. Your data is never used to train the AI models.
- Local chat storage. Chats and settings stay on your device to protect your privacy.
- Instant deletion. Erase your chat history in a flash with our Fire Button.
Today, we're expanding Duck.ai by giving DuckDuckGo subscribers access to more advanced AI models, covered by the same strong protections. The base version of Duck.ai is not changing; it’s still free to use, with no account necessary. We’re just adding more models for subscribers. You can see which models are available with and without a subscription here.
Please note that Duck.ai is always optional, whether you’re a subscriber to DuckDuckGo or not. If AI is not for you, you can hide the AI buttons and features from your search settings and your desktop and mobile browser settings. If you use the VPN, for example, but you’re not interested in anonymized AI chat, that’s no problem. Just head to your browser’s Settings menu to turn off the AI features and continue using your VPN normally.
What does the DuckDuckGo subscription include?
Formerly known as Privacy Pro, the DuckDuckGo subscription expands the great protection you get from DuckDuckGo’s free offerings, covering even more of what you do online:
- DuckDuckGo VPN. Built for speed and simplicity, the DuckDuckGo VPN secures your WiFi connection on your entire device, hiding your location and IP address from the sites you visit. Includes full-device coverage on up to five devices at once. Learn more.
- Personal Information Removal. Helps remove personal information like your name, address, and family connections from people search sites that store and sell it, helping to combat identity theft and spam. Available for Mac and Windows.* Learn more.
- Identity Theft Restoration. If your identity is stolen, get expert guidance as you get back on track. Brought to you by Iris (Iris Powered by Generali) — a world leader in identity theft restoration.* Learn more.
- NEW: More Advanced AI models. Subscribers can now access OpenAI’s GPT-4o and GPT-5, Anthropic’s Claude 4 Sonnet, and Meta’s Llama Maverick, in addition to all the free-tier chat models. Models are updated regularly. See the full list here.
The price is staying the same in all regions: $9.99 USD/month or $99 USD/year, with international pricing information available on this help page.
Achieve more with advanced models
More advanced AI models like OpenAI’s GPT-4o are built to handle more complicated tasks than their smaller counterparts like GPT-4o mini. These bigger models are better at following detailed instructions, maintaining context through extended chats, and delivering deeper, more nuanced responses. The DuckDuckGo subscription offers a way to use some of these models, but with more privacy. Even larger and more highly advanced models will be made available through higher subscription tiers in the future.
If you’re a frequent user of different advanced chatbots, the DuckDuckGo subscription is an easy one-stop solution. It lets you access multiple premium models in one place, rather than juggling multiple subscriptions and apps. Your subscription lets you visit Duck.ai and use those premium models in any browser you like. But it's especially convenient within the DuckDuckGo browser, where Duck.ai is seamlessly integrated on both desktop and mobile. Using the DuckDuckGo browser, you can access AI chat when and where you need it, getting support for specific tasks without switching platforms. And as always, it’s completely optional – you can adjust or turn off Duck.ai’s integrations from your browser’s settings menu.
Whether you subscribe for premium models or stick with the free tier, you get the same strong privacy protections.
Is the DuckDuckGo subscription worth it?
When you get a DuckDuckGo subscription, you get instant, full access to any or all the features you want, without complex add-ons – at a price competitive with any of the individual features on their own. The $9.99 USD monthly price tag is more cost effective than maintaining multiple separate AI subscriptions – many of which are in the $20/month range. (See this help page for more international pricing information.)
Additional features like the DuckDuckGo VPN and Personal Information Removal service add value and convenience – and everything is available in one place, your DuckDuckGo browser.
Want to give it a try for free? You can get a 7-day trial of the subscription in the DuckDuckGo Browser's settings. In the US, you can also access the 7-day trial at DuckDuckGo.com/subscribe.
How to access Duck.ai and activate your subscription
Duck.ai can be accessed from any browser. Just visit duck.ai or hit the Duck.ai button on any search engine results page on duckduckgo.com. From there, paid subscribers can head to Duck.ai Settings, click “I Have A Subscription”, and follow the prompts to access the premium models.
If you are using the DuckDuckGo browser, you can use more subscription features, like the VPN and Personal Information Removal*. You also have even more ways to get to Duck.ai! You can click the optional Duck.ai buttons in our desktop and mobile browsers, use one of our iOS widgets, or press and hold the DuckDuckGo icon on iOS or Android. However you get there, the process for activating your subscription is the same.
Learn more about the DuckDuckGo subscription and sign up at duckduckgo.com/subscribe
*The DuckDuckGo subscription is available in the U.S., Canada, the E.U. and the U.K. All subscribers can use the VPN and access the same premium AI models, regardless of region. Personal Information Removal is available to U.S.-based subscribers. Identity Theft Restoration coverage varies by region. Learn more here.
2025-08-05, 20:09

Privacy Pro is our privacy-protecting subscription service that includes the DuckDuckGo VPN, Personal Information Removal to protect yourself from data brokers, and Identity Theft Restoration, which you can call if your identity is ever stolen.
In the year since we launched Privacy Pro, we’ve been working hard behind the scenes to make it more comprehensive, more powerful, and easier to use. Have you been waiting for the perfect moment to sign up? Good news: you can now try Privacy Pro free for 7 days. The free trial is available on all platforms – sign up here to redeem the offer. After your free trial, you can continue at $9.99 USD/month or $99.99 USD/year. (International pricing information here.)
Here’s a look at the major improvements we’ve made in the past year! To learn even more about Privacy Pro, you can visit our blog and Help Pages.
Overall Improvements
International Availability
Privacy Pro subscriptions are now available in the U.S., E.U., Canada, and the U.K. Features and coverage vary by region, but the DuckDuckGo VPN works the same in all regions. You can now use Privacy Pro in more languages including Dutch, French, German, Italian, Polish, Portuguese, Russian, and Spanish. Learn more about using Privacy Pro outside the U.S. here.
DuckDuckGo VPN Improvements
More Server Locations
DuckDuckGo VPN users can now choose from more than 40 locations in 30+ countries. Check out the full list here.
Independent Security Audit
We partnered with Securitum to conduct a comprehensive security audit of the DuckDuckGo VPN and supporting infrastructure. We're pleased to report that it found no critical vulnerabilities, underscoring the strong security measures we have in place for our VPN! Visit this help page for a summary of the key findings, remediations, and accepted risks, plus a link to the full report.
Block Risky Domains Automatically
The DuckDuckGo VPN now automatically blocks known phishing, malware, and scam sites – no matter what browser you're using. This new setting is on by default on all platforms.
Now On All Platforms: VPN Notifications
All users can now get notifications that display VPN status at a glance. These notifications are on by default but can be disabled in your VPN Settings.
Desktop: Automatic VPN Connection
All desktop users now have a setting that lets the VPN connect automatically when you log in to your computer.
Desktop: Introduced App and Website Exclusions
Because some apps and websites aren’t compatible with VPNs, we made sure you can exclude them from our VPN. This lets you use those incompatible apps and websites on desktop without disconnecting from the VPN. (App exclusions are also available on Android. Not compatible with iOS.) Manage website and app exclusions in your VPN settings; you can also manage website exclusions by clicking on the VPN icon in the toolbar.
IOS: VPN Widgets and Siri Shortcuts
We created VPN widgets for the iOS home screen and Control Center, so you can quickly connect or disconnect from the VPN and see your VPN connection status at a glance. We also added a Siri Shortcut.
Mobile: VPN Snooze
Both iOS and Android users can now “snooze” the VPN for easier access to sites and apps incompatible with VPNs.
Android: Automatically Pause VPN During Wi-Fi Calls
To help avoid dropped calls on Android, we introduced a setting that temporarily snoozes the DuckDuckGo VPN during Wi-Fi calls. The best part? We automatically restore your VPN connection when you end your call.
Android: Implemented Auto-Excluded Apps
Our new auto-exclude feature on Android automatically detects apps that aren’t compatible with VPNs and bypasses them, so you won’t need to manually adjust settings. (If you would like to adjust this feature, you can! Just go to Settings > VPN > Manage Apps.)
Custom DNS for Windows, iOS, Mac, and Android
You can now switch between the default DuckDuckGo DNS resolvers and a custom DNS resolver of your choosing in VPN Settings > Advanced Settings.
Personal Information Removal Improvements
New Personal Information Removal Dashboard
We completely redesigned the Personal Information Removal dashboard to give Privacy Pro subscribers more insight into the data removal process. You can more easily see when a site was last scanned, how many records have been removed, which sites are clear of your personal information, and more.
Personal Information Removal Request Timeline
Monitor your data broker removal requests with our new Removal Request timeline. You can track the progress of each request, see when your data has been removed, and get help with next steps if any removals take longer than expected.
More Data Brokers Covered
Privacy Pro now covers over 80 data broker sites and counting, including FastPeopleSearch, MyLife, and OfficialUSA.com. Check out the full list here. Some competitors only re-scan data broker sites on a monthly or quarterly basis…or not at all! But we re-scan the sites every 10 days, submitting new removal requests if your data has reappeared.
Improved Scan Performance
Personal Information Removal now more reliably detects when your information has been removed from the data broker sites. Your first scan after signing up or updating your profile now happens 10x faster than before.
What’s Next for Privacy Pro?
Even more improvements are coming soon. We’re working on adding an upgraded AI chat experience to your subscription, with anonymized access to more advanced chat models than the free version on Duck.ai. We’re adding more data brokers to Personal Information Removal all the time, and we’re working on bringing the feature to mobile. Your feedback helps us catch and address bugs, too – so keep it coming!
Go here to redeem your free trial today. Follow us on social [Reddit/X/Facebook/Linkedin] for updates about all things DuckDuckGo, including more Privacy Pro improvements.
2025-07-22, 19:24
Have you been using the DuckDuckGo browser for a while? If so, you may have noticed a few changes around here! As you navigate through the browser, you’ll notice redesigned icons, a softer, rounder interface, and a fresh color palette. Moving between desktop and mobile is more seamless than ever. And new interactive elements show you exactly how DuckDuckGo is protecting you.
Fresh Visuals, Seamless Protection
We’ve updated our browser’s visual design with a new color palette and softer, rounder shapes, including new icons that we designed in-house. This new look reflects what we believe the internet should feel like with real privacy protection: calm instead of chaotic, streamlined instead of cluttered, secure instead of surveilled.

Hit the green duck-foot shield in the redesigned address bar for real-time information about our tracking protections. Use the redesigned Fire Button to delete your browsing data with one click. Other changes you’ll notice include smoother, softer tab lines and a roomier address bar.

Private, Useful, and Optional AI
We’ve also made it easier than ever to access our private, useful, and optional AI features. Add a Duck.ai button to your URL bar for quick access to free, anonymized AI chats – available on both desktop and mobile.
These new buttons join several other convenient access points. On iOS, get to Duck.ai via Siri shortcut or widgets for your Lock Screen and Control Center. On Android, you find a shortcut by pressing and holding the DuckDuckGo app icon. (There’s also a Duck.ai button on our search results page when you visit duckduckgo.com, which can be toggled on and off here.)
Don’t use Duck.ai? You can disable the feature and hide the buttons in your browser’s Settings menu.

Tell Us What You Think
We love our browser’s new look – and we hope you do, too. If you have comments or questions, you can join our active community on Reddit or reach out on social media (Facebook | Linkedin | X).

2025-07-17, 15:40

Nearly two years ago, a federal court ruled that Google illegally monopolized search. The judge was specific about how: Google didn't win by building a better product. It paid billions of dollars to be the default everywhere, on your phone and in your web browser, such that most Americans never actively choose their search engine at all.
That ruling should have been a turning point. Instead, nothing has changed.
Getting away with a monopoly.
The court's decision was a diagnosis, not the cure. The remedies ordered last year fall dramatically short of what needs to happen to level the playing field in search. And Google has appealed them anyway. So too has the Justice Department, seeking the stronger fixes it originally asked for. The strongest remedies haven't taken effect and may not for years to come. Meanwhile, the court-appointed technical committee charged with putting change into practice is only just getting up and running. The result is a company operating exactly as it did before being declared a monopolist while running the same exact playbook that was ruled to be illegal. This is the definition of getting away with it.
And the harm compounds each day. Google's vice grip on search was never only about defaults. It rests on two engines. The first is distribution, or the paid defaults that the court condemned. The second, less visible, is scale. Because Google sees far more searches than anyone else, it trains its systems on data no rival can touch. At trial, an analysis of 3.7 million unique search phrases over a single week found that 93% were seen only by Google. More searches produce better results, which draw more users, which produce still more searches. Every day the remedies are delayed, that flywheel spins faster and the gap a court has already ruled illegal grows wider. And the same flywheel is now spinning up in AI, threatening to rig the next era of search before it starts.
Congress doesn't have to wait.
It doesn't have to be this way. A solution now exists in Congress. Introduced this week by Senator Klobuchar and Senator Schmitt, the SEARCH Act – Securing Enforcement of Americans' Right to Competition at Home – would end Google's waiting games. It also directly addresses both of Google's engines of monopoly at the same time.
On distribution, Google could no longer pay to be the preset default, nor wire its own search into Chrome and Android instead of letting you choose. People would choose for themselves and could switch in a single step, including straight from a competitor's own website or app.
Scale is the harder problem, and the SEARCH Act proposes to do the thing that actually closes the gap. Google would have to share search results and de-identified data with rivals. This would let new startups, AI companies and existing search engines compete on a level playing field for your loyalty on privacy, design, and overall experience.
This bipartisan proposal would codify the same package of remedies that the Department of Justice and a coalition of 49 states and territories fought for in court, and its rules would apply to AI as well as search. DuckDuckGo is proud to support the SEARCH Act. We urge Congress to pass it without delay.
Endorsements and additional information
The text of S. 5007 is available to read here. The SEARCH Act is endorsed by the Bull Moose Project, Digital Progress Institute, and Public Knowledge.
Statements of support:
In U.S. v. Google, the court found Google had illegally used its search monopoly to lock out search defaults from competitors, preventing them from operating at the scale needed to be optimally competitive. The SEARCH Act proposes to finally do something to fix this broken search market. DuckDuckGo is grateful to Senator Klobuchar and Senator Schmitt for their leadership on this bill and for taking on a fight that's long overdue. This is what a serious, bipartisan fix looks like, and we're proud to support it.
— Gabriel Weinberg, Founder and CEO, DuckDuckGo
The courts have done what they can with the tools they have, and it isn't enough. Even after a federal judge found that Google unlawfully monopolizes the search market, the remedies that followed relied on behavioral fixes rather than the kind of structural relief that actually restores competition, proving that antitrust law as written wasn't built for markets like this one. Congress can't keep leaving it to judges to improvise solutions case by case; lawmakers need to give the courts clear, modern guidance for dealing with dominant digital platforms, and DPI urges Congress to pass the SEARCH Act.
— Joel Thayer, President, Digital Progress Institute
Google's motto used to be, "Don't be evil." They dumped that years ago, instead choosing to eliminate competition through self-preferencing and exclusivity agreements. Using their browser, Google Chrome, and their search engine - the main venue through which millions ofAmericans find information - Google picked winners and losers while also giving preference to themselves, including their AI, Gemini.
The SEARCH Act will hold Google and other future monopolists accountable by building upon the proposed remedies from U.S. v. Google, opening up search, advertising, and even internet browsers as areas of competition and innovation instead of control by one behemoth. We commend Senators Schmitt and Klobuchar for introducing this bill, and encourage quick and speedy passage.
— Aiden Buzzetti, Founder and President, Bull Moose Project
The Google search case shows why antitrust enforcement and legislation must work together. Courts must stop unlawful conduct and restore competition in the market Google monopolized. Google’s effort to overturn the remedies should fail, and the states are right to seek stronger relief. But litigation takes years, often after monopoly power has become deeply entrenched. The SEARCH Act would establish clear, forward-looking rules for the largest search platforms, including restrictions on payments for preferential treatment and exclusive distribution arrangements. Antitrust remedies can reopen the search market. The SEARCH Act can help keep it open.
— Patrick Gallaher, Senior Policy Advocate, Public Knowledge
2025-06-19, 11:41
- The DuckDuckGo browser’s built-in Scam Blocker guards against phishing sites, malware, and other common online scams. It’s on by default, so you’re protected as soon as you open the browser.
- NEW: Scam Blocker now also covers sham e-commerce sites, fake cryptocurrency exchanges, “scareware” that falsely claims your device has a virus, and other sites known to advertise fake products or services.
- Most browsers use Google tools for their phishing and malware protections, sending browsing data to Google in real time. We don’t. We designed Scam Blocker ourselves, with data from Netcraft, an independent cybersecurity company. Our scam protections don’t require an account, and we don’t share your browsing data with third parties.
- Scam Blocker is available for free within the DuckDuckGo browser on desktop and mobile. DuckDuckGo subscribers get full-device coverage when logged into the DuckDuckGo VPN – even when using other browsers.
Scam Blocker: Multiple protections for multiple threats

It’s not your imagination – online scams are getting more sophisticated. According to new reporting from the United States’ Federal Trade Commission, consumers lost $12.5 billion to fraud in 2024 alone. Scams related to investments, online shopping, and internet services were among the worst offenders.
Around here, we believe the best way to protect your personal information from hackers, scammers, and privacy-invasive companies is to stop it from being collected at all. Our browser and built-in search engine never track your searches, and our browsing protections help stop other companies from collecting your data, too. One of those protections is our Scam Blocker, designed and built by us for your security and your privacy. Scam Blocker guards against phishing sites, malware, and other common online scams without tracking your browsing data or sharing it with any third parties. It’s built into the DuckDuckGo browser and free to use, with no signup required.
Fake cryptocurrency offers, urgent messages about "viruses," and high-paying surveys – like the hypothetical examples above – are some of the common scam sites covered by DuckDuckGo’s Scam Blocker.
Scammers and cybercriminals have constantly evolving tactics, so it’s important to stay protected on multiple fronts. Thanks to Scam Blocker, the DuckDuckGo browser can help you spot and avoid some of the most common types:
- NEW PROTECTION: Scam investment sites, storefronts, surveys and more. Designed to trick you into giving away personal information or making bad financial transactions under false pretenses. These scam sites can include investment offers, cryptocurrency trading schemes, discounted pharmaceutical products, affiliate surveys with cash rewards, and more; the sites can look legitimate, but the offers are often “too good to be true.”
- NEW PROTECTION: Scareware. These alarming sites claim that your computer or phone is infected with spyware or viruses. Scareware creates a false sense of urgency to trick people into engaging with fake “tech support” and buying unwanted – or completely fake – antivirus software.
- Phishing sites. Phishing generally uses impersonation to get your login credentials or sensitive personal information. Cybercriminals’ phishing techniques include creating sham websites that look like a familiar legitimate business and using link redirects to get unsuspecting users there.
- Malware sites. If you download a harmless-looking file from one of these sites, malware can infect your phone or computer, causing damage or extracting personal information for later use. Some malware sites start an automatic download before you even click or enter anything.
- Tracker-powered malicious ads. “Malvertising” typically involves injecting malware-laden advertisements into legitimate websites and online ad networks. Some malicious ads can compromise your system even if you don’t click on them.
The scam tactics vary, but the end goals are usually the same: to commit financial fraud using your personal information or to trick you into paying for products or services that don’t exist. If you accidentally click a link that would take you to one of these scammy sites, DuckDuckGo’s built-in Scam Blocker will stop the page from loading and show you a warning message that allows you to navigate safely away. The DuckDuckGo browser also reduces your malicious ad risk while you browse, blocking tracker-powered ads while before they load.
Other browsers like Chrome, Firefox, and Safari rely on Google’s Safe Browsing Service to provide warnings about phishing sites, which involves sending information to Google. We don’t. We built our own anonymous solution that doesn’t send data to any third parties. No sign in, no tracking, and it’s on by default, so you're protected from the moment you open the browser. DuckDuckGo subscribers can connect to the DuckDuckGo VPN to get these protections for your whole device – including in other browsers!
How Scam Blocker works
When you land on a potentially dangerous website, Scam Blocker will display a warning message before loading the site.
New scam sites pop up all the time, but the DuckDuckGo browser stays on top of it. We get a feed of malicious site URLs from Netcraft, an independent cybersecurity company that’s always scanning for new threats. We store that constantly refreshing list on our servers and pass any updates to your browser every 20 minutes.
The way Scam Blocker works is always anonymous. Once your browser downloads the latest dangerous site list from DuckDuckGo, it’s available locally on your device. When you navigate to a site, your browser first checks the site against the list stored on your device. If the site is on the list, your browser shows a warning message that gives you the option to navigate away safely or to continue to the site at your own risk.
Most of the potentially dangerous URLs flagged by Scam Blocker can be found on common sites like Google Drive or GitHub. Uncommon threats – which we encounter less than 0.1% of the time! – require an extra verification step that checks websites against a larger and more comprehensive database on DuckDuckGo servers. But this process is also anonymous; at no time during the threat verification process does your device communicate with any third parties. For a deeper dive on the cryptography we use to maintain anonymity when handling uncommon threats, visit this Help Page.
All this means that your searches and browsing history are still completely anonymous.
Note: This blog post has been edited since initial publication to stay up to date with our evolving product offerings.
2025-03-06, 12:41
- DuckDuckGo’s approach to AI is to provide private, useful, and optional AI features – including chat and search instant answers – to people who want the productivity benefits of AI without the privacy risks.
- Now out of beta: Get free, anonymized access to popular chatbots at Duck.ai. Easily move traditional search results – which now include more AI-assisted answers from web sources – to Duck.ai to continue your conversation.
- Both Duck.ai and AI-assisted answers are free to use, with no account required. We now serve millions of AI-assisted answers daily. If you opt to show them "often" in your settings, they should appear in our traditional search results over 20% of the time.
- Recent updates to AI-assisted answers include expanding sources across the web, beyond just Wikipedia; answering English-language queries outside the U.S.; and adding customization that lets you decide how often you want
answers to appear: often, sometimes (default), on-demand, or never. - Recent Duck.ai chat updates include upgraded models (GPT-4o mini and o3-mini from OpenAI, Meta Llama 3.3, Mistral Small 3, and Claude 3 Haiku from Anthropic) and a “Recent Chats” feature that stores conversations locally on your device – not on DuckDuckGo or other remote servers.
Our approach to AI: private, useful, and optional.
At DuckDuckGo, we believe the best way to protect your personal information from hackers, scammers, and privacy-invasive companies is to stop it from being collected at all. We started with a search engine that doesn’t collect your search history; our flagship experience is now a browser with a suite of built-in protections that includes our search engine, ad and cookie blocking, and many more protections.
Our approach to AI extends this strategy by integrating protected AI features that offer the productivity benefits of AI without privacy risks like tracking your prompts and training on your data.
We’re not making AI features just for the sake of making AI features. They have to be actually useful in everyday use, starting with helping people get faster, high-quality answers to their questions. However, we recognize not everyone wants AI in their lives right now, and that’s OK with us. That’s why all our AI features are optional and can be turned off or tuned down.
To chat or not to chat.
Head to Duck.ai for free, proxied access to popular chatbots from OpenAI, Anthropic, Meta, and Mistral.
A search engine’s core job is to get you the high-quality information you want fast. AI can help with that job, including a new mode of information-seeking through chat. We’re finding that some people prefer to start in chat mode and then jump into more traditional search results when needed, while others prefer the opposite. (Some questions just lend themselves more naturally to one mode or the other, too.) So, we thought the best thing to do was offer both. We made it easy to move between them, and we included an off switch for those who’d like to avoid AI altogether.
If you want to start with chat, try Duck.ai (previously called DuckDuckGo AI Chat), a free and account-less way to access popular AI chatbots, privately. Models are periodically updated and currently feature GPT-4o mini and o3-mini from OpenAI, open-source models Meta Llama 3.3 and Mistral Small 3, and Claude 3 Haiku from Anthropic. Chats are anonymized via proxying and never used for AI model training.
You can navigate directly to https://duck.ai/ or via the optional chat icons within our search engine or browsers. (There's also a widget - on iOS for now.) You can also use the !ai or !chat bang search commands from any browser where you have DuckDuckGo search set as the default search engine.
One way to access Duck.ai is via the Chat icons in our desktop and mobile browsers.
If you’d rather start with traditional search results, simply use DuckDuckGo search as usual. AI-assisted answers – previously called DuckAssist – will automatically appear on the search results page for relevant English language queries. You can also manually trigger an AI-assisted answer on demand by pressing the “Assist” button under the search box, which appears on most queries. The answers source information from across the web, and like Duck.ai, they are completely free and private, with no sign-up required.
The “Assist” button lets you generate AI-assisted answers on demand.
We’ve continuously heard from users that they want more quick, at-a-glance answers, for a broad range of topics. For years, we’ve been doing that by working on search modules to provide instant answers for things like sports scores, local business information, where to watch movies and TV shows, and much more. Now, we are finding that we can significantly expand the scale of high-quality instant answers we can show with AI as we’re now serving millions of AI-assisted answers daily. Since we’ve introduced AI-assisted answers on our search results, overall user satisfaction with our search results has improved.
If you were unsatisfied after trying DuckDuckGo search in the past, now is a great time to try us again. We’re always improving. If you do try us or try us again, please set DuckDuckGo search as your default search engine or download our browser and make it the device default. It can take a moment to get used to something different, and setting the default is the best way to get over that hump.
How can I customize my search experience?
Navigate to the AI Features section of your search settings. If you really like our AI-assisted answers, change Assist to Often, which will make them appear over 20% of time. On the other hand, if you never want to see any AI features, turn Chat to Off and Assist to Never.
On DuckDuckGo browsers, you can choose whether the chat icon appears on the toolbar from within the ‘Duck.ai’ section in your browser settings.

Control how often you see AI-assisted answers from your search settings.
In addition to respecting our users’ choices, we respect publishers’ wishes to opt out of AI-assisted answers on DuckDuckGo and don’t penalize publishers for that choice. Even if they opt out as a source for our AI-assisted answers, they can stay opted into our other search results.
How am I protected?
When we generate AI-assisted answers, we anonymously call the underlying AI models used to summarize web sources on your behalf, so your personal information is never exposed to third parties. This method is called proxying. Duck.ai chats work similarly. To accomplish this technically, we remove your IP address completely and use our own IP address instead. This way, the proxied requests are coming from us, not you. For more information, please see the DuckDuckGo General Privacy Policy.
Duck.ai's "Recent Chats" let you pick up where you left off. Chats are saved locally on your device – not on DuckDuckGo or any other outside servers.
Within Duck.ai, recent chats are only stored locally on your device, not on DuckDuckGo servers. Not interested in storing your chats? You can disable the option altogether, or use the Fire Button to clear all your recent chats at once. Duck.ai chats are not used for any AI training, either by us or the underlying model providers. To respond with answers and ensure all systems are working, these providers may store chats temporarily, but we remove all the metadata so there’s no way for them to tie chats back to you personally. On top of that, we have agreements in place with all providers to ensure that any saved chats are completely deleted within 30 days. For more information, please see the DuckDuckGo AI Chat Privacy Policy and Terms of Use.
Clear your recent Duck.ai chats with the click of a button.
Are AI-assisted answers reliable?
When you search on DuckDuckGo, our AI-assisted answers are based on real-time web crawling, so they’re as reliable as the sources from which they are drawn. But even the most reliable sources can have errors, and mistakes can occasionally happen in the summarization process, too. That’s why we prominently display our cited sources: you can easily check them out and use your own judgment to make the final call.
Want to know where your AI-assisted answer came from? Check the sources below the answer and click through for a deeper dive into complex topics.
We also have a number of precautions in place. Out of the countless websites we could draw from, we try to weed out ultra-low-quality sources like spammy content farms and invasive people search sites, and we try to avoid satirical sites and opinion pieces.
You are a critical part of the process as well. “Was this helpful? 👍 👎” is displayed next to every AI-assisted answer. So, if you see a bad answer – or a great answer! – please let us know. We review it all as part of our quality control process.
Is this really free?
Yes! AI-assisted answers are integrated into DuckDuckGo search, which is always free to use, with no log-in required. (We make money from private search ads.) Chatting on Duck.ai is also free within a daily limit, which we implement while maintaining strict user anonymity, just like we do for our search engine. We plan to keep the current level of access free; we’re exploring a paid plan for access to higher limits and more advanced (and costly) chat models.
What’s next?
We are largely driving our AI roadmap based on your feedback, so please keep it coming—we appreciate it. Within Duck.ai, this includes adding newer models, voice and image support, and granting models web access. For AI-assisted answers on our traditional search engine, we’re making them faster and more interactive, answering more queries, and improving when they appear automatically, including for less straightforward queries.
In the meantime, give Duck.ai a try and keep an eye out for AI-assisted in your traditional search results. Head to your search settings if you want to see them more or less often.
2024-12-03, 14:00

2024 marks DuckDuckGo's 14th year of donations—our annual program to support organizations that share our vision of raising the standard of trust online. We are proud to donate to diverse group of organizations around the world that promote privacy, digital rights, access to information online, and a healthier online ecosystem.
This year, we’re donating $1,100,000, bringing DuckDuckGo's total donations since 2011 to $6,950,000. Everyone using the Internet deserves simple and accessible online protection; these organizations are all pushing to make that a reality. We encourage you to check out their valuable work below, alongside details about how our funds were allocated this year.
$100,000 to the Electronic Frontier Foundation (EFF)
“EFF's mission is to ensure that technology supports freedom, justice, and innovation for all people of the world.”
$75,000 to Public Knowledge
"Public Knowledge promotes freedom of expression, an open internet, and access to affordable communications tools and creative works. We work to shape policy on behalf of the public interest."
$50,000 to ARTICLE 19
"Established in 1987, ARTICLE 19 is an international non-profit organization that defends freedom of expression, fights against censorship, protects dissenting voices, and advocates against laws and practices that silence individuals, both online and offline."

$50,000 to Demand Progress
"DPEF educates our members and the general public about matters pertaining to the democratic nature of our nation’s communications infrastructure and governance structures, and the impacts of corporate power over our economy and democracy."
$50,000 to European Digital Rights (EDRi)
"The EDRi network is a dynamic and resilient collective of 50+ NGOs, as well as experts, advocates and academics working to defend and advance digital rights across Europe and beyond. For over two decades, it has served as the backbone of the digital rights movement and has achieved landmark successes in digital rights in Europe."
$50,000 to Fight for the Future
"Known for organizing some of the largest and most effective online campaigns in history, Fight for the Future’s mission is to ensure a just Internet and technology that is a force for empowerment and liberation, free of surveillance, censorship, and abuse of personal data."
$50,000 to The Markup
"The Markup challenges technology to serve the public good by producing investigative journalism, unique tools, and accessible resources to inspire action and agency."
$50,000 to OpenMedia
"OpenMedia is a community-driven organization that works to keep the Internet open, affordable, and surveillance-free. We operate as a civic engagement platform to educate, engage, and empower Internet users to advance digital rights around the world."
$50,000 to Restore the Fourth
“Restore the Fourth opposes mass government surveillance, and organizes locally and nationally to defend privacy and the Fourth Amendment.”
$50,000 to Signal
“Signal Technology Foundation protects free expression and enables secure global communication through open source privacy technology.”
$50,000 to the Surveillance Technology Oversight Project (S.T.O.P.)
“The Surveillance Technology Oversight Project (S.T.O.P.) advocates and litigates for privacy, working to abolish local governments’ systems of discriminatory mass surveillance."
$50,000 to Tech Policy Press

“Tech Policy Press promotes discussion, debate, and analysis of issues and ideas at the critical intersection of technology and democracy.”
$50,000 to the Tech Oversight Project
"Through engaging with lawmakers, exposing false narratives and bad actors, and pushing for landmark legislation, the Tech Oversight Project seeks to hold tech giants accountable for their anti-competitive, corrupting, and corrosive influence on our society and the levers of power."
$25,000 to Algorithmic Justice League (AJL)
“AJL’s harms reporting platform aims to capture people's lived experiences with AI harms, connect them with resources, and identify areas where there are no or few resources.”
$25,000 to Bits of Freedom

“Bits of Freedom shapes tech policy in order to facilitate an open and just society, in which people can hold power accountable and effectively question the status quo.”
$25,000 to the British Institute of International and Comparative Law (BIICL)
"The Competition Law Forum is a centre of excellence for European competition and antitrust policy and law at the British Institute of International and Comparative Law (BIICL)."
$25,000 to the Center for Critical Internet Inquiry (C2i2)

“UCLA Center for Critical Internet Inquiry (C2i2), housed in the UCLA Division of Social Sciences, is a critical internet studies community committed to reimagining technology, championing social justice, and strengthening human rights through research, culture, and public policy.”
$25,000 to Creative Commons (CC)

“Creative Commons (CC) is an international nonprofit organization dedicated to building and sustaining a thriving commons of shared knowledge and culture that serves the public interest.”
$25,000 to Digital Rights Watch

"Digital Rights Watch is Australia's leading digital rights organisation. They defend and promote privacy, democracy, fairness and fundamental rights in the digital age."
$25,000 to Gesellschaft für Freiheitsrechte (GFF)
"The Society for Civil Rights e.V. (Gesellschaft für Freiheitsrechte e.V. or "GFF") is a donor-funded organization from Germany that defends fundamental and human rights by legal means. The organization promotes democracy and civil society, protects against disproportionate surveillance and advocates for equal rights and social participation for everyone."
$25,000 to noyb
"noyb is committed to the legal enforcement of European data protection laws and has filed more than 850 cases against numerous intentional infringements by Big Tech companies - to make online privacy a reality for everyone."
$25,000 to the Open Home Foundation
“The Open Home Foundation fights for the fundamental principles of privacy, choice, and sustainability for smart homes - and for every person who lives in one. It is best known as the organization that owns and governs Home Assistant, among many other projects crucial to the open home."
$25,000 to the Open Rights Group (ORG)

"Open Rights Group is the UK’s largest grassroots digital rights campaigning organisation, working to protect everyone’s rights to privacy and free speech online."
$25,000 to the Open Source Technology Improvement Fund (OSTIF)
"Open Source Technology Improvement Fund helps critical open source projects with their security needs and is grateful for the continued support from DuckDuckGo. This funding is pivotal to ongoing operations, as it is one of our only donation sources that is not tied to any deliverable or project. Over the past year, OSTIF has been able to sustainably help critical open source projects improve their security posture, and in the process have found and fixed over 150 bugs and vulnerabilities."
$25,000 to Perl and Raku Foundation
"The Perl and Raku Foundation is a non-profit, 501(c)(3) which fulfills a range of activities including the collection and distribution of development grants, sponsorship and organization of community-led local and international Perl conferences, and support for community resources and user groups."
$25,000 to Privacy Rights Clearinghouse
"Privacy Rights Clearinghouse focuses on increasing access to information, policy discussions, and meaningful rights so that data privacy can be a reality for everyone."
$25,000 to Proof

"Proof is a new nonprofit journalism studio that is working to redefine and reimagine trustworthiness in news and investigative reporting."
$25,000 to the Tor Project
"At the Tor Project, we believe everyone should be able to explore the internet with privacy. We advance human rights and defend your privacy online through free, open source software and the decentralized Tor network."
2024-11-20, 12:30

Today, we are calling on the European Commission to launch three non-compliance investigations around Google’s obligations under the EU’s Digital Markets Act (DMA):
- On Google’s non-compliance with Article 6(11), which requires Google to share anonymized click and query data.
- On Google’s non-compliance with Article 6(3), which requires Google to implement choice screens and enable end users to easily change default search settings.
- On Google’s non-compliance with Article 6(4), which requires any downloaded search or browser app to have the ability to prompt users to set search defaults easily.
The DMA created these obligations to address Google’s scale and distribution advantages, which the judge in the United States v. Google search case found to be illegal. The judge specifically highlighted that 70% of queries flow through search engine access points preloaded with Google, which creates a “perpetual scale and quality deficit” for rivals that locks in Google’s position.
Unfortunately, Google is using a malicious compliance playbook to undercut the DMA. Google has selectively adhered to certain obligations – often due to pressure from the Commission – while totally disregarding others or making farcical compliance proposals that could never have the desired impact. As a result, the DMA has yet to achieve its full potential, the search market in the EU has seen little movement, and we believe launching formal investigations is the only way to force Google into compliance. The Commission has already demonstrated its ability to use such investigations effectively under the DMA.
While Google’s bad faith approach is not surprising, it should not go unnoticed. Any regulator looking to create enduring competition in the search market should take note of the tactics Google is using to thwart and circumvent its legal obligations.
We project Google’s Click-and-Query data sharing proposal eliminates ~99% of search queries.
Google’s exclusive default distribution deals mean they see many times more search queries than any competitor can, which gives them what’s called a “scale advantage.” In Article 6(11), the DMA directly addresses this scale advantage by mandating Google share anonymized click, query, ranking, and view data. This data would help search engines improve results quality, especially for less frequent (so-called “long-tail”) queries.
Google’s Click-and-Query obligation under the DMA, Article 6(11), reads:
“The gatekeeper shall provide to any third-party undertaking providing online search engines, at its request, with access on fair, reasonable and non-discriminatory [FRAND] terms to ranking, query, click and view data in relation to free and paid search generated by end users on its online search engines. Any such query, click and view data that constitutes personal data shall be anonymised.”
To comply with this requirement, Google announced the “Google European Search Dataset Licensing Program.” However, this data set has little to no utility to competing search engines due, in large part, to Google’s proposed anonymization method, which only includes data from queries that have been searched more than 30 times in the last 13 months by 30 separate signed in users. This method is conveniently overbroad: we extrapolate that Google’s dataset would omit a staggering ~99% of search queries including “longtail” queries that are the most valuable to competitors. Google is trying to avoid its legal obligation in the name of privacy, which is ironic coming from the Internet’s biggest tracker.
Part of our goal at DuckDuckGo has always been to prove that tech can make great products without exploiting people’s data or using mass surveillance. Our Privacy Policy explains how we go about doing this, for example, “we have no way to create a history of your search queries.” We do this by stripping out any metadata that can tie searches together made by the same individual, so re-identification cannot happen like in the memorable AOL case. For example, we may know that we got a lot of searches for "cute cat pictures" today, but we don’t know - and have no way to figure out - who actually performed those searches.
The fact is that most "rare" queries are actually just common words put in an order that isn’t searched very often. These queries are not inherently problematic since they cannot be traced back to any individual. So, instead of attempting to filter all of these relatively unique queries, we should instead focus on removing the subset of those queries that contain personal identifiers, like addresses and phone numbers or accidental pastes like user ids and passwords. Fortunately, there are relatively straightforward approaches to remove these types of queries that will result in much of the long tail data remaining available to improve search results.
This isn’t even the only part of the proposal that severely hampers the usefulness of the data:
- The proposal averages ranking data, which eliminates critical nuances. It also doesn’t provide anonymous ranking signals like dwell time or bounce rate.
- The proposal shares at best three-month old data, meaning the data is already stale when received because many results would no longer reflect current search trends.
- The proposal contains hardly any information on search modules, such as knowledge panel content, meaning information on much of the content on the search result page is not being shared.
We recognize that fine-tuning the right approach requires further considerations and, most importantly, testing and good faith cooperation from Google. Faced with Google’s continued obstruction, we believe that opening an official investigation is the only way to arrive at a workable proposal. We would like to help in that effort and believe there are ways for Google to provide a data set that is both privacy respecting and useful to competitors.
Google has so far completely ignored “easy switching” requirements.
The DMA includes provisions designed to facilitate easy switching of search engines and browsers, targeting Google’s entrenched hold over search and browser access points. Google’s obligation under Article 6(3) of the DMA reads:
“The gatekeeper shall allow and technically enable end users to easily change default settings on the operating system, virtual assistant and web browser of the gatekeeper.”
Despite this obligation, switching search engines on Android devices (which make up more than 60% of the mobile market in the EU) is still not “easy.” Before the DMA came into effect, it took more than 15 steps to switch your default search engine on Android and today that is still the case.
Zero changes have been made. What should happen is that users should be able to change their default search engine across every search access point in one click, similar to how a choice screen works, but currently choice screens are only shown on device onboarding. Users should be able to get back to a similar screen via a top-level device setting for default search, which we should be also able to guide users to directly from our app.
Similarly on Chrome, switching the default search engine has not been made any easier either. For example, there’s still no way to guide a user directly to the default search engine setting from the DuckDuckGo search homepage. And Google’s persistent dark pattern for search extensions on Chrome remains.
Google has completely ignored its easy switching obligations under the DMA. As a result, we believe the Commission must launch a non-compliance investigation to get Google to fulfill its requirements under the law. “Easy switching” should mean competition is actually one click away.
Google still hasn’t rolled out its updated Android choice screens to 250+ million EU Android users.
Article 6(3) DMA requires Google to show choice screens to end users “at the moment of the end users’ first use of an online search engine or web browser.”
Google’s search engine DMA choice screen is explicitly different from the choice screen Google implemented following the Android case. Key improvements have been made to its design, such as automatically showing taglines. But Google has not rolled out this updated DMA choice screen to all Android users, in breach of Article 6(3). Apple, for example, rolled out its DMA browser choice screen to its entire EEA user base and is planning to do so again after an investigation from the Commission – this time to Safari default users only.
A non-compliance investigation must therefore be opened to ensure that Google will fulfill its obligation and roll out both the DMA search engine and browser choice screens to all Android devices at once like they did on Chrome for desktop and iOS. When those Chrome choice screens rolled out, the positive competitive impact was evident: DuckDuckGo search queries on Chrome have increased by around 75% across the EEA. This rapid and stable growth in query volume shows pent-up demand by Chrome users for privacy-respecting search alternatives.
What can regulators learn from this?
Regulators around the world should be looking at what’s happening with the DMA, learn from how Google has been able to exploit its loopholes and circumvent it, and then take steps to make sure Google cannot continue to put up roadblocks in the way of progress and fair competition.
In the EU, Google chose to roll out self-serving compliance proposals around these obligations without engaging in meaningful consultations, leading to significant delays in achieving contestability and fairness, the objectives of the DMA. Given the opportunity, it should not come as a surprise that Google is taking advantage.
Instead, regulators and market participants should be able to review, test, and validate remedies before they are implemented to ensure they actually accomplish their intended purpose, while maintaining the regulatory authority to launch investigations and make changes after implementation, if necessary. Regulators can set additional criteria to make sure these interventions have the desired impact. For example, dominant firms could be required to demonstrate that consumers understand how to switch and that switching to a competitor is equivalently easy to sticking with the services from the dominant firm.
In addition, we believe the DMA doesn’t properly address Google’s scale advantage. Sharing click-and-query data is a critical intervention to address Google’s scale advantage, but alone, it isn’t sufficient to create a competitive search engine. As we’ve previously written, we believe the best and fastest way to level the playing field on search quality is for Google to provide access to its search results via real-time APIs (Application Programming Interfaces), also on FRAND (Fair, Reasonable, and Non-Discriminatory) terms. That means for any query that could go in a search engine, a competitor would have access to the same search results.
If Google is required to license its search results in this manner, this would allow existing search engines and potential market entrants to build on top of Google’s various modules and indexes, and offer consumers more competitive and innovative alternatives. In addition, while choice screens are an excellent mechanism to provide consumers access to competitors, they need to be shown periodically, at least yearly, to give competing search engines a chance to build awareness over time. We are happy to work with regulators to craft remedies that will create enduring search competition.
2024-10-23, 11:50

At DuckDuckGo, we know what it's like to turn a vision into a successful company. Our founder and CEO, Gabriel Weinberg, began DuckDuckGo’s journey to “raise the standard of trust online” from his basement in Pennsylvania and turned it into a browser and search engine used by millions of people around the world.
Today, this vision still inspires us. Each year, we donate to non-profit organizations that align with this vision, and now we're investing in companies that align with it as well.
As more and more consumers seek privacy-conscious technologies, we want to partner with other like-minded entrepreneurs and help turn their visions into reality. With the core objective of supporting consumer privacy technologies, DuckDuckGo is actively investing in early-stage companies as well as pursuing acquisitions and partnerships. We've actually already been doing this quietly for the last couple years, and we’re energized to do more. So, we'd love to hear from you and find ways to work together.
We are focused primarily on three domains:
- Search and browse: It's the core of our product and where we continue to invest most heavily.
- Consumer privacy technologies: This spring, we launched Privacy Pro, a 3-in-1 subscription service with VPN, Personal Information Removal, and Identity Theft Restoration. Our acquisition of Removaly was key to accelerating the development of our Personal Information Removal solution. We continue to look for other complementary technologies that could extend our offerings.
- Emerging technologies: We recently announced DuckDuckGo AI Chat, which offers private access to popular AI chatbots. We’re committed to investing in this emerging technology space and others, but only in ways that are privacy-respecting.
For early-stage investments, we are flexible on deal structure, aim to move quickly and are happy to co-invest with other companies, funds, and individuals. For acquisitions, we are open to a range of companies that share a commitment to protecting user privacy.
You can reach Mike Marino, SVP of Finance and Diana Chiu, Director of Corporate & Business Development directly at investments@duckduckgo.com.
2024-09-12, 12:39

Since the ruling in the U.S. v. Google search case was announced, there has been discussion about how to remedy Google’s dominance. As a company that operates a search engine that directly competes with Google, we have several ideas about how to craft a set of legal and technical interventions that can, in combination, effectively curb the advantages Google has gained through illegal use of their search monopoly. DuckDuckGo believes it is possible to put remedies in place that will establish enduring search competition, encourage innovation and new market entrants, and result in significant market share among multiple competitors.
However, there is no silver bullet remedy that, alone, will adequately address both Google’s scale and distribution advantage as well as ensure that Google cannot circumvent its obligations. Instead, the “remedy” must be a package of remedies that work together to effectively counteract the unlawful competitive imbalance.
Counteracting Google’s Scale Advantage with Access to Search Results
Many ideas on the table aim to counteract Google’s distribution advantage, but we believe it’s equally important to address Google’s scale advantage. Google’s exclusive default distribution deals mean they see way more queries than everyone else, a.k.a. their scale advantage. The court’s opinion quantifies this disparity:
More users mean more advertisers, and more advertisers mean more revenues…. Google’s scale means that it not only sees more queries than its rivals, but also more unique queries, known as “long-tail queries.” To illustrate the point, Dr. Whinston analyzed 3.7 million unique query phrases on Google and Bing, showing that 93% of unique phrases were only seen by Google versus 4.8% seen only by Bing.
Google uses this stream of information to continuously improve their results by running large-scale experiments in ways that no rival can because we’re effectively blinded. Google infers the best results based on queries it has seen before. If a search engine sees fewer – or often zero – similar queries, these inferences are less effective.
As the court describes the situation, Google’s scale advantage fuels a powerful feedback loop of different network effects that ensure a “perpetual scale and quality deficit” for rivals that locks in Google’s advantage.
Google’s exclusive defaults are part of a reinforcing feedback loop that gives them an insurmountable scale advantage and makes it difficult for rivals to compete.
The best and fastest way to level this playing field is for Google to provide access to its search results via real-time APIs (Application Programming Interfaces) on fair, reasonable, and non-discriminatory (FRAND) terms. That means for any query that could go in a search engine, a competitor would have access to the same search results: everything that Google would serve on their own search results page in response to that query. If Google is forced to license its search results in this manner, this would allow existing search engines and potential market entrants to build on top of Google’s various modules and indexes and offer consumers more competitive and innovative alternatives.
Today, we believe that we already offer a compelling search alternative with more privacy and fewer ads, relative to Google. We’ve also been working for fifteen years to make our search results on par in terms of feature set and quality by combining our own search indexes with those of partners like Apple, Microsoft, TripAdvisor, Wikipedia, and Yelp. However, we know that many consumers still prefer Google’s results due to the benefits of scale discussed above, and this intervention would erase that advantage, instantly making us and others much more competitive.
We’ve already seen some concerns about this remedy direction that we’d like to quickly address. First, licensing Google’s search results does not involve accessing any user data. This remedy will not invade user’s privacy, which is aligned with our vision as a company. We know from experience that this remedy can be implemented anonymously, and we can advise on that implementation. We can open up Google without opening up user data.
A second potential concern is that long-tail results on leading search engines could be similar in some cases, but that’s a feature not a bug. Google’s scale advantage gives them insights into which obscure links should be ranked higher, and so we should expect that when smaller search engines incorporate this information that some results would become more similar. However, licensing on FRAND terms should also allow competitor search engines to re-rank and mix results with other content, which will enable competitor search engines to produce different ranking algorithms based on the same underlying high-quality search results.
Additionally, FRAND licensing will allow other search engines to more competitively differentiate on things like privacy, design, and customization of the user interface and results page, while still providing high-quality results. For example, we can envision a universe of differentiated and innovative experiences, such as features that allow users to tweak ranking algorithms, features that bring more transparency to ranking algorithms, and other AI capabilities, all leveraging Google’s search result APIs. Future-looking use cases like these must be kept in mind, and FRAND API access is what is needed to power these types of search innovations.
A third concern is that competitor indexes could become too reliant on Google; however, if all the results that come through the APIs can also be used as an input into building search indexes, this would ensure that there is also a path to long term viability and independence for competitors. We, for one, would go further down this path. This could be accelerated if the APIs also provide access to Google’s anonymous ranking signals (for example, how often and quickly people in aggregate click back after visiting a link), which will help tune competitor indexes even faster as well as improve real-time reranking algorithms. That said, we recognize that licensing Google’s search results needs to be a long-term intervention because their scale advantage will persist as long as Google has much more significant market share than competitors.
There are historical precedents for this type of remedy as well. AT&T’s 1956 antitrust agreement required the company to license its patents on FRAND terms, which allowed existing and new companies to build on top of AT&T’s innovations. Similarly, the Telecommunications Act of 1996 encouraged competition in communications markets by requiring large telecommunications providers to interconnect their networks with new competitors on FRAND terms.
This is not a new technical challenge for Google either: Google already licenses their search results, including their ads, via real-time APIs to some competitors. It’s also not novel in antitrust, as API access was at stake in Microsoft’s antitrust settlement two decades ago. An API-based remedy also means that startups could immediately enter the search market rather than be forced to invest tens or hundreds of millions of dollars upfront to get started by acquiring and consuming massive data sets. It also protects nascent competition in AI-driven search by allowing them to use the APIs to ground answers in real-time.
Finally, we should note that the EU’s Digital Markets Act attempts to solve Google’s scale advantage by requiring Google to provide FRAND access to its “click and query data.” To date, this has been ineffective because Google has undermined the requirement by limiting the data they share to the point of being useless. However, while we believe that click and query data is not a substitute for FRAND access to search result APIs, we also believe that if implemented correctly it can complement and further accelerate the path to competitor independence. That’s because API access will be limited to queries a competitor search engine actually sees, whereas click and query data can be much broader, covering almost all the queries Google sees. Therefore, access to this data in a privacy-protective manner should also be given on FRAND terms.
Counteracting Google’s Distribution Advantage with a Ban on Self-Preferencing in Chrome and Android
Google likes to claim everyone chooses Google, but most consumers don’t: they just go with the default. The court outlines how staggering this default advantage is:
50% of all queries in the United States are run through the default search access points covered by the challenged distribution agreements…. An additional 20% of all searches nationwide are derived from user-downloaded Chrome, a market reality that compounds the effect of the default search agreements. That means only 30% of all [general search engine] queries in the United States come through a search access point that is not preloaded with Google. Additionally, default placements drive significant traffic to Google. Over 65% of searches on all Apple devices go through the Safari default. On Android, 80% of all queries flow through a search access point that defaults to Google.
The court also consolidates evidence highlighting that large percentages of consumers don’t even realize they are using Google because of these defaults:
- An internal Google email in 2016 acknowledged that “users on Edge don’t even realize they aren’t using Google.”
- A 2018 Google study revealed there was “substantial user confusion regarding which browser and [general search engine] was in use.”
- A 2020 Google study found that over 50% of U.S. iPhone users were “unsure” what search engine powered Safari, concluding users are “often unaware they’re using Google.”
Users are confused and competition is crushed. As a result, Google shouldn’t be able to self-preference its search engine on Chrome and Android, which were developed to expand the reach of Google Search. Within these products, there should be no preset search default. Instead, these platforms need user-friendly settings based on sound principles that provide for:
- Regular access to well-designed choice screens that put users in charge of choosing their search engine default when setting up Android or Chrome, and periodically thereafter. Choice screens should set the search engine across all search access points on Android and Chrome.
- An easy way for users to navigate back to these settings.
- A one-click mechanism for any rival search engine to switch these settings and offer itself as a default search engine when users visit their website or app.
Image of the search engine choice screen on Android in the EU.
Banning self-preferencing must also include a prohibition on dark patterns, and all remedies must be subject to anti-circumvention provisions. For example, these restrictions should prohibit Google from discouraging users from installing rival apps or search extensions, or encouraging them to switch back to Google.
Unfortunately, a self-preferencing ban won’t create enduring competition by itself. However, as rivals can innovate on top of Google’s search results, and consumers become aware of rival brands and their increased quality, this increased access to consumers will accelerate competition in the search market.
Counteracting Google’s Distribution Advantage by Restricting Exclusionary Contracts
The court has already declared Google’s exclusionary contracts unlawful. While there are methods outside of these exclusive defaults to access search engines, the court recognizes that these “channels are far less effective at reaching users. That is due in part to users’ lack of awareness of these options and the ‘choice friction’ required to reach these alternatives.”
Restricting these exclusive agreements is therefore essential to help open up access to the search market. However, just restructuring these contracts by itself won’t do much because it won’t directly counteract Google’s entrenched advantage. For that, we need to look to the remedies discussed above.
On Accountability
Even the most well-crafted remedies will ultimately fail if Google is in charge of designing and implementing them, as has been the case in the EU. We’ve seen firsthand how Google has easily and repeatedly avoided complying with both the letter and the spirit of the law. Consequently, an independent monitoring body made up of technical experts and affected market participants must be fully empowered to keep Google honest. We should expect that this monitoring entity will need to be in place for as long as the remedies are in place. We cannot let the fox guard the henhouse.
On Structural Remedies
We are not opposed to structural remedies, but they would need to be paired with the additional interventions outlined in this post. In other words, structural changes to Google could theoretically be an accelerant in some circumstances, but regardless are not a replacement for FRAND access to search results and click and query data together with a ban on Google-self preferencing and a restriction on exclusive contracts. And we can envision some scenarios where a particular structural remedy could be more harmful to us than helpful.
A Long Road Ahead
Counteracting the entrenched competitive imbalance that Google’s default advantage has afforded them will not happen overnight. Realistically, it will take years for competition to take hold, and a fully-funded and motivated Department of Justice will need to be involved for the long haul. However, we are confident that a package of well-implemented and carefully monitored remedies, each designed to address a specific choke point, can work to create enduring competition in the search market.
2024-06-06, 11:36
DuckDuckGo AI Chat is an anonymous way to access popular AI chatbots – currently, Open AI's GPT 3.5 Turbo, Anthropic's Claude 3 Haiku, and two open-source models (Meta Llama 3 and Mistral's Mixtral 8x7B), with more to come. This optional feature is free to use within a daily limit, and can easily be switched off.
- Chats are private, anonymized by us, and not used for any AI model training.
- Find DuckDuckGo AI Chat at duck.ai, duckduckgo.com/chat, on your search results page under the Chat tab, or via the !ai and !chat bang shortcuts. They all take you to the same place.
- Improvements are already on the way. Our roadmap includes adding more chat models and browser entry points. We’re also exploring a paid plan for access to higher daily usage limits and more advanced models.
Why did you make AI Chat?
Find AI Chat on your search results page for easy switching between the two.
Our mission is to show the world that protecting your privacy online can be easy. We believe people should be able to use the Internet and other digital tools without feeling like they need to sacrifice their privacy in the process. So, we meet people where they are, developing products that add a layer of privacy to the everyday things they do online. That’s been our approach across the board – first with search, then browsing, email, and now with generative AI via AI Chat.
DuckDuckGo AI Chat is a free, anonymous way to access popular AI chatbots. According to recent Pew reporting, adults in the U.S. have a negative view of AI's impact on privacy, even as they're feeling more positive about AI's potential impact in other areas. "About eight-in-ten of those familiar with AI say its use by companies will lead to people’s personal information being used in ways they won’t be comfortable with (81%) or that weren’t originally intended (80%)." Even so, another recent report shows a steady uptick in the share of U.S. adults who are using chatbots for work, education, and entertainment. If you're interested in AI chatbots but share those privacy concerns, DuckDuckGo AI Chat is for you.
In the industry-wide race to integrate generative AI, there’s a lot of pressure to add AI features just for the sake of saying you have them. We’re taking a different approach. Before adding any AI-assisted features to our products – first DuckAssist, our AI-enhanced Instant Answer, and now AI Chat – we think carefully about how to make them additive to the search and browse experience, and we roll them out cautiously to ensure this is the case. We also recognize these features aren’t for everyone, so we’ve made our AI-assisted features totally optional; if you’re not interested, you can easily switch them all off.
We view AI Chat and search as two different but powerful tools to help you find what you’re looking for – especially when you’re exploring a new topic. You might be shopping or doing research for a project and are unsure how to get started. In situations like these, either AI Chat or Search could be good starting points. If you start by asking a few questions in AI Chat, the answers may inspire traditional searches to track down reviews, prices, or other primary sources. If you start with Search, you may want to switch to AI Chat for follow-up queries to help make sense of what you’ve read, or for quick, direct answers to new questions that weren’t covered in the web pages you saw. It’s all down to your personal preference. That’s on top of AI Chat’s unique generative capabilities, like drafting emails, writing code, creating travel itineraries, and much more.
Since it can be useful to switch back and forth, we’ve made AI Chat accessible through DuckDuckGo Private Search for quick access: after you make a search, just click on the Chat tab underneath the search bar to keep exploring the topic. You can also get to AI Chat directly by navigating to duck.ai or duckduckgo.com/chat; from there, it’s easy to jump back into traditional search using the top navigation.
How does it work … and how is it private?
AI Chat is always anonymous. Want to start over? Hit the Fire Button to delete your current conversation.
When you land on the AI Chat page, you can pick your chat model – currently, OpenAI’s GPT 3.5 Turbo, Anthropic’s latest generation Claude 3 Haiku, and open-source options Mixtral 8x7B and Meta Llama 3 – and start using it just like any other chat interface. Just like searches on DuckDuckGo, all chats are completely anonymous: they cannot be traced back to any one individual. To accomplish that technically, we call the underlying chat models on your behalf, removing your IP address completely and using our IP address instead. This way it looks like the requests are coming from us and not you. Within AI Chat, you can use the Fire Button to clear the chat and start over.
In addition, DuckDuckGo does not save or store any chats. To respond with answers and ensure all systems are working, the underlying model providers may store chats temporarily, but there’s no way for them to tie chats back to you, personally, since all metadata is removed. (Even if you enter your name or other personal information into the chat, the model providers have no way of knowing who typed it in – you, or someone else.) We have agreements in place with all model providers to ensure that any saved chats are completely deleted by the providers within 30 days, and that none of the chats made on our platform can be used to train or improve the models. For more information, please see the DuckDuckGo AI Chat Privacy Policy and Terms of Use.
Is it really free?
Yes! AI Chat is free to use, within a daily limit – which we implement while still maintaining strict user anonymity, just like we do for our search engine. We are planning to keep the current level of access free and exploring a paid plan for access to higher limits and more advanced (and costly) chat models.
What’s next?
We’re excited to spread the word about AI Chat, but there are already improvements on the way. Keep an eye out for new capabilities, like custom system prompts, and general improvements to the AI Chat user experience. We’re also planning to add more chat models – potentially including either DuckDuckGo- or user-hosted options. If you’re interested in seeing a particular chat model or feature added in the future, please let us know via the Share Feedback button in the AI Chat screen.
Ready to give it a spin? Head to duck.ai or duckduckgo.com/chat. You can also find it on your search results page – the Chat tab is just under the search box, on the right side, alongside Images and Videos on the left. If you’re a fan of our bangs, you can also initiate an AI chat by starting your search query with !ai or !chat. Not for you? Head to the Search settings menu to disable AI Chat, DuckAssist, or both.
Happy chatting!
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
4. NAKED SECURITYby Sophos NewsWide range of security and privacy topics.
2026-07-15, 00:00
Categories: Threat Research
Tags: advisory, Vulnerabilities, SonicWall
2026-07-07, 00:00
<p>An X-Ops analysis of how AI coding agents trigger endpoint detection rules designed for adversaries</p>
Categories: Threat Research
2026-07-02, 00:00
Credentials harvested through supply chain compromises enable large‑scale ransomware deployment
Categories: Threat Research
Tags: Vect, TeamPCP, Ransomware
2026-06-17, 00:00
Amid discussions about how artificial intelligence can facilitate cybercrime, some threat actors remain skeptical
Categories: Threat Research
Tags: AI, Dark Web, underground
2026-06-11, 00:00
209 patches + 388 advisories = welcome to summer 2026
Categories: Threat Research
Tags: x-ops, Patch Tuesday, MICROSOFT PATCH TUESDAY
2026-06-04, 00:00
<p>Following a certification test, Sophos X-Ops found an unexpected guest had hitched a ride</p>
Categories: Threat Research
Tags: Crypto mining, Supply chain
2026-06-02, 00:00
AI accelerated tool development and testing, but humans drove the workflow
Categories: Threat Research
Tags: AI, EDR
2026-05-20, 00:00
<p>A malicious VS Code extension led to cloned private repositories, reportedly offered for sale on a criminal forum</p>
Categories: Threat Research
Tags: GitHub, Supply chain
2026-05-19, 00:00
Brute-force attempts against SMB services can be early signs of an attack
Categories: Threat Research
Tags: Ransomware, WantToCry, SMB
2026-05-14, 00:00
<p>Sophos X-Ops looks at the Atomic macOS Stealer and its capabilities</p>
Categories: Threat Research
Tags: MacOS, AMOS, infostealer
2026-05-13, 00:00
With advisories, this month’s count approaches 300 – though many are already in place
Categories: Threat Research, X-ops
Tags: Patch Tuesday, MICROSOFT PATCH TUESDAY
2026-05-12, 00:00
<p>Seven things security teams can start doing today to reduce risk</p>
Categories: Threat Research
Tags: AI, CISO, risk
2026-05-07, 00:00
<p>A malicious imitation of Anthropic’s Claude site leads to DLL sideloading – and a backdoor</p>
Categories: Threat Research
Tags: Claude, Beagle, Backdoor, malvertising, AI, DONUT, DLL sideloading, Sophos X-Ops
2026-05-01, 00:00
Categories: Threat Research
Tags: advisory, Linux, Copy Fail
2026-04-29, 00:00
Categories: Threat Research
Tags: advisory, NPM, SAP
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
5. KREBS ON SECURITYby Brian KrebsAbout hackers, malware and scams on Internet.
2026-07-22, 01:10
The home appliance giant LG Electronics USA said this week it plans to suspend any apps built for its smart TVs that turn one’s television into an always-on residential proxy node. The move comes less than a month after researchers found that more than 42 percent of games and other apps available for download on LG’s webOS store allow unknown third-parties to route their Internet traffic through a user’s TV.

Proxy SDK prevalence among smart TV apps for LG (webOS) and Samsung (Tizen OS) televisions. Image: Spur.us.
On July 2, we featured research by the security firm Spur that examined the prevalence of residential proxy software development kits (SDKs) in smart TV apps. Spur found more than 42 percent of apps available for download on LG smart TVs include SDKs that turn one’s television in a proxy node indefinitely, and that more than a quarter of the apps made for Samsung’s Tizen operating system had similar residential proxy components.
Responding to questions about Spur’s research, LG Senior Vice President John Taylor told KrebsOnSecurity the company was working with app developers to remove the residential proxy option from their apps on the webOS platform. Developers that fail to comply, he said, will find their apps suspended.
“A residential proxy network is not an intended use for LG smart TVs, and LG Electronics is working with developers to remove the residential proxy option from their apps on the webOS platform,” Taylor said. “If this option is not removed, these apps will be suspended.”
Taylor said LG is committed to keeping residential proxy networks out of its smart TV apps going forward, and that the company’s review of those apps is “well underway now.”
“As part of our ongoing efforts to enhance platform quality and the user experience, LG will continue to strengthen our evaluation process for developer-submitted apps, including those that incorporate residential proxy SDKs,” Taylor wrote in an emailed statement.
App makers looking for ways to monetize their creations can turn to residential proxy providers, which pay developers to include SDKs that turn the user’s device into a residential proxy node that is rented to paying customers. In the case of LG and Samsung smart TVs, Spur found residential proxy SDKs bundled with everything from simple games like Pac-Man to screensavers and file utilities.

A Pac-Man smart TV app from Bright Data offers users the choice between viewing ads in the game or agreeing to allow their TV to serve as a residential proxy node. Image: Spur.us.
Spur’s report found the residential proxy network Bright Data accounted for a majority of proxy SDKs across both Samsung and LG smart TVs. Bright Data did not respond to requests for comment.
Bright Data and other proxy providers named in Spur’s report all say they follow rigorous know-your-customer processes to validate legitimate uses of their services, which is often heavily tied to content-scraping activities by said customers. The proxy companies also say they incorporate technological countermeasures to prevent proxy service customers from being able to interact with and control other devices on the proxy user’s local network.
Spur argues the problem is not that residential proxy networks exist, but rather that they are being embedded at scale in devices that most consumers do not think of as computers and are not equipped to audit.
“A one-time consent prompt buried in a TV app is not a substitute for meaningful transparency, ongoing control, and platform oversight,” Spur’s Trevor Sutter wrote. “The risk is amplified when consent comes from individuals within the household who use the device but shouldn’t give consent, such as minors.”
LG’s announcement that it is culling residential proxy SDKs from its app store is welcome news, but the company recently came under fire for another questionable partnership: Pimping McAfee security products via software drivers included in its high-end LCD monitors.
Earlier this week, the Youtube channel Gamers Nexus showed that certain LG LCD monitors will automatically install an app that promotes paid McAfee antivirus subscriptions, and that the app arrives through Windows Update without an approval prompt.
2026-07-14, 19:22
Microsoft Corp. today released software updates to plug at least 570 security holes in its Windows operating systems and other software, almost triple the number of vulnerabilities the software giant fixed in its record-smashing Patch Tuesday release last month. Microsoft attributed the burgeoning patch counts to vulnerability discoveries aided by artificial intelligence.

Nearly 60 of the bugs quashed in July’s Patch Tuesday earned a “critical” severity rating, meaning miscreants or malware could use them to seize remote control over a Windows device with little or no help from the user. Microsoft also addressed three zero-day flaws, including two that are already being exploited in the wild.
Two of the zero-day weaknesses allow an attacker to elevate their user rights on a Windows system, as do approximately 250 other elevation of privilege flaws fixed this month; they include CVE-2026-56155 — an Active Directory Federation Services bug — and CVE-2026-56164, a Microsoft Sharepoint vulnerability.
CVE-2026-50661 is a security feature bypass in Windows BitLocker that could allow attackers to gain access to encrypted data if they have physical access to the device. Microsoft said this bug has been detailed publicly, but that it is not aware of any active exploitation.
In a blog post on July 9, Microsoft Executive Vice President Pavan Davuluri wrote that Windows users will notice “a higher volume of security updates included in each security release” as a result of AI aiding in the discovery of vulnerabilities.
“The pace of vulnerability discovery is changing with advances in AI making it possible to find more issues, faster, across more code, with new mechanisms that can accelerate both discovery and analysis,” Davuluri wrote.
Jack Bicer, director of vulnerability research at Action1, called attention to CVE-2026-48561, a remote code execution flaw in Microsoft Copilot (with a 9.6 CVSS threat score) that allows an unauthorized attacker to execute code over the network. Microsoft says an attacker could exploit this bug by hosting a malicious website that causes Microsoft Edge for Android to automatically send crafted prompts to Copilot when a user visits the site.
As AI advances the state of vulnerability discovery and remediation, it is also making it easier for attackers to quickly devise working exploits for known software flaws. Microsoft has long labeled security bugs using its “exploitability index,” which is Redmond’s best guess as to how likely it is that attackers will be able to figure out a reliable way to exploit a given vulnerability.
But Satnam Narang, senior staff research engineer at Tenable, argues that Microsoft’s exploitability index needs to do a better job of shifting with the machine speed of discovery. For example, Microsoft originally gave this month’s SharePoint zero-day an exploitability rating of “less likely,” although the flaw was added to CISA’s Known Exploited Vulnerabilities list on July 1.
“Anthropic’s Red Team’s own findings for known vulnerabilities (n-days) revealed how fragile this system has become, with its Mythos Preview model being able to produce proof-of-concept exploits for 13 of 14 vulnerabilities that were rated ‘Exploitation Less Likely’ or ‘Exploitation Unlikely,'” Narang said. “What this means is that our way of looking at Patch Tuesday has changed, because the exploitability index is centered around humans, not AI tools, and as these tools continue to improve, defense needs to improve alongside it.”
Chris Goettl at Ivanti observed that the record patch numbers from Microsoft come as a number of other major software makers are increasing their patch cadence, including Adobe which announced today it is moving to twice-monthly security bulletins published on the 2nd and 4th Tuesday of each month (Adobe also cited AI for accelerating their patch cycles). Cisco, Mozilla and Oracle also are shipping updates more frequently, while Google’s patch batches in June 2026 totaled more than 900 security fixes, Goettl noted.
Backing up your Windows system and/or data is always a good idea before applying operating system updates. Given the volume of patches addressed this month it may be wise for end users to wait a few days before applying these fixes. It’s not uncommon for security patches to introduce system stability issues, and those chances probably increase quite a bit with the gigantic patch count released today.
Further reading:
2026-07-13, 15:03
The Cybersecurity and Infrastructure Security Agency (CISA) has issued a postmortem on a recent data leak in which a contractor published dozens of internal CISA credentials — including AWS Govcloud keys — in a public GitHub repository for almost six months before being notified by KrebsOnSecurity. Experts say the gaps identified in the agency’s initial response provide important lessons that all security teams should absorb.
![]()
On May 15, 2026, the security firm GitGuardian asked for help in notifying CISA about the existence of a public GitHub repository called “Private CISA” that included 844 MB of sensitive CISA-related data. One of the exposed files, titled “importantAWStokens,” included the administrative credentials to three Amazon AWS GovCloud servers. Another file — “AWS-Workspace-Firefox-Passwords.csv” — listed plaintext usernames and passwords for dozens of internal CISA systems.
CISA quickly acknowledged our initial alert, but took more than 48 hours to invalidate the AWS keys and many other important secrets leaked in the GitHub repo. In its report on the data leak, CISA said the complexities of the agency’s systems and interconnections with federal and industry partners caused its key rotation to take longer than anticipated.
“Drawing on this experience, CISA encourages others to maintain mature and well-tested key management capabilities,” the report notes.
CISA also admitted it can do better when it comes to responding to security incident notifications from external parties. The postmortem stresses that clear and distinct reporting channels are essential to ensure that incidents affecting the organization itself are handled differently from those involving its products or customers.
“In CISA’s case, these channels were not well defined, leading the security researcher to try multiple avenues – including emailing the contractor, submitting through CISA’s vulnerability disclosure platform (which is intended for vulnerabilities impacting the broader cybersecurity community), and ultimately involving a reporter,” reads the analysis written by Preston Werntz and Brad Libbey, the acting chief information officer and acting chief information security officer at CISA, respectively.
CISA said it is refining its reporting channels to make them easier and faster for researchers. “Additionally, while many researchers rely on the security.txt file, organizations can ensure clarity by publishing reporting instructions in multiple prominent locations,” the CISA authors wrote.
Guillaume Valadon, the GitGuardian researcher who first contacted KrebsOnSecurity about the exposed CISA credentials, said CISA ignored nine automated alerts about the exposed credentials prior to our notification on May 15. Valadon’s company constantly scans public code repositories at GitHub and elsewhere for exposed secrets, automatically alerting the offending accounts of any apparent sensitive data exposures.
“Letting nine notification emails go unanswered is how a one-day incident becomes a six-month exposure,” Valadon wrote in an analysis of CISA’s report. “Make it trivial to report a leak about you, not just about your products. The person reporting a leak to you is not the threat. Publish a security.txt, but do not stop there. Put reporting instructions in several prominent places, and make sure a report about your own infrastructure does not land in a product-bug queue.”
The report’s authors also emphasized the importance of continuously scanning public code repositories like GitHub for exposed secrets, and said CISA has since rotated all secrets and created an action plan to improve management of developer secrets and to better monitor for them going forward.
The report notes that while CISA had developed a playbook for responding to cybersecurity incidents, that playbook somehow didn’t include what to do in situations involving GitHub or other cloud services. Valadon said the report validates the need to scan continuously — not just quarterly — for exposed secrets.
“The Private-CISA repository sat public for six months,” Valadon wrote. “Continuous monitoring of public GitHub surfaced it. Comprehensive internal scanning could have caught the plaintext passwords and committed backups long before they left the building.”
CISA gave itself passing grades on several areas of security preparedness that it said helped the agency gauge the scope and impact of the exposed secrets, including enhanced logging capabilities, and the adoption of zero-trust principles in both its production and development systems. CISA said those detailed logs allowed it to show that no customer or mission data was exposed, and that the leaked credentials were not used outside of CISA’s environments. The agency said the contractor who exposed the secrets had their system access revoked.
Valadon reckons the biggest takeaway is the CISA postmortem itself, and praised the agency for being transparent about what worked and what didn’t.
“To my knowledge, it is also the first time a national cybersecurity agency has publicly advocated for secrets scanning and for simplifying relations with security researchers,” Valadon wrote. “That is exactly the incident communication we should expect from every organization.”
2026-07-08, 12:31
A cybersecurity startup dangling millions of dollars to acquire zero-day security vulnerabilities in popular software is run by a pair of far-right conspiracy theorists and convicted felons whose most recent ventures included fake intelligence companies and a now-defunct AI-based lobbying platform they operated under assumed names.
The X/Twitter account IRIS C2 (@C2IRIS) has gained more than 4,000 followers since its creation in January 2025, posting frequently about security vulnerabilities, AI and software exploits. IRIS C2 says it is a company in McLean, Va. that sells offensive cybersecurity capabilities.

The IRIS C2 website dangles the possibility of million-dollar payouts for exploits to attract talent.
“Our business model is this,” reads a pinned post on top of the IRIS C2 account on X. “Attract the very best vulnerability researchers and exploit developers in the world to join our company. This mostly revolves around junior engineers with raw talent/extremely high IQ. We don’t care if they have a college degree/industry experience.”
The website linked in that profile — irisc2[.]com — says the company is hiring for a number of open positions, and a recent post on its LinkedIn page enthuses about an overwhelming number of applications from potential employees. The website claims IRIS C2 is in the business of acquiring “zero-day exploits, individual primitives, partial chains, and full capabilities across all major platforms. Payouts range from $10,000 to $7 million depending on target, reliability, and operational value.”
The government contracting portal g2exchange.com reports that irisc2[.]com is operated by a business based in Virginia called Calvexa Group LLC. The “contact” link on the website for Calvexa Group — calvexagroup[.]com — forwards visitors to irisc2[.]com. G2Exchange shows that while Calvexa Group LLC is registered as a federal contractor, it does not appear to be working on any direct government contracts.
A search on the Arlington, Va. address listed in the incorporation records for Calvexa Group LLC finds the property is occupied by Jack Burkman, the 60-year-old founder and managing partner of the lobbying firm Burkman & Associates. When approached with questions about IRIS C2, Burkman referred further inquiries to his longtime associate, 28-year-old Jacob Wohl.

Jack Burkman (left) and Jacob Wohl, at a press conference in August 2020. Image: Wikipedia.
Burkman and Wohl have a storied history of creating fake intelligence companies and using them to spread false claims about and frame public figures, including fabricated sexual assault claims against then FBI director Robert Mueller, and Pete Buttigieg, then mayor of South Bend, Indiana and a Democratic candidate for the presidency. In 2019, Burkman and Wohl held press conferences falsely alleging extramarital affairs by Sen. Elizabeth Warren (D-Mass.) and then-2020 presidential candidate Kamala Harris.
In the wake of the 2020 presidential election, Wohl and Burkman were prosecuted by multiple U.S. states for making thousands of robocalls to residents of battleground states and disseminating false claims about mail-in ballots. They were indicted in Cleveland on 15 felony counts of orchestrating a robocall scheme aimed at suppressing the black vote in Detroit, and were sentenced in late 2025 to probation after their appeals to dismiss the charges were rejected.
In 2022, Wohl and Burkman both pleaded guilty to a single felony charge of telecommunications fraud in Ohio, and sentenced to a fine, probation, and community service. In March 2023, a judge in a New York civil case ruled that Wohl and Burkman had violated federal and state civil rights laws, and the two agreed to pay a $1 million settlement.
In June 2023, the Federal Communications Commission (FCC) imposed a $5.1 million fine against Wohl and Burkman for their robocall campaigns, at the time the largest fine ever sought by the FCC under the Telephone Consumer Protection Act.

Jacob “Jay” Wohl’s GitHub account.
By the age of 17, Wohl had started multiple investment firms, and cultivated the nickname “Wohl of Wall Street” after appearing on Fox News in 2015 to discuss his new hedge funds. In 2017, the Arizona Corporation Commission charged Wohl and his investment funds with 14 counts of securities fraud, and ordered him to pay $35,000 in restitution. In 2019, Wohl pleaded guilty in California to four felony counts of selling unregistered securities and was sentenced to two years of probation.
The market for previously unknown security vulnerabilities has always been populated by a colorful mix of researchers, academics, charlatans, clout-chasers and people actively involved in cybercrime communities. But the market for selling offensive security services to the U.S. government tends to be far more circumspect. Plenty of government contractors recruit vulnerability researchers and pay for the exclusive rights to novel software exploits, yet none of them do so quite as brazenly and openly as IRIS C2.

Recent posts from the Twitter/X account IRISC2 (@c2iris).
Indeed, KrebsOnSecurity was unaware of IRIS C2 until last month, when an attendee at a regional cybersecurity conference shared that Wohl and Calvexa Group were pestering people at the conference about selling their vulnerability research.
In an interview with KrebsOnSecurity, Wohl said Mr. Burkman was not involved in the day-to-day operations of IRIS C2. Wohl shared that IRIS C2 originally began as a penetration testing company, but shifted its focus recently to selling phone-hacking services to the government. Several times throughout the interview, Mr. Wohl mentioned working on federal government contracts, but when pressed for specifics said he was not at liberty to speak publicly about them.
Mr. Wohl said he does not have any formal education or training in computer science or information security, and that most of his knowledge on the matter is self-taught.
“I know more about tech than anyone,” Wohl bragged. “My background has always been extremely technical, and I’ve always been deeply into tech. People know me as someone who is able to create spectacularly exquisite capabilities that would make your head spin.”
Wohl said security researchers bring the company unique vulnerability findings “on a regular basis,” but that in many cases those findings are preliminary and not fully fleshed-out.
“Let’s say someone finds a flaw in a media decoder on a phone,” Wohl said. “A lot of times what we receive is an exploit primitive, where the idea is there but the [execution] needs work. You need that exploit to be stable and reliable, and that’s what we do.”
Wohl claims IRIS C2 has approximately 40 employees, although he said none of them are allowed to list their employment on LinkedIn for operational security reasons. In May, the author of the IRIS C2 account on X said that his girlfriend had no idea what he did for a living. But if IRIS C2 has any other employees, they may be similarly unaware of Mr. Wohl’s history of outright fabrications — or even his real name.
In September 2024, Politico reported that Burkman and Wohl were bragging about big companies supposedly buying services from their now-defunct company LobbyMatic, which claimed to use artificial intelligence to assist in political lobbying efforts. However, Politico found the pair were running the company using pseudonyms, with Wohl reportedly adopting the name “Jay Klein” and Burkman using the moniker “Bill Sanders.” Politico reported that two of the former LobbyMatic employees resigned after learning of their true identities, while other employees only learned after they had left the company.
Update, July 9, 9:44 a.m. ET: Several readers pointed our attention to a March 31 publication from journalist Molly White, which reported that Burkman and Wohl were paid a $300,000 retainer by a Canadian cryptocurrency fraudster wanted by the United States and several other countries for allegedly stealing $65 million from the crypto platforms KyberSwap and Indexed Finance. According to that report, the two were hired to pursue a “presidential pardon to avert a miscarriage of justice” on behalf of the accused hacker, who has not yet been convicted.
2026-07-02, 19:27
The Federal Bureau of Investigation (FBI) said today it worked with industry partners to seize hundreds of domains associated with NetNut, a sprawling residential proxy service operated by the publicly-traded Israeli company Alarum Technologies [NASDAQ: ALAR]. The action comes roughly two weeks after KrebsOnSecurity published findings from multiple security firms connecting NetNut to the Popa botnet, a collection of at least two million devices that have been compromised by malicious software with little or no consent from victims.

The NetNut homepage today was replaced by this seizure banner from the FBI.
On June 19, three different security firms issued similar findings: That NetNut is a residential proxy network which populates a botnet called Popa, and distributes software for devices commonly found in homes, such as smart TVs and streaming boxes. NetNut’s software turns those systems into always-on residential proxy nodes that are rented to others, who predominantly use them to relay abusive and intrusive Internet traffic, such as mass content scraping, advertising fraud, and account takeover activity.
Earlier today, NetNut’s homepage was replaced with a seizure notice from the FBI and the Internal Revenue Service Criminal Investigation division. The seizure notice thanked Google, Lumen, Shadowserver and other industry partners for their help in dismantling hundreds of domains tied to the Popa botnet, which experts say has long been synonymous with NetNut’s residential proxy infrastructure.
In a blog post published today, the Google Threat Intelligence Group (GTIG) said NetNut’s proxy network is widely resold and white-labeled by a number of third-party proxy providers, and that its services are heavily sought out by cybercriminals seeking to obfuscate the source of their malicious traffic. The GTIG said that in a single week during June 2026, they observed 316 distinct clusters of threat actors using suspected NetNut exit nodes, including cybercriminal and espionage groups.
“These bad actors can use NetNut to mask their origin IP address when accessing victim environments, accessing their own infrastructure, and conducting password spray attacks,” Google’s GTIG wrote. “Furthermore, when a consumer device becomes an exit node, unauthorized network traffic passes through it. This means bad actors can access other private devices on the same home network, effectively exposing them to Internet threats.”
Google said it disabled Google accounts and services used by NetNut for malware command and control, and that it shared technical intelligence on NetNut’s software development kits (SDKs) and backend infrastructure with platform providers, law enforcement and research firms. The company also disabled apps known to bundle NetNut’s various SDKs.
Omer Weiss, legal counsel for NetNut parent Alarum Technologies, said the company was aware of the FBI seizure and cooperating with investigators.
“Alarum takes this matter seriously and will fully cooperate with law enforcement to ensure any misuse of its infrastructure is thoroughly investigated and those responsible are held to account,” Weiss said in a written statement.
Benjamin Brundage is founder of the proxy tracking service Synthient, one of the companies that published evidence last month linking the Popa botnet to NetNut and Alarum Technologies. Brundage said the domain seizures appear to have disrupted both the Popa botnet and the NetNut proxy network that rides on top of it.
Brundage said NetNut’s apparent demise is likely to be a great disadvantage for the cybercrime community, which was already reeling from legal actions by Google earlier this year that seized infrastructure for NetNut’s biggest competitor — IPIDEA.
“I think this takedown is going to have a big impact, because NetNut gained significant popularity after the IPIDEA takedown,” he said. “Also NetNut has been incredibly common among resellers, and they were on par with IPIDEA in terms of their daily traffic, quality, size, price per gigabyte, all of it.”
NetNut’s infrastructure, in a nutshell. Image: Black Lotus Labs, Lumen.
The NetNut and Popa botnet takedown may have another added benefit, Brundage said: Lessening the impact of large distributed denial-of-service botnets that have been built on the backs of poorly configured residential proxy services. In January, Synthient revealed how cybercriminals had built the world’s largest DDoS botnet (Kimwolf) by tunneling through IPIDEA proxy connections into the local networks of TV box owners, and infecting other Android-based devices behind the victim’s firewall.
While many of the bigger proxy providers took steps to block this activity, resellers of the major proxy networks have been far slower to respond to the threat, Brundage said.
“In terms of all these TV box devices getting compromised from the proxy network, it will have an impact on the DDoS botnets out there,” he said.
For its part, Google reckons today’s actions have caused “significant degradation to NetNut’s proxy network and its business operations, reducing the available pool of devices for the proxy operator by millions.” But the company warns that proxy networks can rebuild themselves by effectively reselling other proxy services, as IPIDEA has done over the past few months.
“Google has high confidence that many popular residential proxy brands are in fact whitelabeling the NetNut botnet,” the GTIG report concludes. “While we expect this disruption to have a larger ripple effect across the residential proxy ecosystem, observations after the disruption of IPIDEA proved that individual networks can appear resilient. What we have observed is that when faced with the degradation of their own botnet, proxy operators begin buying capacity from their competitors, effectively becoming a reseller. We recognize that creating a lasting disruption in this fluid ecosystem means we must scale our efforts to target the infrastructure of several interconnected providers.”
As KrebsOnSecurity has warned repeatedly, most of the no-name TV streaming boxes for sale on the major e-commerce websites either come pre-installed with residential proxy software, or require the installation of proxy SDKs in order to use the device for its stated purpose (streaming pirated movies, sporting events and TV shows). Google’s advice here is sound: When it comes to TV boxes, stick to name brands from reputable manufacturers, and then be sparing and judicious with any apps you choose to install.
The sketchy TV boxes that are being commandeered by the Popa botnet and other threats all come with or require the user to install unofficial Android operating systems that do not operate within the confines of Google’s Official Play Protect store. Google says consumers can confirm whether or not a device is built with the official Android TV OS and Play Protect certification by following these instructions.
Even people without TV streaming boxes can find their smart TVs enrolled in residential proxy networks, just by installing one of thousands of apps available for download on Samsung and LG smart TVs. In a report released last month, the proxy tracking company Spur found 42 percent of apps available for download via the webOS operating system on LG smart TVs include SDKs that turn one’s television into an always-on residential proxy node. More than a quarter of the apps made for Samsung’s Tizen operating system had similar residential proxy components, Spur found.

Image: Spur.us.
Update, 4:24 p.m. ET: Included a statement shared post-publication from an attorney representing NetNut parent Alarum Technologies.
Update, July 8, 2:34 p.m. ET: The website for Alarum Technologies — alarum[.]io — now also features a seizure notice from the FBI. The company’s stock has taken a beating since the FBI action, and is currently trading at $2.62 a share, a roughly 67 percent decline over the past week.
2026-06-23, 16:12
Two men pleaded guilty in the United Kingdom this week to criminal charges stemming from an August 2024 cyberattack that crippled Transport for London, the entity responsible for the public transport network in the Greater London area. The duo were key members of a prolific cybercrime group known as Scattered Spider, and their guilty pleas came on the first day of what was expected to be a six-week trial.

Owen Flowers (left) 18, and Thalha Jubair, 20. Image: UK National Crime Agency (NCA).
Thalha Jubair, 20, of East London and 18-year-old Owen Flowers of Walsall admitted conspiring to commit unauthorized acts against Transport for London computer systems and causing risk of serious damage to human welfare. According to a report from the BBC, Flowers alone admitted to being part of a conspiracy to hack into U.S. based healthcare providers SSM Health Care Corporation and Sutter Health in September 2024.
Jubair is also wanted by U.S. law enforcement agencies. In September 2025, prosecutors in New Jersey unsealed an indictment alleging Jubair and other Scattered Spider members committed computer fraud, wire fraud, and money laundering in relation to 120 computer network intrusions involving 47 U.S. entities between May 2022 and September 2025, and that the group’s victims paid at least $115 million in ransom payments.
In July 2025, KrebsOnSecurity reported that Flowers and Jubair were arrested in the United Kingdom in connection with Scattered Spider ransom attacks against the retailers Marks & Spencer and Harrods, and the British food retailer Co-op Group. Multiple sources familiar with those investigations said Flowers was the Scattered Spider member who anonymously gave interviews to the media in the days after the group’s September 2023 ransomware attacks disrupted operations at Las Vegas casinos operated by MGM Resorts and Caesars Entertainment.
According to prosecutors, Jubair co-ran a bustling Telegram channel called Star Chat, the home of a SIM-swapping group that used voice- and SMS-based phishing attacks to steal credentials from employees at the major wireless providers in the U.S. and U.K. The group would then use that access to sell a service that could redirect a target’s phone number to a device the attackers controlled and intercept the victim’s calls and text messages (including one-time codes for multi-factor authentication).
A receipt from Star Fraud Chat’s SIM-swapping service targeting a T-Mobile customer after the group gained access to internal T-Mobile employee tools. “Rocket Ace” was one of Jubair’s hacker handles, according to U.S. prosecutors.
New Jersey prosecutors also allege Jubair also was involved in a mass SMS phishing campaign during the summer of 2022 that stole single sign-on credentials from employees at hundreds of companies. That weeks-long SMS phishing campaign led to intrusions and data thefts at more than 130 organizations, including LastPass, DoorDash, Mailchimp, Plex and Signal.
KrebsOnSecurity reported last year that one of Jubair’s alter egos at age 15 was “Everlynn,” a hacker who sold fraudulent “emergency data requests” that used compromised police and government email addresses to demand subscriber data (e.g. username, IP/email address) from major tech companies, claiming the requests concerned urgent matters of life and death and could not wait for a court order.
In April 2026, 24-year-old British national and Scattered Spider member Tyler “Tylerb” Buchanan pleaded guilty to wire fraud conspiracy and aggravated identity theft for participating in the group’s SMS phishing spree in the summer of 2022. The government said Buchanan, Jubair and others used the credentials harvested in that phishing campaign to steal at least $8 million in cryptocurrency from victims throughout the United States. Buchanan is currently scheduled to be sentenced on October 2.
In August 2025, 20-year-old Scattered Spider member from Florida named Noah Michael Urban was sentenced to 10 years in federal prison and ordered to pay $13 million in restitution, after pleading guilty to charges of wire fraud and conspiracy.
The U.S. Department of Justice says three alleged Scattered Spider defendants indicted along with Buchanan still face charges, including Ahmed Hossam Eldin Elbadawy, 24, a.k.a. “AD,” of College Station, Texas; Evans Onyeaka Osiebo, 21, of Dallas, Texas; and Joel Martin Evans, 26, a.k.a. “joeleoli,” of Jacksonville, North Carolina.
Flowers and Jubair are slated to be sentenced in a London court on July 15, 2026.
2026-06-18, 17:37
For the past four years, a sprawling Android-based botnet called Popa has forced millions of consumer TV boxes to relay Internet traffic linked to advertising fraud, account takeovers, and mass data-scraping efforts. This week, researchers from multiple security firms concluded that the Popa botnet is linked to NetNut, a “residential proxy” provider operated by the publicly-traded Israeli firm Alarum Technologies Ltd [NASDAQ: ALAR].

Malicious streaming devices sold online that enroll the user’s home Internet address in a residential proxy service. Image: HUMAN Security.
Popa is a massive botnet, but by all accounts it is unlike traditional botnets that enlist compromised systems in destructive activities, such as coordinating huge distributed denial-of-service attacks. Rather, Popa appears designed with a singular purpose: Implementing a persistent communications layer capable of registering a device, maintaining long-lived encrypted connections, and opening communication tunnels on demand.
Experts say Popa is a plugin component associated with the Vo1d botnet, a large-scale malware campaign targeting unofficial Android-based TV boxes. These devices, which are marketed under thousands of brand names and model numbers and broadly available for purchase at top e-commerce destinations, all advertise the ability to stream hundreds of subscription video services for an up front one-time fee.
But as the FBI and security industry experts have warned repeatedly, these streaming boxes typically bundle or come pre-installed with software that turns the user’s TV into a “residential proxy” — allowing anyone to route their Internet traffic through that device for as long as it remains plugged into a wall socket and connected to a local network. More concerning, some of these proxy networks do little to stop malicious customers from communicating with and even compromising systems on the local network of the unsuspecting device owner.
The first clues about Popa’s origins came in a 2025 report from the Chinese security company XLAB, which flagged at least nine domain names that were used to register and direct the activities of compromised devices. In a report released today, the security firm Qurium described how it stumbled on some of those same domains while investigating a series of disruptive and expensive data scraping events targeting the company’s hosted organizations in May 2026, in which the scraping activity was scattered evenly across more than 1.4 million Internet addresses.
Qurium said it found several dozen domains used to control Popa that were all hosted in lockstep across multiple Internet addresses over time, including gmslb[.]net, safernetwork[.]io, tera-home[.]com, and ninjatech[.]io. Digging deeper, Qurium discovered gmslb[.]net was referenced in dozens of pirated or modded video content streaming apps, such as CRICFy, DooFlix, Sprozfy, RTS Tv, Flixoid, CyberFlix, Rapid Streamz, TvMob and HD/OceanStreams.
Qurium’s report notes that most of the domains long used to control the Popa botnet were seized or dismantled in July 2025, after Google, HUMAN Security and Trend Micro teamed up to disrupt Badbox 2.0, a botnet that is closely associated with Vo1d. Qurium said that immediately after that disruption, several dozen new domains were registered to serve as controllers for the Popa botnet, but that one of those control domains was not new: ninjatech[.]io.
Ninjatech is a company founded by Moishi Kramer, whose LinkedIn profile says he is vice president of research and development at NetNut. That resume credits Kramer for helping NetNut to build from the “ground up,” “designing the architecture,” and “scaling the NetNut” before the company was acquired by Alarum Technologies. A self-created listing at the job board F6S references Kramer as the sole owner of the Ninjatech domain (a screen capture of it is pictured below).

Image: F6S.com.
Responding via email, Mr. Kramer said Ninjatech ceased operations approximately five years ago, when the company sold a software development kit (SDK) called Popa that was designed to use a small portion of a device’s bandwidth and to run only after the host application obtained user consent.
“That code was sold and licensed to third parties including resellers years ago,” Kramer said. “Once software is distributed that way, the original developer has no control over how others later modify, rebrand, or deploy it.”
Kramer said neither he nor NetNut builds, operates or maintains the infrastructure being described as Popa, nor does he control the Ninjatech domain.
“I didn’t register the June 2025 domains you mention, and I don’t know who did,” he continued. “I have no control over, or visibility into, that infrastructure. I can only tell you it isn’t operated by me or by NetNut.”
But in a separate Popa research report released today, the proxy-tracking company Synthient said a recent analysis of the Popa SDK revealed outbound traffic clearly associated with NetNut.
“The research team assesses with high confidence that devices running Popa forward traffic from Netnut clients,” Synthient wrote. “This proves without a shadow of a doubt that Popa actively continues to be used by NetNut as part of their proxy pool.”

Synthient’s platform receiving outbound traffic from Popa. Image: Synthient.com.
Alarum Technologies, NetNut’s Tel Aviv-based parent company, said the reports by Synthient and Qurium contained “demonstrably inaccurate assertions and flawed deductions rather than verified facts.” Alarum shared a statement saying they reject the basic characterization of the SDKs and technologies discussed in the reports as a “botnet.”
“The SDKs at issue are designed to facilitate bandwidth-sharing functionality and do not transform user devices into malware-controlled systems or otherwise compromise the devices on which they operate,” the statement reads. “Netnut operates a commercial proxy network and maintains policies, procedures, and technological measures designed to promote lawful and responsible use of its services.”
Alarum said NetNut places “significant emphasis on appropriate notice and consent mechanisms, conducts customer due diligence, monitors for potential misuse, and takes steps intended to detect and mitigate suspicious or unauthorized activity.”
“This method of operation is supported both by internal procedures and policies, including performing KYC checks and additional due diligence of NetNut’s customers, as well as employing various technological measures, designed to assist in identifying and addressing suspected misuse of the network,” their statement continued.
However, in a report released on June 8, the proxy tracking service Spur asserted that NetNut does not require corporate verification or meaningful “know your customer” procedures before allowing customers to purchase proxy access.
“An individual can sign up, pay, and route traffic through partner address space, including space belonging to institutions whose users never opted in,” Spur wrote. “The ‘verified corporations only’ claim is simply marketing for bandwidth sellers, not an access control on who actually uses the proxies.”
“Nor is NetNut the only front door,” Spur continued. “A number of downstream white labelers and resellers repackage the same ISP proxy pool under their own brands. These outlets typically perform no KYC at all, less scrutiny than NetNut itself, who at the very least might assign an account manager to potential users. Anyone who knows where to look can buy access through a reseller with nothing more than a burner email address and $5 in crypto.”
Synthient found that although the most recent builds of Popa (as of three months ago) have added the ability to ask the user for consent before installing proxy components, not all variants or previous versions of Popa contain this functionality.
“Of the over 20 genuine Popa publishers analyzed, none of them were observed asking for user consent,” Sythient wrote.
THE PREVALENCE OF POPA
Chris Formosa is senior lead information security engineer for Black Lotus Labs, a division of the Internet backbone carrier Lumen Technologies.
“What especially makes Popa dangerous is just how widely used NetNut is for reselling and sharing,” Formosa said, explaining that many other proxy services simply resell NetNut proxies rather than building out their own far-flung proxy networks. “So these Popa IPs appear in tons of different services all over the ecosystem, which makes it one of the most problematic and dangerous proxy botnets on the market currently.”
Formosa said the Popa botnet averages between 1.5 million to 2.5 million distinct IP addresses each day, relying on between 250 and 300 Internet addresses that are used to direct its activities.
“That’s why Popa is so dangerous,” Formosa said. “It may not be the largest botnet we have seen, but it is spread all over the industry, making its power very amplified.”
Formosa said while that makes Popa one of the larger botnets out there today, its numbers pale in comparison to those previously boasted by IPIDEA, a China-based proxy provider that until recently operated a daily pool of nearly 10 million devices that they resold as proxies to anyone. In January 2026, Synthient published research showing that multiple new large DDoS botnets had grown rapidly by tunneling through IPIDEA proxies into the local networks of unsuspecting TV box owners and infecting other Android-based devices behind the user’s firewall.
IPIDEA is based largely on SDKs used to view pirated streaming content on a vast number of TV box devices, but the service’s numbers have dwindled since January, when Google and industry partners took legal action to seize domain names that IPIDEA used to control devices and proxy traffic through them.
Jérôme Meyer, a security researcher at Nokia Deepfield, said the total population of devices participating in the Popa botnet may be far higher than Lumen’s estimates. Meyer told KrebsOnSecurity that Nokia is monitoring 26 of at least 359 known relay nodes for the botnet, and estimates that each relay node handles between 35,000 and 60,000 clients simultaneously.
“On the relay node subset I am looking at (26 of them), 750,000 unique sources in 24 hours,” Meyer wrote in response to questions.
Nokia Deepfield released its own report today on RoboVPN, a VPN app tied to the Vo1d botnet’s Popa plugin that Qurium attributes to NetNut/Alarum Technologies.
THE SYMBIOSIS OF PROXIES AND DATA SCRAPING
Experts say many of the world’s largest proxy providers have updated their public-facing branding to highlight their utility for training AI platforms, implying it is a primary use case for their residential proxies. That’s because AI services tend to rely on constantly mass-scraping the Internet for new text, images and video content that can be used to train large language models (LLMs).

NetNut and other proxy services have recast themselves as critical infrastructure for the AI scraping economy. Image: Synthient.com.
“AI companies depend on web-scraped content: for pre-training, for retrieval, for agent grounding, for search,” reads a report this month from Include Security that examines the prevalence of proxy SDKs in smart TV apps. “But the modern web isn’t scrapeable from a datacenter. Cloudflare, DataDome, HUMAN, among others throttle or block requests from known cloud IPs. The workaround is residential proxies. A scraping job routed through a Comcast or T-Mobile subscriber’s connection arrives at the target site from an IP that belongs to a paying residential customer.”
This non-stop content scraping has spawned more than 70 copyright infringement lawsuits against major tech companies that have acknowledged large-scale data scraping as a major source of the “brains” behind their commercial AI offerings. Ironically, much of that scraping is being aided by proxy services that are intimately tied to unofficial Android TV boxes and associated SDKs whose stated purpose is streaming pirated content.
The scraping activity has become so aggressive that it often overwhelms the targeted websites, preventing them from being reachable by legitimate visitors. In many reported cases, nonprofit organizations, libraries and universities have complained of constantly battling to keep their services online in the face of relentless data-scraping firms hiding behind residential proxy services.
A survey conducted last year by the Confederation of Open Access Repositories (COAR) found while some content scraping bots are rather innocuous, “others are sufficiently aggressive that they are increasingly causing service disruptions in repositories and other scholarly communications infrastructures.” More than 90 percent of survey respondents indicated their repository is encountering aggressive bots, usually more than once a week, and often leading to slow downs and service outages.
“Automated web scraping is nothing new, and has been the key technology underlying search engines such as Google for over 30 years,” wrote Brendan O’Connell, platform manager at the Directory of Open Access Journals (DOAJ), a free, community-curated index of peer-reviewed academic journals. “However, the current investor-fueled AI startup craze means there are now thousands of well-funded companies developing and deploying their own scraping tools to train AI models, alongside existing major players like OpenAI and Google.”
DON’T TOUCH THAT DIAL!
Across the United States, local communities are pushing back against the proliferation of new data centers aimed primarily at improving the capabilities of AI. But security experts say the general public remains largely unaware that using one of these unsanctioned Android TV boxes means their “smart TV” is almost certainly using a significant amount of bandwidth each month to help train modern AI models.
Even households without these sketchy TV boxes can still have their smart TVs turned into residential proxy nodes, just by downloading one of thousands of apps made available on Samsung and LG smart TVs. Spur said it recently scraped the LG and Samsung app stores and found that each had approximately 3,000 apps available for download. Many of these apps are simple games or utilities that state in the fine print that the user’s Internet connection will be used to download data and that they can opt out at any time.
Spur said it found that more than 42 percent of apps available for download via the webOS operating system on LG smart TVs include SDKs that turn one’s television into an always-on residential proxy node. More than a quarter of the apps made for Samsung’s Tizen operating system had similar residential proxy components, Spur found.
Image: Spur.us.
Experts say it’s questionable whether TV apps with proxy SDKs can obtain meaningful consent from users for installing an always-on proxy connection, particularly when anyone in a household — including children — can effectively opt the family TV into a residential proxy network just by installing a simple game or app.
“Privacy-policy disclosure is the wrong control surface for a TV,” Include Security wrote. “It is hard to scroll through a legal document navigated by arrow keys on a remote, and the in-app consent dialog doesn’t convey that a paying customer is about to route their scraping traffic through the user’s home internet.”
Spur’s head of research Sean Simmons told KrebsOnSecurity that most people do not have a working mental model for what it means to sell access to their residential IP address, no matter what device they are using.
“And on a TV, the gap is even wider,” Simmons said. “A one-time prompt navigated with a remote can disappear into the setup flow, while the app keeps monetizing the connection long after anyone remembers what they accepted.”
Simmons said LG and Samsung should follow the lead of other TV platforms that have already drawn a line against residential proxy providers, pointing to policies by Amazon that prohibit apps facilitating proxy services for third parties. Likewise the TV streaming device maker Roku reportedly now bars developers from using proxy SDKs and has removed apps that bundled them.

Piracy related apps pushing proxy SDKs onto unconsenting users. Image: Synthient.
Apps that turn one’s device into a residential proxy node are not limited to smart TVs and no-name streaming boxes, of course. As noted by the security firm Infoblox, mobile app developers can embed SDKs provided by the residential proxy networks into their products to monetize their software, allowing them to receive a small amount of money on each installation.
The result, Infoblox said, is that devices are frequently enrolled without the owner’s knowledge, typically through free applications such as VPNs, streaming apps, screensavers and “productivity” apps such as PDF viewers and break reminders.
All too often, these proxy services are beaconing out from employee devices brought into the workplace, Infoblox found. In a blog post earlier this month, Infoblox said it discovered that fully 65% of its customer base was querying one or more residential proxy related domains.
“We saw steady growth in these queries in 2025, with a 25% increase over the year to over 500 billion per month,” Infoblox wrote. “Over 90% of our pharmaceutical and food & beverage customers have queried residential proxy indicators. Perhaps even more concerning is that over 60% of government and banking customers have as well.”
Infoblox researchers Nick Sundvall and David Brunsdon warned that with residential proxies in the corporate environment, external access is granted to an organization’s IP space.
“If threat actors were to abuse the residential proxy to attack a third party, the third party’s incident response would, correctly, identify your residential proxy as the source,” they wrote. “Untangling that, by proving that you were the conduit and not the threat actor, costs time, creates legal exposure, and can damage your reputation. The stunning prevalence of these services within customer environments warrants attention from both network defenders and policy makers who should consider how the risks posed by residential proxies could be impacting their security posture.”
2026-06-10, 14:03
A cybercrime group known as The Gentlemen has emerged as the second most active ransomware gang by victim count, rapidly attracting a talented pool of hackers through an aggressive recruitment strategy that promises affiliates 90 percent of any ransom paid by victims. This post examines clues pointing to a real life identity for the administrator of The Gentlemen ransomware group.

A graphic created and shared by The Gentlemen ransomware group administrator Hastalamuerte on Breachforums in May 2026. Credit: ke-la.com.
Experts at the security firm Check Point Software have been closely covering exploits of The Gentlemen, a so-called “ransomware-as-a-service” (RaaS) offering that pays affiliates handsomely to help spread the group’s malware.
“A 90/10 affiliate revenue split — compared to the industry standard 80/20 — is accelerating the group’s growth by attracting experienced operators from competing programs,” the researchers wrote in April.
Check Point found The Gentlemen are the second most active ransomware group by victim count so far this year, claiming at least 332 published victims since the group’s inception in mid-2025 and more than 240 in 2026 alone.
According to Check Point, the group targets Internet-facing devices (VPNs, firewalls) as their entry point, and once inside moves quickly to encrypt entire networks within hours.
Check Point says the administrator and primary operator of the ransomware group uses the nickname Zeta88 on the Russian-language cybercrime forums, and that this individual was previously known under the moniker Hastalamuerte. Check Point noted that a breach of the group’s backend infrastructure made it clear that Hastalamuerte/Zeta88 is the person who assembles the locker and RaaS panel, manages payments, and is essentially the administrator of the entire program who receives 10 percent of all ransoms.
WHO IS HASTALAMUERTE?
The cyber intelligence firm Intel 471 shows that the user Hastalamuerte is a Russian and English speaking person who registered on almost a dozen cybercrime forums between 2019 and the present day, including Exploit, Breachforums, Ramp_V2, BHF, Raidforums, and Nulled.
Intel 471 reveals that Hastalamuerte registered on Breachforums in January 2025 from an Internet address in Izhevsk, the capital city of Russia’s Udmurt Republic. Likewise, the user Zeta88 signed up at the English-language cybercrime forum Breached in August 2022 from a different Internet address in Izhevsk.
Intel 471 finds Hastalamuerte registered on Raidforums in 2020 using the email address hastalamuerte1488@protonmail.com (1488 is a common combination of two numeric symbols associated with white supremacy). A lookup on this address at the open source intelligence service Epieos shows it is connected to an account at Apple and to a phone number ending in 04.
Epieos says that Protonmail address is also linked to a GitHub account under the username SantaMuerte. That account is marked private, but a history of this user’s activity shows they are watching and developing a number of malware tools and exploits.
In April 2020, Hastalamuerte said on the crime forum Nulled that they could be contacted at the Telegram instant messenger name @hastalamuerte18, and the threat intelligence company Flashpoint finds this username is assigned the unique Telegram ID number 30907522 [full disclosure: Flashpoint is an advertiser on this blog].
The breach tracking service Constella Intelligence reports that Hastalamuerte’s Telegram ID is connected to another username — “bu4vs” — and to the Russian phone number 79127650004. Pivoting on this phone number in Constella fetches multiple records from hacked Russian government databases showing it is assigned to one Alexander Andreevich Yapaev, a 36-year-old from Izhevsk.
Constella reveals that phone number was used to create an account at the Russian social media platform Pikabu under the name “4apai18,” and shows Mr. Yapaev has signed up at a number of websites using the common surname Ivanov, or else “Chapaev” (the numeral 4 is often used as shorthand for a “ch” sound in Russian).
A search in Intel 471 for cybercrime forum members with the nickname SantaMuerte unearths an account by the same name created in 2020 on the Russian hacking forum Codeby. Intel 471 shows this user originally registered on Codeby with the not-so-subtle nickname Alexandr 4apaev.
Constella finds Mr. Yapaev regularly used the email address bu4vs@mail.ru. Meanwhile, Epieos shows this address is connected to a LinkedIn account for Alexander Yapaev, who lists himself as the head of B2B marketing at the company Uralenergo Udmurtia, one of Russia’s largest suppliers of electrotechnical and lighting products.
Mr. Yapaev did not respond to multiple requests for comment.
Nearly every time we publish one of these Breadcrumbs stories, readers are curious to know why it seems like so many cybercriminals from Russia apparently do little to hide their real life identities. The truth is that — Russian or not — most didn’t exactly set out to be arch criminals, but instead got drawn into the scene gradually over several years as their skills broadened and sharpened.
Another important dynamic is that the Russian government generally either co-opts or ignores cybercriminal activity within its borders so long as the hackers do not steal from or attack Russian businesses and citizens. As a result, successful cybercriminals in Russia are usually insulated from prosecution and arrest by foreign law enforcement agencies provided they occasionally pay off the right people and do not travel abroad. And cybercriminals who intend to strictly adhere to those unwritten rules may (at least initially) be less concerned about covering their tracks online.
But the simplest explanation is that cybercriminals of all nationalities tend to make a number of basic operational security mistakes early in their careers, when they are less savvy and have far less to lose by their carelessness. A review of Hastalamuerte’s early posts on the crime forums (circa 2019-2020) shows a relatively unsophisticated and low-skilled hacker still trying to learn the ropes and earn a positive reputation on these communities.
For example, in June 2020 Hastalamuerte’s Telegram account joined a multi-month training program (@pntst) to learn how to use popular penetration testing tools, and their candid posts to this hacker training camp show Hastalamuerte struggling to use these tools effectively. A Google-translated record of Hastalmuerte’s posts to @pntst is here.
Update, June 11, 10:23 a.m. ET: The threat research group PRODAFT has released a detailed writeup on the history and current operations of The Gentlemen. PRODAFT said its findings match the same persona with “high confidence,” and found the administrator (Zeta88/Hastalamuerte) supplies affiliates with initial access directly, primarily Fortinet SSL-VPN credentials obtained through brute-force attacks or sourced from the group’s own leak database. They also discovered the administrator is using AI to develop and maintain the ransomware and associated tooling, as well as to assist with post-exploitation activity.
2026-06-09, 22:07
Microsoft today released software updates to plug nearly 200 security holes across its Windows operating systems and supported software, a record number of fixes for the company’s monthly Patch Tuesday cycle. Nearly three dozen of those bugs earned Microsoft’s most dire “critical” rating, and exploit code for at least three of the weaknesses is now publicly available.
The software giant said in a blog post last month that both its engineers and the security community are increasing using artificial intelligence tools to find bugs, meaning this month’s heavy Patch Tuesday may start to become the norm, said Satnam Narang, senior staff research engineer at Tenable.
“Some surveys put AI usage among security professionals generally at 90%, so it’s unsurprising that this volume of patches may be the norm,” Narang said. “Pandora’s proverbial box has been opened, and as more advanced AI models become available, we expect the norm to continue upward across the board, not just for Patch Tuesday.”
June’s zero-day bugs include CVE-2026-49160, a denial of service vulnerability affecting a range of web servers, including Microsoft Internet Information Services (IIS). Microsoft says the flaw was reported by OpenAI’s Codex.
Two of the zero-days addressed this month appear to stem from recent vulnerability disclosures by Nightmare Eclipse, the nickname chosen by a security researcher who has been dropping exploits for various Windows flaws. One of those, dubbed “GreenPlasma,” leverages an elevation of privilege weakness in the Windows Collaborative Translation Framework, the same framework patched today in CVE-2026-45586.
Nightmare Eclipse also last month released “YellowKey,” an exploit for a Windows BitLocker vulnerability that allows an attacker with physical access to view encrypted data, and CVE-2026-50507 is a patch for an elevation of privilege bug in BitLocker.
Microsoft received heavy blowback on social media last month after it said in a blog post that it was considering taking legal action against the security researcher. The company later clarified on Twitter/X that while it has no intention of pursuing legal actions against researchers, it would report them to authorities if they break the law. The advisories for CVE-2026-49160 and CVE-2026-50507 do not credit any researchers in the acknowledgement section, saying only that “Microsoft recognizes the efforts of those in the security community who help us protect customers through coordinated vulnerability disclosure.”
Nightmare Eclipse claims to be a former employee of Microsoft, although Microsoft has not responded to questions about this claim. Rapid7 notes that a recent blog post by Nightmare Eclipse included an image of Albert Wesker, a character from the Resident Evil video game series who formerly worked as a researcher for a technology company before going rogue.
Nightmare Eclipse has pledged to release even more zero-day exploits for Windows in what they called a “bone shattering” drop planned for July 14 (the same day as next month’s Patch Tuesday). Immediately following the release of Microsoft patches today, the researcher published an exploit for what they claimed was a zero-day bug in Windows Defender.
While 200 vulnerabilities may be a record for Patch Tuesday, the actual number of security flaws Microsoft addressed this month is far higher, said Rapid7’s Adam Barnett.
“So far this month, Microsoft has provided patches to address 360 browser vulnerabilities, which is an order of magnitude more than has been typical in any given month over the past few years,” Barnett wrote. “As usual, browser [flaws] are not included in the Patch Tuesday count above. Indeed, the vast, and presumably sustained, uptick in the number of browser vulnerabilities has led to Microsoft no longer enumerating Chromium CVEs in the Security Update Guide.”
Microsoft also patched a zero-day vulnerability in Visual Studio Code that allows attackers to steal GitHub tokens with a single click. The company was forced to push a stopgap fix for the flaw on June 3, after a researcher published instructions showing how to exploit it. The researcher said they opted not to work with Microsoft because of a recent experience wherein Redmond silently patched a flaw they reported without offering credit or recognition.
Microsoft battled its own internal zero-day emergencies last week, after at least 72 of the company’s public code repositories were infected with a variant of the Shai-Hulud worm. Researchers found that all of the affected packages were connected to Microsoft official Azure Durable Task SDK, which got hit by the same Shai-Hulud worm in May.
Other major software makers are also shipping outsized update bundles this month. Adobe has released updates to fix a massive number of critical vulnerabilities across a range of products, including Adobe Experience Manager, Acrobat Reader and Cold Fusion. On June 3, Google resolved a whopping 429 vulnerabilities in its latest Chrome browser update (Chrome automatically downloads updates but installing them usually requires a complete restart of the browser).
As ever, please consider backing up your data before applying operating system updates, and drop a note in the comments if you run into any problems with this month’s patches.
Further reading:
Microsoft’s Security Update Guide
2026-06-01, 17:32
The Instagram accounts for the Obama White House and the Chief Master Sergeant of the U.S. Space Force were briefly defaced with pro-Iranian images and messages over the weekend, after instructions began circulating on Telegram showing how to trick Meta’s “AI support assistant” bot into resetting account passwords.
A screenshot from a video released on Telegram claiming to show how Meta’s AI customer support bot could be tricked into resetting a target’s password.
On May 31, word began to spread on several Telegram instant message channels that Meta’s AI bot would happily add an email address to an existing account as part of the bot’s standard password reset flow.
A video released on Telegram by pro-Iran hackers claimed to document a remarkably simple exploit that appears to have involved using a VPN connection with an IP address that is in or near the target’s usual hometown, requesting a password reset for the account, and then choosing to chat with Meta’s AI support assistant. From there, the video shows the attacker told the bot to link the account in question to a new email address, after which the bot dutifully sent that address a one-time code that allowed a password reset.
The Telegram account that posted the video also linked to screenshots of pro-Iran images, videos and messages that defaced the hacked Instagram accounts, saying hackers had used the exploit to hijack a number of valuable (read: short) Instagram account names that allegedly have a resale value of more than a half million dollars.
Meta has not responded to requests for comment on the video’s claims, but Meta’s Andy Stone said on Twitter/X that the issue had been resolved and that they were securing impacted accounts. The security blog thecybersecguru.com reports that Meta pushed an emergency patch over the weekend, and clarified that no back end database was breached.
“Instagram has notoriously poor human support infrastructure,” Cybersecguru wrote. “Recovering a locked account – especially a high-value one can take weeks of back-and-forth with an automated ticketing system. Meta’s solution was to deploy a conversational AI layer to handle common recovery workflows: relinking a lost email address, triggering a password reset, verifying account ownership. The assistant, presumably, was supposed to reduce friction for legitimate users stuck in account-access hell.”
Ian Goldin, a threat researcher at Lumen’s Black Lotus Labs, said we’re entering unchartered security territory as more large online platforms start allowing AI chatbots to handle sensitive account recovery requests. Just like human customer support employees can be social engineered into providing unauthorized access to someone’s account, AI bots are equally eager to help and vulnerable to persuasion and trickery, he said.
“AI chatbots create interesting new attack surface, and we’re likely going to see a lot more of these kinds of attacks,” Goldin said.
Securing your various online accounts means taking full advantage of the most secure form of multi-factor authentication (MFA) offered (such as a passkey or security key). In this case, even using the least robust form of MFA that Instagram offers — a one-time code sent via SMS — likely would have blocked the exploit: The hackers who released the video on Telegram said their exploit failed to work against any accounts that had MFA enabled.
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
6. HOT FOR SECURITYby Graham CluleyComputer security news, advice and opinion.
2026-07-21, 09:51
Ukraine's computer emergency response team, CERT-UA, has warned that the Kremlin-backed Sandworm hacking group is leveraging fake CAPTCHA checks on compromised websites that persuade users to run malicious code. Read more in my article on the Hot for Security blog.
2026-07-17, 22:30
Gemini, Google's AI assistant, is supposed to make life easier for Android smartphone owners. But right now it may also be making life easier for anyone anyone who happens to pick up your phone. Read more in my article on the Hot for Security blog.
2026-07-16, 21:05
The Anubis ransomware-as-a-service (RaaS) operation has hit some healthcare organisations hard - but they are not the only ones at risk. Read more in my article on the Fortra blog.
2026-07-16, 09:02
An app has appeared in India that lets anyone with a smartphone stop a passing e-rickshaw dead in its tracks - no login, no passwords, no permissions needed. Meanwhile, Geoff - swimming in money and Lamborghinis, as all published authors are - has been on the receiving end of a slew of AI-generated scam pitches from fake book marketing experts. Rather than ignore them, he's been playing them at their own game... All this and more in this episode of the "Smashing Security" podcast with cybersecurity expert and keynote speaker Graham Cluley, and special guest Geoff White.
2026-07-14, 07:54
When a company falls victim to a ransomware attack, it is not uncommon for it to turn to experts for help. Specialist ransomware negotiation firms handle communications with criminal gangs on a victim's behalf. What victims don't expect is that their trusted negotiator might be separately sharing details of the victim's cyber-insurance policy and negotiation strategy directly with the attackers themselves. Read more in my article on the Hot for Security blog.
2026-07-09, 13:17
Have you received an email from a recruiter at Adobe, Netflix, or OpenAI offering you an exciting new marketing role? Well, before you start brushing up your interview technique, take a closer look at who is really behind it. Read more in my article on the Hot for Security blog.
2026-07-08, 23:19
A 15-year-old boy asked a chatbot for help - and cancelled nearly 47,000 anime streaming subscriptions in under four hours. Meanwhile, researchers have documented the first fully autonomous, agentic AI-driven ransomware attack, "JadePuffer". What does this tell us about the future of cybersecurity? Also, Apple's "Hide My Email" feature turns out to hide rather less than it promises - despite Apple knowing it has a problem for over a year. All this and more in this episode of the "Smashing Security" podcast with cybersecurity expert and keynote speaker Graham Cluley, and special guest Zoë Rose.
2026-07-07, 12:56
Two young men have been arrested in the Netherlands on suspicion of running a phishing operation that harvested the credit card details of unsuspecting victims. Read more in my article on the Hot for Security blog.
2026-07-02, 16:50
Who Are The Gentlemen? Despite the impeccably polite name, there is nothing polite or refined about this particular gang of cybercriminals. Read more in my article on the Fortra blog.
2026-07-01, 23:12
Polymarket has built an entire business on predicting the future. So how did it manage to spectacularly fail to predict its own hack? Plus, the Google engineer with a million-dollar secret, and the curious case of the airport hairdryer. Meanwhile, "FortiBleed" sees 75,000 Fortinet firewalls thrown wide open - and the real damage is going to roll on for years. All this and more in episode 474 of the "Smashing Security" podcast with cybersecurity expert and keynote speaker Graham Cluley, and special guest Quentyn Taylor.
2026-06-30, 21:04
Scammers wasted no time exploiting Venezuela's devastating earthquake, with researchers uncovering 212 newly-registered relief-themed domains in just five days. Read more in my article on the Hot for Security blog.
2026-06-30, 10:25
Read more in my article on the Hot for Security blog.
2026-06-24, 23:10
A polite caller from your bank says there is a problem with your account. Don't worry - they'll send someone round to help. They'll even take your cards away to keep them safe. The scam has run rampant, until Dutch police plastered blurred photos of 100 suspects across billboards, supermarkets, and TikTok, with a two-week ultimatum to turn themselves in... or else. Meanwhile, a security researcher called Bob DaHacker got her hands on the live broadcast controls for every match of the 2026 FIFA World Cup. She could have Rickrolled the entire planet, but actually spent days trying to find anyone at FIFA who would pick up the phone. Plus! Don't miss our featured interview with Black Kite's Jeffrey Wheatman exploring ransomware and extortion attacks across Europe. All this and more in episode 473 of the "Smashing Security" podcast with cybersecurity expert and keynote speaker Graham Cluley, and special guest Danny Palmer.
2026-06-23, 12:16
Emergency alert systems work because people believe them. Every time one of these systems issues a false alert - whether through negligence or a deliberate attack - trust erodes. Read more in my article on the Hot for Security blog.
2026-06-19, 15:47
Apple has long marketed itself as the privacy-first tech giant. So why is it making a change to Hide My Email that will make it easier for websites to block anonymous sign-ups - and harder for you to stay private online? Read more in my article on the Hot for Security blog.
2026-06-19, 13:51
Someone is pretending to be your bank, your government, or your local planning office. And according to the FTC, they're making billions doing it. Read more in my article on the Fortra blog.
2026-06-17, 23:10
What if your AI coding assistant could be tricked into stealing your own company's secrets - by reading a single booby-trapped bug report? No phishing email. No malware. No password ever stolen. Just an AI doing exactly what it was told. Meanwhile, someone themselves Nightmare Eclipse has decided to teach Microsoft a lesson. The result? Three zero-days dropped on the internet, one of which lets a thief with a USB stick walk straight past BitLocker. Microsoft is furious. Plus don't miss our featured interview with Son Nguyen Kim of Proton Pass, who explains why plugging AI agents into your email and calendar without thinking twice is rather like hiring a new employee with the keys to everything - and skipping the background check. All this and more in episode 472 of the "Smashing Security" podcast with cybersecurity expert and keynote speaker Graham Cluley, and special guest Paul Ducklin.
2026-06-15, 13:23
The US state of Maine has taken its public data breach notification portal offline after someone submitted fraudulent breach disclosures impersonating two well-known technology companies. Read more in my article on the Hot for Security blog.
2026-06-12, 18:48
Argentina's World Cup squad had their passport numbers leaked before a ball was kicked - not by hackers, but by someone who failed to redact a document properly. document. It's a mistake that has been made many times in the past... Read more in my article on the Hot for Security blog.
2026-06-11, 15:43
Most extortion gangs hide behind a keyboard. Silent Ransom Group will phone your staff pretending to be IT support - and if that fails, send someone to your office in person to plug in a USB stick. Read more in my article on the Fortra blog.
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
7. BLEEPING COMPUTERby Lawrence AbramsA blog & a free community of computer users.
2026-07-21, 23:07
Authorities in Germany and the U.S. dismantled the central infrastructure of Kratos, a phishing-as-a-service (PhaaS) platform with global reach, and its developer was arrested in Indonesia. [...]
2026-07-21, 22:34
A large-scale operation dubbed 'FakeGit' is pushing SmartLoader and StealC malware through 7,600 malicious GitHub repositories that accumulated more than 14 million downloads. [...]
2026-07-21, 20:06
Hackers are actively exploiting the critical CVE-2026-50522 vulnerability in Microsoft SharePoint to steal machine keys and maintain access even after affected servers are patched. [...]
2026-07-21, 18:50
The Anubis ransomware gang has claimed responsibility for the cyberattack on Coca-Cola's Fairlife dairy subsidiary, threatening to publish allegedly stolen corporate data unless the company pays a ransom. [...]
2026-07-21, 16:41
Hackers are exploiting the "wp2shell" critical vulnerability suite (CVE-2026-63030 and CVE-2026-60137) affecting WordPress Core to deploy persistent webshells and install malicious plugins on affected servers. [...]
2026-07-21, 14:00
Critical infrastructure attacks often begin with stolen credentials, compromised devices, or trusted accounts. Specops Software explains why Zero Trust should verify both user identities and device trust before granting access to critical systems. [...]
2026-07-21, 11:07
The U.S. Justice Department has seized more than 1,000 websites and blocked 1,970 domains used to stream FIFA World Cup 2026 matches without authorization. [...]
2026-07-21, 10:12
The Qilin ransomware gang is exploiting a critical PAN-OS GlobalProtect authentication bypass flaw to breach victims' networks, according to cybersecurity company Arctic Wolf. [...]
2026-07-21, 09:05
Microsoft has shared manual mitigations to help IT administrators fix Windows Server Update Services (WSUS) servers affected by a known issue that causes Windows Update scans to fail or time out. [...]
2026-07-21, 08:06
Free unofficial patches are available for a recently disclosed Windows zero-day flaw that allows attackers to escalate privileges on up-to-date Windows systems. [...]
2026-07-20, 22:39
Cosmetics giant Estée Lauder is notifying employees of a data breach after hackers exploited a flaw in Oracle E-Business Suite that the company used for human resources (HR) operations. [...]
2026-07-20, 22:23
Two recently disclosed SonicWall SMA1000 vulnerabilities were exploited in zero-day attacks for weeks, allowing threat actors to install custom malware on vulnerable VPN appliances. [...]
2026-07-20, 22:22
The Ostium trading platform announced that an attacker stole $23.75 million from its liquidity provider vault last week, after compromising off-chain infrastructure used to feed prices into the protocol. [...]
2026-07-20, 21:14
Researchers escaped the sandboxes in Cursor, Codex, Gemini CLI and Antigravity by having the AI agent write files that trusted host tools later run. Multiple CVEs, patches, and Google downgrading two Antigravity findings. [...]
2026-07-20, 21:08
The JadePuffer autonomous AI agent has upgraded with custom malware called EncForge that focuses on encrypting AI assets, such as training datasets, vector databases, and model checkpoints. [...]
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
8. RESTORE PRIVACYby Heinrich LongPrivacy Blog & Knowledge Base
2024-11-12, 12:01
Signal, the privacy-focused messaging app, has announced new features to enhance its calling experience, making it easier for users to initiate and manage group calls. The primary addition, “Call Links,” allows users to share a link to initiate a call with any contact on Signal without the need to create a group chat. This feature …
The post Signal Introduces Call Links for Simplified Private Group Calls appeared first on RestorePrivacy.
2024-11-08, 18:11
The Tor Project is currently facing an unusual, ongoing attack aimed at its infrastructure. For several weeks, an unknown threat actor has been spoofing the IP addresses of Tor relays and directory authorities, sending fake TCP SYN packets over SSH’s port 22. This technique has led to a flood of abuse complaints directed at Tor …
The post Tor Relays Targeted in IP Spoofing Campaign Causing Widespread Disruptions appeared first on RestorePrivacy.
2024-10-28, 18:34
Proton has launched its much-anticipated Black Friday sale for 2024, offering incredible discounts on services like Proton VPN, Proton Mail, Drive, and Pass. These Proton deals all include a 30-day money-back guarantee, allowing you to assess the service risk-free. This sale is the perfect chance to boost your online privacy and access premium features at …
The post Proton Black Friday Deals Go Live: VPN, Mail, Drive, Pass appeared first on RestorePrivacy.
2024-10-22, 17:16
Session, the encrypted messaging app known for its commitment to privacy and decentralization, announced a change of base from Australia to Switzerland. The app will now be overseen by the newly formed Session Technology Foundation (STF), based in central Europe. This move follows increasing regulatory pressure on privacy technologies in Australia, where the app was …
The post Encrypted Messenger Session Moves to Switzerland Amid Privacy Concerns appeared first on RestorePrivacy.
2024-10-16, 16:37
Mullvad VPN announced that macOS users may experience traffic leaks after applying recent system updates due to a firewall malfunction. According to a bulletin published earlier today on Mullvad’s blog, the macOS firewall fails to enforce certain routing rules properly, allowing some applications to bypass the VPN tunnel and send traffic outside of it. Mullvad …
The post Mullvad VPN Warns About Traffic Leaks on Latest macOS Sequoia appeared first on RestorePrivacy.
2024-10-09, 13:48
Discord, a popular communication platform, has been blocked in both Russia and Turkey, sparking widespread backlash from users in both countries. In Russia, the block took place yesterday, with the government citing concerns over illegal content, while Turkey implemented blocks a day prior, on October 7, 2024, claiming the platform was being used for criminal …
The post Discord Blocked in Russia and Turkey Amid Government Crackdowns appeared first on RestorePrivacy.
2024-10-01, 16:07
NordVPN, one of the world's leading VPN service providers, has launched its first application featuring quantum-resilient encryption. Post-quantum cryptography support is currently available on NordVPN's Linux client, with plans to extend this security to all applications by the first quarter of 2025. The move represents a significant step toward preparing for potential future threats posed …
The post NordVPN Adds NIST-Approved Quantum Encryption on the Linux Client appeared first on RestorePrivacy.
2024-09-25, 17:19
The European privacy rights organization noyb has filed a formal complaint against Mozilla for enabling a new feature in its Firefox browser that allegedly tracks users without their consent. The feature in question, called Privacy-Preserving Attribution (PPA), is designed to measure the effectiveness of online advertisements while minimizing data collection, but noyb claims it violates …
The post Mozilla Faces GDPR Complaint Over Firefox Tracking Users Without Consent appeared first on RestorePrivacy.
2024-09-23, 20:05
Telegram CEO Pavel Durov announced significant updates to the app's Terms of Service and Privacy Policy, aimed at bringing the popular communications platform in alignment with the request of authorities to bring criminal activity under control. Most notably, Telegram will now share user IP addresses and phone numbers when responding to valid legal requests. Putting …
The post Telegram to Share User Data with Authorities on Legal Requests appeared first on RestorePrivacy.
2024-09-19, 18:06
The Tor Project has issued a statement in response to recent claims of a targeted de-anonymization attack on a Tor user. The attack, reportedly a “timing analysis” method, involved the long-retired Ricochet application. Although the incident raises concerns about the security of Tor’s Onion Services, the project maintains that its network remains healthy and that …
The post Tor Project Reassures Users Amid Claims of De-Anonymization Attack appeared first on RestorePrivacy.
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
9. HAVE I BEEN PWNED?by Troy HuntAccount login credential breaches
Is your e-mail address compromised? Check it on this page.
2026-07-20, 19:49
In November 2025, AI music generation tool Suno suffered a data breach that later came to light in July the following year. The data contained over 55M unique email addresses. Phone numbers were also present where they had been used as the sign-up method. Although representing a small portion of the corpus, the breach also included tens of thousands of Stripe records relating to purchases, containing names, physical addresses, purchase amounts and partial credit card data including the card type, expiry date and last 4 digits. The company advised that "Suno does not have access to customers' full credit card numbers in Stripe".
2026-07-19, 22:57
In March 2026, hackers claimed they had obtained data from the gig economy platform Paidwork which they then listed for sale. Almost 11GB of data allegedly obtained from the platform was subsequently posted publicly in July and contained over 23M unique email addresses. The breach also included a broad range of other data relating to the operation of the platform including user profile data, banking information, payout history for workers and passwords stored as bcrypt hashes.
2026-07-15, 08:01
In July 2026, electronic test and measurement equipment company Fluke was targeted in a ShinyHunters "pay or leak" extortion campaign. The group subsequently published more than 100GB of data allegedly taken from the company. The corpus contained largely corporate contact information, including over 800k unique email addresses, names, phone numbers and physical addresses. A large collection of support cases was also present.
2026-07-15, 05:03
In June 2026, a party claiming to have access to data from Goose Creek Candle Company sent emails to a number of the company's customers, claiming the company had a security vulnerability and suffered a data breach. The data was subsequently sent to Have I Been Pwned and contained 6.6M unique email addresses along with names, phone numbers, physical addresses, order IDs and total spent. The data appears to have been obtained from the company's Shopify instance. Goose Creek is aware of the reports but was unable to provide Have I Been Pwned with any further information at the time of publication.
2026-07-11, 10:40
In June 2026, Glendale Community College was the target of a ShinyHunters "pay or leak" extortion campaign. Data allegedly obtained from Glendale was later published online and included almost 800k unique email addresses along with various other data fields, including names, addresses, phone numbers, Social Security numbers and other information relating to student enrolments. In its disclosure notice, the college advised that "the potentially impacted information may vary for each individual and may include all or just one of the above-listed types of information".
2026-07-03, 16:03
In June 2026, Moody Bible Institute was targeted by a ShinyHunters "pay or leak" extortion campaign. Over 2.3M unique email addresses and other personal data were later published publicly, including names, physical addresses, phone numbers, dates of birth and other information relating to donors, supporters, students and alumni. In their disclosure notice, Moody advised that they had "engaged both internal and external cybersecurity experts to thoroughly investigate the matter".
2026-06-28, 15:57
In June 2026, the food distribution company Sysco was targeted by a ShinyHunters "pay or leak" extortion campaign. Data was subsequently published containing 2.7M unique email addresses belonging to staff and customers. The data also contained largely corporate contact information including names, phone numbers, physical addresses, internal job titles, and customer feedback.
2026-06-26, 07:17
In June 2026, telecommunications tower infrastructure company American Tower was the target of a ShinyHunters "pay or leak" extortion campaign. The group subsequently published data allegedly taken from the company containing more than 200k unique email addresses belonging to employees, contractors, customers, and leads. Exposed data also included names, addresses, and phone numbers.
2026-06-24, 13:02
In June 2026, the sports and entertainment company Madison Square Garden Sports was the target of a ShinyHunters "pay or leak" extortion campaign. The group later published the alleged data, which included almost 10M unique email addresses spanning staff and customers, along with extensive personal, employment and customer relationship information.
2026-06-20, 03:02
In June 2026, retailer JCPenney and associated brands were targeted in a ShinyHunters "pay or leak" extortion campaign. Data allegedly obtained from JCPenney through the exploitation of a critical zero-day vulnerability in Oracle PeopleSoft was later published publicly. The exposed records indicated they primarily related to internal HR systems and impacted current and former employees. The data included 368k corporate and personal email addresses, names, dates of birth, Social Security numbers, phone numbers and home addresses.
2026-06-18, 22:48
In June 2026, fashion retailer Ralph Lauren was targeted in a ShinyHunters "pay or leak" extortion campaign. The group subsequently published hundreds of gigabytes of data they claimed was obtained from the organisation's Salesforce instance, including 140k unique email addresses along with names, phone numbers, genders and age groups.
2026-06-18, 20:08
On 18 June 2026, the latest phase of Operation Endgame targeted the SocGholish malware operation, a prolific malware distribution network used to compromise systems and facilitate further cybercrime. Coordinated by international law enforcement agencies with support from Europol and Eurojust, the operation remediated almost 15,000 compromised websites and disrupted more than 100 servers and domains used to distribute malware. Authorities initially provided HIBP with 154k impacted email addresses and more than half a million previously unseen passwords recovered during the operation. The following week, a further 4M email addresses and 9M passwords relating to the StealC malware operation targeted by Operation Endgame were provided to HIBP, bringing the total to almost 4.2M unique email addresses.
2026-06-18, 03:22
In March 2026, the financial consulting and advisory firm CFGI was the target of a ShinyHunters "pay-or-leak" extortion campaign. The group subsequently publicised data allegedly obtained from CFGI comprising corporate contact information, including 243k unique email addresses, names, phone numbers and physical addresses.
2026-06-15, 19:30
In June 2026, a collection of accumulated stealer logs from various sources was added to HIBP. The corpus comprised 56M unique email addresses across hundreds of millions of stealer log records. The data also contained 124M unique passwords, which have been added to Pwned Passwords and are now searchable. Individuals can view any records captured against their email address in the stealer logs section of their dashboard. Organisations can see logs affecting their domain via the stealer logs API.
2026-06-15, 04:09
In March 2026, the commercial real estate finance company Berkadia was the target of a ShinyHunters "pay or leak" extortion campaign. The group subsequently published data they alleged was taken from Berkadia's Salesforce instance, including over 300k unique email addresses as well as names, physical addresses and phone numbers, among other data.
2026-06-15, 01:03
In March 2026, the student information system Infinite Campus was targeted in a ShinyHunters "pay or leak" extortion campaign. The group subsequently published data they alleged was taken from Infinite Campus, containing 137k unique email addresses along with names, phone numbers, physical addresses and support tickets. Infinite Campus subsequently sent notifications, advising that the exposed data largely consisted of "names and contact information for school staff" and that "the majority is directory information commonly found on school websites".
2026-06-10, 22:13
In June 2026, the University of Nottingham was the target of a cyber attack, later linked to a ShinyHunters "pay or leak" extortion campaign. Tens of gigabytes of data were subsequently published online and included 455k unique email addresses along with extensive personal information including names, addresses, phone numbers, ethnicities, disabilities, passport numbers and information relating to academic enrolments and fee payments. In a post about the incident, the university advised that the breach affected both "current students, and alumni".
2026-06-07, 06:16
In May 2026, the HVAC/R wholesale distributor Baker Distributing Company was added to the ShinyHunters data extortion group's "pay or leak" site. In early June, the group publicly published data they claimed had been obtained from Baker's SharePoint and Salesforce infrastructure including 103k unique email addresses along with names, physical addresses, phone numbers and tickets relating to the company's HVAC contractor customer base. The exposed data was largely corporate contact and support information with limited sensitivity.
2026-06-05, 06:53
In May 2026, the corporate travel management company BCD Travel was claimed as a victim of the ShinyHunters "pay or leak" extortion campaign. Data allegedly obtained from BCD was subsequently published publicly in early June and contained 396k unique email addresses. Other exposed data included names, addresses, phone numbers, job titles and employer names, spanning a variety of different data sets including leads, internal staff and support tickets.
2026-06-03, 22:56
In May 2026, the dental benefits administrator DentaQuest was the target of a ShinyHunters "pay or leak" extortion campaign that resulted in the group publicly publishing hundreds of gigabytes of data allegedly obtained from the company. The data included 2.6M unique email addresses along with names, addresses and phone numbers. Much of the data appeared in healthcare enrollment files (ASC X12 transaction sets) with some containing Medicaid IDs, while additional data appeared in member records and related files. DentaQuest acknowledged "a cybersecurity incident involving unauthorized access to a limited portion of our network", and advised they had contained the attack and mitigated the threat.
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
10. AI RESEARCHby Sophos NewsCybersecurity in AI and AI in cybersecurity
2026-06-30, 00:00
<p>Sophos X-Ops presents a working taxonomy for attacks using, and targeting, AI</p>
Categories: AI Research
Tags: AI, Agentic AI
2026-06-16, 00:00
<p>The sheer number of events and alerts can be overwhelming, but multi-layered pipelines can filter out the noise</p>
Categories: AI Research
Tags: AI, infostealer
2026-03-30, 00:00
“We’ll have a generation of security professionals who can supervise AI but can’t function without it."
Categories: AI Research, Sophos Insights
Tags: AI, AI Cybersecurity, AI RESEARCH, Generative AI, SOC
2025-10-24, 06:00
Following on from our preview, here’s the full rundown on LLM salting: a novel countermeasure against LLM jailbreaks, developed by AI researchers at Sophos X-Ops
Categories: AI Research
Tags: AI, CAMLIS, Featured, jailbreak, LLM, salting, Sophos X-Ops
2025-10-21, 06:00
On October 22-24, SophosAI will present research on ‘LLM salting’ (a novel countermeasure against jailbreaks) and command line classification at CAMLIS 2025
Categories: AI Research
Tags: AI, CAMLIS, Featured, LLM, Sophos X-Ops
2025-06-30, 07:00
Analyzing dark web forums to identify key experts on e-crime
Categories: AI Research, Threat Research
Tags: AI, cybercrime, Dark Web, Featured, threat activity cluster, threat actors
2025-03-19, 06:30
Sophos X-Ops’ research, presented at Virus Bulletin 2024, uses ‘multimodal’ AI to classify spam, phishing, and unsafe web content
Categories: AI Research
Tags: Featured, Large Language Models, Multimodal AI, Sophos X-Ops, spam detection, Web Content Filtering
2024-12-13, 06:30
SophosAI’s framework for upgrading the performance of LLMs for cybersecurity tasks (or any other specific task) is now open source.
Categories: AI Research
Tags: deepspeed, Featured, LLM, LLM tuning
2024-12-10, 10:35
“LLMbotomy” research reveals how Trojans can be injected into Large Language Models, and how to disarm them.
Categories: AI Research
Tags: AI Trojans, Featured, LLM
2024-10-23, 11:02
On October 24 and 25, SophosAI presents ideas on how to use models large and small—and defend against malignant ones.
Categories: AI Research
Tags: AI Trojans, anti-phishing, CAMLIS, Featured, Google, LLM, small model machine learning
2024-10-02, 00:00
Applying generative AI, bad actors could tailor disinformation campaigns to affect election outcomes on a massive scale with relatively little effort.
Categories: AI Research
Tags: adversarial ai, Featured, Generative AI, misinformation, scampaign
2024-10-01, 12:49
Sophos' Younghoo Lee will present his research on the use of AI to analyze both text and image data to classify spam, phishing, and unsafe web content in Dublin.
Categories: AI Research
Tags: anti-phishing, Featured, Large Language Models, Multimodal AI, spam detection, Web Content Filtering
2024-03-18, 06:00
Comparative Sophos X-Ops testing not only indicates which models fare best in cybersecurity, but where cybersecurity fares best in AI
Categories: AI Research
Tags: Featured, Large Language Models
2023-11-27, 06:30
Categories: AI Research, Threat Research
Tags: adversarial ai, artificial intelligence, Featured, Generative AI, scams, Sophos X-Ops
2023-10-18, 08:42
The conference on machine learning in cybersecurity is key to open exchange of research and knowledge.
Categories: AI Research
Tags: artificial intelligence, CAMLIS, Featured, Large Language Models, scams, Web Content Filtering
DISCLAIMER:
- Copyrights belong to each article's respective author.
- Article links lead to external websites, where you will be tracked, most likely.
11. SAFETY DETECTIVESby Safety DetectivesSafety Blog
2025-10-27, 10:48

An anonymous cybersecurity researcher discovered and reported to Safety Detectives about an unencrypted and non-password-protected database that contained approximately 7,000 records. Exposed data included names, email addresses, phone numbers, security clearance status or level, and other personal information.
The publicly exposed database was not password-protected or encrypted. It contained 7,028 records marked as “resume bank data” with potentially sensitive applicant information. In a reverse DNS search, it was identified that the IP address that hosted the documents traced back to a website called DomeWatch.us. According to information posted on House.gov by the Democratic Whip, DomeWatch is the House Democrats’ Official Online Resume Bank. On its Jobs section, DomeWatch posts current openings across Democratic Members’ offices and committees on Capitol Hill as well as related internships or fellowships. Individuals can submit their resumes using either the employment portal (which was created in November 2012) or the official mobile apps for both iOS and Android. The submissions are accessible by Senate Democratic offices.
The registration and technical contacts of the domain were promptly notified of the exposure. Public access to the database was restricted the same day, and it was no longer visible. Later on, they replied with a message that read: “Thanks for flagging”. In the About Us section of the website, it states that resumes remain in the bank for 90 days; once 3-months-old, the resume is automatically archived. However, nearly all of the records exposed were indicated with timestamps circa 2024-2025. It is unclear if this was a backup of archive data or otherwise. It is also unclear why these records appeared to have been kept for longer than the stated dates of storage.
The records indicated fields with information such as: internal ID numbers, application codes, first name, last name, phone number, email address, bio or congress experience, education, military service, security clearance and level, office interest, interest issues, home state, languages, political party affiliation, action tokens, and more. In total, the records listed 469 individuals with “top secret” federal security clearance as well as 4,221 individuals with congress experience. In regards to political affiliation, 6,300 individuals listed marked the Democratic Party; 17, the Republican Party; and 265, “Independent” or “Other”. The database also contained weblinks to Google forms and other documents.
According to the description on the Google Play Store: DomeWatch is a product of the Office of Democratic Whip Katherine Clark. It is designed to help House staff, the press, and the public better follow the latest developments from the US House of Representatives Floor. The app uses data from both majorityleader.gov and demcom.house.gov, which is the official intranet for House Democratic staff (available only within the House of Representatives firewall).





Any data exposure of a resume bank that contains potentially sensitive applicant information presents significant cybersecurity and privacy risks. When it comes to social engineering and phishing, the more personally identifiable information available, the more it may increase the potential success rate of a targeted attack. These records pose additional risks due to the fact that many of these individuals have working or volunteering experience in the government, Congress, political campaigns, or the military. Many of them also have security clearances, language skills, and political party affiliations that may potentially be of interest to malefactors.
In the current political environment, profiling and targeted harassment are notable potential risks. Another serious concern would be adversaries targeting specific individuals with privileged access to government systems, making them potentially high-value targets for espionage, recruitment, or blackmail. This isn’t an assertion that there are any national security risks to this exposure or that the data was ever at risk. These details are only here to provide hypothetical risk scenarios for educational purposes.
According to reports by AP, in July 2025, criminals used AI to create a deepfake of US Secretary of State Marco Rubio and attempted to contact foreign ministers. This raises serious potential concerns of how these individuals could be targeted for AI-assisted social engineering attempts, as many of them are currently (or have been previously) employed by members of Congress.
It is highly recommended that individuals who believe their PII or contact details may have potentially been exposed in any data breach take additional steps to validate job opportunities or suspicious communications. It is a good idea to enable MFA on email and mobile accounts that are associated with the potentially exposed data. Change passwords of affected accounts and never reuse passwords or variants of previously used passwords. For individuals with security clearance, there may be additional requirements to report the potential exposure so the incident is documented and any necessary mitigations can be applied. Strictly communicate through official channels and validate that the person or office is who they claim to be.
It is not known what internal safeguards are in place to protect congressional staff, interns, and volunteers. Hypothetically, these individuals could be potential targets because attackers might believe that their email accounts or contacts could provide policy intelligence, influence campaigns, or access government systems. It is not implied that there was ever any risk to this exposure. It is not known if the data was accessed by anyone else or how long the database was publicly exposed.
No wrongdoing by DomeWatch, or its employees, agents, contractors, affiliates, and/or related entities is implied here. It is not claimed either that any internal, applicant, or user data was ever at imminent risk. This report was published to raise public awareness and help strengthen data protection and cybersecurity practices. The hypothetical data-risk scenarios presented in this report are strictly and exclusively for educational purposes and do not reflect, suggest, or imply any actual compromise of data integrity.
The Safety Detectives’ Cybersecurity Team didn’t get access to the database, which means we could not download, retain, or share any data. This report has been shared with our team by an anonymous cybersecurity researcher. The limited number of redacted screenshots included in this article are used solely for verification and documentation purposes. We disclaim any and all liability arising from the use, interpretation, or reliance on this disclosure. We publish our findings to raise awareness of issues of data security and privacy.
Safety Detectives’ Previous Work
The Safety Detectives research lab is a pro bono service that aims to help the online community defend itself against cyber threats while educating organizations on how to protect their users’ data. The overarching purpose of our web mapping project is to help make the internet a safer place for all users.
Our previous reports have brought multiple high-profile data leaks to light, including 61 million records allegedly belonging to Verizon USA and listed for sale on a well-known hacker’s forum.
Our previous work also includes the discovery of a clear web forum post where a threat actor publicized a database with 10,000 records allegedly belonging to VirtualMacOSX.
2025-10-03, 12:19

A ransomware attack targeting Collins Aerospace’s MUSE check-in software caused widespread disruption across European airports beginning Friday, with continued delays and flight cancellations reported through the weekend.
The European Union Agency for Cybersecurity (ENISA) confirmed the incident on Monday, stating that “the type of ransomware has been identified. Law enforcement is involved to investigate.” Affected airports included London Heathrow, Brussels Zaventem, Berlin Brandenburg, and others using Collins’ automated check-in systems.
The attack disabled critical airline services, forcing airports to revert to manual boarding processes. Heathrow Airport told Reuters that “airlines across Heathrow have implemented contingencies whilst their supplier Collins Aerospace works to resolve an issue.” By Sunday, about half the airlines operating from Heathrow had restored partial access using backup systems.
The BBC obtained internal crisis memos showing Heathrow staff were instructed to continue manual check-ins while Collins rebuilt infected systems. However, the same memo warned that “more than a thousand computers may have been ‘corrupted’” and cleanup was mostly being done in person due to continued hacker presence within systems.
Brussels Airport canceled more than 130 outbound flights on Monday, while Berlin reported over an hour of delays for many departures. The Berlin Marathon worsened congestion at Brandenburg Airport, with passengers describing the experience as similar to early commercial air travel.
Collins Aerospace, a subsidiary of RTX, said on Monday it was “in the final stages of completing necessary software updates.” The company has not disclosed the exact nature of the ransomware strain, but reports suggest it may be linked to a group using the HardBit variant.
UK police have since arrested a man in his 40s in West Sussex in connection with the attack under the Computer Misuse Act. He has been released on conditional bail pending further investigation.
While ENISA and national agencies continue their inquiry, security experts like Sophos’ Rafe Pilling caution that “disruptive attacks are becoming more visible in Europe, but visibility doesn’t necessarily equal frequency.”
2025-10-03, 12:06

Cloudflare has successfully mitigated the largest distributed denial-of-service (DDoS) attack ever recorded, showcasing a concerning escalation in the scale of cyber threats.
“Cloudflare just autonomously blocked hyper-volumetric DDoS attacks twice as large as anything seen on the Internet before — peaking at 22.2 Tbps & 10.6 Bpps,” the company said in a tweet.
The previous record was an 11.5 Tbps UDP flood attack, which lasted 35 seconds. In contrast, Cloudflare’s report indicates that the latest attack lasted only about 40 seconds, which is a “hit-and-run” tactic designed to overwhelm defenses before they can respond fully.
This record-breaking incident combined multiple attack techniques in a single, massive multi-vector assault. Experts say such attacks are typically launched from enormous botnets (networks of compromised computers and IoT devices) that flood servers with traffic, rendering online services inaccessible to legitimate users.
Crucially, Cloudflare’s systems detected and blocked the attack autonomously, without any human intervention. By neutralizing the traffic at the network edge, close to its source, Cloudflare ensured that the intended targets remained fully operational.
Cloudflare’s success proves the growing importance of automated, machine learning-powered defenses, as traditional DDoS “scrubbing” centers, which are often reliant on manual traffic analysis, are ill-equipped to respond at this speed and scale.
As cybercriminals continue to refine their methods and expand their botnets, industry experts warn that hyper-volumetric DDoS attacks will likely become more frequent and more intense.
2025-10-03, 05:33

Valve has pulled the 2D platformer BlockBlasters from Steam after a malicious update enabled it to steal over $150,000 in cryptocurrency from users, including $32,000 from a Latvian streamer raising funds for cancer treatment. As reported by BleepingComputer and confirmed by malware researchers at G Data, the game was originally published on July 30, 2025, by Genesis Interactive and appeared legitimate, even earning more than 200 “Very Positive” reviews.
But a patch released on August 30 silently injected a cryptostealer, which began exfiltrating sensitive data such as crypto wallets, Steam credentials, browser extensions, and IP information from users’ machines. The campaign appears to have been targeted, with vx-underground reporting that “the Steam game was actually a cryptodrainer masquerading as a legitimate video game” and that some streamers were approached with fake promotional offers.
G Data’s analysis of the infected patch found a staged malware structure starting with a batch script named game2.bat, which checked for antivirus tools, harvested user information, and uploaded the data to a remote C2 server. Additional scripts (launch1.vbs, test.vbs) and executables (Client-built2.exe, Block1.exe) then loaded a Python-based backdoor and the StealC info-stealer. The malware added folder exclusions to Microsoft Defender and hid its actions behind the game’s launcher.
Latvian streamer Raivo Plavnieks (RastalandTV), who has stage 4 cancer, said they were infected during a live fundraiser. “For anybody wondering what is going on … my life was saved … until someone tuned in my stream and got me to download verified game on @Steam,” he posted on X.
Steam removed BlockBlasters on September 21. The incident follows a growing pattern of malware-laced games slipping past Valve’s initial screening, including Chemia and PirateFi. G Data noted that “hundreds of users are potentially affected” by the BlockBlasters campaign, which used password-protected archives and deprecated RC4 encryption to bypass detection.
As of early September, the game still had active players and was flagged as suspicious on SteamDB, reinforcing concerns about malware threats on mainstream game platforms.
2025-10-01, 15:50

Mexico’s Senate is moving forward with a new cybersecurity work agenda that could reshape the country’s digital regulation landscape. Led by the Senate’s Digital Rights Commission, the initiative seeks to develop and approve a comprehensive national cybersecurity law covering data protection, digital commerce, and online expression.
“With the Agency for Digital Transformation and Telecommunications, we discussed several topics, one of them being the organization of dialogue tables on cybersecurity to prepare the ruling on three initiatives that are in commissions for a national cybersecurity law,” said Luis Donaldo Colosio, President of the Digital Rights Commission.
The Senate aims to respond to the country’s fragmented cybersecurity framework, which currently lacks unified regulation. Existing laws criminalize certain cyber activities and mandate data protection, but oversight is split across multiple agencies. A recent legislative reshuffle has intensified the urgency, after the dissolution of Mexico’s data protection authority INAI and growing concerns about centralized power over digital governance.
According to the Digital Rights Commission, the absence of robust legislation “creates uncertainty for companies operating in the digital sector and exposes citizens to significant risks.” The new work plan includes cybersecurity training workshops during October, designated as Cybersecurity Month, as well as forums in November to update the General Law of Digital Rights.
The effort also includes a gender lens. A workshop titled “Legislating with a Gender Perspective in the Ecosystem” will be held in collaboration with Mujeres por más mujeres to help legislative teams embed equality into new digital policies.
If passed, the law would establish safeguards across digital platforms, social networks, and e-commerce tools, with a specific emphasis on protecting minors. The framework would also address the intersection of cybersecurity and free speech, a point that has drawn scrutiny in previous legislative proposals.
The final objective, Colosio noted, is to “establish a safer, more predictable, and equitable digital environment for all stakeholders.”
2025-09-27, 14:11

The Central Bank of Kenya (CBK) has launched the Banking Sector Cybersecurity Operations Centre (BS-SOC), a centralized facility aimed at improving cyber resilience across the country’s financial system.
Hosted within the CBK’s Cyber Fusion Unit, the BS-SOC will provide cyber threat intelligence, incident response, digital forensics, and cyber investigations. According to CBK, the centre is “a key part of the implementation of the Computer Misuse and Cybercrime (Critical Information Infrastructure and Cybercrime Management) Regulations, 2024” and aligns with the CBK Strategic Plan 2024–2027.
The launch comes amid a sharp rise in cyberattacks. Kenya’s Communications Authority reported 4.5 billion cyber threat events between April and June 2025, up 80.7% from the previous quarter. CBK’s own stress tests in May modeled a 5% chance of successful cyberattacks, with potential losses ranging from KSh 32.8 million to KSh 2.9 billion depending on severity.
CBK said it is working to harmonize the Commercial Banks Cybersecurity Guidelines (2017) and the Payment Service Providers Cybersecurity Guidelines (2019) with the 2024 regulations. In the meantime, regulated institutions are expected to comply with all three and report incidents to the BS-SOC within the stipulated timelines.
“The successful implementation of this initiative requires the full collaboration and cooperation of all stakeholders,” the CBK noted in its official statement. Governor Kamau Thugge added that “cyber threats continue to evolve. A sector-wide response is essential to protect Kenya’s financial system.”
Data from CBK also shows that cybercriminals siphoned KSh 1.59 billion from customer accounts in 2024, further underscoring the need for coordinated monitoring and response.
By integrating enforcement and threat response under one roof, CBK hopes to reduce fragmentation and give regulators better visibility into systemic cyber risks affecting banks and payment providers across Kenya.
2025-09-25, 08:51

The City of Yellowknife says its network has been safely restored following a cybersecurity incident that disrupted services for over a week.
The attack, first disclosed on September 15, forced the city to limit internal access and temporarily disable online services. Debit and credit card payments were suspended, library computers were offline, and patrons were restricted to borrowing five items at a time. As of Monday, most systems have returned to normal.
Public safety and critical infrastructure continued to operate throughout. “The city enacted its incident response protocols to contain the incident, including the implementation of additional measures to further enhance its network security,” officials said in a statement cited by NNSL.
Click and Fix YK, the city’s issue-reporting portal, remains offline, as does CityExplorer, its interactive mapping tool. Residents are being asked to email non-emergency issues while restoration continues.
There is no evidence of data loss so far. “To date, we have no evidence that any personal information was compromised in the incident,” the city confirmed. “In the event our investigation determines that personal information was compromised, we will contact those individuals directly.”
City Manager Stephen Van Dine told Cabin Radio the network breach was being handled carefully, saying, “We believe it is under control at this stage… we’re certainly more confident than we were 48 hours ago.” He noted there was no ransom demand and declined to label the event a confirmed cyberattack, only that “there was some kind of activity to get into our systems that shouldn’t be there.”
Third-party experts continue to assist with the investigation, and the city has promised a thorough post-incident review to evaluate the timeline, impacts, and potential long-term upgrades to network defenses.
2025-09-25, 08:26

SonicWall has disclosed a security incident involving its MySonicWall cloud backup service, confirming that threat actors gained access to a subset of firewall configuration files. The company said that fewer than 5% of its firewall install base was affected, but acknowledged the potential severity of the breach.
The attack involved a series of brute force attempts targeting the MySonicWall.com portal, allowing unauthorized access to firewall preference files stored in cloud backups. While credentials within the files were encrypted, SonicWall warned that “the files also included information that could make it easier for attackers to potentially exploit the related firewall.”
Security researchers noted that these configuration files often contain DNS, log, and user/group settings — sensitive data that could be leveraged in future attacks. As Arctic Wolf researchers pointed out, “nation-state hackers and ransomware groups previously have exploited such information to conduct subsequent attacks.”
SonicWall emphasized that this was not a ransomware event, stating it was “a series of brute force attacks aimed at gaining access to the preference files stored in backup.” The company has terminated the unauthorized backup point and is working with cybersecurity partners and law enforcement to assess the full scope of the breach.
The Cybersecurity and Infrastructure Security Agency (CISA) also issued an alert urging immediate action. “Customers with at-risk devices should implement the advisory’s containment and remediation guidance immediately,” the agency said.
SonicWall has published detailed guidance for users to determine if their firewall devices are affected. Impacted customers are advised to log in to their MySonicWall accounts, check for flagged serial numbers under the Product Management section, and follow the remediation steps, including credential resets and service reviews.
At present, there is no indication that the compromised files have been leaked online. However, the company stated that it will continue to monitor the situation and release further updates as necessary.
2025-09-23, 16:22

OpenAI is preparing stricter safety features for ChatGPT as it faces mounting lawsuits and scrutiny over teen protection. CEO Sam Altman confirmed the company will soon require users to verify their age if it suspects a user is under 18, saying the changes are meant to “prioritize safety ahead of privacy and freedom for teens.”
“When you log in to ChatGPT, a banner will appear asking you to verify your age,” the company explained. “You will have 60 days to complete this process, after which your access to ChatGPT will be blocked until you successfully complete the age verification process.”
OpenAI will rely on third-party service Yoti to perform the checks. “You will be asked to enter the necessary details to confirm your age,” the post continued. “Depending on the method you choose, you may be asked to take a selfie, upload a valid ID, or use the Yoti app. Once your age is verified, you will be redirected to ChatGPT and can continue using the service as usual.”
The system will automatically place under-18 users into a restricted version of ChatGPT, which blocks sexual content and adds safeguards. Parents will soon be able to link accounts to monitor chats, disable history, enforce blackout hours, and receive alerts if the AI detects signs of acute distress. OpenAI noted that in some cases, “we may involve law enforcement as a next step.”
The rollout comes as lawmakers question whether AI can reliably predict age. Researchers warn that language-based cues are easily manipulated, while recent lawsuits accuse ChatGPT of failing to prevent harm in long sessions with vulnerable teens.
Despite concerns about privacy trade-offs, Altman stood by the decision. “Not everyone will agree with how we are resolving that conflict,” he said, “but we believe it is a worthy tradeoff.”
2025-09-23, 15:54

CrowdStrike and Meta have jointly released CyberSOCEval, a new open-source benchmark suite designed to evaluate how large language models (LLMs) perform across critical security operations center (SOC) tasks like malware analysis, incident response, and threat detection.
Built on Meta’s CyberSecEval framework and integrated with CrowdStrike’s threat intelligence, the tool aims to give organizations a standardized way to test the effectiveness of AI models under real-world attack conditions. The benchmark suite, now available on GitHub, includes documentation, sample datasets, and guidance for integrating the tests into existing SOC environments.
The rise of AI in cybersecurity has made it harder for teams to choose the right tools. Many security products now claim AI capabilities, but without clear benchmarks, it’s been difficult to assess which models deliver real-world value. CyberSOCEval addresses this by simulating adversarial tactics and complex security scenarios, allowing teams to validate LLM performance before deployment.
Vincent Gonguet, Director of Product, GenAI at Superintelligence Labs at Meta, said the collaboration “introduces a new open source benchmark suite to evaluate the capabilities of LLMs in real world security scenarios. With these benchmarks in place, and open for the security and AI community to further improve, we can more quickly work as an industry to unlock the potential of AI in protecting against advanced attacks.”
Daniel Bernard, Chief Business Officer at CrowdStrike, added that “when two leaders like CrowdStrike and Meta come together, it’s larger than collaboration, it’s about setting the direction of cybersecurity for the AI era,” emphasizing the benchmark’s role in helping security teams adopt AI with confidence.
The companies hope CyberSOCEval will support both enterprise users and AI developers. Businesses get a transparent framework for comparison, while developers gain feedback on how their models handle realistic security workflows, including complex reasoning and industry-specific language.
ALL RSS FEEDS
